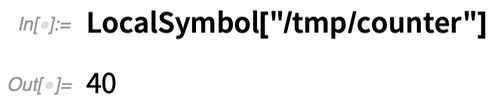A Wolfram Language & Mathematica 12.3-as verziójának elindítása
Nézd meg, mit csináltunk öt hónap alatt!

A 12.2-es verziót 2020. december 16-án adtuk ki. Ma pedig, mindössze öt hónappal később, kiadjuk a 12.3-as verziót. A 12.3-ban van néhány áttörés és jelentős új irányvonal. De a 12.3 nagy része csak arról szól, hogy a Wolfram Language és a Mathematica használata jobb, gördülékenyebb és kényelmesebb legyen. A dolgok gyorsabbak. Több „De mi van ___-vel?” esetet kezelünk. A nagy keretrendszerek teljesebbek. És rengeteg új kényelmi funkció van.
Megvannak az első darabkái annak is, ami a jövőben nagy struktúrákká fog válni. Korai funkciók – amelyek már önmagukban is nagyon hasznosak -, és amelyek a jövőbeni kiadásokban a nagy, egész rendszerre kiterjedő keretrendszerek részei lesznek.
Egy kiadás értékelésének egyik módja, hogy arról beszélünk, hány új funkciót tartalmaz. A 12.3-as verzió esetében ez a szám 111 (vagy körülbelül 5 új funkció fejlesztésenként). Ez a K+F termelékenység igen lenyűgöző szintje. De különösen a 12.3 esetében ez csak egy része a történetnek; 1190 hibajavítás is van (körülbelül egynegyedük külsőleg jelentett hiba), valamint 105 jelentősen frissített és továbbfejlesztett funkció.
Az inkrementális kiadások a nyílt fejlesztés iránti elkötelezettségünk részét képezik. Többféle funkciót is megosztunk nyílt forráskódú formában (beleértve több mint 300 új függvényt a Wolfram Function Repositoryban). És egyedülálló módon élőben közvetítjük belső tervezési folyamatainkat. A 12.3-as verzió esetében ismét lehetőség van arra, hogy megnézzük, hol és hogyan születtek a tervezési döntések, és milyen érvek állnak mögöttük. A közösségünk is nagyszerű hozzájárulásokat kapott (gyakran valós időben, a livestreamek során), amelyek jelentősen javították a 12.3-as verziót, amelyet ma szállítunk.
Mellesleg, amikor azt mondjuk, hogy a Wolfram Language és a Mathematica „12.3-as verziója”, akkor az asztali, a felhő- és a motorverzióra gondolunk: mindhárom verzió ma jelenik meg.
Sok kis új kényelem
A 12.3-as verzió tartalmazza a legutóbbi adag kényelmi funkciót, a nyelv számos pontján elszórva. Egy új dinamika, amely ebben a verzióban jelent meg, azok a függvények, amelyeket lényegében a Wolfram Function Repositoryban „prototipizáltunk”, majd „frissítettünk”, hogy beépítsük a rendszerbe.
Íme egy első példa egy új kényelmi függvényre: SolveValues. A Solve függvény – amely eredetileg az 1.0-s verzióban került bevezetésre – nagyon rugalmasan ábrázolja az eredményeit, ami lehetővé teszi a változók különböző számát, a megoldások különböző számát stb.
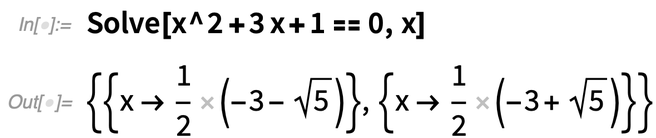
|

|
Egyébként van egy NSolveValues is, amely közelítő numerikus értékeket ad:
 |
Egy másik példa egy új kényelmi függvényre a NumberDigit. Tegyük fel, hogy a π 10. számjegyét szeretnénk. Mindig használhatjuk a RealDigits-et, majd kiválaszthatjuk a kívánt számjegyet:
 |
Egy másik példa egy új kényelmi függvényre a NumberDigit. Tegyük fel, hogy a π 10. számjegyét szeretnénk. Mindig használhatjuk a RealDigit-et, majd kiválaszthatjuk a kívánt számjegyet:
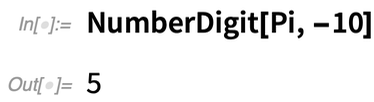 |
Az 1.0-s verzióban még csak Sort volt. A 10.3-as verzióban (2015) hozzáadtuk az AlphabeticSortot, majd a 11.1-es verzióban (2017) a NumericalSortot. Most a 12.3-as verzióban – hogy teljessé tegyük az alapértelmezett rendezési típusok családját – hozzáadjuk a LexicographicSortot. Az alapértelmezett (Sort által előállított) rendezés a következő:

|
De itt az igazi lexikográfiai sorrend, mint amilyen egy szótárban található:

Egy másik kis új funkció a 12.3-as verzióban a StringTakeDrop:

|
Azzal, hogy ez egyetlen függvény, könnyebben használható az ilyen funkcionális programozási konstrukciókban:
 |
Mindig fontos cél, hogy a „szabványos munkafolyamatokat” a lehető legegyszerűbbé tegyük. Például a gráfok kezelésében a 8.0-s verzió (2010) óta van VertexOutComponent. Ez egy listát ad azokról a csúcsokról, amelyek egy adott csúcsból elérhetőek. És bizonyos dolgokhoz pontosan ez az, amit az ember akar. De néha sokkal kényelmesebb, ha a részgráfot kapjuk meg (és valójában a Fizika projektünk formalizmusában ez a részgráf – amit mi „geodéziai gömbnek” tekintünk – egy meglehetősen központi konstrukció). Ezért a 12.3-as verzióban hozzáadtuk a VertexOutComponentGraph-ot:
 |
Egy másik példa egy kis „munkafolyamat-javításra” a HighlightImage-ben található. A HighlightImage általában a képen kiemelendő érdekes régiók listáját veszi fel. Az olyan függvények azonban, mint a MorphologicalComponents, nem egyszerűen listát készítenek a kép régióiról; ehelyett egy „címkemátrixot” állítanak elő, amely számokkal jelöli a kép különböző régióit. Így a HighlightImage munkafolyamat gördülékenyebbé tétele érdekében a 12.3. verzióban lehetővé tettük, hogy közvetlenül egy címkemátrixot használjon, és különböző színeket rendeljen a különbözőképpen címkézett régiókhoz:
 |
A Wolfram Nyelvben keményen dolgozunk a koherencia és az interoperabilitás biztosításán. (Valójában egy egész kezdeményezésünk van ezzel kapcsolatban, amelyet „Language Completeness & Consistency” (Nyelvi teljesség és konzisztencia) néven emlegetünk, és amelynek heti találkozóit rendszeresen élőben közvetítjük). Az interoperabilitás egyik különböző aspektusa az, hogy azt szeretnénk, ha a függvények képesek lennének bármilyen ésszerű bemenetet „megenni”, és olyanná alakítani, amit „természetesen” tudnak kezelni.
Egy kis példa erre, amit a 12.3-as verzióban hozzáadtunk, az a színterek közötti automatikus konverzió. A piros alapértelmezés szerint a piros RGB színt jelenti (RGBColor[1,0,0,0]). De mostantól
 |
azt jelenti, hogy a vöröset vörösre változtatja a színárnyalat-térben:

|
Tegyük fel, hogy egy hosszú számítást futtatsz. Gyakran szeretnénk valamilyen jelzést kapni az elért haladásról. A 6.0 (2007) verzióban hozzáadtuk a Monitor funkciót, és a későbbi verziókban néhány funkcióhoz, például a NetTrainhez, automatikus beépített előrehaladási jelentést adtunk. Most azonban folyamatban van egy olyan kezdeményezés, amelynek célja, hogy szisztematikusan hozzáadjuk a haladásjelentést mindenféle olyan függvényhez, amely hosszú számításokat végezhet. (A $ProgressReporting = False globálisan kikapcsolja ezt.)
 |
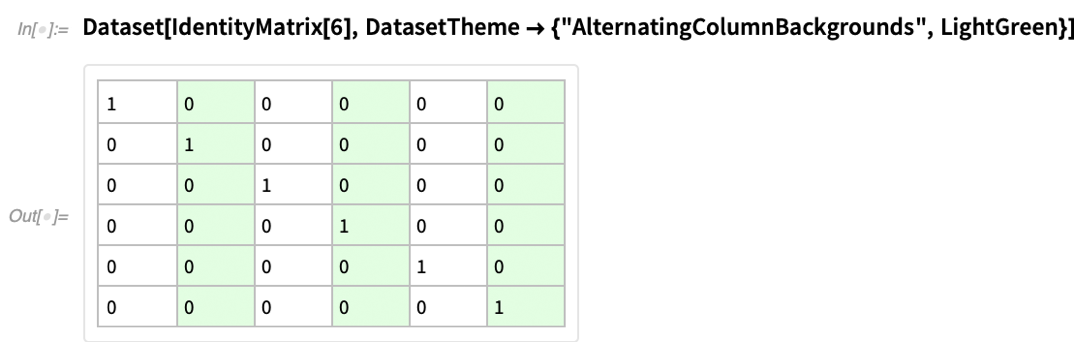
Keményen dolgozunk a Wolfram Language-ben, hogy biztosítsuk, hogy jó alapértelmezéseket válasszunk, például a dolgok megjelenítésének módját illetően. De néha meg kell mondanod a rendszernek, hogy milyen „megjelenést” szeretnél. A 12.3-as verzióban ezért hozzáadtuk a DatasetTheme opciót, amellyel megadhatjuk a Dataset objektumok megjelenítésének „témáit”.
Alatta minden téma csak bizonyos beállításokat állít be, amelyeket maga is beállíthatott. De a téma „bankváltó” opciókat kényelmes módon. Íme egy alap Dataset alapértelmezett formázással:
 |
Itt már „élénkebbnek” tűnik a világhálón:
 |
Különböző „témairányelveket” is megadhat:
 |
Valamint további tippeket:
 |
Nem tudom, miért nem gondoltunk rá korábban, de a 11.3-as verzióban (2018) bevezettünk egy nagyon szép „felhasználói felület újítást”: Iconize. A 12.3-as verzióban pedig egy újabb csiszolást adtunk az ikonizáláshoz. Ha kijelöl egy kifejezés egy darabját, majd a kontextus („jobb klikk”) menüben az Iconize funkciót használja, a kifejezés megfelelő alrészlete ikonizálódik, még akkor is, ha a kijelölés esetleg tartalmazott egy extra vesszőt, vagy olyasmi volt, ami nem lehet a kifejezés szigorúan vett alrészlete:
 |
Tegyük fel, hogy létrehoz egy olyan objektumot, amelynek tárolása sok memóriát igényel:
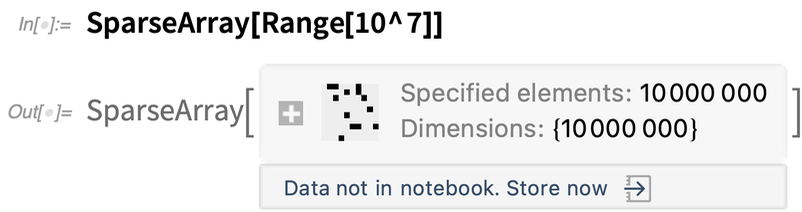 |
Alapértelmezés szerint az objektum a kernel-munkamenetben marad, de nem közvetlenül a notebookban tárolódik, így nem marad fenn az aktuális kernel-munkamenet befejezése után. A 12.3-as verzióban hozzáadtunk néhány lehetőséget arra vonatkozóan, hogy hol tárolja az adatokat:
 |
Az egyik fontos terület, ahol nagy erőfeszítéseket teszünk annak érdekében, hogy a dolgok „csak úgy működjenek”, az adatimport és -export. A Wolfram Language jelenleg mintegy 250 külső adatformátumot támogat, a 12.3. verzióban például olyan új statisztikai adatformátumokkal, mint a SAS7BDAT, DTA, POR és SAV.
Sok minden gyorsabb lett
Íme egy számítás az Around segítségével:
 |
A 12.2-es verzióban ez a 10.000-szeres művelet az én számítógépemen körülbelül 1,3 másodpercet vesz igénybe:
 |
A 12.3-as verzióban ez nagyjából 100-szor gyorsabb:
 |
Számos oka van annak, hogy a 12.3-as verzióban a dolgok gyorsabbak lettek. A Permanent esetében például egy új és sokkal jobb algoritmust tudtunk használni. Itt van ez a 12.2-ben:
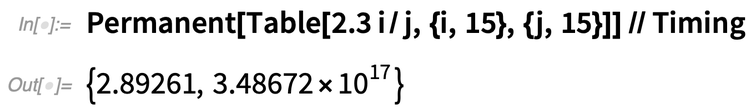 |
És most a 12.3-as verzióban:
 |
További példa a Rasterize, amely a 12.3-as verzióban jellemzően 2-4-szer gyorsabb, mint a 12.2-es verzióban. Ennek a gyorsulásnak az oka némileg finom. Amikor a Rasterize-t először a 6.0-s verzióban (2007) vezették be, a folyamatok közötti adatátvitel sebessége problémát jelentett, ezért jó optimalizálás volt az átvitt adatok tömörítése. Ma azonban az adatátviteli sebességek sokkal nagyobbak, és jobb optimalizált tömbi adatszerkezetekkel rendelkezünk – így a tömörítésnek már nincs értelme, és a tömörítés megszüntetése (más kódútvonal-optimalizálással együtt) lehetővé teszi, hogy a Rasterize jelentősen gyorsabb legyen.
Fontos előrelépés volt a 12.1-es verzióban a DataStructure bevezetése, amely lehetővé teszi az optimalizációs adatszerkezetek közvetlen használatát (az új fordítótechnológiánkkal megvalósítva). A 12.3-as verzió több új adatszerkezetet vezet be. Ott van a „ByteTrie” a gyors prefix-alapú keresésekhez (gondoljunk csak az Autocomplete és a GenomeLookup) szolgáltatásokra, és ott van a „KDTree” a gyors geometriai keresésekhez (gondoljunk csak a Nearest-re). Mostantól létezik az „ImmutableVector” is, amely alapvetően olyan, mint egy közönséges Wolfram Language lista, kivéve, hogy gyors függesztésre van optimalizálva.
A számítási mag sebességének javításán kívül a 12.3-as verzió a felhasználói felület sebességét is javította. Különösen figyelemre méltó a Windows platformokon jelentősen gyorsabb renderelés, amelyet a DirectWrite használatával és a GPU képességek kihasználásával értek el.
A matematika határainak feszegetése
A 12.3-as verzió esetében beszéljünk először a szimbolikus egyenletmegoldásról. Még a 3. verzióban (1996) vezettük be a polinomok gyökeinek implicit „Root objektum” reprezentációjának ötletét, amely lehetővé tette, hogy „explicit formulák” nélkül is pontos, szimbolikus számításokat végezhessünk a gyökök tekintetében. A 7-es verzió (2008) általánosította a Root objektumot, hogy transzcendens egyenletek esetén is működjön.
Mi a helyzet az egyenletrendszerekkel? A polinomok esetében az eliminációs elmélet azt jelenti, hogy a rendszerek valójában nem különböznek az egyes egyenletektől; ugyanazok a Root-objektumok használhatók. Transzcendens egyenletekre azonban ez már nem igaz. A 12.3-as verzióhoz azonban most kitaláltuk, hogyan lehet általánosítani a Root-objektumokat, hogy azok többváltozós transzcendens gyökökkel is működjenek:
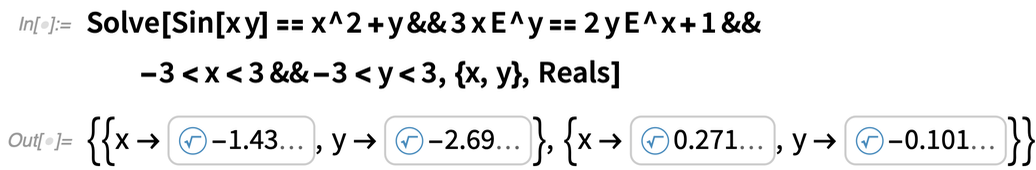 |
És mivel ezek a Root-objektumok egzaktak, például bármilyen pontossággal kiértékelhetők:
 |
A 12.3-as verzióban van néhány új, elliptikus függvényeket tartalmazó egyenlet is, ahol pontos szimbolikus eredmények adhatók, akár Root objektumok nélkül is:
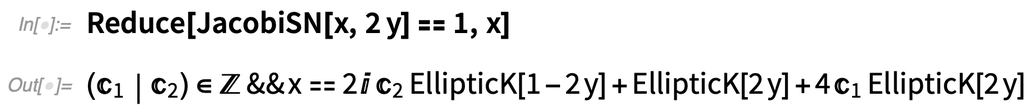 |
A 12.3-as verzió jelentős előrelépése, hogy képes szimbolikusan megoldani bármely lineáris ODE (közönséges differenciálegyenlet) rendszert racionális függvény együtthatókkal.
Néha az eredmény explicit matematikai függvényeket tartalmaz:
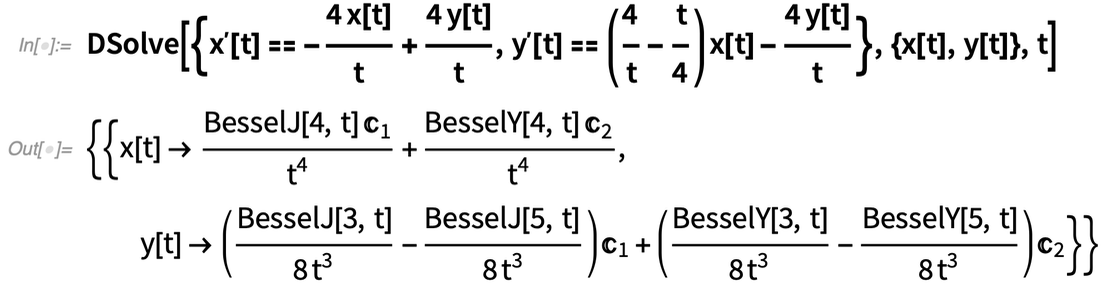 |
Néha vannak integrálok – vagy differenciális gyökök – az eredményekben:
 |
A 12.3-as verzió másik ODE-fejlesztése a q-racionális függvények együtthatóival rendelkező lineáris ODE-k teljes lefedettsége, amelyekben a változók explicit vagy implicit módon jelenhetnek meg az exponensekben. Az eredmények pontosak, bár jellemzően differenciális gyökökkel járnak:
 |
Mi a helyzet a PDE-kkel? A 12.2-es verzióban bevezettünk egy jelentős új keretrendszert a numerikus PDE-kkel való modellezéshez. A 12.3-as verzióban pedig egy egész 105 oldalas monográfiát készítettünk a PDE-k szimbolikus megoldásairól:

|
|
Most már pontosan és szimbolikusan is megoldható:
 |
A 12.3-as verzió a lineáris PDE-k mellett a speciális megoldások lefedettségét a nemlineáris PDE-kre is kiterjeszti. Íme egy (4 változós) megoldás, amely a Jacobi-módszert használja:
 |
A 12.3-ban a kétoldalú Laplace-transzformáció (azaz a Fourier-transzformációhoz hasonlóan -∞-től +∞-ig történő integrálás) olyan újdonság, amely támogatja a PDE-ket és új funkciókat biztosít a jelfeldolgozáshoz:
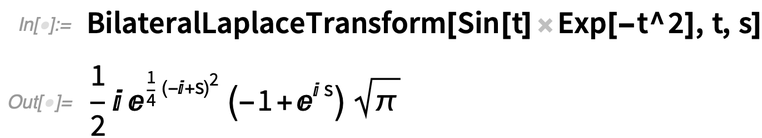 |
Még a 3. verzióban (1996) vezettük be a MeijerG-t, amely drámaian kibővítette a szimbolikus formában elvégezhető határozott integrálok körét. A MeijerG egy Mellin-Barnes-integrál segítségével definiálható a komplex síkban. Ez egy apró változás az integránsban, de 25 évbe telt, hogy kibogozzuk a szükséges matematikát és algoritmusokat, hogy most a 12.3 FoxH verzióban elérjük.
A FoxHegy nagyon általános függvény – magában foglalja az összes hipergeometriai pFq és Meijer G függvényt, és még sokkal többet. És most, hogy a FoxH a nyelvünkön van, képesek vagyunk elkezdeni az integrációs és egyéb szimbolikus képességeink bővítését, hogy felhasználhassuk.
Szimbolikus optimalizálási áttörés
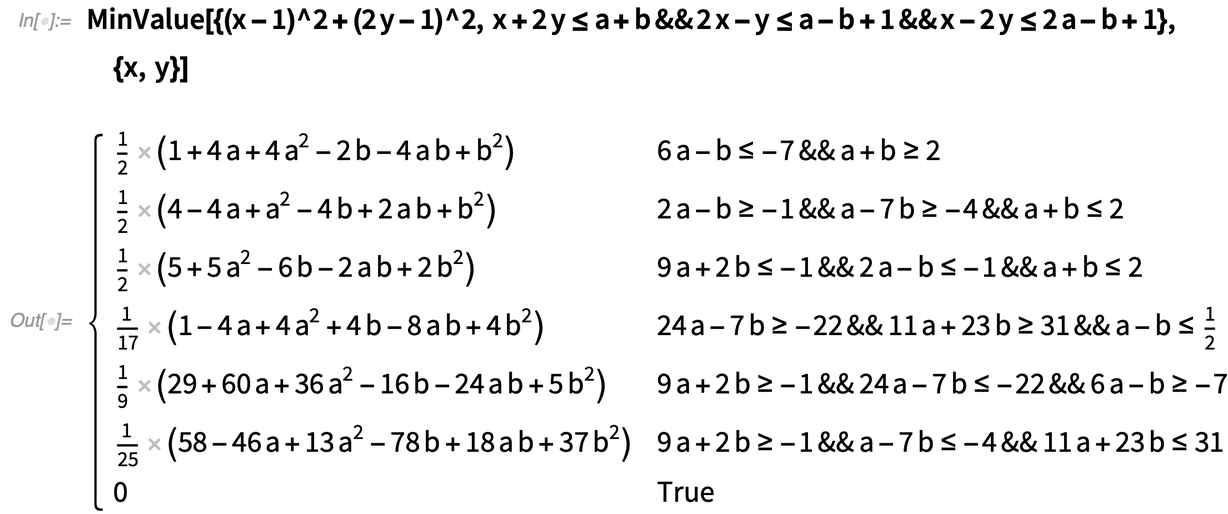 |
 |
A 12.0 verzióban jelentős előrelépés volt az ipari szintű konvex optimalizálás bevezetése, amely rutinszerűen kezeli a lineáris esetben több millió változót, nemlineáris esetben pedig több ezer változót tartalmazó problémákat. A 12.0 verzióban mindennek numerikusnak kellett lennie (a 12.1-ben egészértékű optimalizálással egészítettük ki). A 12.3-as verzióban most hozzáadjuk a szimbolikus paraméterek lehetőségét a nagyméretű lineáris és kvadratikus problémákban, mint ebben a kis példában:
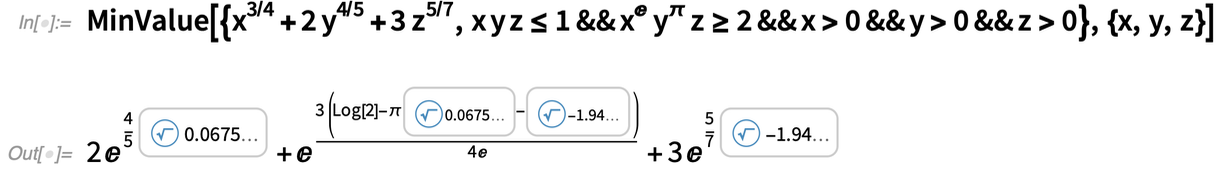 |
Egy ilyen pontos megoldás birtokában most már bármilyen pontosságú numerikus kiértékelést végezhetünk:
 |
Még több gráffal
A 12.3-as verzióban tovább bővítettük ezt a funkcionalitást. Itt van például egy új 3D-s megjelenítési funkció a gráfok számára:
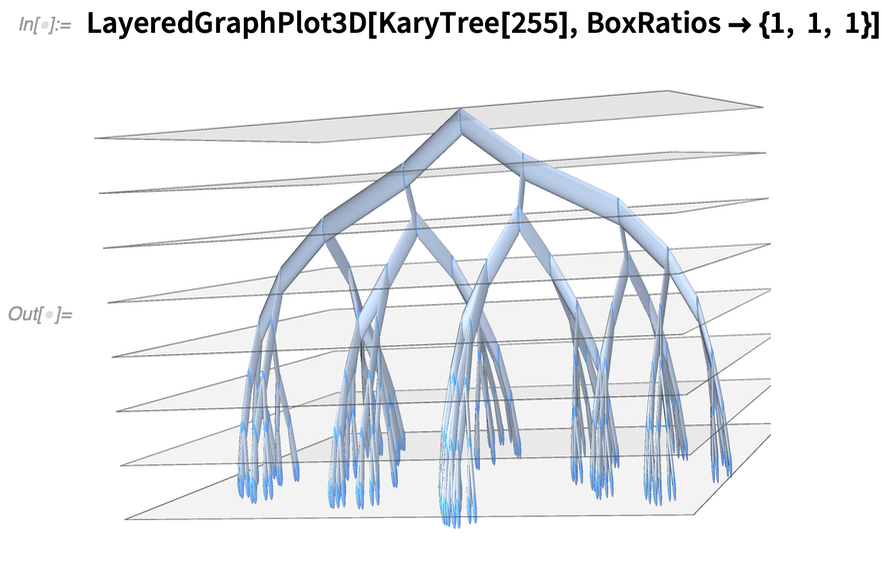 |
És itt egy új 3D gráf beágyazás:
 |
A 10-es verzió (2014)óta képesek vagyunk a gráfokban átívelő fákat találni. A 12.3-as verzióban azonban általánosítottuk a FindSpanningTree-t, hogy közvetlenül kezelhessünk olyan objektumokat — például földrajzi helyeket —, amelyek valamilyen koordinátával rendelkeznek. Íme egy átívelő fa, amely az európai fővárosok helyzetén alapul:
 |
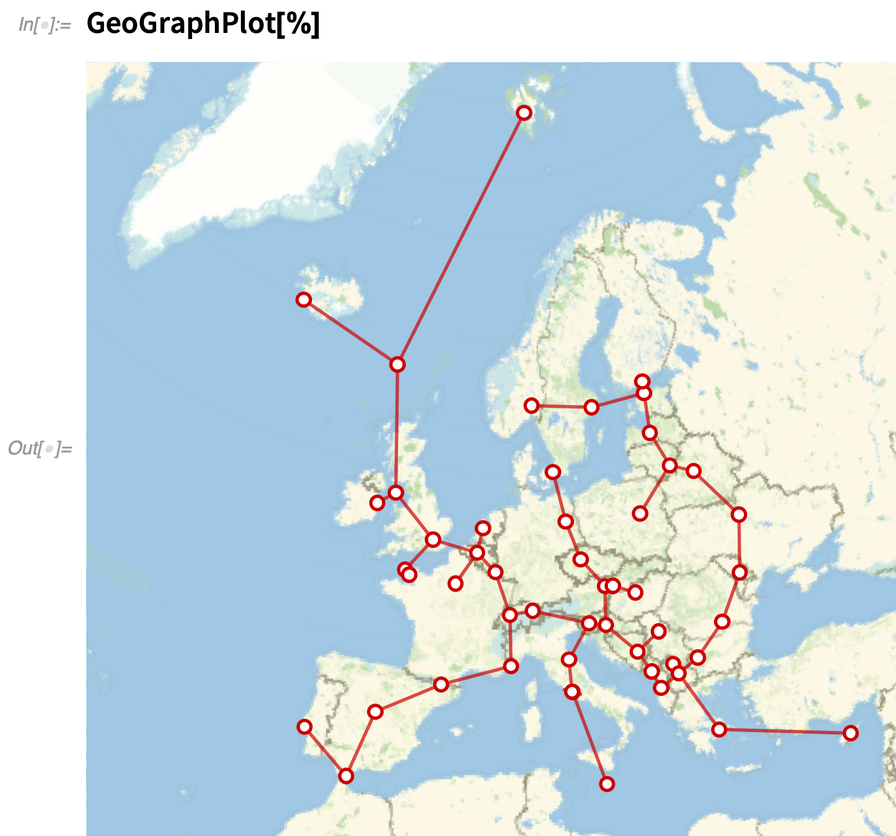 |
Egyébként egy „geo-gráfban” vannak „geo” módjai az élek útvonalának. Például megadhatja, hogy azok (ha lehetséges) a vezetési irányokat kövessék (ahogyan azt a TravelDirections biztosítja):
 |
Euklidész találkozik Descartes-szal, és így tovább
Három szimbolikusan megadott pont esetén a GeometricTest meg tudja adni azt az algebrai feltételt, hogy azok kollineárisak legyenek:
 |
A kollinearitás különleges esetére van egy speciális függvény a teszt elvégzésére:
 |
A GeometricTest azonban sokkal általánosabb – több mint 30 féle predikátumot támogat. Ez adja meg a feltételét annak, hogy egy sokszög konvex legyen:
 |
Ez a feltétele annak, hogy egy sokszög szabályos legyen:
 |
És itt a feltétele annak, hogy három kör kölcsönösen érintkezzen egymással (és igen, ez a ∃ egy kicsit „poszt Descartes-i”):
 |
s verzió az alapvető számítási geometriát is továbbfejlesztette. A legjelentősebbek a RegionDilation és a RegionErosion, amelyek lényegében a régiók egymáshoz való összevonását végzik. A RegionDilation gyakorlatilag megtalálja a teljes („Minkowski-összeg”) „egyesített régiót”, amelyet úgy kapunk, hogy egy régiót egy másik régió minden pontjához transzláljuk.
Miért hasznos ez? Kiderült, hogy sok oka van. Az egyik példa a „zongoramozgató probléma” (más néven a robotok mozgástervezési problémája). Adott, mondjuk, egy téglalap alakú alakzat, van-e mód arra, hogy azt (a legegyszerűbb esetben, forgatás nélkül) egy bizonyos akadályokat (például falakat) tartalmazó házon keresztül manőverezzük?
Alapvetően azt kell tennünk, hogy vesszük a téglalap alakzatot, és „kitágítjuk vele a szobát” (és az akadályokat):
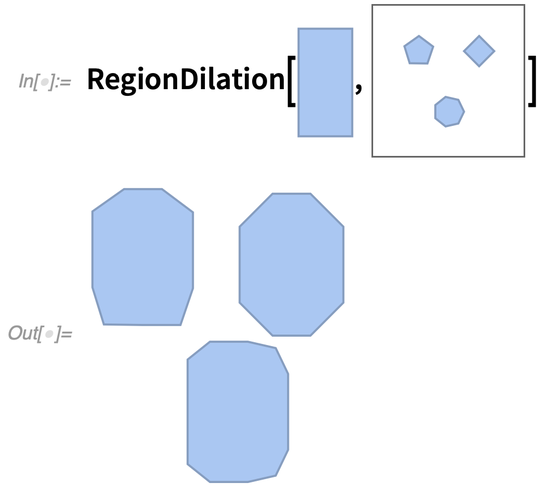 |
Aztán ha van egy összefüggő útvonal, ami „megmaradt” az egyik pontból a másikba, akkor a zongorát ezen az úton lehet mozgatni. (És persze ugyanezt meg lehet csinálni a robotokkal is egy gyárban, stb. stb. stb.)
A RegionDilation hasznos az alakzatok „kisimítására” vagy „eltolására” is, például CAD alkalmazásokhoz:
 |
Legalábbis egyszerű esetekben „Descartes-szerűen” lehet vele haladni, és explicit képleteket kaphatunk:
 |
És mellesleg mindez tetszőleges számú dimenzióban működik, ami hasznos módot biztosít mindenféle „új alakzat” létrehozására (például a henger a korongnak egy vonallal való tágulása 3D-ben).
Még több vizualizáció
Íme egy 3D-s véletlenszerű séta, amelyet a ListLinePlot3D-vel rendereltünk:
 |
Ha több adatlistát ad meg, a ListLinePlot3D külön-külön ábrázolja őket:
 |
A vektormezők ábrázolását először a 7.0 verzióban (2008) vezettük be, olyan funkciókkal, mint a VectorPlot és a StreamPlot, amelyeket a 12.1 és 12.2 verzióban jelentősen továbbfejlesztettünk. A 12.3-as verzióban most hozzáadtuk a StreamPlot3D (valamint a ListStreamPlot3D) funkciót. Íme egy 3D vektormező áramvonalainak ábrázolása, a mező erőssége szerint színezve:
|
|
A vektormezők ábrázolását először a 7.0 verzióban (2008) vezettük be, olyan funkciókkal, mint a VectorPlot és a StreamPlot, amelyeket a 12.1 és 12.2 verzióban jelentősen továbbfejlesztettünk. A 12.3-as verzióban most hozzáadtuk a StreamPlot3D (valamint a ListStreamPlot3D) funkciót. Íme egy 3D vektormező áramvonalainak ábrázolása, a mező erőssége szerint színezve:

A tengelyek kicsit úgy működnek, mint a nyilak: először megadjuk a „magstruktúrát”, majd megmondjuk, hogyan kell megjegyezni. Itt van egy tengely, amely lineárisan van felcímkézve 0-tól 100-ig egy vonalon:








Aranycsomók és egyéb anyagi kérdések



A felületekkel kölcsönhatásba lépő fény modellezésének – és a „fizikailag alapú renderelésnek” – bonyolult története, amelyről a 12.3-as verzió egy egész monográfia szól:

Fák!
Az alapvető objektum a Tree:

Számos „*Tree” függvény létezik a fák létrehozására, és „Tree*” függvények a fák más dolgokká való átalakítására. A RulesTree például egy fát állít össze szabályok egymásba ágyazott gyűjteményéből:





Amikor a Tree-t terveztük, először azt gondoltuk, hogy külön szimbolikus reprezentációval kell rendelkeznünk a teljes fák, a részfák és a levélcsomópontok számára. De kiderült, hogy elegáns tervezést tudtunk készíteni csak a Tree-vel. A fa csomópontjai jellemzően a Tree[payload, {child1, child2, …}] formájúak, ahol a childi részfák. Egy csomópontnak nem feltétlenül kell, hogy legyen payloadja, ebben az esetben egyszerűen megadhatjuk Tree[{child1, child2, …}] alakban. A levélcsomópont ekkor Tree[expr, None] vagy Tree[None].
Ennek a felépítésnek egy nagyon szép tulajdonsága, hogy a fák azonnal felépíthetők részfákból, egyszerűen a kifejezések egymásba fészkelésével:















Dátumok, időpontok és milyen gyorsan forog a Föld?
Íme egy dátum a svéd nyelvben használt szabványos konvenciókkal:


A 12.3-as verzióban új, részletes specifikáció van arra vonatkozóan, hogy hogyan kell felépíteni a dátumformátumokat:


A sziderikus (csillagalapú) időt a 10.0 verzióban (2014) vezettük be:



Ez megmondja, hogy a nap jelenleg mennyivel hosszabb a 24 óránál:


A gépi tanulás és a neurális hálók élvonala
Prédikátor képzése a „borminőség” előrejelzésére a bor kémiai tartalmából:




A gépi tanulás egy finom, de fontos kérdése az osztályozók „megbízhatóságának” kalibrálása. Ha egy osztályozó azt mondja, hogy bizonyos képek 60%-os valószínűséggel macskák, akkor ez azt jelenti, hogy 60%-uk valóban macska? Egy nyers neurális háló ezt jellemzően nem fogja helyesen megítélni. A valószínűségek kalibrációs görbe segítségével történő újrakalibrálásával azonban közelebb kerülhetünk hozzá. A 12.3-as verzióban az automatikus újrakalibrálás mellett az olyan funkciók, mint a Classify, támogatják az új RecalibrationFunction opciót, amely lehetővé teszi, hogy megadjuk, hogyan történjen az újrakalibrálás.
A gépi tanulási keretrendszerünk fontos része a neurális hálók mélyreható szimbolikus támogatása. És folytattuk a kutatási irodalomból származó legújabb neurális hálók elhelyezését a Neural Net Repository-ban, így azok a NetModel segítségével azonnal elérhetővé válnak a keretrendszerünkben.
A 12.3-as verzióban néhány extra funkcióval bővítettük keretrendszerünket, például „swish” és „hardswish” aktiválási függvényekkel az ElementwiseLayerr számára. „A motorháztető alatt” sok minden történt. Továbbfejlesztettük az ONNX importálást és exportálást, nagymértékben egyszerűsítettük az MXNet integrációnk szoftverfejlesztését, és majdnem elkészült a keretrendszerünk Apple Siliconhoz készült natív verziója (a 12.3.0-ban a keretrendszer a Rosetta segítségével fut).
Folyamatosan arra törekszünk, hogy a lehető legjobban automatizáljuk a gépi tanulási keretrendszerünket. És ennek elérésében nagyon fontos volt, hogy ennyi kurrens net kódolót és dekódolót kaptunk, amelyeket azonnal használhatsz különböző típusú adatokon. A 12.3-as verzióban ennek egyik kiterjesztése egy tetszőleges jellemző-kivonó mint hálózati kódoló használata, amelyet a fő képzési folyamat részeként lehet betanítani. Miért fontos ez? Nos, ez egy edzhető módot biztosít arra, hogy különböző típusú adatok tetszőleges gyűjteményeit tápláljuk egy neurális hálóba, még akkor is, ha nincs előre meghatározott módja annak, hogy egyáltalán tudjuk, hogyan lehet az adatokat egy neurális hálóba való bevitelre alkalmas számtömbökké alakítani.
Amellett, hogy közvetlen hozzáférést biztosít a legmodernebb gépi tanuláshoz, a Wolfram Language egyre több beépített függvénnyel rendelkezik, amelyek erőteljes belső használatot biztosítanak a gépi tanulásnak. Az egyik ilyen függvény a TextCases. A 12.3-as verzióban a TextCases jelentősen megerősödött, különösen a kevésbé gyakori szöveges tartalomtípusok, például a „Protein” és a „BoardGame” támogatása terén:

Újdonságok a videóban
A 12.3 új képességeinek egyik fő csoportja a programozott videógenerálás körül forog. Három alapvető új funkciót tartalmaz: FrameListVideo, SlideShowVideo és AnimationVideo.
A FrameListVideo a képek nyers listáját veszi, és úgy állít össze egy videót, hogy azokat egymás után következő nyers képkockákként kezeli. A SlideShowVideo hasonlóan egy képlistát fogad el, de most egy „diavetítéses videót” hoz létre, amelyben minden egyes kép egy meghatározott időtartamig jelenik meg. Itt például minden kép 1 másodpercig jelenik meg a videóban:

Az AnimationVideo nem vesz létező képeket; ehelyett egy kifejezést vesz, majd „Manipulatestílusban” kiértékeli azt egy paraméter értéktartományára. (Gyakorlatilag ez olyan, mint az Animate videókészítő analógja).




Így például itt van az én zöld képernyőm a fenti folyamattal kompozitálva:

A 12.3-as verzió néhány új videoszerkesztési képességgel is bővült. A VideoTimeStretch lehetővé teszi az idő „eltorzítását” egy videóban bármilyen megadott függvénnyel. A VideoInsert segítségével videoklipet illeszthet be egy videóba, a VideoReplace segítségével pedig egy videó egy részét cserélheti le egy másikra.
Az egyik legjobb dolog a Wolfram Nyelvben a videóban az, hogy a nyelv összes eszközével azonnal elemezhető. Ez magában foglalja a gépi tanulást is, és a 12.3-as verzióban megkezdtük a folyamatot, amely lehetővé teszi a videók kódolását neurális hálós számításokhoz. A 12.3-as verzió tartalmaz egy egyszerű képkocka-alapú háló kódolót a videókhoz, valamint néhány beépített jellemző-kivonatolót. Hamarosan továbbiak is érkeznek, beleértve a Wolfram Neural Net Repositoryban található különféle videófeldolgozó és -elemző hálókat.
További információ a kémia témakörben
A 12.3-as verzióban például a Molecule új tulajdonságokkal rendelkezik, mint például a „TautomerList” (lehetséges átkonfigurációk oldatban):









A hurok bezárása a vezérlőrendszerek számára
Kezdjük egy olyan modell importálásával, amelyet a Wolfram System Modeler programban hoztunk létre. Ebben a konkrét esetben egy egyszerű tengeralattjáró modelljéről van szó:


Tehát az alapul szolgáló rendszermodell ismeretében hogyan tervezhetjük meg ezt a szabályozót? Nos, a 12.3-as verzióban sikerült ezt néhány függvényre redukálnunk. Először megadjuk a modellt és a szabályozandó paramétereket, és megadjuk a tervezési célunkat a kívánt sajátértékek megadásával:



Hogyan is működött ez? Nos, ahogy az ilyen típusú szabályozórendszerek tervezésénél jellemző, először is megtaláltuk a mögöttes modell linearizálását, amely megfelel annak a területnek, amelyben működni fogunk:







Egyszerűbb lesz kódot írni a jegyzetfüzetekben
Ez azt jelenti, hogy például ahelyett, hogy a kódod így nézne ki


De ha [[ … ]]-vel foglalkozol, nem tudsz csak úgy „helyi helyettesítést” végezni anélkül, hogy ne okozna zavart, hogy egyes ]]-ek 〛-ként jelennek meg, míg mások a rutinszerű szerkesztés eredményeként ]]-re bomlanak szét.
A 12.3-as verzióban egyáltalán nem végzünk cseréket, hanem csak meghatározott karaktersorozatokat (mint például a ]]) adunk ki speciális módon. Ennek eredményeképpen nagyon általános „ligatúra-szerű” viselkedést tudunk támogatni, és a visszaléptetés mindig pontosan megfordítja a beírt karaktereket.
Az AutoOperatorRenderings segítségével a beírt kód szebben fog kinézni és könnyebben olvasható lesz. De van egy második, jelentősebb változás is a kód bevitelében, amely a 12.3-as verzióban már elérhető. Ez még meglehetősen kísérleti jellegű, így alapértelmezésben nem lett bekapcsolva, de ha akarod, kifejezetten bekapcsolhatod, egyszerűen csak kiértékelve a

Ez azt jelenti, hogy ha beírja a

Mi történik tehát a régi gépelési szokásaiddal? Nos, továbbra is használhatja őket. Ugyanis a ] beírásával „átírhatod” a záró ]-t. És ez azt jelenti, hogy pontosan ugyanazokat a karaktereket gépeli be, mint korábban. De a lényeg az, hogy nem kell. A ] már ott van neked.
Miért fontos ez? Alapvetően azért, mert ez azt jelenti, hogy többé nem kell gondolkodnod a határolójelek illesztésén. Ez automatikusan megtörténik helyetted. A 3.0-s verzió (1996) óta van szintaxis színezésünk, amely jelzi, ha a határolójelek nem lettek lezárva – és azt javasolja, hogy zárja le őket. De most már a lezárás automatikusan megtörténik. És ez különösen azt jelenti, hogy a beírt kifejezések mindig „teljesnek” fognak látszani, és nem fognak mindenféle szerkezeti változások történni az egyes karakterek beírása közben.
Mondanom sem kell, hogy ez az egész sokkal trükkösebb, mint amilyennek elsőre tűnik. Tegyük fel, hogy már beírtál egy bonyolult kifejezést, és most hozzáadsz egy nyitó elválasztójelet, vagy ami még rosszabb, több nyitójelet. Hová kerülnek a záró elválasztójelek? Mennyit zárjanak be a már meglévő kódból? Néha ez elég nyilvánvaló, de néha nem. A helytelenül hozzáadott záró elválasztójelet mindig törölhetjük, de mi keményen dolgozunk azon, hogy a megfelelő heurisztikát használva vagy a megfelelő helyre tegyük a zárójelet, vagy egyáltalán ne tegyük.
Mi a baj ezzel a kóddal? Kódelemzés és segítségnyújtás
Évtizedek óta vannak olyan dolgok, mint a szintaxis színezés és a hiányzó argumentumok ^. És ezek rendkívül hasznosak. De amit mi akarunk, az valami globálisabb. Valami, ami nem annyira a helyesírás-ellenőrzéshez hasonlít, mint inkább ahhoz, hogy meg tudjuk mondani, hogy egy szövegdarab a megfelelő dolgot jelenti-e.
Azt gondolhatnánk, hogy ezzel valamiféle filozófiai probléma van. A Wolfram Nyelvben minden kóddarab – feltéve, hogy szintaktikailag helyes – egy szimbolikus kifejezés, amely valamilyen szinten jelent valamit. A kérdés az, hogy ez a „valami” az-e, amit akarunk. És a lényeg az, hogy a „helyes kód” tipikus szerkezetének ismeretében gyakran nagyon jó tippeket lehet adni. És ezt teszi az új kódelemző rendszerünk.
Tegyük fel, hogy van ez az egyszerű kódrészlet:


Íme egy kicsit bonyolultabb példa:

A Kódelemzés elkapja a valódi hibákat? Igen, és erre bizonyítékunk is van, mivel lefuttattuk a belső kódunkon, valamint a dokumentációnkban szereplő példákon. Például a 12.2-es verzióban a FitRegularization dokumentációja a következő példát tartalmazta:


Fejlődés a fordítóban: Kompilátor: hordozhatóság és könyvtárak
A 12.3-as verzióban fontos lépést tettünk annak érdekében, hogy megkönnyítsük az ezzel kapcsolatos munkafolyamatokat. Tegyük fel, hogy lefordítunk egy nagyon egyszerű függvényt:

Mi ez a kimenet? Nos, a 12.3-as verzióban ez egy szimbolikus objektum, amely nyers, alacsony szintű kódot tartalmaz:

De fontos szempont, hogy minden ott van ebben a szimbolikus tárgyban. Tehát csak fel kell venni és használni:
 |
Van azonban egy kis bökkenő. Alapértelmezés szerint a FunctionCompile nyers, alacsony szintű kódot generál annak a számítógépnek a típusára, amelyen fut. Ha azonban a kapott CompiledCodeFunction-t egy másik típusú számítógépre viszi, az nem fogja tudni használni az alacsony szintű kódot. (A fordítás előtt megtartja az eredeti kifejezés másolatát, így továbbra is futtatható, de nem lesz meg a lefordított kód hatékonysági előnye).
A 12.3-as verzióban a FunctionCompile új opciót tartalmaz: TargetSystem. A TargetSystem → All opcióval pedig megmondhatja a FunctionCompile-nak, hogy az összes jelenlegi rendszerhez készítsen keresztkompilált alacsony szintű kódot:
 |
Mondanom sem kell, hogy lassabban megy az összeállítás. De az eredmény egy hordozható objektum, amely alacsony szintű kódot tartalmaz minden jelenlegi platformra:
 |
Tehát ha van egy jegyzetfüzeted – vagy egy Wolfram Function Repository bejegyzésed -, amely ilyen CompiledCodeFunction-t tartalmaz, akkor elküldheted bárkinek, és az automatikusan lefut a rendszerén.
Van még néhány egyéb finomság is. A FunctionCompile-ben alapértelmezetten létrehozott alacsony szintű kód valójában LLVM IR (intermediate representation) kód, nem pedig tiszta gépi kód. Az LLVM IR minden egyes platformra optimalizálva van, de amikor a kódot betöltjük a platformra, van egy kis plusz lépés, hogy helyben átkonvertáljuk tényleges gépi kóddá. A UseEmbeddedLibrary → True használatával elkerülheti ezt a lépést, és előre létrehozhat egy teljes könyvtárat, amely tartalmazza a kódját.
Ez némileg gyorsabbá teszi a fordított kód betöltését a platformon, de a bökkenő az, hogy egy teljes könyvtár létrehozása csak egy adott platformon lehetséges. Megépítettük egy felhőalapú fordítás-az-a-szolgáltatás rendszer prototípusát, de még nem egyértelmű, hogy a sebességnövekedés megéri-e a fáradságot.
A 12.3-as verzió másik új fordítófunkciója, hogy a FunctionCompile mostantól képes egy listát vagy asszociációt venni a függvényekből, amelyeket együtt fordítanak le, optimalizálva az összes függőségükkel együtt.
A fordító továbbra is egyre erősebb és szélesebb körű, egyre több függvény és típus (például „Integer128”) támogatott. És a nagyobb léptékű fordítási projektek támogatása érdekében a 12.3-as verzióban hozzáadott valami a CompilerEnvironmentObject. Ez egy szimbolikus objektum, amely a lefordított erőforrások egész gyűjteményét reprezentálja (például a FunctionDeclaration által definiált), amelyek könyvtárként viselkednek, és azonnal felhasználhatók a további fordítási munkálatok környezetének biztosítására.
Shell, Java, ….: Új beépített külső kapcsolatok
First, there’s the shell. Back in Version 1.0, there was the notion of “shell escapes”: type ! at the beginning of a line, and everything after it would be sent to your operating system shell. A third of a century later, it’s a bit more polished and sophisticated, though it’s the same basic idea.
Írja be a > billentyűt a jegyzetfüzetbe, majd válassza a Shell parancsot, és írja be a shell parancsot:
 |
A shell-ből származó stdout visszhangra kerül, ahogyan generálódik, majd ami visszajön, az egy szimbolikus objektum lesz – amiből olyan dolgokat lehet kinyerni, mint a kilépési kód vagy az stdout:
 |
A korábbi verziókban olyan nyelvek, mint a Python, a Julia, az R stb., valamint az SQL számára is adtunk lehetőségeket. Ebben a verzióban hozzáadjuk az Octave támogatását is (igen, a függvénynevek nem nagyszerűek):
 |
De a lényeg itt az, hogy az adatszerkezeteket úgy kapcsoltuk össze, hogy egy Octave tömb megfelelő kifejezésként érkezzen vissza, ebben az esetben listák listájaként (amelyek közelítő számokat tartalmaznak, mert az Octave csak ezt kezeli).
Egyébként, bár a jegyzetfüzetekben lévő külső nyelvi cellák szépek, semmiképpen sem kell használni őket, és az ExternalEvaluate – vagy ExternalFunction – segítségével tisztán programozottan is elvégezhetünk dolgokat.
A J/Link segítségével már több mint 20 éve szoros integráció van a Wolfram Language-ben a Javával. A 12.3-as verzióban azonban úgy állítottuk be a dolgokat, hogy ahelyett, hogy a J/Link kifinomult szimbolikus interfészét használná a Java-hoz, egyszerűen csak Java kódot írhat be közvetlenül az ExternalEvaluate és a külső nyelvi cellákba:
 |
Az alapvető Java adatstruktúrákat a Wolfram Language szabványos kifejezéseiként adják vissza:
 |
A Java objektumok szimbolikus megjelenítése a J/Link segítségével történik:
 |
Minden zökkenőmentesen együttműködik a J/Linkkel. És például közvetlenül a J/Link segítségével hozhat létre Java-objektumokat – amelyeket később egy külső nyelvi cellába beírt Javával használhat:

Ha egy Java-funkciót definiálsz, az szimbolikusan egy ExternalFunction objektumként jelenik meg:
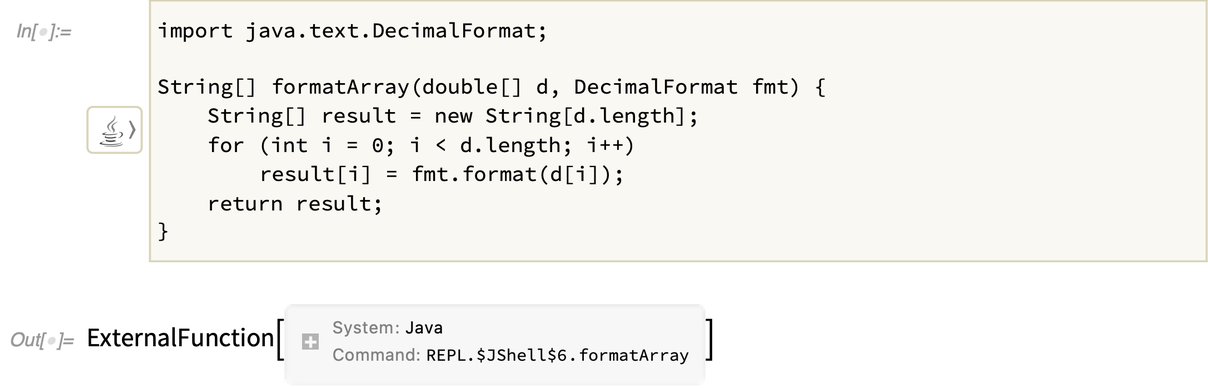
Ez a függvény egy számlistát és egy Java objektumot fogad el – olyat, amilyet fentebb a J/Link segítségével hoztunk létre:
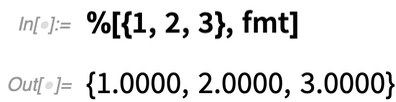
(Igen, ez a művelet rendkívül könnyen elvégezhető közvetlenül a Wolfram Nyelvben.)
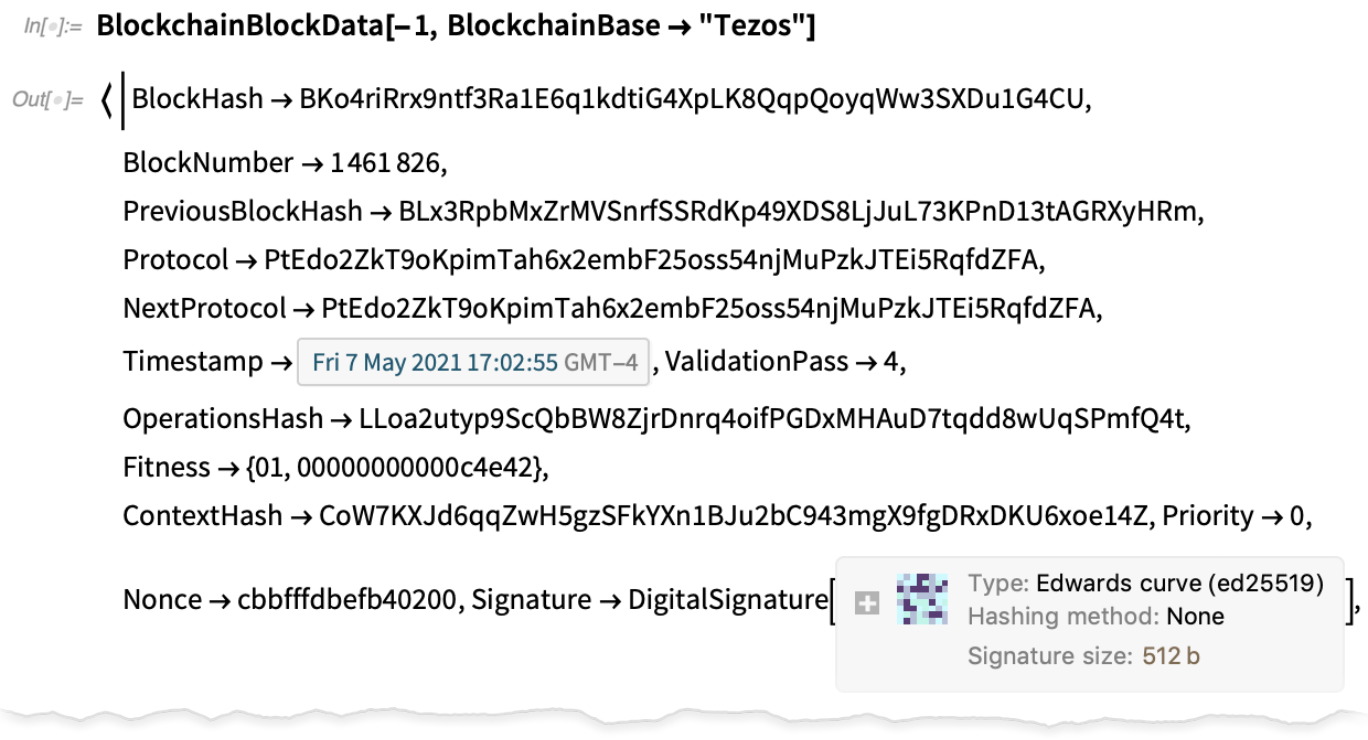
Blockchain, tárolás, hitelesítés és kriptográfia
A 12.1-es verzióban bevezettük az ExternalStorageObjectet, kezdetben az IPFS és a Dropbox támogatásával. A 12.3-as verzióban hozzáadtuk az Amazon S3 támogatását (és igen, egyszerre egy egész vödörnyi fájlt tárolhatunk és kérhetünk le):

Mindenféle külső interakció szükséges lépése a hitelesítés. A 12.3-as verzióban már támogatjuk az OAuth 2.0 munkafolyamatokat. Létrehoz egy SecuredAuthenticationKey:

Megjelenik egy böngészőablak, amely arra kéri, hogy jelentkezzen be a fiókjával – és máris indulhat.
Számos gyakori külső szolgáltatáshoz „előre csomagolt” ServiceConnect-kapcsolatokat kínálunk. Ezek gyakran hitelesítést igényelnek. Az OAuth-alapú API-khoz (például a Reddithez vagy a Twitterhez) pedig a WolframConnector alkalmazásunk közvetíti a hitelesítés külső részét. A 12.3-as verzió újdonsága, hogy a hitelesítés közvetítésére saját külső alkalmazást is használhat, így nem korlátozza a WolframConnector alkalmazás külső szolgáltatással kötött megállapodásai.
A motorháztető alatt minden, amiről itt beszélünk, a kriptográfia. A 12.3-as verzióban pedig néhány új kriptográfiai képességgel bővültünk; különösen a NIST FIPS 186-4 digitális aláírási szabványában szereplő összes elliptikus görbét támogatjuk, valamint az Edwards görbéket, amelyek a FIPS 186-5 szabvány részét képezik majd.
Mindezt úgy csomagoltuk össze, hogy nagyon egyszerűvé tegyük a blokklánc-tárcák létrehozását, a tranzakciók aláírását és az adatok kódolását a blokkláncok számára:


Elosztott számítástechnika és annak kezelése
A 12.2-es verzióban bevezettük a RemoteKernelObject-et, mint a távoli Wolfram Language képességek szimbolikus reprezentációját. A 12.2-es verziótól kezdve ez a RemoteEvaluate segítségével elérhető volt egyszeri kiértékelésekhez. A 12.3-as verzióban a RemoteKernelObject-et integráltuk a párhuzamos számításba.
Próbáljuk ki ezt az egyik gépemen. Itt van egy távoli kernelobjektum, amely egyetlen kernelt reprezentál rajta:

Most már elvégezhetünk egy számítást, itt csak a processzormagok számát kérdezzük meg:
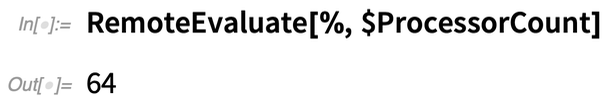
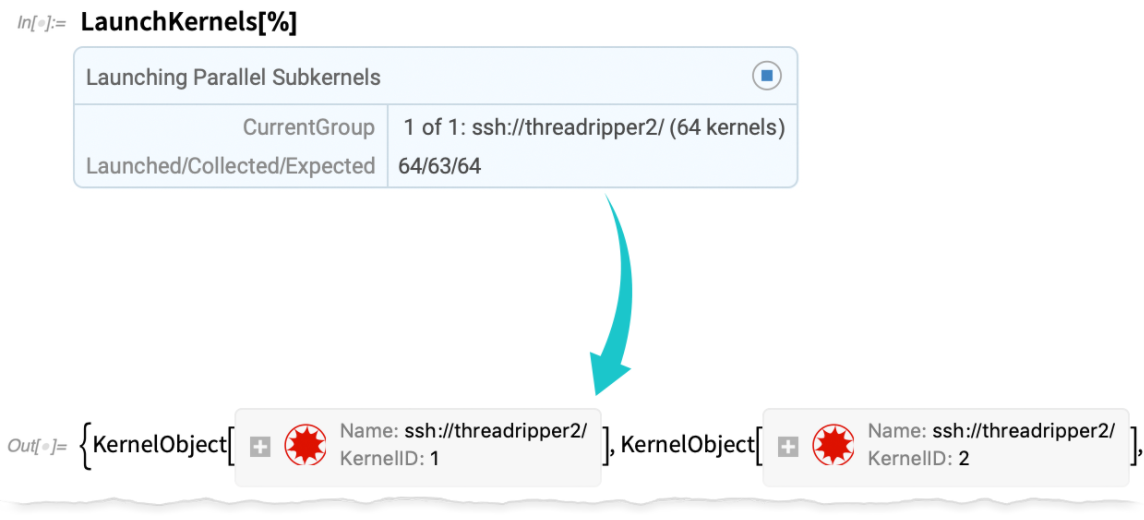
Most hozzunk létre egy távoli kernelobjektumot, amely a gép mind a 64 magját használja:

Most már el tudom indítani ezeket a rendszermagokat (és igen, sokkal gyorsabb és robusztusabb, mint korábban):
Most már használhatom ezt párhuzamos számítások elvégzésére:

A hozzám hasonló, gyakran párhuzamos számításokat végző felhasználók számára a 12.3-as verzió ezen képességeinek egyszerűsítése nagy változást jelent.
Az olyan függvények, mint a ParallelMap egyik jellemzője, hogy alapvetően csak a számítás darabjait küldik egymástól függetlenül különböző processzoroknak. A dolgok meglehetősen bonyolulttá válhatnak, ha a processzorok között kommunikációra van szükség, és minden aszinkron módon történik.
Ennek alaptudománya mélyen kapcsolódik a többutas gráfok történetéhez és a kvantummechanika eredetéhez a Fizika projektünkben. De a szoftverfejlesztés gyakorlati szintjén a versenyfeltételekről, a szálbiztonságról, a zárolásról stb. van szó. A 12.3-as verzióban pedig hozzáadtunk néhány képességet ezzel kapcsolatban.
Különösen a WithLock függvényt adtuk hozzá, amely képes fájlok (vagy helyi objektumok) zárolására egy számítás során, ezáltal megakadályozva az interferenciát a különböző folyamatok között, amelyek megpróbálnak írni a fájlba. A WithLock egy alacsony szintű mechanizmust biztosít a műveletek atomicitásának és szálbiztonságának biztosítására.
Ennek egy magasabb szintű változata a LocalSymbolban található. Tegyük fel, hogy egy helyi szimbólumot 0-ra állítunk:
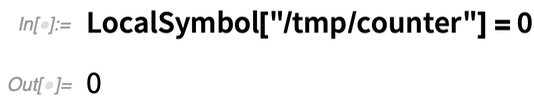
Ezután indítson el 40 helyi párhuzamos kernelt (ezeknek lokálisnak kell lenniük, hogy megosszák a fájlokat):
Most a zárolás miatt a számlálót minden egyes rendszermagban szekvenciálisan kell frissíteni: