L’histoire se poursuit: Annonce de la version 14 du Langage Wolfram et de Mathematica. À la pointe de la technologie 2023
La version 14.0 deWolfram Language et Mathematica est disponible dès maintenant, aussi bien sur le bureau que dans le cloud. Veuillez également consulter des informations plus détaillées sur la Version 13.1, la Version 13.2 et la Version 13.3.
Construire quelque chose de plus grand et plus grand… depuis 35 ans et en comptant
Aujourd’hui, nous célébrons un nouveau jalon dans notre parcours de près de quatre décennies avec la sortie de la Version 14.0 de Wolfram Language et Mathematica. Depuis la sortie de laVersion 13.0 il y a deux ans, nous avons régulièrement livré les fruits de nos recherches et développements dans des versions .1 tous les six mois. Aujourd’hui, nous regroupons tout cela, et plus encore, dans la Version 14.0.
Cela fait maintenant plus de 35 ans depuis la sortie de la Version 1.0. Et pendant toutes ces années, nous n’avons cessé de construire une tour de capacités de plus en plus haute, élargissant progressivement la portée de notre vision et l’étendue de notre couverture computationnelle du monde.

La version 1.0 comptait 554 fonctions intégrées ; dans la version 14.0, il y en a 6602. Et derrière chacune de ces fonctions se cache une histoire. Parfois, c’est l’histoire de la création d’un superalgorithme qui encapsule des décennies de développement algorithmique. Parfois, c’est l’histoire d’une sélection minutieuse de données qui n’avaient jamais été assemblées auparavant. Parfois, c’est l’histoire de creuser jusqu’à l’essence même de quelque chose pour inventer de nouvelles approches et de nouvelles fonctions capables de la capturer.
Et à partir de tous ces éléments, nous avons progressivement construit l’ensemble cohérent qu’est le Langage Wolfram d’aujourd’hui. Dans l’arc de l’histoire intellectuelle, il définit un nouveau paradigme computationnel global pour formaliser le monde. Et sur le plan pratique, il offre un superpouvoir pour mettre en œuvre la pensée computationnelle – et permettre le “X computationnel” pour tous les domaines X.
Pour nous, il est profondément satisfaisant de voir ce qui a été accompli au cours des trois dernières décennies avec tout ce que nous avons construit jusqu’ici. Tant de découvertes, tant d’inventions, tant réalisé, tant appris. Et voir cela nous aide à continuer à avancer dans nos efforts pour aborder encore plus, et pour continuer à repousser toutes les limites que nous pouvons avec notre R&D, et pour livrer les résultats dans de nouvelles versions de notre système.
Notre portefeuille de R&D est vaste. Des projets qui sont achevés quelques mois seulement après leur conception, à des projets qui reposent sur des années (et parfois même des décennies) de développement systématique. Et la clé de tout ce que nous faisons est d’exploiter ce que nous avons déjà fait – souvent en prenant ce qui était autrefois le summum de la réalisation technique, et en l’utilisant maintenant comme un élément de construction routinier pour atteindre un niveau qui pouvait à peine être imaginé auparavant. Et au-delà de la technologie pratique, nous continuons également à aller de plus en plus loin dans l’exploitation du vaste cadre conceptuel que nous avons construit toutes ces années – et à le encapsuler progressivement dans la conception du Langage Wolfram.
Nous avons travaillé dur toutes ces années non seulement pour créer des idées et de la technologie, mais aussi pour façonner un écosystème pratique et durable dans lequel nous pouvons faire cela systématiquement maintenant et à l’avenir. Et nous continuons à innover dans ces domaines, élargissant la diffusion de ce que nous avons construit de nouvelles et différentes manières, et par le biais de nouveaux et différents canaux. Et au cours des cinq dernières années, nous avons également pu ouvrir notre processus de conception central au monde – diffusant régulièrement en direct ce que nous faisons d’une manière unique et ouverte.
Et en effet, au cours des dernières années, les fondements essentiels de tout ce que nous offrons aujourd’hui dans la version 14.0 ont été partagés ouvertement avec le monde, ce qui représente une réalisation non seulement pour nos équipes internes mais aussi pour les nombreux participants et commentateurs de nos diffusions en direct.
Une partie de ce que représente la version 14.0 est de continuer à étendre le domaine de notre langage computationnel et de notre formalisation computationnelle du monde. Mais la version 14.0 consiste également à rationaliser et à peaufiner les fonctionnalités que nous avons déjà définies. À travers le système, nous avons rendu les choses plus efficaces, plus robustes et plus pratiques. Et oui, dans les logiciels complexes, les bogues de toutes sortes sont une inévitabilité théorique et pratique. Et dans la version 14.0, nous avons corrigé près de 10’000 bugs, la majorité étant trouvée par nos méthodes de test logiciel internes de plus en plus sophistiquées.
Maintenant, nous devons le dire au monde
Même après tout le travail que nous avons investi dans le langage Wolfram au cours des dernières décennies, il reste encore un autre défi : comment faire savoir aux gens ce que le langage Wolfram peut réellement accomplir. Lorsque nous avons publié la Version 1.0, j’ai pu rédiger un livre de taille raisonnable qui expliquait assez bien l’ensemble du système. Mais pour la Version 14.0, avec toutes les fonctionnalités qu’elle contient, il faudrait un livre comportant peut-être 200 000 pages.
Et à ce stade, personne (même moi !) ne sait immédiatement tout ce que peut faire le langage Wolfram. Bien sûr, l’une de nos grandes réussites a été de maintenir, à travers toutes ces fonctionnalités, une conception étroitement cohérente et consistante qui se traduit finalement par un petit ensemble de principes fondamentaux à apprendre. Mais à l’échelle immense du langage Wolfram tel qu’il existe aujourd’hui, savoir ce qui est possible – et ce qui peut maintenant être formulé en termes computationnels – est inévitablement très difficile. Et bien trop souvent, lorsque je montre aux gens ce qui est possible, j’obtiens la réponse : “Je ne savais pas que le langage Wolfram pouvait faire cela !”
Ces dernières années, nous avons donc mis de plus en plus l’accent sur la création de mécanismes à grande échelle pour expliquer le langage Wolfram aux gens. Cela commence à un niveau très détaillé, avec des informations “juste à temps” fournies, par exemple, par des suggestions lorsque vous tapez. Ensuite, pour chaque fonction (ou autre construction dans le langage), il existe des pages qui expliquent la fonction, avec de nombreux exemples. Et maintenant, de plus en plus, nous ajoutons du “matériel d’apprentissage juste à temps” qui tire parti de la concrétude des fonctions pour fournir des explications autonomes du contexte plus large de ce qu’elles font.
Au fait, de nos jours, nous devons expliquer le langage Wolfram non seulement aux humains, mais aussi aux IA – et notre documentation et nos exemples très complets se sont révélés extrêmement utiles pour former les LLM à utiliser le langage Wolfram. Et pour les IA, nous fournissons toute une gamme d’outils, comme un accès documentaire immédiatement calculable et une gestion des erreurs calculable. Et avec notre technologie Chat Notebook, il existe également une nouvelle “rampe de lancement” pour créer du code Wolfram Language à partir d’entrées linguistiques (ou visuelles, etc.).
Mais qu’en est-il du tableau d’ensemble du langage Wolfram ? Pour les humains et les IA, il est important de pouvoir expliquer les choses à un niveau plus élevé, et nous nous engageons de plus en plus dans cette voie. Depuis plus de 30 ans, nous avons des “pages guides” qui résument des fonctionnalités spécifiques dans des domaines particuliers. Maintenant, nous ajoutons des “pages de domaine principal” qui donnent une image plus large de vastes domaines de fonctionnalités – chacune couvrant en effet ce qui pourrait autrement être un produit complet à part entière, s’il n’était pas simplement une partie intégrée du langage Wolfram.

Mais nous allons encore beaucoup plus loin, en créant des cours entiers et des livres qui offrent des introductions modernes et pratiques, activées par le langage Wolfram, à un large éventail de domaines. Nous avons désormais couvert le contenu de nombreux cours universitaires standard (et bien plus encore), d’une manière nouvelle et très efficace “computationnelle”, qui permet une immersion immédiate et pratique dans les concepts.

Tous ces cours comprennent non seulement des cours magistraux et des cahiers de notes, mais aussi des exercices automatiquement corrigés, ainsi que des certifications officielles. De plus, nous avons un calendrier régulier de groupes d’étude entre pairs, dirigés par un instructeur, où tout le monde se réunit en même temps pour discuter de ces cours. Et oui, notre programme Wolfram U est en train de devenir une entité éducative importante, avec des milliers d’étudiants à tout moment.
En plus des cours complets, nous proposons des “mini-séries” de cours sur des sujets spécifiques:

Et nous proposons également des cours et des livres sur le langage Wolfram lui-même, comme mon Introduction Élémentaire au Langage Wolfram, qui est sortie dans une troisième édition cette année (et est accompagnée d’un cours, d’une version en ligne, etc.).

Dans une direction quelque peu différente, nous avons élargi notre École d’Été Wolfram pour inclure une École d’Hiver Wolfram, et nous avons considérablement développé notre Programme de Recherche Estivale au Lycée Wolfram, en ajoutant des programmes toute l’année, des programmes pour le collège, etc. – y compris le nouveau programme d’activités hebdomadaires “Aventures Computationnelles”.
Ensuite, il y a la diffusion en direct. Nous faisons des “diffusions en direct R&D” chaque semaine avec notre équipe de développement (et parfois aussi des invités externes). Et moi-même, j’ai également beaucoup fait de diffusion en direct (232 heures en 2023 seulement) – certaines pour examiner les fonctionnalités du langage Wolfram, et d’autres pour répondre à des questions techniques et autres.
La liste des moyens par lesquels nous faisons connaître le langage Wolfram ne cesse de s’allonger. Il y a la Communauté Wolfram, pleine de contributions intéressantes, et qui compte de plus en plus de lecteurs. Il y a des sites comme les Défis Wolfram. Il y a nos Conférences sur la Technologie Wolfram. Et bien plus encore.
Nous avons déployé des efforts immenses pour construire l’ensemble de la pile technologique Wolfram au cours des quatre dernières décennies. Et même alors que nous continuons à la développer de manière agressive, nous mettons de plus en plus d’efforts pour informer le monde de tout ce qu’elle contient réellement, et pour aider les gens (et les IA) à en faire le meilleur usage possible. Mais dans un sens, tout ce que nous faisons n’est qu’une graine pour ce que la communauté plus large des utilisateurs du langage Wolfram fait et peut faire. Répandre la puissance du langage Wolfram à de plus en plus de personnes et de domaines.
Les LLMs ont débarqué
Les superfonctions d’apprentissage automatique Classify et Predict sont apparues pour la première fois dans le langage Wolfram en 2014 (Version 10). L’année suivante, des fonctions telles que ImageIdentify et LanguageIdentify ont commencé à apparaître, et quelques années plus tard, nous avions introduit tout notre cadre de réseaux neuronaux et le Neural Net Repository. Cela incluait divers réseaux neuronaux pour la modélisation du langage, qui nous ont permis de développer des fonctions comme SpeechRecognize et une version expérimentale de FindTextualAnswer. Mais, comme tout le monde, nous avons été pris au dépourvu à la fin de 2022 par ChatGPT et ses remarquables capacités.
Très rapidement, nous avons réalisé qu’un nouveau cas d’utilisation majeur – et un nouveau marché – avait émergé pour Wolfram|Alpha et le langage Wolfram. Désormais, ce n’étaient pas seulement les humains qui auraient besoin des outils que nous avions construits ; ce sont aussi les IA. En mars 2023, nous avons travaillé avec OpenAI pour utiliser notre technologie Wolfram Cloud et fournir un module complémentaire à ChatGPT qui lui permet d’appeler Wolfram|Alpha et le langage Wolfram. Les LLMs comme ChatGPT offrent de remarquables nouvelles capacités en reproduisant le langage humain, la pensée humaine de base et les connaissances générales. Mais, comme les humains non assistés, ils ne sont pas configurés pour traiter des calculs détaillés ou des connaissances précises. Pour cela, comme les humains, ils doivent utiliser un formalisme et des outils. Et la chose remarquable est que le formalisme et les outils que nous avons construits dans le langage Wolfram (et Wolfram|Alpha) sont essentiellement une correspondance parfaite pour ce dont ils ont besoin.
Nous avons créé le langage Wolfram pour établir un pont entre ce que les humains pensent et ce que la computation peut exprimer et mettre en œuvre. Et maintenant, c’est ce que les IA peuvent utiliser également. Le langage Wolfram fournit un médium non seulement pour que les humains “pensent de manière computationnelle”, mais aussi pour que les IA le fassent. Et nous avons continuellement travaillé à l’ingénierie pour permettre aux IA d’appeler le langage Wolfram aussi facilement que possible.
Mais en plus des LLMs utilisant le langage Wolfram, il existe également maintenant la possibilité pour le langage Wolfram d’utiliser les LLMs. Et déjà en juin 2023 (Version 13.3), nous avons publié une collection importante de capacités basées sur les LLMs dans le langage Wolfram. Une catégorie comprend des fonctions LLM, qui utilisent efficacement les LLMs comme “algorithmes internes” pour les opérations dans le langage Wolfram:

À la manière typique du langage Wolfram, nous avons une représentation symbolique pour les LLMs : LLMConfiguration[…] représente un LLM avec ses différents paramètres, invitations, etc. Ces derniers mois, nous avons progressivement ajouté des connexions à toute la gamme des LLMs populaires, faisant du langage Wolfram un hub unique non seulement pour l’utilisation des LLMs, mais aussi pour l’étude des performances – et de la science – des LLMs.
Vous pouvez définir vos propres fonctions LLM dans le langage Wolfram. Mais il existe également le Répertoire de Prompts Wolfram qui joue un rôle similaire pour les fonctions LLM que le Répertoire de Fonctions Wolfram joue pour les fonctions ordinaires du langage Wolfram. Il existe un Répertoire de Prompts public qui contient actuellement plusieurs centaines de prompts organisés. Il est également possible pour quiconque de publier ses prompts dans le Wolfram Cloud et de les rendre accessibles publiquement (ou privément). Les prompts peuvent définir des personnages (“parler comme un [pirate stéréotypé]”). Ils peuvent définir des fonctions orientées IA (“écrire avec des emojis”). Et ils peuvent définir des modificateurs qui affectent la forme de la sortie (“style haïku”).

En plus d’appeler les LLM de manière “programmatique” dans le langage Wolfram, il existe le nouveau concept (introduit pour la première fois dans la version 13.3) des “Chat Notebooks”. Les Chat Notebooks représentent un nouveau type d’interface utilisateur qui combine les fonctionnalités graphiques, computationnelles et documentaires des traditionnels Wolfram Notebooks avec les nouvelles capacités d’interface linguistique apportées par les LLMs.
L’idée de base d’un Chat Notebook – introduit dans la version 13.3 et désormais étendu dans la version 14.0 – est que vous pouvez avoir des “cellules de chat” (demandées en tapant ‘) dont le contenu est envoyé non pas au noyau Wolfram, mais plutôt à un LLM:

Vous pouvez utiliser des “prompts de fonction” – par exemple, à partir du Répertoire de Prompts Wolfram – directement dans un Chat Notebook:

Et à partir de la version 14.0, vous pouvez également intégrer directement des calculs du langage Wolfram dans votre “conversation” avec l’LLM:

(Vous tapez pour insérer Wolfram Language, un peu comme vous pouvez utiliser <* … *> pour insérer Wolfram Language dans des cellules d’évaluation externes.)
Une des particularités des Chat Notebooks, comme leur nom l’indique, c’est qu’ils sont vraiment axés sur le “chat” et sur l’interaction séquentielle avec un LLM. Dans un notebook ordinaire, l’endroit où chaque évaluation en langage Wolfram est demandée n’a pas d’importance ; ce qui compte, c’est l’ordre dans lequel le noyau Wolfram effectue les évaluations. Mais dans un Chat Notebook, les évaluations LLM font toujours partie d’un “chat” qui est explicitement structuré dans le notebook.
Un élément clé des Chat Notebooks est le concept de “chat block” : tapez ~ pour insérer un séparateur dans le notebook qui “démarre un nouveau chat”.

Les Chat Notebooks, avec toutes leurs capacités typiques d’édition, de structuration, d’automatisation, etc., sont très puissants en tant qu'”interfaces LLM”. Mais il y a une autre dimension également, rendue possible par la capacité des LLM à appeler le langage Wolfram en tant qu’outil.
À un niveau, les Chat Notebooks fournissent une “rampe de lancement” pour utiliser le langage Wolfram. Wolfram|Alpha – et encore plus, Wolfram|Alpha Notebook Edition – vous permettent de poser des questions en langage naturel, qui sont ensuite traduites en langage Wolfram et les réponses calculées. Mais dans les Chat Notebooks, vous pouvez aller au-delà de poser des questions spécifiques. Au lieu de cela, à travers l’LLM, vous pouvez simplement “commencer à discuter” de ce que vous voulez faire, puis générer et exécuter du code en langage Wolfram:

The workflow is typically as follows. First, you have to conceptualize in computational terms what you want. (And, yes, that step requires computational thinking—which is a very important skill that too few people have so far learned.) Then you tell the LLM what you want, and it’ll try to write Wolfram Language code to achieve it. It’ll typically run the code for you (but you can also always do it yourself)—and you can see whether you got what you wanted. But what’s crucial is that Wolfram Language is intended to be read not only by computers but also by humans. And particularly since LLMs actually usually seem to manage to write pretty good Wolfram Language code, you can expect to read what they wrote, and see if it’s what you wanted. If it is, you can take that code, and use it as a “solid building block” for whatever larger system you might be trying to set up. Otherwise, you can either fix it yourself, or try chatting with the LLM to get it to do it.
One of the things we see in the example above is the LLM—within the Chat Notebook—making a “tool call”, here to a Wolfram Language evaluator. In the Wolfram Language there’s now a whole mechanism for defining tools for LLMs—with each tool being represented by an LLMTool symbolic object. In Version 14.0 there’s an experimental version of the new Wolfram LLM Tool Repository with some predefined tools:

Dans un Chat Notebook par défaut, l’LLM a accès à certains outils par défaut, qui comprennent non seulement l’évaluateur en langage Wolfram, mais aussi des fonctionnalités telles que la recherche dans la documentation Wolfram et les requêtes Wolfram|Alpha. Il est courant de voir l’LLM aller et venir en essayant d’écrire du “code qui fonctionne”, et parfois de devoir “recourir” (comme le font les humains) à la lecture de la documentation.
Quelque chose de nouveau dans la version 14.0 est l’accès expérimental aux LLM multimodaux qui peuvent prendre des images ainsi que du texte en entrée. Lorsque cette fonctionnalité est activée, cela permet à l’LLM de “regarder les images à partir du code qu’il a généré”, de voir si elles correspondent à ce qui a été demandé, et éventuellement de se corriger lui-même:

L’intégration profonde des images dans le langage Wolfram – et les notebooks Wolfram – ouvre toutes sortes de possibilités pour les LLMs multimodaux. Ici, nous fournissons un tracé sous forme d’image et demandons à l’LLM comment le reproduire:

Une autre direction pour les LLMs multimodaux consiste à prendre des données (dans les centaines de formats acceptés par le langage Wolfram) et à utiliser l’LLM pour guider leur visualisation et leur analyse dans le langage Wolfram. Voici un exemple qui part d’un fichier data.csv dans le répertoire actuel sur votre ordinateur:

Une chose très agréable lorsque l’on utilise le langage Wolfram directement, c’est que tout ce que l’on fait (sauf si l’on utilise RandomInteger, etc.) est complètement reproductible ; refaites la même computation deux fois et vous obtiendrez le même résultat. Ce n’est pas vrai avec les LLMs (du moins pour l’instant). Ainsi, lorsque l’on utilise des LLMs, cela semble quelque chose de plus éphémère et fugace que l’utilisation du langage Wolfram. Il faut saisir tous les bons résultats que l’on obtient, car on pourrait ne jamais être capable de les reproduire. Oui, c’est très utile de pouvoir tout stocker dans un Chat Notebook, même si on ne peut pas le rerun et obtenir les mêmes résultats. Mais l’utilisation des résultats des LLMs de manière plus “permanente” tend à se faire “hors ligne”. Utilisez un LLM “en amont” pour comprendre quelque chose, puis utilisez simplement le résultat qu’il a donné.
Une application inattendue des LLMs pour nous a été de suggérer des noms de fonctions. Avec “l’expérience” de l’LLM sur ce dont les gens parlent, il est bien placé pour suggérer des fonctions que les gens pourraient trouver utiles. Et oui, lorsqu’il écrit du code, il a tendance à halluciner de telles fonctions. Mais dans la version 14.0, nous avons en fait ajouté une fonction – DigitSum – qui nous a été suggérée par les LLMs. Et dans le même esprit, nous pouvons nous attendre à ce que les LLMs soient utiles pour établir des connexions avec des bases de données externes, des fonctions, etc. L’LLM “lit la documentation” et essaie d’écrire du “code de colle” en langage Wolfram – qui peut ensuite être examiné, vérifié, etc., et s’il est correct, peut être utilisé par la suite.
Ensuite, il y a la curation des données, un domaine dans lequel – grâce à Wolfram|Alpha et à beaucoup de nos autres efforts – nous sommes devenus extrêmement compétents au cours des deux dernières décennies. Dans quelle mesure les LLMs peuvent-ils aider dans ce domaine ? Ils ne “résolvent certainement pas tout le problème”, mais les intégrer avec les outils que nous avons déjà nous a permis, au cours de l’année écoulée, d’accélérer certains de nos pipelines de curation des données par un facteur de deux ou plus.
Si l’on regarde l’ensemble de la pile technologique et de contenu qui compose le langage Wolfram moderne, la grande majorité de celui-ci n’est pas aidée par les LLMs et ne le sera probablement pas. Mais il existe de nombreux coins – parfois inattendus – où les LLMs peuvent considérablement améliorer les heuristiques ou résoudre d’autres problèmes. Et dans la version 14.0, il commence à y avoir toute une variété de fonctions “LLM à l’intérieur”.
Un exemple est TextSummarize, une fonction que nous avons envisagée d’ajouter depuis plusieurs versions – mais que nous pouvons enfin implémenter à un niveau utile grâce aux LLMs:

Les principaux LLMs que nous utilisons actuellement sont basés sur des services externes. Cependant, nous développons des capacités pour nous permettre d’exécuter des LLMs dans des installations locales du langage Wolfram dès que cela sera techniquement réalisable. Et une capacité qui fait en fait partie de notre effort principal en matière d’apprentissage automatique est NetExternalObject – une façon de représenter de manière symbolique un réseau neuronal défini de manière externe qui peut être exécuté dans le langage Wolfram. NetExternalObject vous permet, par exemple, de prendre n’importe quel réseau au format ONNX et de le traiter efficacement comme un composant dans un réseau neuronal du langage Wolfram. Voici un réseau pour l’estimation de la profondeur des images – que nous importons ici depuis un référentiel externe (bien qu’il existe en fait un réseau similaire déjà disponible dans le Wolfram Neural Net Repository) :

Maintenant, nous pouvons appliquer ce réseau importé à une image qui a été encodée avec notre encodeur d’images intégré, puis nous prenons le résultat et le visualisons :

Il est souvent très pratique de pouvoir exécuter des réseaux localement, mais cela peut parfois nécessiter un matériel de haute performance. Par exemple, il existe maintenant une fonction dans le Wolfram Function Repository qui effectue une synthèse d’images entièrement localement, mais pour l’exécuter, vous avez besoin d’un GPU avec au moins 8 Go de VRAM :

Au fait, basées sur les principes des LLM (et des idées comme les transformers), il y a eu d’autres avancées en matière d’apprentissage automatique qui ont renforcé toute une gamme de domaines du langage Wolfram – avec un exemple étant la segmentation d’images, où ImageSegmentationComponents fournit maintenant une segmentation “sensible au contenu” robuste :

Still Going Strong on Calculus
Lorsque Mathematica 1.0 a été publié en 1988, c’était un moment de surprise où l’on pouvait maintenant faire des intégrales de manière symbolique par ordinateur de manière routinière. Et ce n’est pas longtemps après que nous sommes arrivés au point – d’abord avec les intégrales indéfinies, puis avec les intégrales définies – où ce qui est maintenant le langage Wolfram pouvait faire des intégrales mieux que n’importe quel humain. Est-ce que cela signifiait que nous avions “terminé” avec le calcul ? Eh bien, non. Tout d’abord, il y avait les équations différentielles et les équations aux dérivées partielles. Il a fallu une décennie pour amener les EDO symboliques à un niveau supérieur à celui des humains. Et avec les EPD symboliques, cela a pris jusqu’à il y a quelques années. En chemin, nous avons développé le calcul discret, les développements asymptotiques et les transformées intégrales. Nous avons également implémenté de nombreuses fonctionnalités spécifiques nécessaires pour des applications telles que les statistiques, la probabilité, le traitement du signal et la théorie de la commande. Mais même maintenant, il reste des frontières à explorer.
Et dans la Version 14, il y a des avancées significatives autour du calcul. Une catégorie concerne la structure des réponses. Oui, on peut avoir une formule qui représente correctement la solution à une équation différentielle. Mais est-elle sous la forme la meilleure, la plus simple ou la plus utile ? Eh bien, dans la Version 14, nous avons travaillé dur pour nous assurer qu’elle l’est – souvent en réduisant de manière spectaculaire la taille des expressions générées.
Une autre avancée concerne l’expansion de la gamme des opérations de calcul “pré-emballées”. Nous avons pu faire des dérivées depuis la Version 1.0. Mais dans la Version 14, nous avons ajouté la différenciation implicite. Et oui, on peut donner une définition de base pour cela assez facilement en utilisant la différenciation ordinaire et la résolution d’équations. Mais en ajoutant un ImplicitD explicite, nous regroupons tout cela – et traitons les cas difficiles – de sorte qu’il devient routinier d’utiliser la différenciation implicite où vous le souhaitez:

Une autre catégorie d’opérations de calcul préemballées nouvelles dans la Version 14 concerne l’intégration basée sur les vecteurs. Il était toujours possible de le faire de manière “faites-le vous-même”. Mais dans la Version 14, ce sont désormais des fonctions intégrées optimisées qui couvrent également les cas particuliers, etc. Et ce qui les rend possibles est en fait un développement dans un autre domaine : notre projet décennal visant à ajouter la computation géométrique au langage Wolfram, ce qui nous a donné une manière naturelle de décrire des constructions géométriques telles que des courbes et des surfaces:


Une fonctionnalité connexe introduite dans la Version 14 est ContourIntegrate:

Des fonctions telles que ContourIntegrate « obtiennent la réponse ». Mais si l’on apprend ou explore le calcul, il est souvent aussi utile de pouvoir effectuer les opérations de manière plus « étape par étape ». Dans la Version 14, vous pouvez commencer avec une intégrale inactive

et effectuer explicitement des opérations telles que le changement de variables:

Parfois, les réponses réelles sont exprimées sous forme inactive, notamment sous la forme de sommes infinies :

Et maintenant, dans la Version 14, la fonction TruncateSum vous permet de prendre une telle somme et de générer une “approximation” tronquée:

Des fonctions comme D et Integrate—ainsi que LineIntegrate et SurfaceIntegrate—sont, en un sens, le « calcul classique », enseigné et utilisé depuis plus de trois siècles. Mais dans la Version 14, nous prenons également en charge ce que nous pouvons considérer comme des opérations de calcul « émergentes », comme la différentiation fractionnaire:

Langage de base
Quelles sont les primitives à partir desquelles nous pouvons le mieux construire notre conception de la computation ? C’est en quelque sorte la question que je me pose depuis plus de quatre décennies, et qui a déterminé les fonctions et les structures au cœur du Langage Wolfram.
Et au fil des années, à mesure que nous découvrons de plus en plus ce qui est possible, nous reconnaissons et inventons de nouvelles primitives qui seront utiles. Et, oui, le monde – et les manières dont les gens interagissent avec les ordinateurs – évoluent également, ouvrant de nouvelles possibilités et apportant une nouvelle compréhension des choses. Oh, et cette année, il y a des LLMs qui peuvent “comprendre le sens intellectuel du monde” et suggérer de nouvelles fonctions qui peuvent s’intégrer dans le cadre que nous avons créé avec le Langage Wolfram. (Et, au fait, il y a également eu de nombreuses suggestions formidables de la part des auditeurs de nos diffusions en direct de révisions de conception.)
Une nouvelle construction ajoutée dans la Version 13.1 – et que j’ai personnellement trouvée très utile – est « Threaded ». Lorsqu’une fonction est listable – comme Plus – les niveaux supérieurs des listes sont combinés:

Mais parfois, vous voulez qu’une liste soit “intégrée” dans l’autre au niveau le plus bas, et non pas le plus haut. Et maintenant, il y a un moyen de spécifier cela en utilisant Threaded:

En un sens, Threaded fait partie d’une nouvelle vague de constructions symboliques qui ont des “effets ambiants” sur les listes. Un exemple très simple (introduit en 2015) est Nothing:

Un autre, introduit en 2020, est Splice:

Un vieux classique de la conception du Langage Wolfram concerne la manière dont les boucles d’évaluation infinies sont gérées. Et dans la Version 13.2, nous avons introduit la construction symbolique TerminatedEvaluation pour fournir une meilleure définition de la manière dont les évaluations hors de contrôle ont été arrêtées:

Dans une connexion curieuse, dans la représentation computationnelle de la physique dans notre récent Projet Physique, l’analogie directe des évaluations non terminées est ce qui rend possible l’univers apparemment sans fin dans lequel nous vivons.
Mais que se passe-t-il réellement “à l’intérieur d’une évaluation”, qu’elle soit terminée ou non? J’ai toujours voulu une bonne représentation de ceci. Et en fait, dès la Version 2.0, nous avons introduit Trace à cette fin:

Mais quelle quantité de détails sur ce que fait l’évaluateur devrait-on montrer ? Déjà dans la Version 2.0, nous avons introduit l’option TraceOriginal qui trace chaque chemin suivi par l’évaluateur:

Mais souvent, cela est beaucoup trop détaillé. Et dans la Version 14.0, nous avons introduit le nouveau paramètre TraceOriginal→Automatic, qui n’inclut pas dans sa sortie les évaluations qui ne font rien:

Cela peut sembler pointilleux, mais lorsque l’on a une expression d’une taille substantielle, c’est une pièce cruciale d’élagage. Ainsi, par exemple, voici une représentation graphique d’une simple évaluation arithmétique, avec TraceOriginal→True:

Et voici la version “élaguée” correspondante, avec TraceOriginal→Automatic:

(Et oui, les structures de ces graphes sont étroitement liées à des choses comme les graphes causaux que nous construisons dans notre Projet Physique.)
Dans l’effort d’ajouter des primitives computationnelles au Langage Wolfram, deux nouveaux arrivants dans la Version 14.0 sont Comap et ComapApply. La fonction Map prend une fonction f et la “mappe” sur une liste:

Comap fait la version “mathématiquement co-” de ceci, prenant une liste de fonctions et les “comappant” sur un seul argument:

Pourquoi est-ce utile ? Par exemple, on pourrait vouloir appliquer trois fonctions statistiques différentes à une seule liste. Et maintenant, c’est facile à faire, en utilisant Comap:

Au fait, comme avec Map, il y a aussi une forme d’opérateur pour Comap:

Comap fonctionne bien lorsque les fonctions avec lesquelles il travaille prennent juste un argument. Si l’on a des fonctions qui prennent plusieurs arguments, ComapApply est ce que l’on veut typiquement:

En parlant de fonctions “co-like”, une nouvelle fonction ajoutée dans la Version 13.2 est PositionSmallest. Min donne le plus petit élément dans une liste ; PositionSmallest dit plutôt où se trouvent les plus petits éléments:

Un des objectifs importants dans le Langage Wolfram est que le plus de choses possible “fonctionnent simplement”. Lorsque nous avons publié la Version 1.0, on pouvait supposer que les chaînes de caractères contenaient simplement des caractères ASCII ordinaires, ou peut-être qu’elles avaient un codage de caractères externe défini. Et, oui, cela pouvait être désordonné de ne pas savoir “à l’intérieur de la chaîne de caractères” quels caractères étaient censés s’y trouver. Et au moment de la Version 3.0 en 1996, nous étions devenus contributeurs et premiers utilisateurs d’Unicode, qui fournissait un codage standard pour “16 bits de caractères”. Et pendant de nombreuses années, cela nous a bien servi. Mais avec le temps – et particulièrement avec la croissance des emoji – 16 bits ne suffisaient pas à coder tous les caractères que les gens voulaient utiliser. Ainsi, il y a quelques années, nous avons commencé à déployer le support pour Unicode sur 32 bits, et dans la Version 13.1, nous l’avons intégré dans les notebooks – faisant en effet des chaînes de caractères quelque chose de bien plus riche qu’auparavant :

Et, oui, vous pouvez désormais utiliser Unicode partout:

Vidéo comme Objet Fondamental
Lorsque la Version 1.0 a été publiée, un mégaoctet représentait beaucoup de mémoire. Mais 35 ans plus tard, nous traitons régulièrement avec des gigaoctets. Et l’une des choses qui rend cela pratique, c’est le traitement vidéo. Nous avons d’abord introduit la vidéo de manière expérimentale dans la Version 12.1 en 2020. Et au cours des trois dernières années, nous avons systématiquement élargi et renforcé notre capacité à travailler avec la vidéo dans le langage Wolfram. Probablement le progrès le plus important est que les choses autour de la vidéo fonctionnent maintenant, autant que possible, sans “grincer” sous la pression de la manipulation de quantités aussi importantes de données.
Nous pouvons capturer directement de la vidéo dans des notebooks, et nous pouvons lire de la vidéo de manière robuste n’importe où dans un notebook. Nous avons également ajouté des options pour stocker la vidéo de manière à ce qu’elle soit facilement accessible pour vous et toute personne à qui vous souhaitez donner accès.
L’encodage vidéo est très complexe, et nous prenons désormais en charge de manière robuste et transparente plus de 500 codecs. Nous faisons également beaucoup de choses pratiques automatiquement, comme la rotation des vidéos en mode portrait, et la possibilité d’appliquer des opérations de traitement d’image comme ImageCrop sur des vidéos entières. À chaque nouvelle version, nous optimisons davantage la vitesse d’une opération vidéo ou d’une autre.
Mais un point particulièrement important a été les générateurs vidéo : des moyens programmables de produire des vidéos et des animations. Un exemple de base est AnimationVideo, qui produit le même type de sortie qu’Animate, mais sous la forme d’un objet Video qui peut être affiché directement dans un notebook, ou exporté en MP4 ou dans un autre format.

AnimationVideo est basé sur le calcul de chaque image dans une vidéo en évaluant une expression. Une autre classe de générateurs vidéo prend une construction visuelle existante et la “parcourt” simplement. TourVideo “parcourt” des images, des graphiques et des géographiques ; Tour3DVideo (nouveau dans la Version 14.0) parcourt une géométrie en 3D.

Une capacité très puissante dans le langage Wolfram est la possibilité d’appliquer des fonctions arbitraires aux vidéos. Un exemple de la manière dont cela peut être fait est VideoFrameMap, qui applique une fonction à travers les images d’une vidéo, et qui a été rendu efficace dans la Version 13.2.
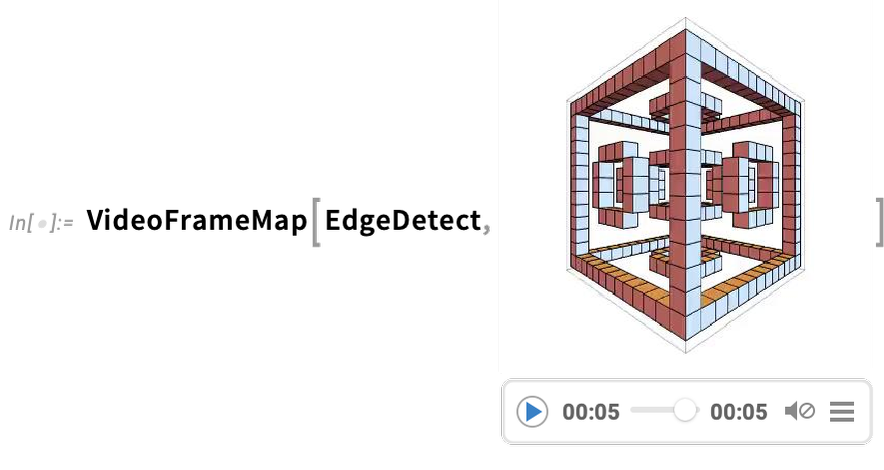
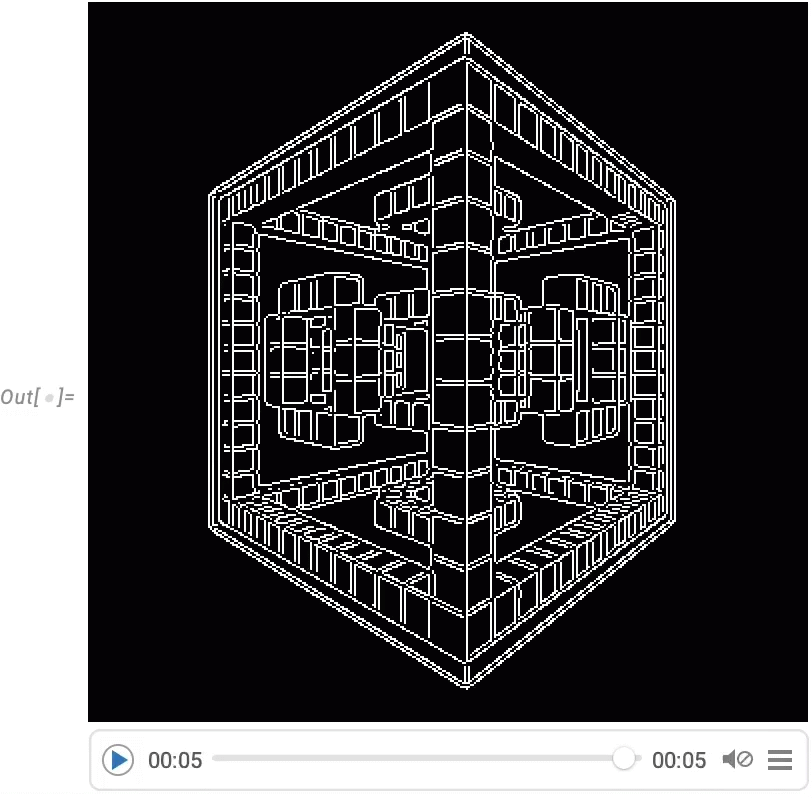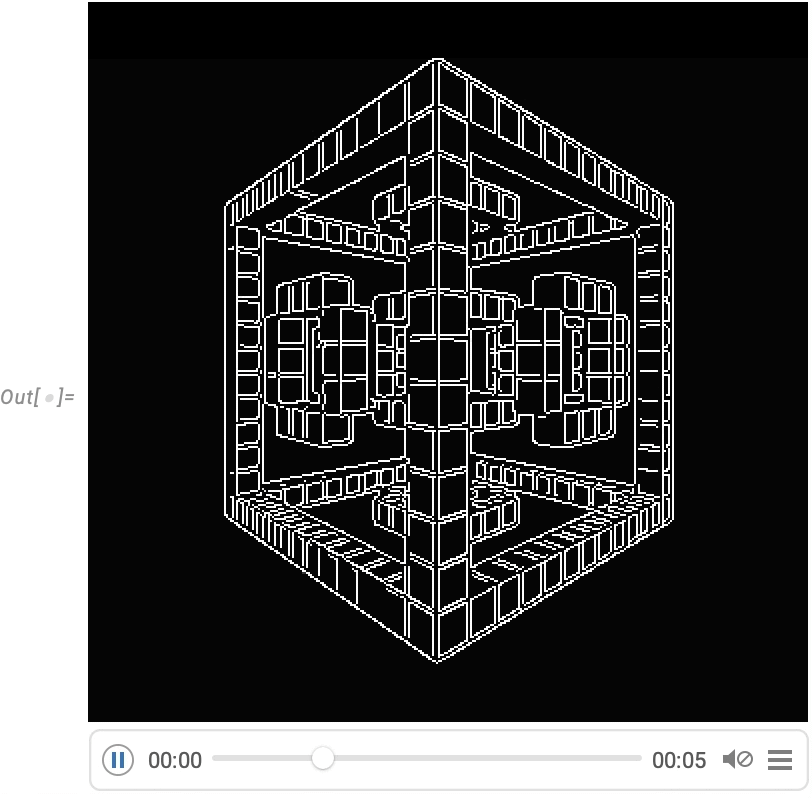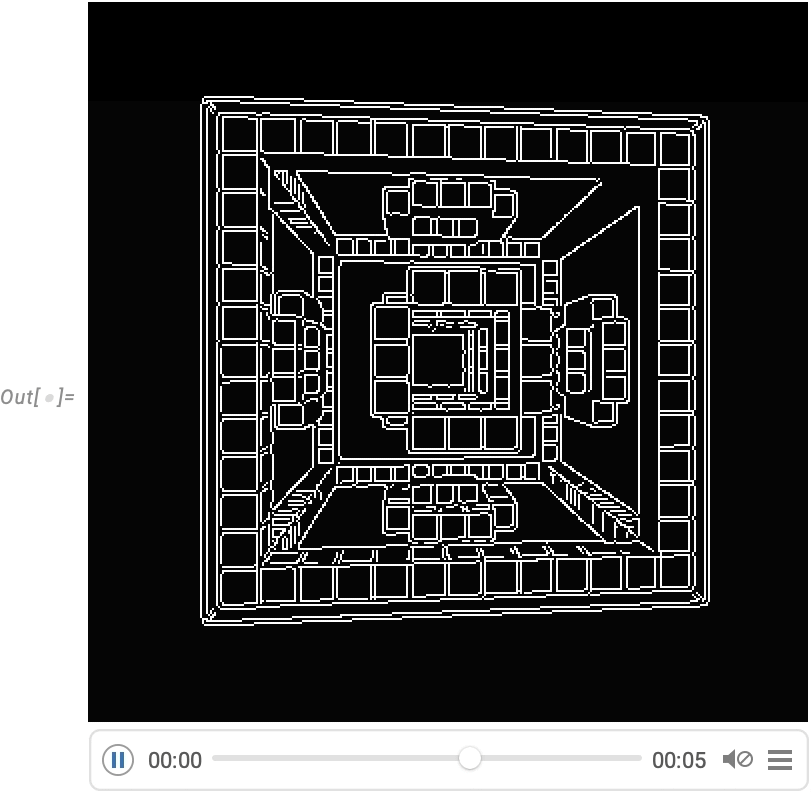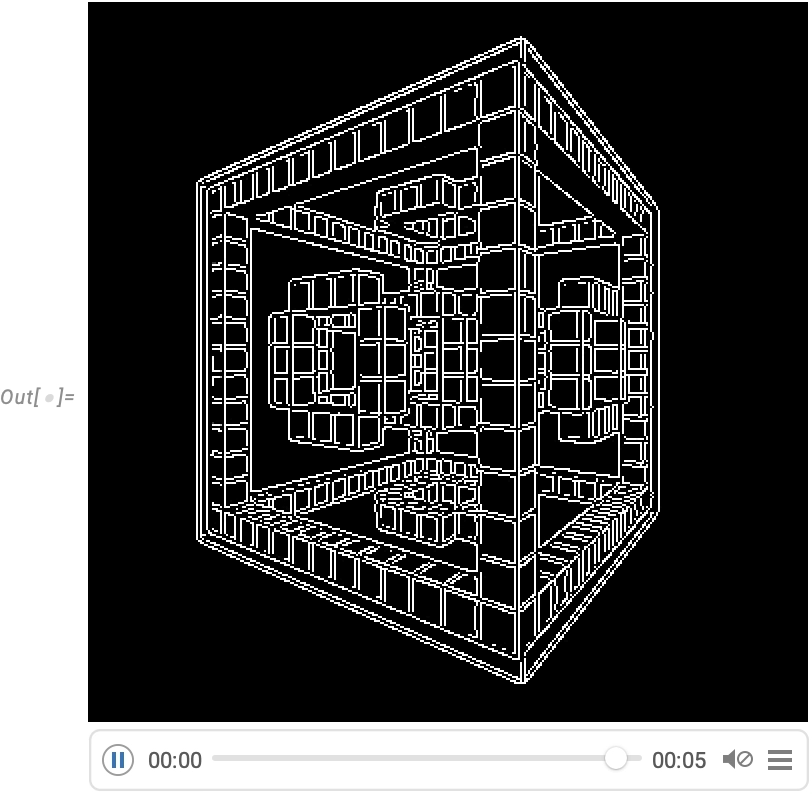
Et bien que le langage Wolfram ne soit pas conçu comme un système de montage vidéo interactif, nous avons veillé à ce qu’il soit possible d’effectuer un montage vidéo programmé de manière rationalisée dans le langage, et par exemple dans la Version 14.0 nous avons ajouté des effets de transition dans VideoJoin et des superpositions synchronisées dans OverlayVideo.
Tant de choses sont devenues plus rapides, plus puissantes, plus élégantes
À chaque nouvelle version du langage Wolfram, nous ajoutons de nouvelles fonctionnalités pour étendre encore davantage le domaine du langage. Mais nous consacrons également beaucoup d’efforts à quelque chose de moins immédiatement visible : rendre les fonctionnalités existantes plus rapides, plus puissantes et plus élégantes.
Et dans la Version 14, deux domaines où nous pouvons voir des exemples de tout cela sont les dates et les quantités. Nous avons introduit la notion de dates symboliques (DateObject, etc.) il y a près d’une décennie. Au fil des années depuis lors, nous avons construit de nombreuses choses sur cette structure. Et au cours de ce processus, il est devenu clair qu’il existe certains flux et chemins particulièrement communs et pratiques. Au début, ce qui importait le plus était de s’assurer que la fonctionnalité pertinente existait. Mais au fil du temps, nous avons pu identifier ce qui devait être simplifié et optimisé, et nous avons progressivement fait cela.
De plus, alors que nous travaillions sur de nouvelles applications différentes, nous avons identifié des “coins” à remplir. Par exemple, l’astronomie est un domaine que nous avons significativement développé dans la Version 14, et le support de l’astronomie a nécessité l’ajout de plusieurs nouvelles capacités de temps “haute précision”, telles que l’option TimeSystem, ainsi que de nouveaux systèmes de calendriers orientés astronomie. Un autre exemple concerne l’arithmétique des dates. Que se passe-t-il si vous souhaitez ajouter un mois au 30 janvier ? Où devriez-vous atterrir ? Différents types d’applications commerciales et de contrats font des suppositions différentes, et donc nous avons ajouté une option Method aux fonctions comme DatePlus pour gérer cela. Pendant ce temps, ayant réalisé que l’arithmétique des dates est impliquée dans la “boucle interne” de certaines computations, nous l’avons optimisée, obtenant un gain de vitesse de plus de 100 fois dans la Version 14.0.
Wolfram|Alpha a été capable de gérer les unités depuis son lancement initial en 2009—maintenant plus de 10 000 d’entre elles. Et en 2012, nous avons introduit Quantity pour représenter les quantités avec des unités dans le langage Wolfram. Au cours de la dernière décennie, nous avons progressivement lissé toute une série de complications et de problèmes liés aux unités. Par exemple, que signifie 100 °C + 20 °C ? Eh bien, les 20 °C ne sont pas vraiment du même type que les 100 °C. Et maintenant dans le langage Wolfram, nous disposons d’une manière systématique de gérer cela, en distinguant les unités de température et de différence de température—de sorte que nous écrivons maintenant 100 °C + 20 °C.
Au début, notre priorité avec Quantity était de le faire fonctionner aussi largement que possible, et de l’intégrer aussi largement que possible dans les calculs, les visualisations, etc. à travers le système. Mais à mesure que ses capacités se sont étendues, ses utilisations se sont également multipliées, ce qui a souvent conduit à la nécessité d’optimiser son fonctionnement pour des cas particuliers courants. En effet, entre la Version 13 et la Version 14, nous avons considérablement accéléré de nombreuses choses liées à Quantity, souvent par des facteurs de 1000 ou plus.
Parlant d’accélérations, un autre exemple—rendu possible par de nouveaux algorithmes opérant sur des processeurs multi-thread—concerne les polynômes. Nous travaillons avec des polynômes dans le langage Wolfram depuis la Version 1, mais dans la Version 13.2, il y a eu une accélération spectaculaire pouvant atteindre 1000 fois sur des opérations comme la factorisation de polynômes.
De plus, un nouvel algorithme dans la Version 14.0 accélère considérablement les solutions numériques aux équations polynomiales et transcendantales—et, associé aux nouvelles options MaxRoots, nous permet par exemple de sélectionner quelques racines d’un polynôme de degré un million
ou pour trouver les racines d’une équation transcendante que nous n’aurions même pas pu essayer auparavant sans spécifier au préalable des bornes sur leurs valeurs:

Un autre “ancien” élément de fonctionnalité avec une amélioration récente concerne les fonctions mathématiques. Depuis la Version 1.0, nous avons mis en place les fonctions mathématiques de sorte qu’elles puissent être calculées avec une précision arbitraire :
![]()
Mais dans les versions récentes, nous avons souhaité être “plus précis sur la précision”, et pouvoir calculer rigoureusement quelle plage de sorties est possible compte tenu de la plage de valeurs fournies en entrée.
![]()
Mais chaque fonction pour laquelle nous faisons cela nécessite effectivement un nouveau théorème, et nous avons progressivement augmenté le nombre de fonctions couvertes—maintenant plus de 130—de sorte que cela “fonctionne” lorsque vous en avez besoin dans un calcul.
L’histoire de l’arbre continue
Les arbres sont utiles. Nous les avons introduits pour la première fois comme objets de base dans le langage Wolfram seulement dans la Version 12.3. Mais maintenant qu’ils sont là, nous découvrons de plus en plus d’endroits où ils peuvent être utilisés. Et pour les soutenir, nous ajoutons de plus en plus de fonctionnalités à ces objets.
Un domaine qui a beaucoup évolué depuis la Version 13 est le rendu des arbres. Nous avons amélioré le design graphique général, mais surtout, nous avons introduit de nombreuses nouvelles options pour définir comment le rendu doit être réalisé.
Par exemple, voici un arbre aléatoire où nous avons spécifié que seuls 3 enfants doivent être affichés explicitement pour tous les nœuds : les autres sont cachés :

Voici comment nous ajoutons plusieurs options pour définir le rendu de l’arbre :

Par défaut, les branches dans les arbres sont étiquetées avec des entiers, tout comme les parties dans une expression. Mais dans la Version 13.1, nous avons ajouté la prise en charge des branches nommées définies par des associations:

Notre conception initiale des arbres était très centrée sur le fait d’avoir des éléments que l’on pourrait adresser explicitement et qui pourraient avoir des “charges utiles” attachées. Mais il est devenu évident qu’il y avait des applications où seule la structure de l’arbre importait, sans tenir compte de ses éléments. C’est pourquoi nous avons ajouté UnlabeledTree pour créer des “arbres purs”:

Les arbres sont utiles car de nombreux types de structures sont essentiellement des arbres. Et depuis la Version 13, nous avons ajouté des fonctionnalités permettant de convertir des arbres en différentes sortes de structures et vice versa. Par exemple, voici un objet Dataset simple:

Vous pouvez utiliser ExpressionTree pour convertir ceci en un arbre:

Et TreeExpression pour le convertir à nouveau:

Nous avons également ajouté des fonctionnalités pour convertir des données en JSON et XML, ainsi que pour représenter les structures de répertoires de fichiers sous forme d’arbres:

Champs Finis
Dans la Version 1.0, nous avions les entiers, les nombres rationnels et les nombres réels. Dans la Version 3.0, nous avons ajouté les nombres algébriques (représentés implicitement par Root)—et une douzaine d’années plus tard, nous avons ajouté les corps de nombres algébriques et les racines transcendantales. Pour la Version 14, nous avons maintenant ajouté une autre construction “liée aux nombres” tant attendue : les champs finis.
Voici notre représentation symbolique du champ des entiers modulo 7 :

Et maintenant voici un élément spécifique de ce champ:

que nous pouvons calculer immédiatement avec:

Mais ce qui est vraiment important dans ce que nous avons fait avec les champs finis, c’est que nous les avons pleinement intégrés à d’autres fonctions du système. Par exemple, nous pouvons factoriser un polynôme dont les coefficients sont dans un champ fini :

Nous pouvons également faire des choses comme trouver des solutions à des équations dans les champs finis. Donc, voici par exemple un point sur une courbe de Fermat sur le champ fini GF(173:

Et voici une puissance d’une matrice dont les éléments sont dans le même champ fini :

Partir Hors de la Planète: L’Histoire Astro
Une importante nouvelle fonctionnalité ajoutée depuis la Version 13 est le calcul astrologique. Cela commence par la capacité à calculer avec une grande précision les positions des planètes, entre autres choses. Même définir ce que l’on entend par “position” est compliqué, avec de nombreux systèmes de coordonnées différents à prendre en compte. Par défaut, AstroPosition fournit la position dans le ciel au moment actuel depuis votre emplacement Here:

Mais on peut aussi demander à propos d’un système de coordonnées différent, comme les coordonnées galactiques globales:

Et maintenant voici un graphique montrant la distance entre Saturne et Jupiter sur une période de 50 ans:

En analogie directe avec GeoGraphics, nous avons ajouté AstroGraphics, qui affiche ici un patch de ciel autour de la position actuelle de Saturne:

Et voici maintenant la séquence des positions de Saturne au cours de quelques années, incluant le mouvement rétrograde:

Il existe de nombreuses options de style pour AstroGraphics. Ici, nous ajoutons un fond de “ciel galactique”:

Et ici, nous incluons des représentations des constellations (et oui, nous avons fait appel à un artiste pour les dessiner):

Une nouveauté spécifique de la Version 14.0 concerne le traitement étendu des éclipses solaires. Nous nous efforçons toujours de fournir de nouvelles fonctionnalités aussi rapidement que possible. Mais dans ce cas, il y avait une date limite très spécifique : l’éclipse solaire totale visible depuis les États-Unis le 8 avril 2024. Nous avions déjà la capacité d’effectuer des calculs mondiaux sur les éclipses solaires depuis un certain temps (en fait, peu avant l’éclipse de 2017). Mais maintenant, nous pouvons également effectuer des calculs détaillés locaux directement dans le langage Wolfram.
Par exemple, voici une carte globale plutôt détaillée de l’éclipse du 8 avril 2024:

Maintenant, voici un graphique de l’amplitude de l’éclipse sur quelques heures, avec une petite “rampe” associée à la période de totalité:

Et voici une carte de la région de totalité chaque minute juste après le moment de l’éclipse maximale:

Des millions d’espèces deviennent calculables
Nous avons d’abord introduit des données calculables sur les organismes biologiques avec la sortie de Wolfram|Alpha en 2009. Mais dans la Version 14, après plusieurs années de travail, nous avons considérablement élargi et approfondi les données calculables que nous avons sur les organismes biologiques.
Par exemple, voici comment nous pouvons déterminer quelles espèces ont les guépards comme prédateurs:

Et voici des images de ces espèces:

Voici une carte des pays où des guépards ont été observés (dans la nature):

Nous disposons désormais de données, provenant de nombreuses sources, sur plus d’un million d’espèces animales, ainsi que sur la plupart des plantes, des champignons, des bactéries, des virus et des archées décrits. Pour les animaux, par exemple, nous disposons de près de 200 caractéristiques qui sont largement renseignées. Certaines sont des caractéristiques taxonomiques:

Certaines sont des caractéristiques physiques:


Certaines sont des caractéristiques génétiques:

Certaines sont des caractéristiques écologiques (oui, le guépard n’est pas le prédateur de sommet):

Il est utile de pouvoir obtenir des propriétés de chaque espèce individuelle, mais la véritable puissance de nos données calculables et organisées apparaît lorsque l’on effectue des analyses à plus grande échelle. Par exemple, voici un graphique des longueurs des génomes pour les organismes ayant les plus longs génomes dans notre collection d’organismes:

Ou voici un histogramme des longueurs de génome pour les organismes présents dans le microbiote intestinal humain:

Et voici un nuage de points représentant les durées de vie des oiseaux par rapport à leur poids:

Suivant l’idée que les guépards ne sont pas des prédateurs de sommet, voici un graphique de ce qui se trouve “au-dessus” d’eux dans la chaîne alimentaire:

Calcul Chimique
Nous avons commencé le processus d’introduction du calcul chimique dans le langage Wolfram avec la Version 12.0, et dès la Version 13, nous avions une bonne couverture des atomes, des molécules, des liaisons et des groupes fonctionnels. Maintenant, dans la Version 14, nous avons ajouté la prise en charge des formules chimiques, des quantités de produits chimiques, et des réactions chimiques.
Voici une formule chimique, qui donne essentiellement un “nombre d’atomes”:

Voici maintenant des molécules spécifiques correspondant à cette formule:

Choisissons l’une de ces molécules:

Maintenant, dans la Version 14, nous avons un moyen de représenter une certaine quantité de molécules d’un type donné, par exemple 1 gramme de méthylcyclopentane:

ChemicalConvert peut convertir vers une autre spécification de quantité, comme les moles:

Et ici, un décompte de molécules:

Maintenant, la grande nouveauté de la Version 14 est que nous pouvons représenter non seulement des types individuels de molécules et des quantités de molécules, mais aussi des réactions chimiques. Voici une représentation “approximative” et non équilibrée d’une réaction, et ReactionBalance nous donne la version équilibrée:

Maintenant, nous pouvons extraire les formules des réactifs:

Nous pouvons également représenter une réaction chimique en termes de molécules:

Avec notre représentation symbolique des molécules et des réactions, il y a maintenant une grande chose que nous pouvons faire : représenter des classes de réactions sous forme de “réactions de motif”, et travailler avec elles en utilisant les mêmes concepts que ceux que nous utilisons pour travailler avec des motifs pour les expressions générales. Par exemple, voici une représentation symbolique de la réaction d’hydrohalogénation:

Maintenant, nous pouvons appliquer cette réaction de motif à des molécules particulières:

Voici un exemple plus élaboré, dans ce cas saisi à l’aide d’une chaîne SMARTS:

Ici, nous appliquons la réaction une seule fois:

Et maintenant, nous le faisons de manière répétée:
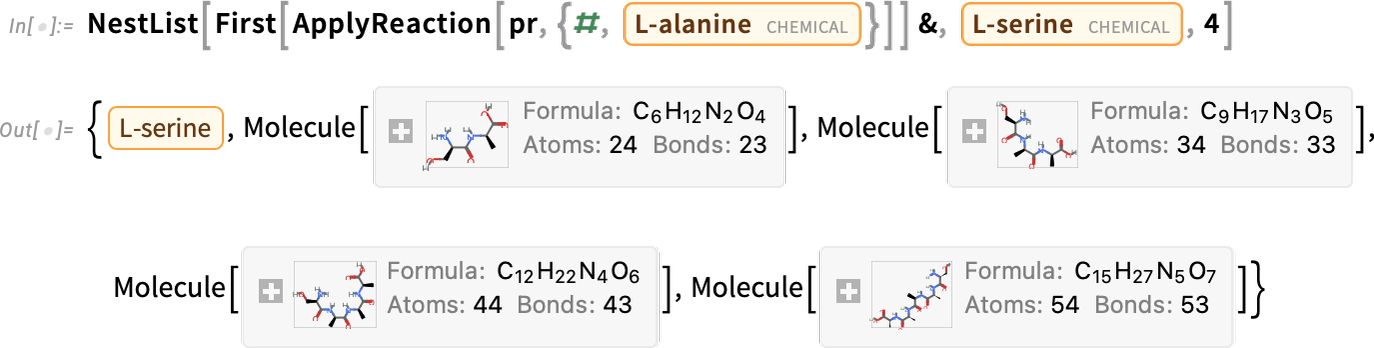
Dans ce cas, cela génère des molécules de plus en plus longues (qui, dans ce cas, se trouvent être des polypeptides):

La base de connaissances ne cesse de s’agrandir
La base de connaissances Wolfram continue de croître chaque minute, avec de nouvelles données ajoutées en permanence à partir de flux en temps réel. Une grande partie de ces données est collectée automatiquement, mais nous avons également un effort continu de curation à grande échelle impliquant des experts humains. Au fil des années, nous avons développé une automatisation sophistiquée en langage Wolfram pour notre pipeline de curation des données, et cette année, nous avons pu accroître l’efficacité dans certains domaines en utilisant la technologie LLM. Cependant, il est difficile de faire de la curation de manière appropriée, et notre expérience à long terme montre qu’il est essentiel d’avoir des experts humains impliqués dans le processus, ce que nous avons.
Alors, qu’est-ce qui est nouveau depuis la Version 13.0 ? 291 842 nouveaux personnages notables actuels et historiques ; 264 467 œuvres musicales ; 118 538 albums musicaux ; 104 024 étoiles nommées, et ainsi de suite. Parfois, l’ajout d’une entité est motivé par la disponibilité de nouvelles données fiables ; souvent, cela est motivé par le besoin d’utiliser cette entité dans une autre fonctionnalité (par exemple, les étoiles à afficher dans AstroGraphics). Mais plus que simplement ajouter des entités, il y a la question de compléter les valeurs des propriétés des entités existantes. Et là encore, nous progressons toujours, parfois en intégrant de nouvelles sources de données secondaires à grande échelle, et parfois en effectuant nous-mêmes la curation à partir de sources primaires.
Un exemple récent où nous avons dû faire une curation directe était dans les données sur les boissons alcoolisées. Nous disposons de données très étendues sur des centaines de milliers de types d’aliments et de boissons. Mais aucune de nos sources à grande échelle n’incluait des données sur les boissons alcoolisées. C’est donc un domaine où nous devons aller aux sources primaires (dans ce cas, généralement les producteurs originaux des produits) et tout curater nous-mêmes.
Ainsi, par exemple, nous pouvons maintenant demander quelque chose comme la répartition des saveurs des différentes variétés de vodka (personnellement, n’étant pas consommateur de ce type de produits, je ne savais même pas que la vodka avait des saveurs…):

Mais au-delà de compléter les entités et les propriétés des types existants, nous avons également régulièrement ajouté de nouveaux types d’entités. Un exemple récent est celui des formations géologiques, au nombre de 13,706:

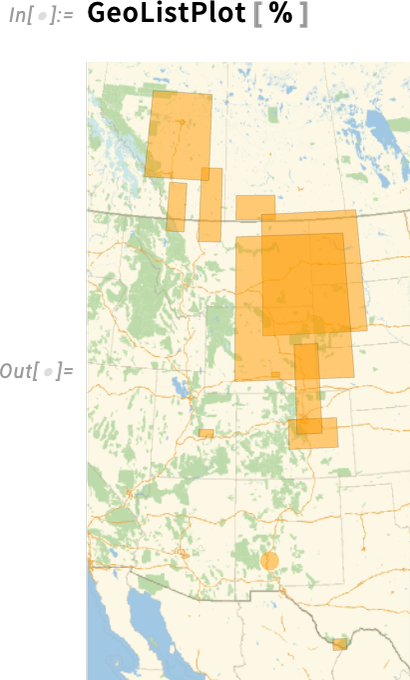
Maintenant, par exemple, nous pouvons spécifier où les T. rex ont été trouvés

et nous pouvons afficher ces régions sur une carte:
Industrial-Strength Multidomain PDEs
Les équations aux dérivées partielles (EDP) sont difficiles. Il est difficile de les résoudre. Et il est difficile même de spécifier précisément ce que vous voulez résoudre. Mais nous sommes engagés dans une mission de plusieurs décennies pour rendre les EDP plus accessibles et plus faciles à manipuler. De nombreux éléments contribuent à cela. Vous devez pouvoir spécifier facilement des géométries élaborées. Vous devez pouvoir définir facilement des conditions aux limites mathématiquement compliquées. Vous devez disposer d’un moyen efficace de mettre en place les équations complexes résultant de la physique sous-jacente. Ensuite, vous devez, aussi automatiquement que possible, effectuer une analyse numérique sophistiquée pour résoudre efficacement les équations. Mais ce n’est pas tout. Vous devez également souvent visualiser votre solution, calculer d’autres quantités à partir de celle-ci ou optimiser des paramètres.
C’est une utilisation profonde de ce que nous avons construit avec le langage Wolfram, impliquant de nombreuses parties du système. Et le résultat est quelque chose d’unique : une manière vraiment simplifiée et intégrée de manipuler les EDP. On ne traite pas d’un package (généralement très coûteux) “juste pour les EDP” ; ce que nous avons maintenant est une façon “consumerisée” de manipuler les EDP chaque fois qu’ils sont nécessaires, que ce soit en ingénierie, en science ou autre. Et oui, être capable de connecter l’apprentissage automatique, ou le traitement d’images, ou des données organisées, ou la science des données, ou des flux de capteurs en temps réel, ou le calcul parallèle, ou, en l’occurrence, les notebooks Wolfram, aux EDP les rend encore plus précieux.
Nous avons eu “NDSolve de base, brut” depuis 1991. Mais ce qui a pris des décennies à construire, c’est toute la structure autour de cela qui permet de configurer de manière pratique, et de résoudre efficacement, des EDP du monde réel, et de les connecter à tout le reste. Cela a nécessité le développement d’une tour entière de capacités algorithmiques sous-jacentes telles que notre géométrie computationnelle industrielle, plus flexible et intégrée que jamais, ainsi que les méthodes d’éléments finis. Mais au-delà de cela, il a fallu créer un langage pour spécifier des EDP du monde réel. Et c’est là que la nature symbolique du langage Wolfram – et tout notre cadre de conception – a rendu possible quelque chose de très unique, qui nous a permis de simplifier et de “consumeriser” de manière spectaculaire l’utilisation des EDP.
Il s’agit de fournir des “kits de construction” symboliques pour les EDP et leurs conditions aux limites. Nous avons commencé cela il y a environ cinq ans, en couvrant progressivement de plus en plus de domaines d’application. Dans la Version 14, nous nous sommes particulièrement concentrés sur la mécanique des solides, la mécanique des fluides, l’électromagnétisme et la mécanique quantique (d’un seul particule).
Voici un exemple de mécanique des solides. Tout d’abord, nous définissons les variables avec lesquelles nous travaillons (déplacement et coordonnées sous-jacentes):
Ensuite, nous spécifions les paramètres que nous voulons utiliser pour décrire le matériau solide avec lequel nous allons travailler:
![]()
Nous pouvons désormais configurer notre PDE (en utilisant des spécifications PDE symboliques telles que SolidMechanicsPDEComponent) ici pour la déformation d’un objet solide tiré sur un côté:

Et, oui, “en dessous”, ces simples spécifications symboliques se transforment en une PDE “brute” compliquée:
Nous sommes maintenant prêts à résoudre réellement notre PDE dans une région particulière, c’est-à-dire pour un objet avec une forme particulière:

Et maintenant, nous pouvons visualiser le résultat, qui montre comment notre objet se déforme lorsqu’il est étiré:
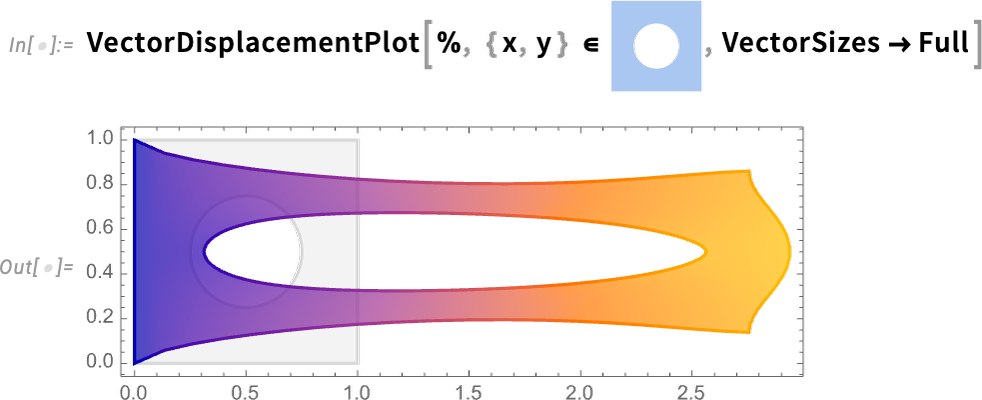
La façon dont nous avons configuré les choses, le matériau de notre objet est une idéalisation de quelque chose comme le caoutchouc. Mais dans le langage Wolfram, nous avons maintenant des moyens de spécifier toutes sortes de propriétés détaillées des matériaux. Par exemple, nous pouvons ajouter un renforcement sous forme d’un vecteur unitaire dans une direction particulière (par exemple, en pratique avec des fibres) à notre matériau:
![]()
Ensuite, nous pouvons réexécuter ce que nous avons fait précédemment:
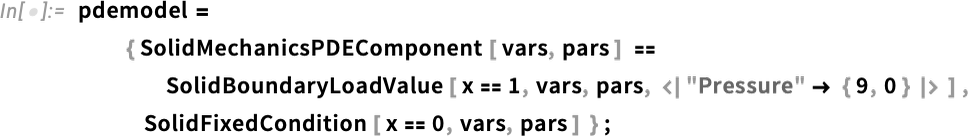
mais maintenant nous obtenons un résultat légèrement différent:
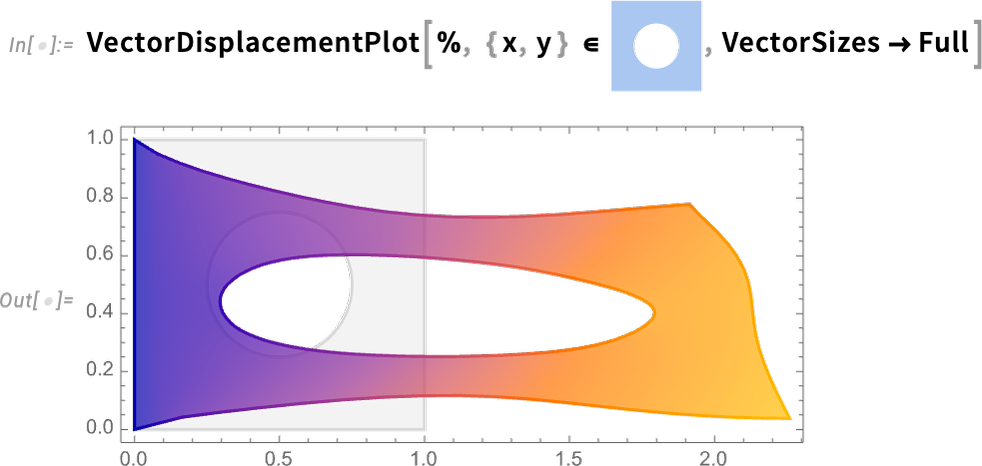
Un autre domaine PDE majeur qui est nouveau dans la version 14.0 est l’écoulement des fluides. Faisons un exemple 2D. Nos variables sont la vitesse et la pression 2D:
![]()
Nous pouvons désormais installer notre système fluide dans une région particulière, avec des conditions antidérapantes sur tous les murs, sauf en haut, où nous supposons que le fluide s’écoule de gauche à droite. Le seul paramètre nécessaire est le nombre de Reynolds. Et au lieu de simplement résoudre nos PDE pour un seul nombre de Reynolds, créons un solveur paramétrique qui peut prendre n’importe quel nombre de Reynolds spécifié:

Voici le résultat pour un nombre de Reynolds de 100:
Mais avec la configuration que nous avons mise en place, nous pouvons également générer une vidéo complète en fonction du nombre de Reynolds (et, oui, l’utilisation de Parallelize accélère les choses en générant différents images en parallèle) :

Une grande partie de notre travail en EDP consiste à répondre aux complexités des situations d’ingénierie du monde réel. Mais dans la Version 14.0, nous ajoutons également des fonctionnalités pour prendre en charge la “physique pure”, et en particulier pour prendre en charge la mécanique quantique avec l’équation de Schrödinger. Voici, par exemple, l’équation de Schrödinger à une particule en 2D (avec ![]() ):
):

Voici la région sur laquelle nous allons résoudre l’équation, montrant une discrétisation explicite:
Maintenant, nous pouvons résoudre l’équation en ajoutant quelques conditions aux limites:
Maintenant, nous pouvons visualiser un paquet d’ondes gaussien se dispersant autour d’une barrière:
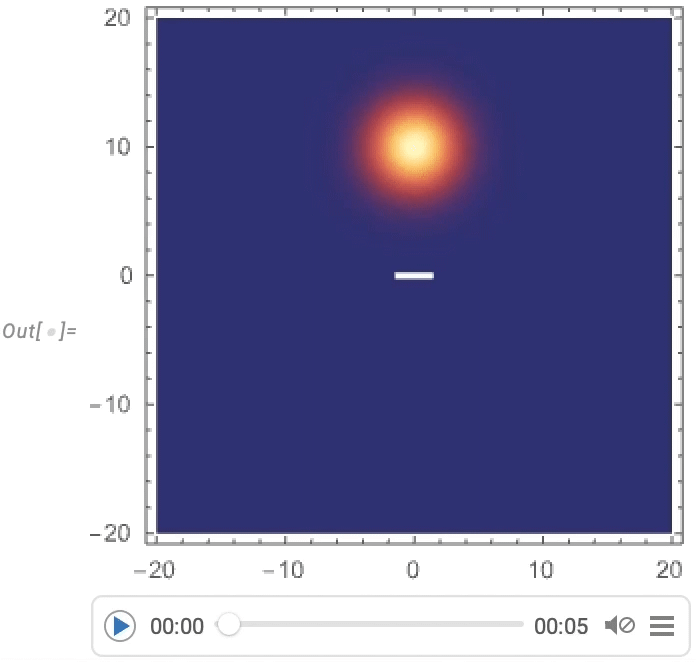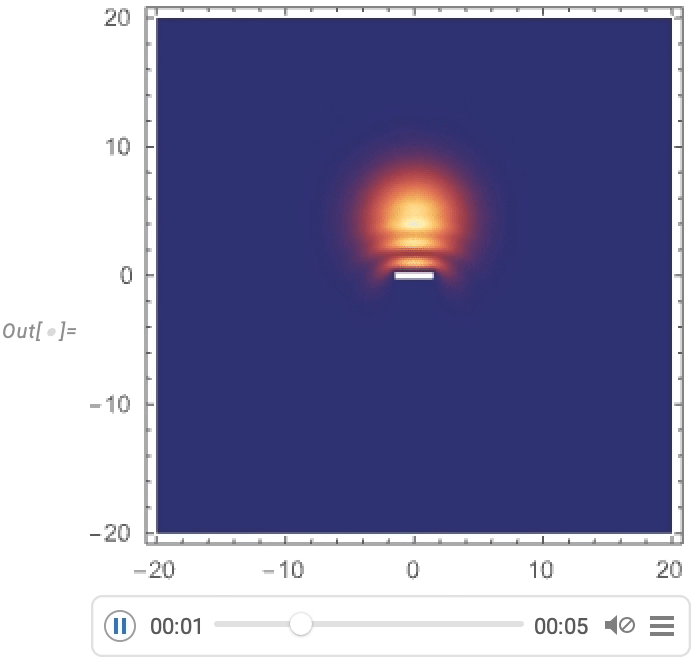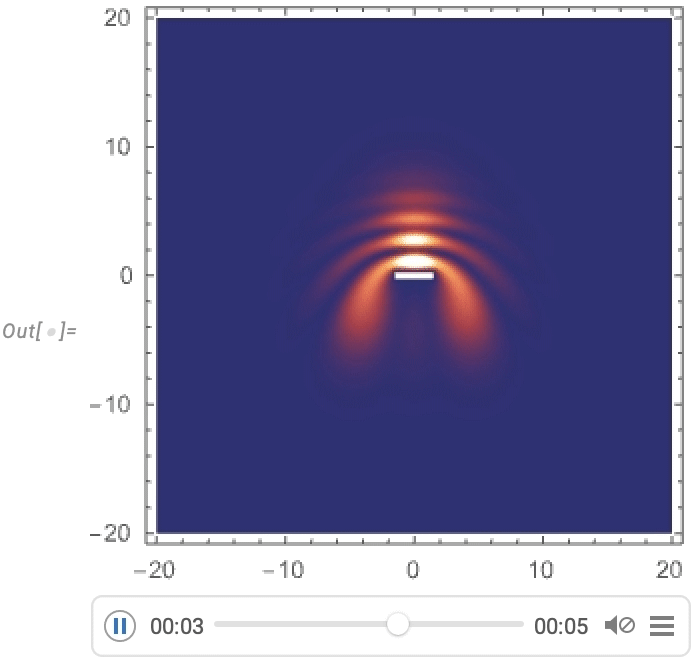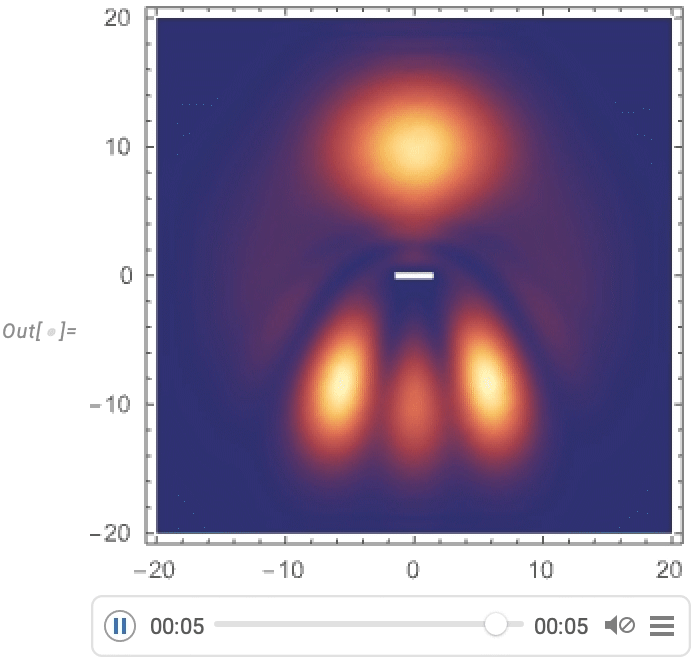
Streamlining Systems Engineering Computation
L’ingénierie des systèmes est un vaste domaine, mais c’est un domaine où la structure et les capacités du langage Wolfram offrent des avantages uniques qui, au cours de la dernière décennie, nous ont permis de développer un support industriel assez complet pour la modélisation, l’analyse et la conception de contrôle pour une large gamme de types de systèmes. Tout cela fait partie intégrante du langage Wolfram, accessible via la structure computationnelle et l’interface du langage. Mais cela est également intégré à notre produit distinct, le Modélisateur de Systèmes Wolfram, qui offre un flux de travail basé sur une interface graphique pour la modélisation et l’exploration de systèmes.
Partagées avec le Modélisateur de Systèmes se trouvent de vastes collections de bibliothèques de modélisation spécifiques à des domaines. Par exemple, depuis la Version 13, nous avons ajouté des bibliothèques dans des domaines tels que l’ingénierie des batteries, l’ingénierie hydraulique et l’ingénierie aéronautique, ainsi que des bibliothèques éducatives pour l’ingénierie mécanique, l’ingénierie thermique, l’électronique numérique et la biologie. (Nous avons également ajouté des bibliothèques pour des domaines tels que la simulation des affaires et des politiques publiques.)

Un flux de travail typique pour l’ingénierie des systèmes commence par la création d’un modèle. Le modèle peut être construit à partir de zéro ou assemblé à partir de composants dans des bibliothèques de modèles, soit de manière visuelle dans le Modélisateur de Systèmes Wolfram, soit de manière programmative dans le langage Wolfram. Par exemple, voici un modèle d’un moteur électrique qui entraîne une charge à travers un arbre flexible:
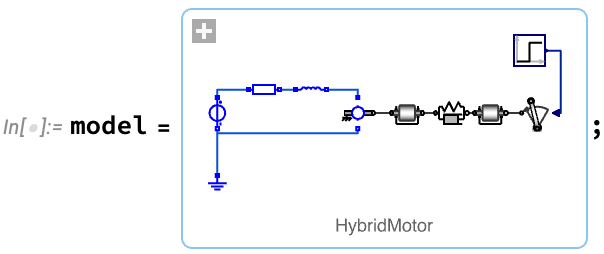
Une fois que l’on a un modèle, on peut ensuite le simuler. Voici un exemple où nous avons défini un paramètre de notre modèle (le moment d’inertie de la charge), et nous calculons les valeurs de deux autres en fonction du temps:
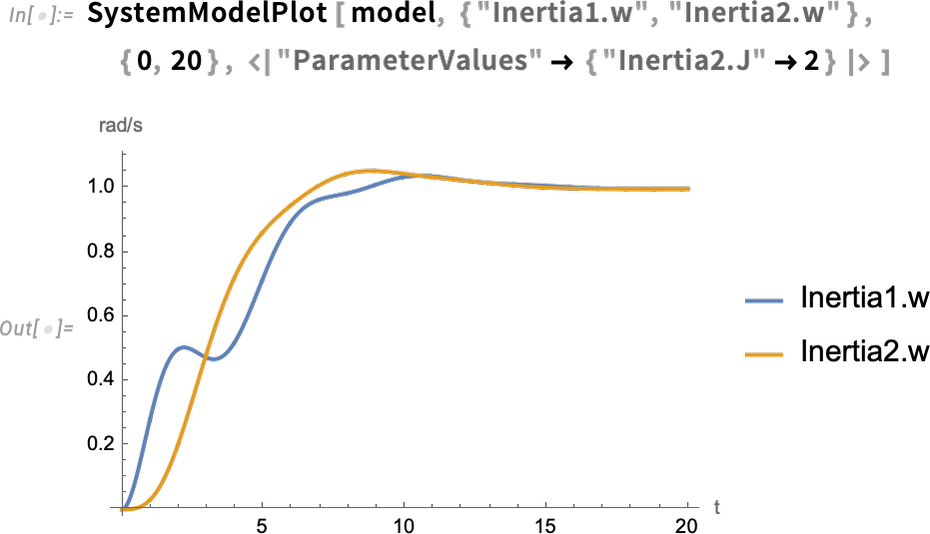
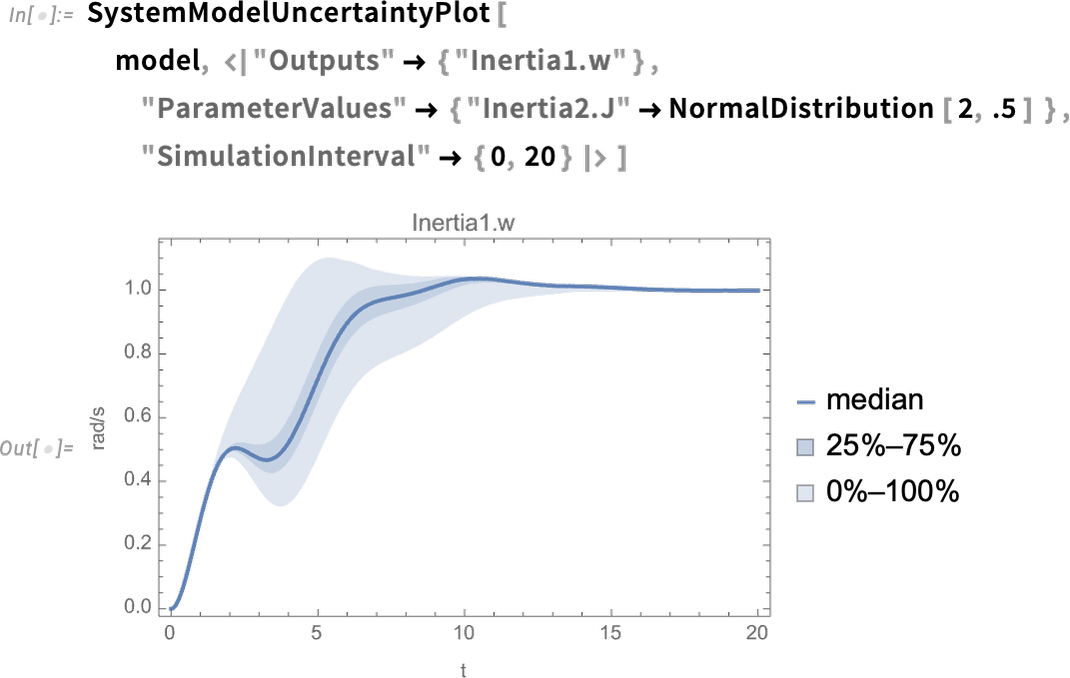
Une nouvelle fonctionnalité dans la version 14.0 permet de visualiser l’effet de l’incertitude sur les paramètres (ou les valeurs initiales, etc.) sur le comportement d’un système. Par exemple, nous spécifions que la valeur du paramètre n’est pas définie de manière précise, mais suit une distribution normale. Ensuite, nous observons la distribution des résultats en sortie:
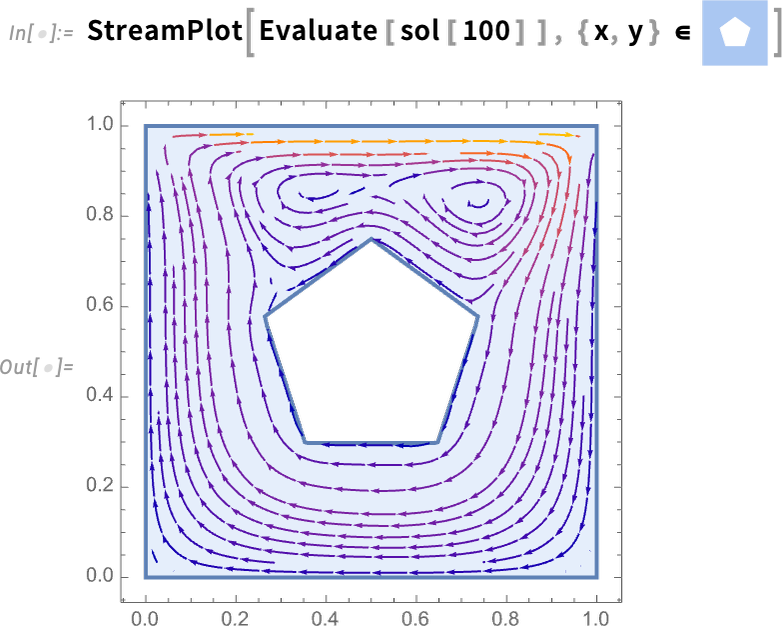
Le moteur avec arbre flexible que nous examinons peut être considéré comme un “système multidomaine”, combinant des composants électriques et mécaniques. Mais le langage Wolfram (et le Modélisateur de Systèmes Wolfram) peut également gérer des “systèmes mixtes”, combinant des composants analogiques et numériques (c’est-à-dire continus et discrets). Voici un exemple assez sophistiqué du monde des systèmes de contrôle : un modèle d’hélicoptère connecté en boucle fermée à un système de contrôle numérique:

Tout ce système de modèle peut être représenté de manière symbolique simplement par:
![]()
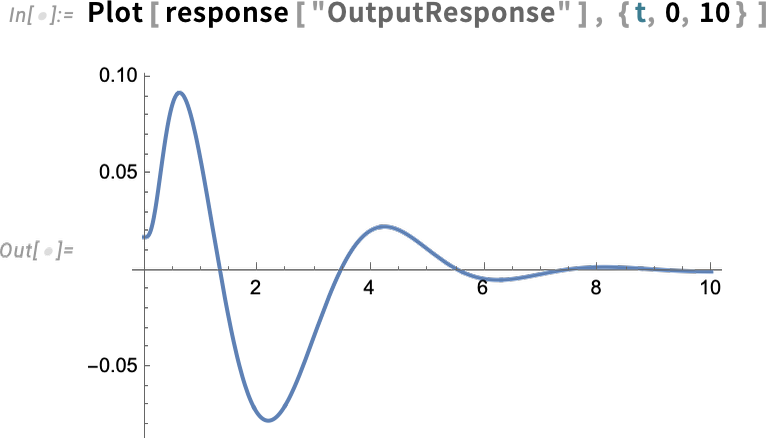
Et maintenant, nous calculons la réponse entrée-sortie du modèle:

Voici spécifiquement la réponse en sortie:
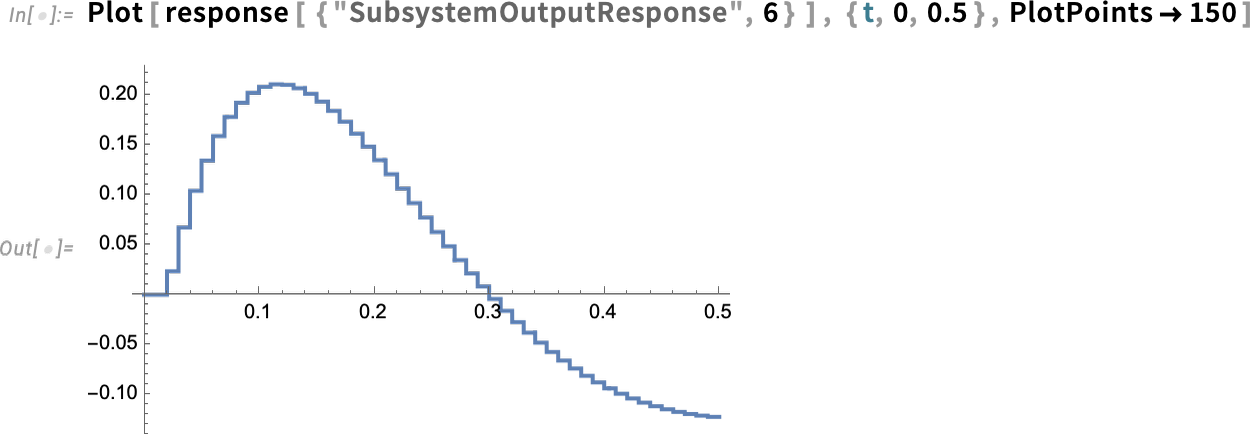
Maintenant, nous pouvons approfondir et voir les réponses spécifiques du sous-système, ici du dispositif de maintien d’ordre zéro (étiqueté ZOH ci-dessus) – avec ses petits pas numériques:
Mais que se passe-t-il si nous voulons concevoir nous-mêmes les systèmes de contrôle ? Eh bien, dans la Version 14, nous pouvons désormais appliquer toutes nos fonctionnalités de conception de systèmes de contrôle du langage Wolfram à des modèles de système arbitraires. Voici un exemple d’un modèle simple, dans ce cas en génie chimique (un réservoir agité en continu):

Maintenant, nous pouvons prendre ce modèle et concevoir un régulateur LQG pour celui-ci, puis assembler un système complet en boucle fermée pour celui-ci:
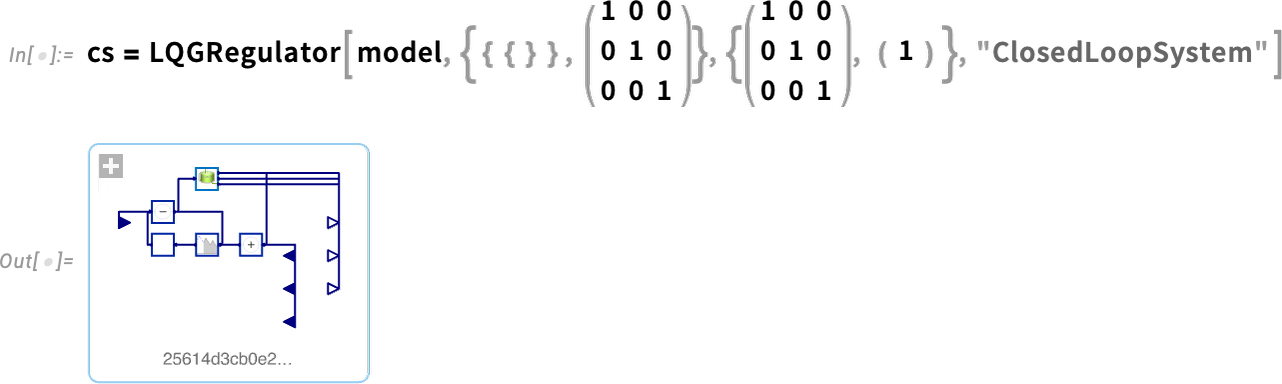
Maintenant, nous pouvons simuler le système en boucle fermée et constater que le régulateur parvient à amener la valeur finale à 0:
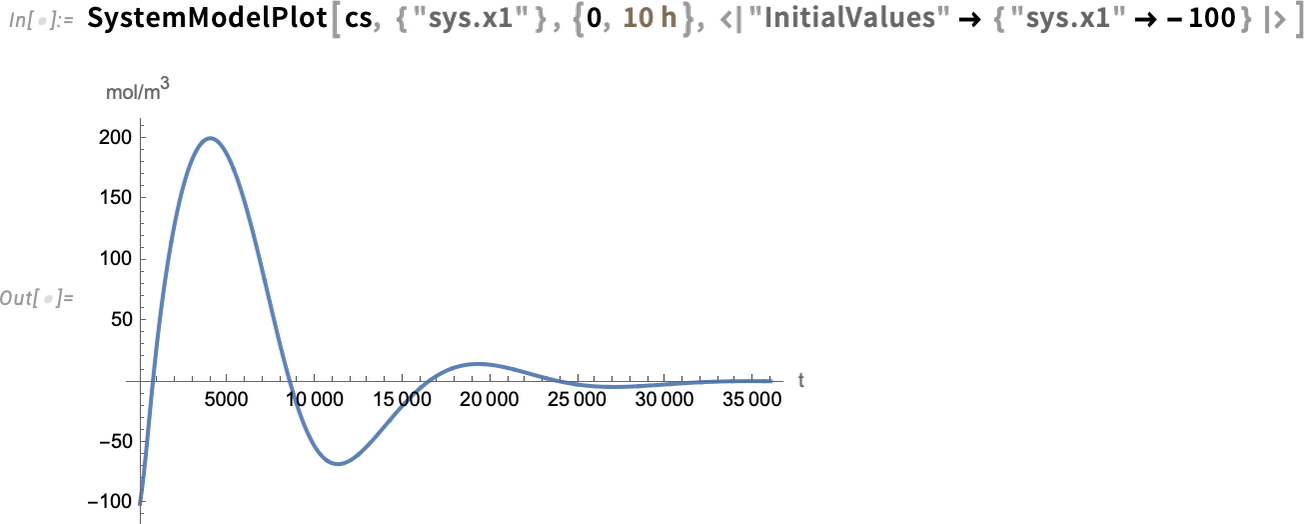
Graphics: More Beautiful & Alive
Les graphiques ont toujours été une part importante de l’histoire du langage Wolfram, et depuis plus de trois décennies, nous avons progressivement amélioré et mis à jour leur apparence et leur fonctionnalité, parfois avec l’aide des progrès des capacités matérielles (par exemple, GPU).
Depuis la Version 13, nous avons ajouté une variété d’effets “décoratifs” (ou “annotatifs”) dans les graphiques 2D. Un exemple (utile pour ajouter des légendes sur les éléments) est l’effet de “halo”:

Un autre exemple est l’effet de “DropShadowing”:

Tous ces effets sont spécifiés de manière symbolique et peuvent être utilisés dans tout le système (par exemple, dans les effets de survol, etc.). Et oui, il existe de nombreux paramètres détaillés que vous pouvez définir:
Une nouvelle capacité significative dans la version 14.0 est le mappage de textures pratique. Nous avions des textures au niveau des polygones depuis une décennie et demie. Mais maintenant, dans la version 14.0, nous avons rendu simple le mappage de textures sur des surfaces entières. Voici un exemple d’application d’une texture sur une sphère:

Et voici l’application de la même texture sur une surface plus complexe:

Une subtilité importante est qu’il existe de nombreuses façons de mapper ce qui revient à des “patches de coordonnées de texture” sur des surfaces. La documentation illustre de nouveaux cas nommés:

Et voici ce qui se passe avec une projection stéréographique sur une sphère:

Voici un exemple de “texture de surface” pour la planète Vénus

et ici, il a été mappé sur une sphère, qui peut être tournée:


Voici un lapin “fleurisé”:

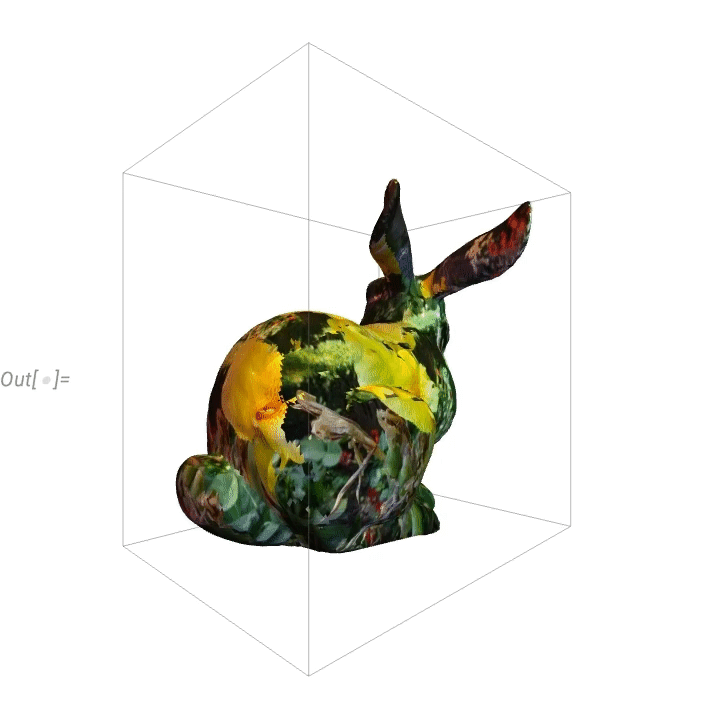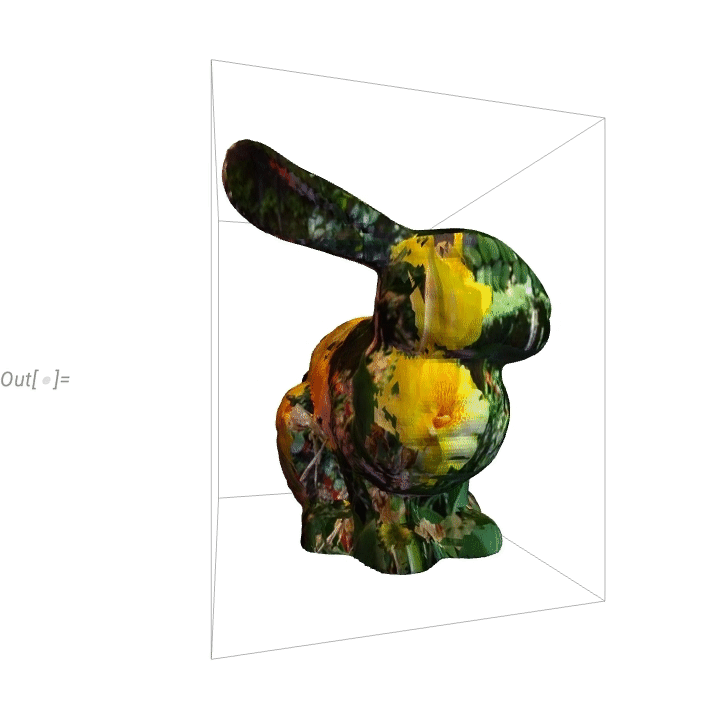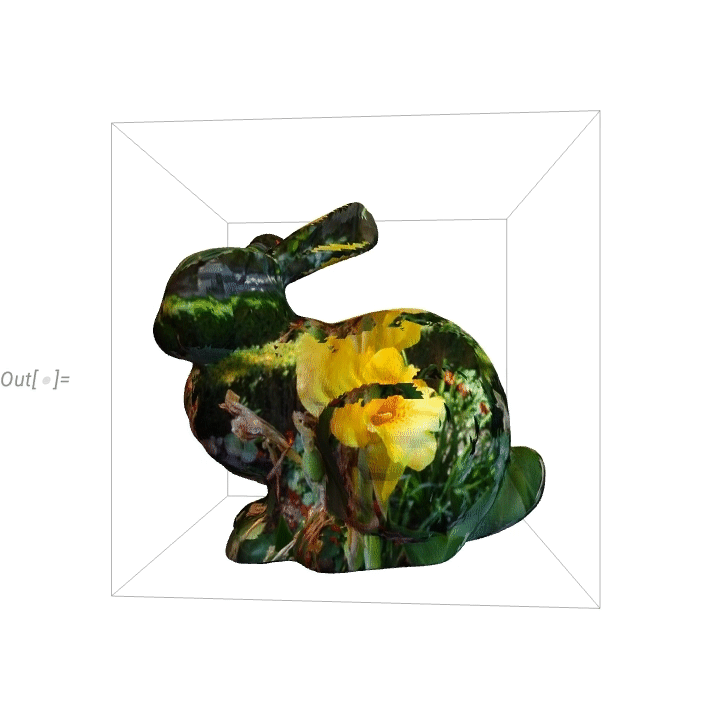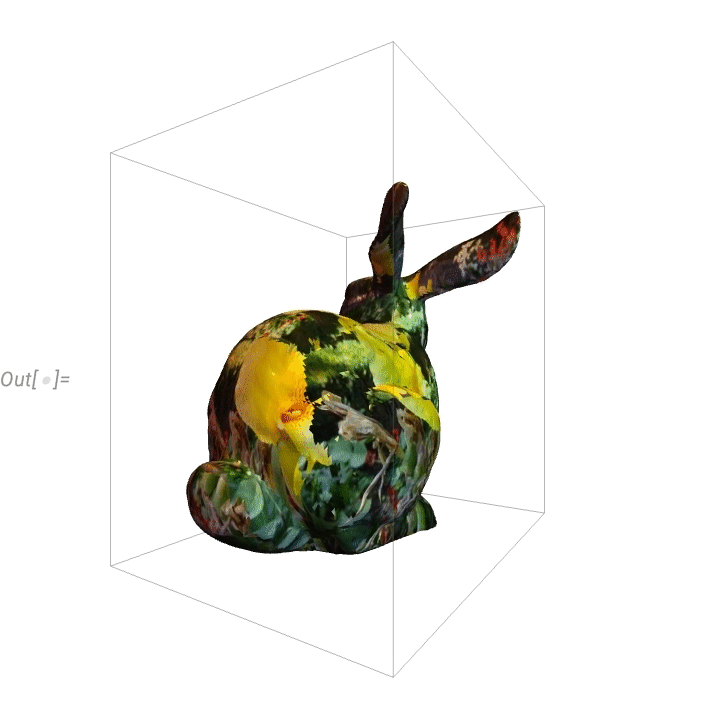
Des fonctionnalités telles que le mappage de texture contribuent à rendre les graphiques visuellement attrayants. Depuis la Version 13, nous avons également ajouté diverses capacités de “visualisation en direct” qui permettent automatiquement de “donner vie aux visualisations”. Par exemple, tout tracé a maintenant par défaut une “surbrillance au survol de la souris”:
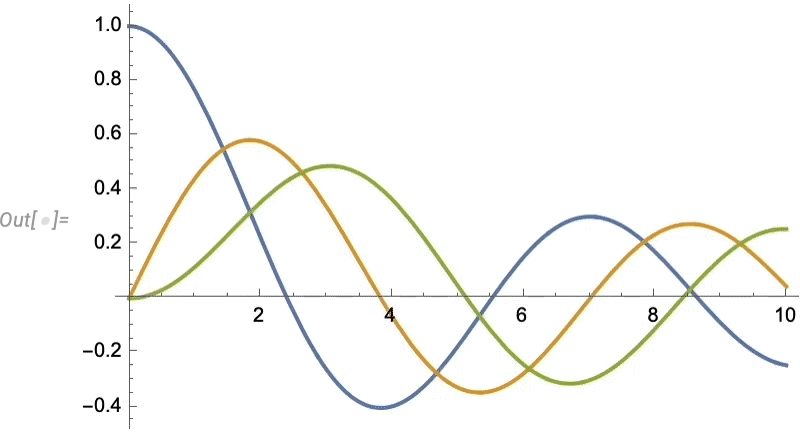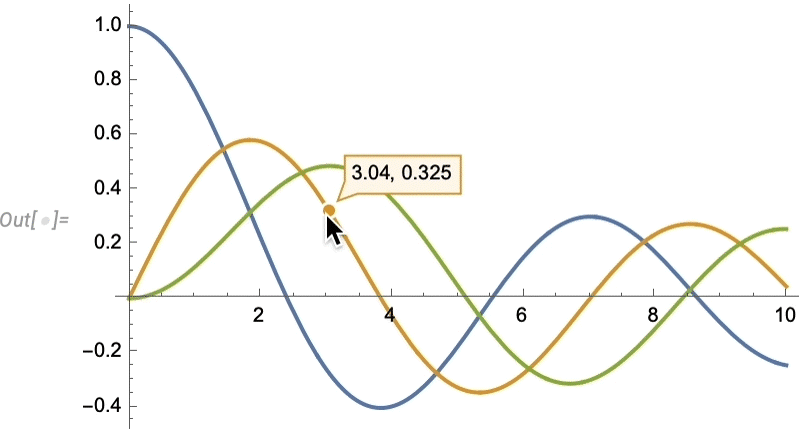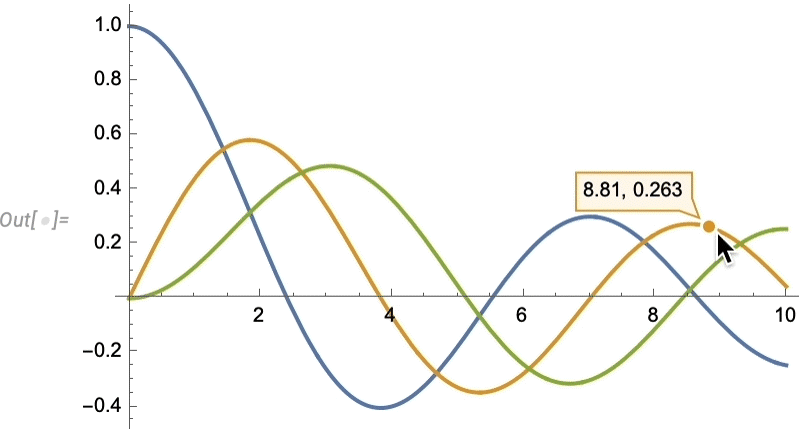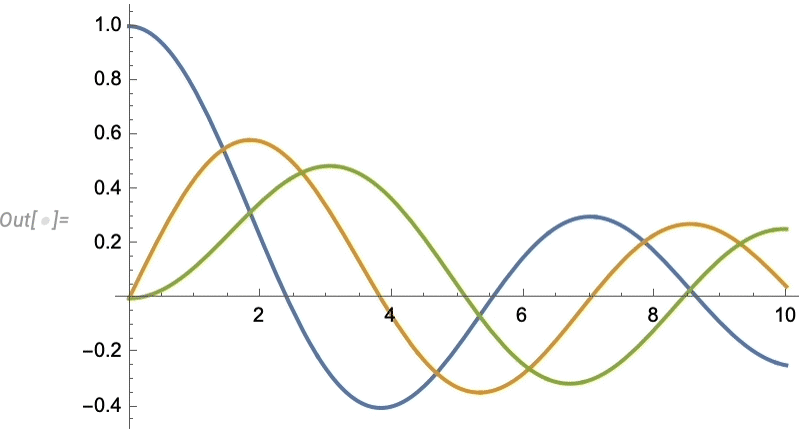
Comme d’habitude, il existe de nombreuses façons de contrôler de tels effets de “surbrillance”:

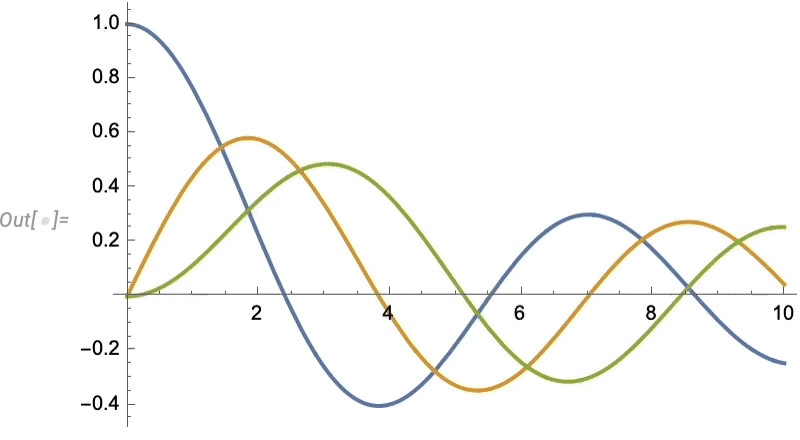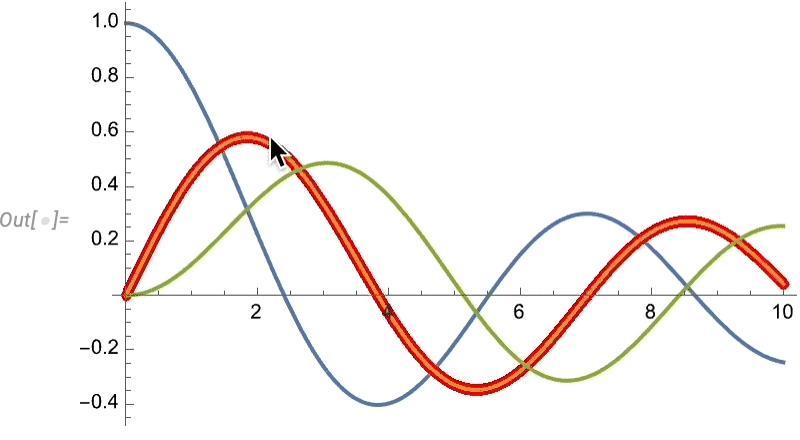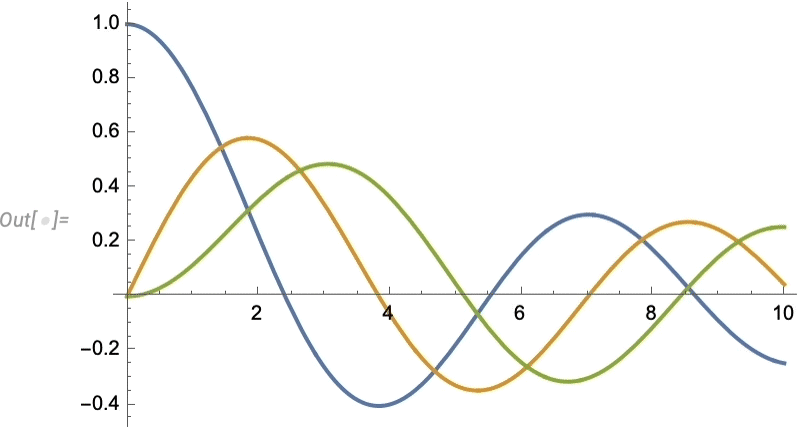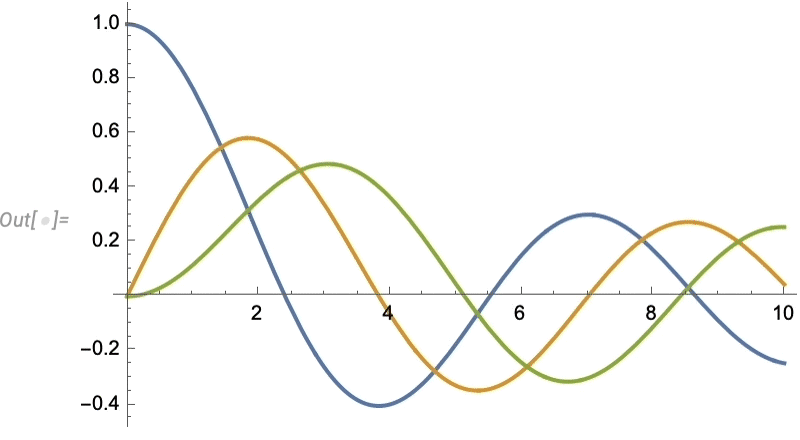

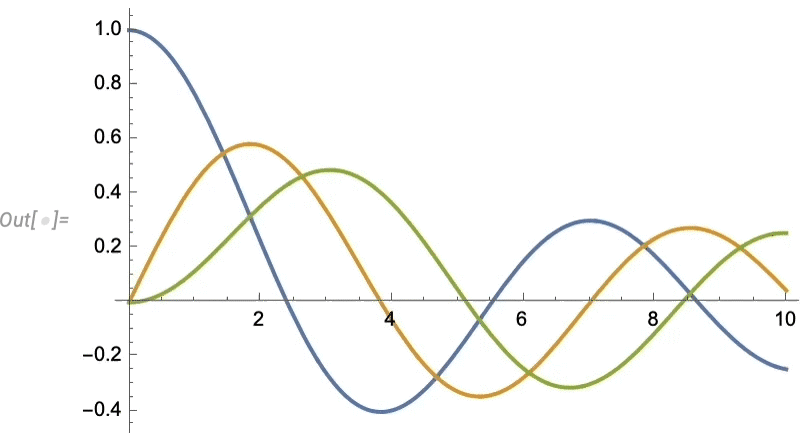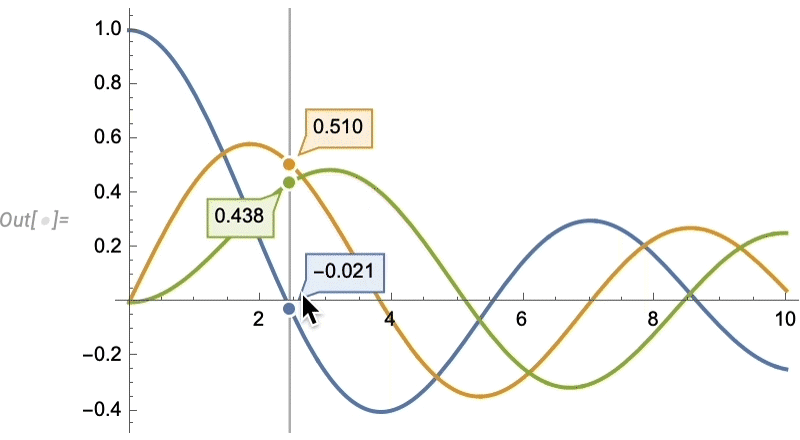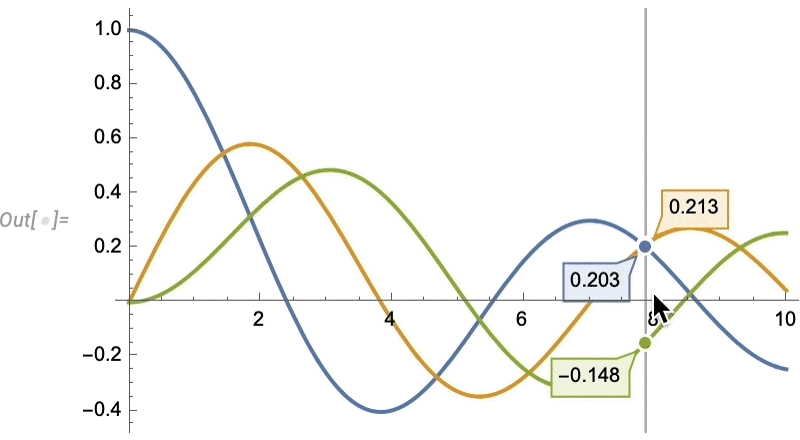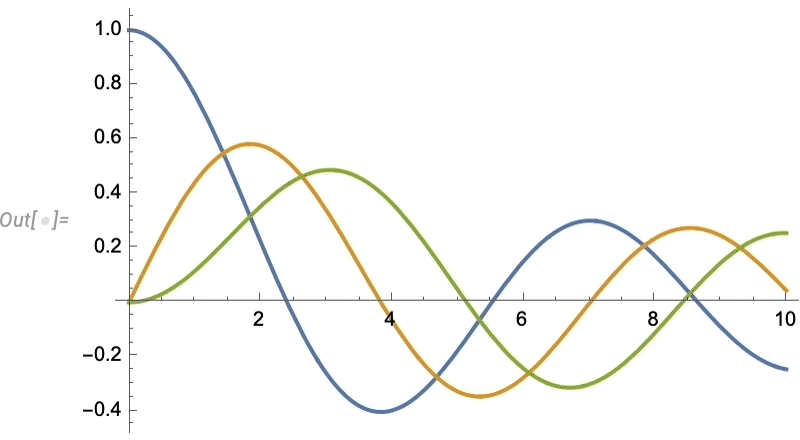
Euclid Redux: l’avancée de la géométrie synthétique
On pourrait dire que cela a pris deux mille ans à réaliser. Mais il y a quatre ans (Version 12), nous avons commencé à introduire une version calculable de la géométrie synthétique de style Euclide.
L’idée est de spécifier des scènes géométriques de manière symbolique en donnant une collection de contraintes (potentiellement implicites)

Nous pouvons ensuite générer une instance aléatoire de géométrie cohérente avec les contraintes, et dans la version 14, nous avons considérablement amélioré notre capacité à garantir que la géométrie sera “typique” et non dégénérée:

Mais maintenant, une nouvelle fonctionnalité de la version 14 est que nous pouvons trouver les valeurs des grandeurs géométriques déterminées par les contraintes:

Voici un cas légèrement plus compliqué:

Et ici, nous résolvons maintenant pour les aires de deux triangles dans la figure:

Nous avons toujours pu spécifier des styles explicites pour des éléments particuliers d’une scène:
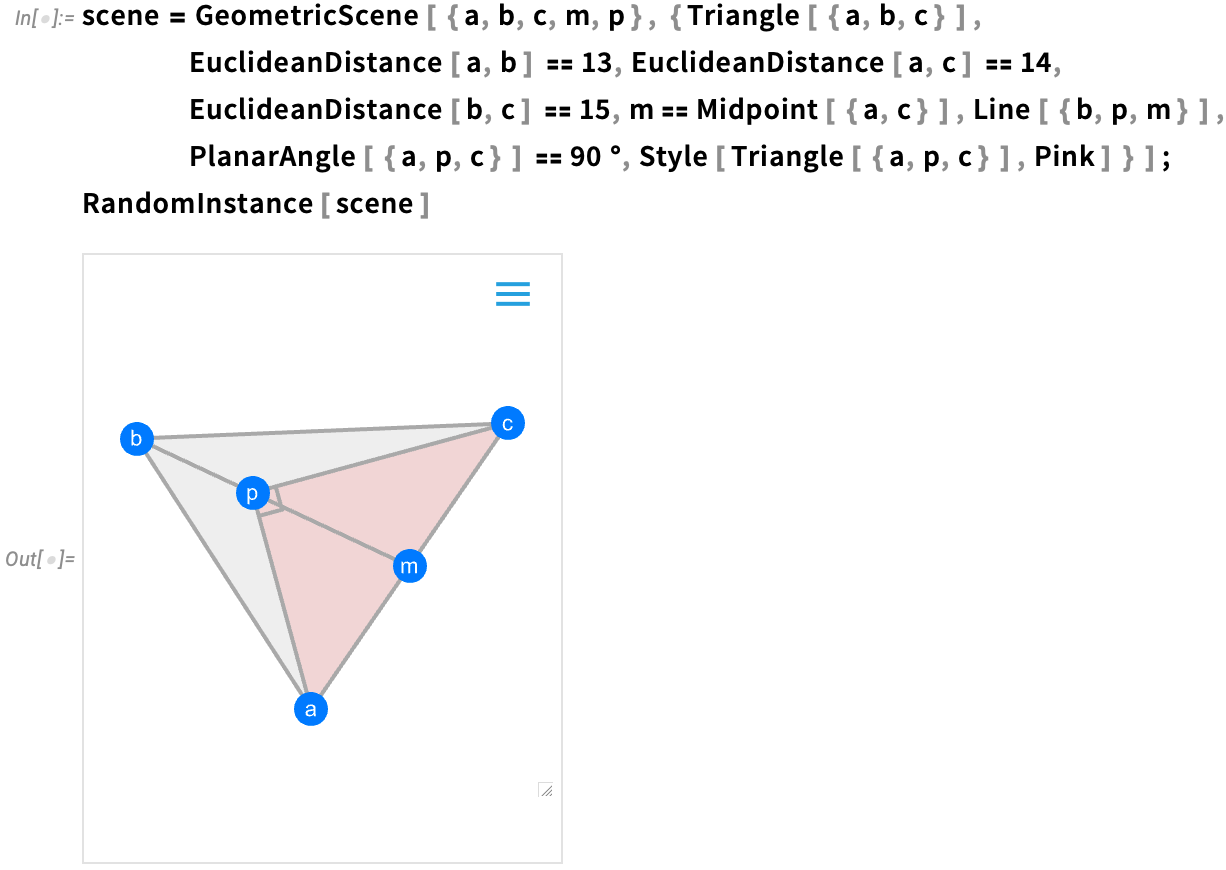
L’une des nouvelles fonctionnalités de la Version 14 est la possibilité de donner des “règles de style géométrique” générales, ici en attribuant simplement des couleurs aléatoires à chaque élément:

The Ever-Smoother User Interface
Notre objectif avec le langage Wolfram est de le rendre aussi facile que possible à exprimer de manière computationnelle. Une grande partie de cet objectif passe par la conception cohérente du langage lui-même. Mais il y a aussi un autre aspect, qui est la capacité à saisir effectivement l’entrée Wolfram Language que l’on souhaite, par exemple dans un notebook, aussi facilement que possible. Et à chaque nouvelle version, nous apportons des améliorations à cet égard.
Un domaine qui n’a cessé d’évoluer est la coloration syntaxique interactive. Nous avons ajouté la coloration syntaxique il y a près de deux décennies, et au fil du temps, nous l’avons rendue de plus en plus sophistiquée, réagissant à mesure que vous tapez et que le code s’exécute. Certains types de coloration ont toujours eu une signification évidente. Mais la coloration, en particulier celle qui est dynamique et basée sur la position du curseur, a parfois été plus difficile à interpréter. Et dans la Version 14, en tirant parti des palettes de couleurs plus lumineuses qui sont devenues la norme ces dernières années, nous avons ajusté notre coloration dynamique de manière à ce qu’il soit plus facile de savoir rapidement “où vous en êtes” dans la structure d’une expression:

En ce qui concerne “savoir ce que l’on a”, une autre amélioration ajoutée dans la Version 13.2 est la coloration différenciée des cadres pour différents types d’objets visuels dans les notebooks. Est-ce un graphique ? Ou une image ? Ou un graphe ? Maintenant, on peut le savoir d’après la couleur du cadre lorsqu’on le sélectionne:

Un aspect important du langage Wolfram est que les noms des fonctions intégrées sont suffisamment explicites pour qu’il soit facile de comprendre ce qu’elles font. Cependant, souvent les noms sont donc nécessairement assez longs, il est donc important de pouvoir les compléter automatiquement lorsqu’on les tape. Dans la version 13.3, nous avons ajouté la notion de “complétion floue” qui non seulement “complète jusqu’à la fin” un nom que l’on tape, mais peut également remplir les lettres intermédiaires, changer la casse, etc. Ainsi, par exemple, il suffit de taper “lll” pour faire apparaître un menu de complétion automatique qui commence par “ListLogLogPlot”:

Une mise à jour majeure de l’interface utilisateur apparue pour la première fois dans la Version 13.1, et améliorée dans les versions suivantes, est une barre d’outils par défaut pour chaque notebook:
![]()
La barre d’outils offre un accès immédiat aux contrôles d’évaluation, au formatage des cellules et à divers types de saisie (comme les cellules en ligne, ![]() , les hyperliens, le canevas de dessin, etc.), ainsi qu’à des fonctionnalités telles
, les hyperliens, le canevas de dessin, etc.), ainsi qu’à des fonctionnalités telles ![]() que la publication dans le cloud,
que la publication dans le cloud, ![]() la recherche dans la documentation et les paramètres de
la recherche dans la documentation et les paramètres de ![]() “chat” (c’est-à-dire LLM).
“chat” (c’est-à-dire LLM).
La plupart du temps, il est utile d’avoir la barre d’outils affichée dans n’importe quel notebook avec lequel vous travaillez. Cependant, sur le côté gauche, ![]() il y a une petite icône qui permet de réduire la barre d’outils
il y a une petite icône qui permet de réduire la barre d’outils

Dans la version 14.0, il y a un paramètre dans les Préférences qui permet de réduire la barre d’outils par défaut dans tout nouveau notebook que vous créez. Cela vous donne en fait le meilleur des deux mondes : vous avez un accès immédiat à la barre d’outils, mais vos notebooks n’ont rien de “supplémentaire” qui pourrait distraire de leur contenu.
Une autre fonctionnalité avancée depuis la Version 13 est la gestion des formes de sortie “résumé” dans les notebooks. Un exemple de base est ce qui se passe si vous générez un résultat très volumineux. Par défaut, seul un résumé du résultat est affiché. Mais maintenant, il y a une barre en bas qui propose différentes options pour gérer la sortie réelle:

Par défaut, la sortie n’est stockée que dans votre session noyau actuelle. Mais en appuyant sur le bouton Iconiser, vous obtenez une forme iconisée qui apparaîtra directement dans votre notebook (ou que vous pouvez copier n’importe où) et qui “contient toute la sortie à l’intérieur”. Il y a aussi un bouton Stocker l’expression complète dans le notebook, qui stockera “invisiblement” l’expression de sortie “derrière” l’affichage résumé.
Si l’expression est stockée dans le notebook, elle sera persistante entre les sessions noyau. Sinon, eh bien, vous ne pourrez pas y accéder dans une session noyau différente ; la seule chose que vous aurez est l’affichage résumé:

C’est une histoire similaire pour les “objets computationnels” volumineux. Par exemple, voici une fonction Nearest avec un million de points de données:
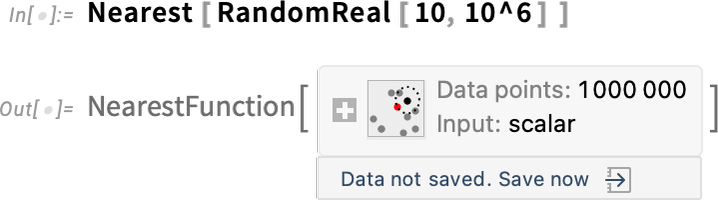
Par défaut, les données sont simplement présentes dans votre session noyau actuelle. Mais maintenant, il y a un menu qui vous permet de sauvegarder les données dans divers emplacements persistants:

Et il y a aussi le cloud
Il existe de nombreuses façons d’exécuter le langage Wolfram. Même dans la Version 1.0, nous avions la notion de noyaux distants : le front end du notebook s’exécutant sur une machine (à l’époque essentiellement toujours un Mac ou un NeXT), et le noyau s’exécutant sur une machine différente (à l’époque parfois même connectée par des lignes téléphoniques). Mais il y a une dizaine d’années, un grand pas en avant a été fait : le Wolfram Cloud.
Il y a vraiment deux façons distinctes d’utiliser le cloud. La première consiste à offrir une expérience de notebook similaire à notre expérience de bureau de longue date, mais fonctionnant entièrement dans un navigateur. Et la deuxième consiste à fournir des API et d’autres capacités accessibles de manière programmable—notamment, même au début, il y a une dizaine d’années, à travers des choses comme APIFunction.
Le Wolfram Cloud fait l’objet d’un développement intensif depuis près de 15 ans. À côté de celui-ci sont également venus le Wolfram Application Server et le Wolfram Web Engine, qui fournissent un support plus rationalisé spécifiquement pour les API (sans des éléments comme la gestion des utilisateurs, etc., mais avec des éléments comme le clustering).
Tous ces éléments—mais surtout le Wolfram Cloud—sont devenus des capacités technologiques centrales pour nous, soutenant bon nombre de nos autres activités. Ainsi, par exemple, le Wolfram Function Repository et le Wolfram Paclet Repository sont tous deux basés sur le Wolfram Cloud (et en fait, c’est vrai pour l’ensemble de notre système de ressources). Et lorsque nous sommes venus construire le plugin Wolfram pour ChatGPT plus tôt cette année, l’utilisation du Wolfram Cloud nous a permis de déployer le plugin en quelques jours seulement.
Depuis la Version 13, il y a eu plusieurs applications très différentes du Wolfram Cloud. L’une d’entre elles concerne la fonction ARPublish, qui prend une géométrie 3D et la place dans le Wolfram Cloud avec des métadonnées appropriées pour permettre aux téléphones d’obtenir des versions en réalité augmentée à partir d’un QR code d’une URL cloud:


Du côté des notebooks Cloud, il y a eu une augmentation constante de l’utilisation, notamment des notebooks Cloud intégrés, qui sont devenus courants sur Wolfram Community, et sont utilisés partout dans Wolfram Demonstrations Project. Notre objectif depuis le début a été de rendre les notebooks Cloud aussi faciles à utiliser que des pages web simples, mais avec la profondeur des fonctionnalités que nous avons développées dans les notebooks au cours des 35 dernières années. Nous avons atteint cet objectif il y a quelques années pour des notebooks assez petits, mais au cours des dernières années, nous avons progressivement étendu nos capacités pour gérer même des notebooks de plusieurs centaines de mégaoctets. C’est une histoire compliquée de mise en cache, de rafraîchissement—et d’évitement des vicissitudes des navigateurs web. Mais à ce stade, la grande majorité des notebooks peuvent être déployés sans problème sur le cloud et s’afficher aussi rapidement que des pages web simples.
La grande histoire de l’intégration du code externe
Il a toujours été possible d’appeler du code externe depuis le langage Wolfram depuis la Version 1.0. Mais dans la Version 14, il y a des avancées importantes dans l’étendue et la facilité d’intégration du code externe. L’objectif global est de pouvoir utiliser toute la puissance et la cohérence du langage Wolfram même lorsque certaines parties d’un calcul sont effectuées dans un code externe. Et dans la Version 14, nous avons fait beaucoup pour rationaliser et automatiser le processus d’intégration du code externe dans le langage.
Une fois quelque chose intégré dans le langage Wolfram, cela devient simplement, par exemple, une fonction qui peut être utilisée comme n’importe quelle autre fonction du langage Wolfram. Mais ce qui se passe en dessous est nécessairement assez différent pour différents types de code externe. Il y a une configuration pour les langages interprétés comme Python. Il y en a une autre pour les langages compilés de type C et les bibliothèques dynamiques. (Et puis il y en a d’autres pour les processus externes, les API et ce qui revient à des “spécifications de code importables”, par exemple pour les réseaux neuronaux.)
Commençons par Python. Nous avons eu ExternalEvaluate pour évaluer du code Python depuis 2018. Mais lorsque vous utilisez réellement Python, il y a toutes ces dépendances et bibliothèques à gérer. Et oui, c’est là que les incroyables avantages du langage Wolfram et sa conception cohérente sont douloureusement évidents. Mais dans la Version 14.0, nous avons maintenant un moyen d’encapsuler toute cette complexité de Python, afin de pouvoir fournir des fonctionnalités Python dans le langage Wolfram, en masquant tout le désordre des dépendances Python, et même la version de Python elle-même.
Par exemple, supposons que nous voulions créer une fonction du langage Wolfram Emojize qui utilise la fonction Python emojize dans la bibliothèque emoji Python. Voici comment nous pouvons faire cela:

Et maintenant, vous pouvez simplement appeler Emojize dans le langage Wolfram et—en coulisses—cela exécutera du code Python:

La façon dont cela fonctionne est que la première fois que vous appelez Emojize, un environnement Python avec toutes les fonctionnalités requises est créé, puis mis en cache pour les utilisations ultérieures. Et ce qui est important, c’est que la spécification du langage Wolfram pour Emojize est complètement indépendante du système (ou aussi indépendante du système que possible, compte tenu des particularités des implémentations Python). Cela signifie que vous pouvez, par exemple, déployer Emojize dans le Wolfram Function Repository tout comme vous déploieriez quelque chose écrit uniquement en langage Wolfram.
Il y a une ingénierie très différente impliquée dans l’appel de fonctions compatibles avec C dans des bibliothèques dynamiques. Mais dans la Version 13.3, nous avons également simplifié cela en utilisant la fonction ForeignFunctionLoad. Il y a toutes sortes de complexités associées à la conversion vers et depuis les types de données C natifs, à la gestion de la mémoire pour les structures de données, etc. Mais nous disposons désormais de moyens très propres pour le faire dans le langage Wolfram.
Par exemple, voici comment configurer un appel de “fonction étrangère” à une fonction RAND_bytes dans la bibliothèque OpenSSL:
À l’intérieur de cela, nous utilisons la technologie de compilation du langage Wolfram pour spécifier les types C natifs qui seront utilisés dans la fonction étrangère. Mais maintenant, nous pouvons empaqueter tout cela dans une fonction du langage Wolfram:

Et nous pouvons appeler cette fonction comme n’importe quelle autre fonction du langage Wolfram:
![]()
En interne, toutes sortes de choses compliquées se produisent. Par exemple, nous allouons un tampon mémoire brut qui est ensuite transmis à notre fonction C. Mais lorsque nous effectuons cette allocation mémoire, nous créons une structure symbolique qui la définit comme un “objet géré”.
Et maintenant, lorsque cet objet n’est plus utilisé, la mémoire qui lui est associée sera automatiquement libérée.
Et, oui, avec Python et C, il y a pas mal de complexité en dessous. Mais la bonne nouvelle, c’est qu’avec la Version 14, nous avons essentiellement pu automatiser sa gestion. Le résultat est que ce qui est exposé est du pur et simple langage Wolfram.
Mais il y a un autre élément important à cela. Au sein de certaines bibliothèques Python ou C, il existe souvent des définitions élaborées de structures de données spécifiques à cette bibliothèque. Ainsi, pour utiliser ces bibliothèques, il faut plonger dans toutes les complexités potentiellement idiosyncratiques de ces définitions. Mais dans le langage Wolfram, nous avons des représentations symboliques cohérentes pour les choses, que ce soient des images, des dates ou des types de produits chimiques. Lorsque vous connectez une bibliothèque externe pour la première fois, vous devez mapper ses structures de données à celles-ci. Mais une fois que cela est fait, n’importe qui peut utiliser ce qui a été construit et intégrer de manière transparente avec d’autres éléments qu’il utilise, peut-être même en appelant d’autres codes externes. En effet, ce qui se passe, c’est que l’on tire parti de l’ensemble du cadre de conception du langage Wolfram, et que l’on l’applique même lorsque l’on utilise des implémentations sous-jacentes qui ne sont pas basées sur le langage Wolfram.
For Serious Developers
Une seule ligne (ou moins) de code en langage Wolfram peut faire beaucoup. Mais l’une des choses remarquables à propos de ce langage est qu’il est fondamentalement scalable : il est bon à la fois pour les programmes très courts et très longs. Depuis la version 13, il y a eu plusieurs avancées dans la gestion des programmes très longs. L’une d’entre elles concerne “l’édition de code”.
Les carnets Wolfram standards fonctionnent très bien pour l’exploration, l’exposition et de nombreuses autres formes de travail. Et il est tout à fait possible d’écrire de grandes quantités de code dans des carnets standards (par exemple, je le fais personnellement). Mais lorsque l’on travaille de manière “ingénierie logicielle”, il est à la fois plus pratique et plus familier d’utiliser ce qui équivaut à un éditeur de code pur, largement séparé de l’exécution et de l’exposition du code. C’est pourquoi nous avons l'”éditeur de packages”, accessible depuis Fichier > Nouveau > Package/Script. Vous travaillez toujours dans l’environnement du carnet, avec toutes ses capacités sophistiquées. Mais les choses ont été adaptées pour fournir une expérience de “code” beaucoup plus textuelle, à la fois en termes d’édition et de ce qui est effectivement enregistré dans les fichiers .wl.
Voici un exemple typique de l’éditeur de packages en action (dans ce cas appliqué à notre package GitLink):

Plusieurs choses sont immédiatement évidentes. Tout d’abord, l’éditeur est très orienté ligne par ligne. Les lignes de code sont numérotées et ne se cassent pas sauf aux sauts de ligne explicites. Il y a des en-têtes comme dans les carnets ordinaires, mais lorsque le fichier est enregistré, ils sont stockés sous forme de commentaires avec une structure stylisée particulière:

Il est toujours parfaitement possible d’exécuter du code dans l’éditeur de packages, mais la sortie ne sera pas enregistrée dans le fichier .wl:

Une des choses qui a changé depuis la Version 13 est que la barre d’outils a été considérablement améliorée. Par exemple, il y a maintenant une “recherche intelligente” qui est consciente de la structure du code:

Vous pouvez également demander à accéder à un numéro de ligne et vous verrez immédiatement les lignes de code environnantes:

En plus de l’édition de code, un autre ensemble de fonctionnalités introduites depuis la Version 13 et importantes pour les développeurs sérieux concerne les tests automatisés. La principale avancée est l’introduction d’un framework de test entièrement symbolique, dans lequel les tests individuels sont représentés sous forme d’objets symboliques.
et peuvent être manipulés sous forme symbolique, puis exécutés à l’aide de fonctions telles que TestEvaluate et TestReport:

Dans la Version 14.0, il existe une autre nouvelle fonction de test: IntermediateTest, qui vous permet d’insérer ce qui équivaut à des points de contrôle à l’intérieur de tests plus grands:

En évaluant ce test, nous constatons que les tests intermédiaires ont également été exécutés:
Le Dépôt de fonctions Wolfram: 2900 fonctions et plus
Le Dépôt de fonctions Wolfram a rencontré un grand succès. Nous l’avons introduit en 2019 comme un moyen de rendre disponibles des fonctions spécifiques et individuelles contribuées dans le langage Wolfram. Aujourd’hui, le Dépôt compte plus de 2900 de ces fonctions.
Les près de 7000 fonctions qui constituent le langage Wolfram tel qu’il est aujourd’hui ont été développées avec soin au cours des trois dernières décennies et demie, toujours dans l’optique de créer un ensemble cohérent avec des principes de conception consistants. En un sens, le succès du Dépôt de fonctions est l’un des bénéfices de tous ces efforts. Car c’est la cohérence et la constance du langage sous-jacent et de ses principes de conception qui rendent possible d’ajouter simplement une fonction à la fois et de la faire fonctionner vraiment. Vous souhaitez ajouter une fonction pour effectuer une opération très spécifique combinant des images et des graphiques. Eh bien, il existe une représentation cohérente à la fois des images et des graphiques dans le langage Wolfram, que vous pouvez exploiter. En suivant les principes du langage Wolfram, comme pour le nommage des fonctions, vous pouvez créer une fonction facile à comprendre et à utiliser pour les utilisateurs du langage Wolfram.
Utiliser le Dépôt de fonctions Wolfram est un processus remarquablement fluide. Si vous connaissez le nom de la fonction, vous pouvez simplement l’appeler à l’aide de ResourceFunction; la fonction sera chargée si nécessaire, puis elle s’exécutera simplement:

Si une mise à jour est disponible pour la fonction, un message vous sera affiché mais l’ancienne version sera quand même exécutée. Ce message contiendra un bouton permettant de charger la mise à jour ; ensuite, vous pourrez réexécuter votre saisie et utiliser la nouvelle version. (Si vous écrivez du code où vous souhaitez « figer » une version particulière d’une fonction, vous pouvez simplement utiliser l’option ResourceVersion de ResourceFunction.)
Si vous souhaitez que votre code paraisse plus élégant, il vous suffit d’évaluer l’objet ResourceFunction.

et utilisez la version formatée:

Et, en fait, en appuyant sur le symbole “+” vous obtiendrez plus d’informations sur la fonction:

Une caractéristique importante des fonctions dans le Dépôt de fonctions est qu’elles disposent toutes de pages de documentation, organisées de manière assez similaire aux pages des fonctions intégrées:

Pour créer une entrée dans le Dépôt de fonctions, il suffit d’aller dans Fichier > Nouveau > Élément de dépôt > Élément du Dépôt de fonctions, et vous obtiendrez un cahier de définition (Definition Notebook):

Nous avons optimisé ce processus pour le rendre aussi simple que possible, en minimisant les sections standardisées et en vérifiant automatiquement la correction et la cohérence autant que possible. Le résultat est qu’il est tout à fait réaliste de créer un élément simple du Dépôt de fonctions en moins d’une heure, la majeure partie du temps étant consacrée à la rédaction de bons exemples explicatifs.
Lorsque vous appuyez sur “Soumettre au Dépôt”, votre fonction est envoyée à l’équipe de révision du Dépôt de fonctions Wolfram, dont le mandat est de s’assurer que les fonctions dans le dépôt font ce qu’elles prétendent faire, fonctionnent de manière conforme aux principes de conception généraux du langage Wolfram, ont des noms pertinents et sont suffisamment documentées. Sauf pour les fonctions très spécialisées, l’objectif est de terminer les révisions dans la semaine (et parfois beaucoup plus tôt) et de publier les fonctions dès qu’elles sont prêtes.
Il y a un résumé des nouvelles (et mises à jour) fonctions dans le Dépôt de fonctions qui est envoyé chaque vendredi, et qui est intéressant à lire (vous pouvez vous abonner ici):

Le Dépôt de fonctions Wolfram est une ressource publique et organisée à laquelle on peut accéder à partir de n’importe quel système utilisant le langage Wolfram (et, soit dit en passant, le code source de chaque fonction est disponible : il suffit d’appuyer sur le bouton “Carnet source”). Mais il y a un autre cas d’utilisation important pour l’infrastructure du Dépôt de fonctions : les “fonctions de ressources” déployées de manière privée.
Tout cela fonctionne à travers le Cloud Wolfram. Vous utilisez le même Cahier de définition, mais au lieu de soumettre à la fonction publique du Dépôt de fonctions Wolfram, vous déployez simplement votre fonction dans le Cloud Wolfram. Vous pouvez la rendre privée afin que seule vous, ou un groupe spécifique, puissiez y accéder. Ou vous pouvez la rendre publique, de sorte que quiconque connaît son URL puisse immédiatement y accéder et l’utiliser dans son système utilisant le langage Wolfram.
Cela s’avère être un mécanisme extrêmement utile, à la fois pour les projets de groupe et pour la création de documents publiés. En un sens, c’est un moyen très léger mais robuste de distribuer du code, empaqueté dans des fonctions qui peuvent être utilisées immédiatement. (En passant, pour trouver les fonctions que vous avez publiées à partir de votre compte Wolfram Cloud, il suffit d’aller dans le dossier DeployedResources dans le navigateur de fichiers du cloud.)
(Pour les organisations qui souhaitent gérer leur propre dépôt de fonctions, il est utile de mentionner que toute la mécanique du Dépôt de fonctions Wolfram, y compris l’infrastructure pour effectuer des révisions, etc., est également disponible sous forme privée via le Cloud Privé Entreprise Wolfram.)
Alors, qu’y a-t-il dans le Dépôt de fonctions Wolfram public ? Il y a beaucoup de “fonctions spécialisées” destinées à des objectifs spécifiques et “de niche”, mais très utiles si elles répondent à vos besoins:





Il existe des fonctions qui ajoutent différents types de visualisations:







Certaines fonctions mettent en place des interfaces utilisateur:

Certaines fonctions sont liées à des services externes:




Certaines fonctions fournissent des utilitaires simples:
![]()

Il existe également des fonctions qui sont explorées en vue d’une éventuelle inclusion dans le système principal:


Il y a aussi beaucoup de fonctions de pointe, ajoutées dans le cadre de la recherche ou du développement exploratoire. Par exemple, dans les articles que j’écris (y compris celui-ci), je veille à ce que toutes les images et autres sorties soient accompagnées d’un code “cliquable pour copier” qui les reproduit, et ce code contient très souvent des fonctions soit du Dépôt de fonctions Wolfram public, soit de déploiements privés (accessibles publiquement).
Le dépôt de paquets arrive
Les paquets sont une technologie que nous utilisons depuis plus d’une décennie et demie pour distribuer des fonctionnalités mises à jour aux systèmes du langage Wolfram sur le terrain. Dans la Version 13, nous avons commencé à fournir des outils permettant à quiconque de créer des paquets. Depuis la Version 13, nous avons introduit le Dépôt de paquets du langage Wolfram en tant que référentiel centralisé pour les paquets:

Qu’est-ce qu’un paclet ? C’est une collection de fonctionnalités du langage Wolfram, comprenant des définitions de fonctions, de la documentation, des bibliothèques externes, des feuilles de style, des palettes, et bien plus encore, qui peuvent être distribuées comme une unité et immédiatement déployées dans n’importe quel système utilisant le langage Wolfram.
Le Dépôt de Paclets est un endroit centralisé où n’importe qui peut publier des paclets pour une distribution publique. Alors, comment cela se rapporte-t-il au Dépôt de Fonctions Wolfram ? Ils sont complémentaires de manière intéressante, avec des optimisations différentes et des configurations différentes. Le Dépôt de Fonctions est plus léger, tandis que le Dépôt de Paclets est plus flexible. Le Dépôt de Fonctions vise à rendre disponibles des fonctions individuelles, qui s’intègrent indépendamment dans la structure existante du langage Wolfram. Le Dépôt de Paclets vise à rendre disponibles des éléments de fonctionnalité à plus grande échelle, qui peuvent définir un cadre et un environnement complet.
Le Dépôt de Fonctions est également entièrement organisé, chaque fonction étant examinée par notre équipe avant d’être publiée. Le Dépôt de Paclets est un système de déploiement immédiat, sans examen préalable à la publication. Dans le Dépôt de Fonctions, chaque fonction est spécifiée uniquement par son nom, et notre équipe de révision est responsable de s’assurer que les noms sont bien choisis et qu’il n’y a pas de conflits. Dans le Dépôt de Paclets, chaque contributeur dispose de son propre espace de noms, et toutes ses fonctions et autres éléments résident dans cet espace. Par exemple, j’ai contribué la fonction RandomHypergraph au Dépôt de Fonctions, qui peut être accédée simplement comme ResourceFunction[“RandomHypergraph”]. Mais si j’avais mis cette fonction dans un paclet dans le Dépôt de Paclets, elle aurait dû être accédée quelque chose comme PacletSymbol[“StephenWolfram/Hypergraphs”, “RandomHypergraph”].
PacletSymbol, soit dit en passant, est un moyen pratique d’accéder en profondeur aux fonctions individuelles à l’intérieur d’un paclet. PacletSymbol installe temporairement (et charge) un paclet afin que vous puissiez accéder à un symbole particulier à l’intérieur. Cependant, le plus souvent, on souhaite installer définitivement un paclet (en utilisant PacletInstall), puis charger explicitement son contenu (en utilisant Needs) chaque fois que l’on souhaite avoir ses symboles disponibles. (Tous les différents éléments auxiliaires, tels que la documentation, les feuilles de style, etc., dans un paclet sont configurés lors de son installation.)
À quoi ressemble un paclet dans le Dépôt de Paclets? Chaque paclet a une page d’accueil qui comprend généralement un résumé global, un guide des fonctions du paclet, et quelques exemples globaux du paclet:

Les fonctions individuelles ont généralement leurs propres pages de documentation:

Tout comme dans la documentation principale du langage Wolfram, il peut y avoir toute une hiérarchie de pages de guide, ainsi que des tutoriels.
Remarquez que dans les exemples de documentation de paclets, on voit souvent des constructions comme ![]() . Celles-ci représentent des symboles dans le paclet, présentés sous forme de PacletSymbol[“WolframChemistry/ProteinVisualization”, “AmidePlanePlot”]` qui permettent d’accéder à ces symboles de manière autonome. Si vous évaluez directement une telle forme, cela forcera (temporairement) l’installation du paclet, puis renverra le symbole réel et brut qui apparaît dans le paclet :
. Celles-ci représentent des symboles dans le paclet, présentés sous forme de PacletSymbol[“WolframChemistry/ProteinVisualization”, “AmidePlanePlot”]` qui permettent d’accéder à ces symboles de manière autonome. Si vous évaluez directement une telle forme, cela forcera (temporairement) l’installation du paclet, puis renverra le symbole réel et brut qui apparaît dans le paclet :
Pour créer un paclet adapté à la soumission dans le Dépôt de Paclets, vous pouvez le faire de manière purement programmatique ou vous pouvez démarrer à partir de Fichier > Nouveau > Élément de dépôt > Élément du Dépôt de Paclets, ce qui lance essentiellement tout un environnement de création de paclets. La première étape consiste à spécifier où vous souhaitez assembler votre paclet. Vous fournissez quelques informations de base

Ensuite, un Cahier de définition des ressources du paclet est créé, à partir duquel vous pouvez définir des fonctions, configurer des pages de documentation, spécifier le format de la page d’accueil de votre paclet, etc.

Il existe de nombreux outils sophistiqués qui vous permettent de créer des paclets complets avec le même niveau de fonctionnalités étendues que vous trouvez dans le langage Wolfram lui-même. Par exemple, les outils de documentation vous permettent de construire des pages de documentation complètes (pages de fonctions, pages de guide, tutoriels, …).

Une fois que vous avez assemblé un paclet, vous pouvez le vérifier, le construire, le déployer en privé, ou le soumettre au Dépôt de Paclets. Une fois soumis, il sera automatiquement configuré sur les serveurs du Dépôt de Paclets, et en quelques minutes seulement, les pages que vous avez créées décrivant votre paclet apparaîtront sur le site web du Dépôt de Paclets.
Alors, qu’y a-t-il dans le Dépôt de Paclets jusqu’à présent ? Il y a beaucoup de choses intéressantes et sérieuses, contribuées à la fois par des équipes de notre entreprise et par des membres de la communauté élargie du langage Wolfram. En fait, bon nombre des 134 paclets actuellement dans le Dépôt de Paclets contiennent suffisamment de contenu pour qu’on puisse écrire un article complet à leur sujet.
Une catégorie de choses que vous trouverez dans le Dépôt de Paclets sont des instantanés de nos projets de développement internes en cours—dont beaucoup deviendront éventuellement des parties intégrées du langage Wolfram. Un bon exemple de cela est notre fonctionnalité LLM et Chat Notebook, dont le développement et le déploiement rapides au cours de l’année écoulée ont été rendus possibles grâce à l’utilisation du Dépôt de Paclets. Un autre exemple, représentant un travail continu de notre équipe de chimie (connue sous le nom de WolframChemistry dans le Dépôt de Paclets), est le paclet ChemistryFunctions, qui contient des fonctions telles que:

Et oui, ceci est interactif:

Ou, également depuis WolframChemistry:

Un autre “instantané de développement” est DiffTools, un paclet permettant de créer et de visualiser des différences entre des chaînes de caractères, des cellules, des cahiers, etc.

Un paclet majeur est QuantumFramework, qui fournit les fonctionnalités pour notre Wolfram Quantum Framework.

et offre un large soutien au calcul quantique (avec au moins quelques liens vers les systèmes multi-voies et notre projet de physique):


En parlant de notre projet de physique, il existe plus de 200 fonctions qui le soutiennent dans le Dépôt de fonctions Wolfram. Mais il existe également des paclets, comme WolframInstitute/Hypergraph:

Un exemple de package contribué par un tiers est Automata, qui comprend plus de 250 fonctions pour effectuer des calculs liés aux automates finis:


Un autre paclet contribué est FunctionalParsers, qui permet de passer d’une spécification de parseur symbolique à un parseur réel, ici utilisé en mode inverse pour générer des “phrases” aléatoires:

Phi4Tools est un paclet plus spécialisé, destiné à travailler avec les diagrammes de Feynman dans la théorie des champs ![]() :
:



Et, comme autre exemple, voici MaXrd, destiné à la cristallographie et à la diffusion des rayons X:


Comme dernier exemple, il y a le paclet Organizer, un utilitaire pour créer et manipuler des cahiers d’organisation. Mais contrairement aux autres paclets que nous avons vus ici, il n’expose aucune fonction du langage Wolfram ; au lieu de cela, lorsque vous l’installez, il ajoute une palette à votre liste de palettes:


Attractions à venir
Aujourd’hui, la Version 14 est terminée et disponible dans le monde entier. Alors, que vient-il ensuite ? Nous avons de nombreux projets en cours, certains avec déjà plusieurs années de développement derrière eux. Certains étendent et renforcent ce qui existe déjà dans le langage Wolfram ; d’autres le poussent dans de nouvelles directions.
Un des principaux axes de développement est d’élargir et de simplifier le déploiement du langage : unifier la façon dont il est distribué et installé sur les ordinateurs, le conditionner pour qu’il puisse être intégré efficacement dans d’autres applications autonomes, etc.
Un autre axe majeur est d’étendre la manipulation de très grandes quantités de données par le langage Wolfram, et d’intégrer de manière transparente le traitement hors mémoire et le traitement paresseux.
Ensuite, bien sûr, il y a le développement algorithmique. Certains sont “classiques”, construisant directement sur les tours de fonctionnalités que nous avons développées au fil des décennies. Certains sont plus basés sur l’IA. Nous créons des algorithmes heuristiques et des méta-algorithmes depuis la Version 1.0—en utilisant de plus en plus des méthodes d’apprentissage automatique. Jusqu’où les méthodes des réseaux neuronaux iront-elles ? Nous ne le savons pas encore. Nous les utilisons régulièrement dans des domaines tels que la sélection d’algorithmes. Mais dans quelle mesure peuvent-ils aider au cœur même des algorithmes ?
Cela me rappelle quelque chose que nous avons fait en 1987 lors du développement de la Version 1.0. Il y avait une longue tradition en analyse numérique consistant à dériver méticuleusement des approximations en séries pour des cas particuliers de fonctions mathématiques. Mais nous voulions être capables de calculer des centaines de fonctions différentes avec une précision arbitraire pour n’importe quelles valeurs complexes de leurs arguments. Alors, comment avons-nous fait ? Nous sommes passés des séries aux approximations rationnelles—et ensuite, de manière très semblable à celle de l’apprentissage automatique, nous avons passé des mois de temps CPU à optimiser systématiquement ces approximations. Eh bien, nous essayons de refaire quelque chose de similaire—mais cette fois sur des domaines plus ambitieux—en utilisant maintenant non pas des fonctions rationnelles mais de grands réseaux neuronaux comme base.
Nous explorons également l’utilisation de réseaux neuronaux pour “contrôler” des algorithmes précis, en effectuant en fait des choix heuristiques qui orientent ou peuvent être validés par les algorithmes précis. Jusqu’à présent, rien de ce que nous avons produit n’a surpassé nos méthodes existantes, mais il semble plausible que cela se produira assez bientôt.
Nous travaillons beaucoup sur divers aspects de la méta-programmation. Il y a le projet d’impliquer les LLM pour aider à la construction du code en langage Wolfram, à donner des commentaires dessus, à analyser ce qui s’est mal passé si le code n’a pas produit les résultats escomptés. Ensuite, il y a l’annotation de code—où les LLM peuvent aider à faire des choses comme prédire le type le plus probable pour quelque chose. Et il y a la compilation de code. Nous travaillons depuis de nombreuses années sur un compilateur à grande échelle pour le langage Wolfram, et à chaque version, ce que nous avons devient de plus en plus performant. Nous avons réalisé une certaine forme de compilation automatique dans des cas particuliers (notamment ceux impliquant des calculs numériques) depuis plus de 30 ans. Et éventuellement, une compilation automatique à grande échelle sera possible pour tout. Mais pour l’instant, certains des plus grands bénéfices de notre technologie de compilation ont été pour notre développement interne, où nous pouvons désormais obtenir des performances optimales en utilisant simplement du code Wolfram compilé (bien que soigneusement écrit).
Une des grandes leçons du succès surprenant des LLM est qu’il y a potentiellement plus de structure dans le langage humain significatif que ce que nous pensions. J’ai depuis longtemps été intéressé par la création de ce que j’ai appelé un “langage de discours symbolique” qui donne une représentation computationnelle du discours quotidien. Les LLM ne l’ont pas fait explicitement. Mais ils encouragent l’idée que cela devrait être possible, et ils fournissent également une aide pratique pour le faire. Et que le but soit de représenter du texte narratif, des contrats ou des spécifications textuelles, il s’agit d’étendre le langage computationnel que nous avons construit pour englober plus de types de concepts et de structures.
Il y a généralement plusieurs types de moteurs pour nos efforts de développement continu. Parfois, il s’agit de continuer à construire une tour de capacités dans une direction connue (comme par exemple, résoudre des EDP). Parfois, la tour que nous avons construite nous permet soudainement de voir de nouvelles possibilités. Parfois, lorsque nous utilisons réellement ce que nous avons construit, nous réalisons qu’il existe une façon évidente de le peaufiner ou de l’étendre, ou de renforcer quelque chose que nous voyons maintenant comme précieux. Et puis, il y a des cas où des événements dans le monde de la technologie ouvrent soudainement de nouvelles possibilités—comme l’ont récemment fait les LLM, et peut-être que la réalité étendue ou mixte le fera finalement. Enfin, il y a des cas où de nouvelles intuitions liées à la science suggèrent de nouvelles directions.
Je pensais que notre Projet de Physique n’aurait au mieux que des applications pratiques que dans des siècles. Mais en fait, il est devenu clair que la correspondance qu’il a définie entre la physique et le calcul nous donne des façons assez immédiates de penser à des aspects pratiques du calcul. En effet, nous explorons activement comment utiliser cela pour définir un nouveau niveau de calcul parallèle et distribué dans le langage Wolfram, ainsi que pour représenter symboliquement non seulement les résultats des calculs mais aussi le processus de calcul en cours.
On pourrait penser qu’après près de quatre décennies de développement intense, il n’y aurait plus rien à faire dans le développement du langage Wolfram. Mais en fait, à chaque niveau que nous atteignons, il y a toujours plus de choses qui deviennent possibles, et toujours plus de choses que nous pouvons imaginer comme étant possibles. Et en effet, ce moment est particulièrement fertile, avec un large éventail de possibilités sans précédent. La Version 14 est une étape importante et satisfaisante. Mais il y a encore de merveilleuses choses à venir—alors que nous poursuivons notre mission à long terme pour que le paradigme computationnel atteigne son potentiel, et pour construire notre langage computationnel afin d’aider cela à se produire.