12.2-es verziójának bevezetése: 228 új funkció és még sok más…
Nagyobb, mint valaha
Amikor idén márciusban kiadtuk a 12.1-es verziót, örömmel mondhattam, hogy a 182 új funkcióval ez volt az eddigi legnagyobb .1-es kiadásunk. De alig kilenc hónappal később még nagyobb .1-es kiadást jelentettünk meg! A ma megjelenő 12.2-es verzió 228 teljesen új funkciót tartalmaz!

Mindig van egy portfóliónyi fejlesztési projektünk, és egy adott projekt befejezése néhány hónaptól akár több mint egy évtizedig is eltarthat. És persze az egész Wolfram Language technológiai stackünknek köszönhető, hogy ilyen gyorsan tudunk ilyen sokat fejleszteni. De a 12.2-es verzió talán még lenyűgözőbb attól a ténytől, hogy csak idén június közepén összpontosítottunk a végleges fejlesztésére. Március és június között ugyanis a 12.1.1-re koncentráltunk, amely egy „csiszoló kiadás” volt. Nem új funkciók, de több mint ezer fennálló hibát javítottunk ki (a legrégebbi egy 1993-as dokumentációs hiba volt):

Hogyan terveztük meg mindazokat az új funkciókat és új funkciókat, amelyek most a 12.2-ben vannak? It’s a lot of work! And it’s what I personally spend a lot of my time on (along with other “apróságokkal„, például a fizikával stb. együtt). De az elmúlt néhány évben a nyelvtervezést nagyon nyíltan végeztük – élőben közvetítettük a belső tervezési megbeszéléseinket, és mindenféle nagyszerű visszajelzést kaptunk valós időben. Eddig körülbelül 550 órát rögzítettünk – ebből a 12.2-es verzió legalább 150 órát foglalt le.
Apropó, a 12.2 teljesen integrált új funkciói mellett a Wolfram Function Repositoryban is jelentős aktivitás tapasztalható – a 12.1 megjelenése óta 534 új, kuriózumnak számító függvény került oda mindenféle speciális célokra.
Biomolekuláris szekvenciák: Szimbolikus DNS, fehérjék stb.
A 12.2-es verzióban olyan sok különböző dolog van, olyan sok területen, hogy nehéz eldönteni, hol is kezdjem. De beszéljünk egy teljesen új területről: bioszekvencia-számítás. Igen, már több mint egy évtizede vannak gén- és fehérjeadatok a Wolfram Nyelvben. De ami újdonság a 12.2-ben, az a bio-szekvenciákkal való rugalmas, általános számítások elvégzésének kezdete. Méghozzá úgy, hogy ez illeszkedjen azokhoz a kémiai számítási képességekhez, amelyeket az elmúlt néhány évben a Wolfram Nyelvhez adtunk hozzá.
Így ábrázolunk egy DNS-szekvenciát (és igen, ez nagyon hosszú szekvenciák esetén is működik):

|
Ez fordítja le a szekvenciát peptiddé (mint egy „szimbolikus riboszóma”):
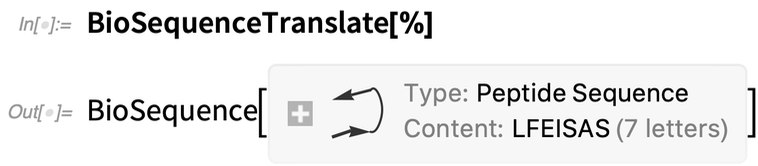
|
Most kideríthetjük, hogy mi a megfelelő molekula:
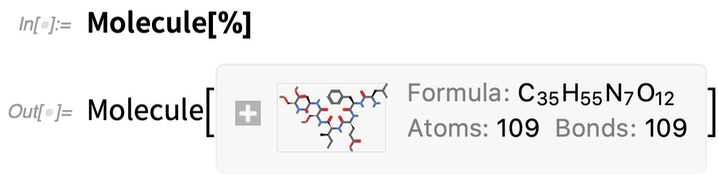
|
És vizualizálja 3D-ben(vagy számoljon ki sok tulajdonságot):
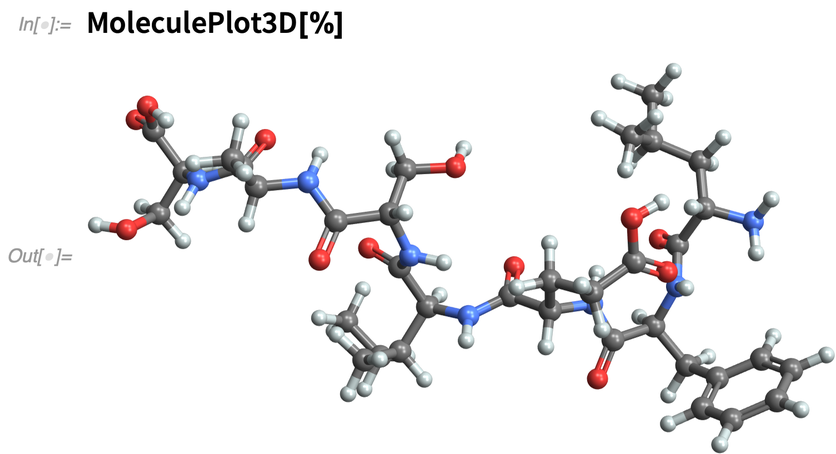
|

|
Azt gondolhatod, hogy a genomszekvenciák kezelése „csak karakterlánc-manipuláció” – és valóban, a karakterláncfüggvényeink már úgy vannak beállítva, hogy bio-szekvenciákkal dolgozzanak:
 |
De van egy csomó biológia-specifikus kiegészítő funkció is. Mint például ez, amely egy komplementer bázispáros szekvenciát talál:

|
A tényleges, kísérleti szekvenciák gyakran tartalmaznak olyan bázispárokat, amelyek valamilyen módon bizonytalanok – és ennek ábrázolására szabványos konvenciók léteznek (pl. az „S” C-t vagy G-t jelent; az „N” bármely bázist jelent). És most már a stringmintáink is megértik az ilyen dolgokat a bioszekvenciák esetében:

|

|
A BioSequence teljesen integrált a beépített genom- és fehérjeadatokkal is. Itt van egy gén, amelyet természetes nyelven „Wolfram|Alpha stílusban” kérhetünk:
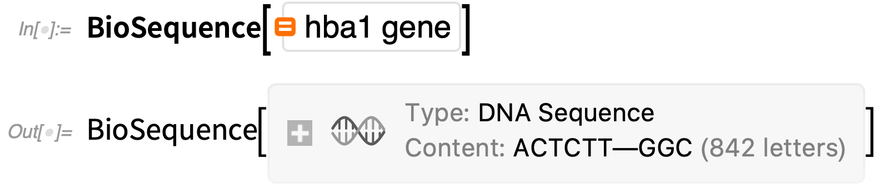 |
Most azt kérjük, hogy végezzünk szekvencia-illesztést e két gén között (ebben az esetben mindkettő emberi – ami, mondanom sem kell, az alapértelmezett):
 |
Ami a 12.2-ben van, az valójában csak a kezdete annak, amit a bioszekvencia-számításhoz tervezünk. De már most is nagyon rugalmas dolgokat lehet csinálni nagy adathalmazokkal. És például most már egyszerűen beolvashatom a genomomat FASTA fájlokból, és elkezdhetem vizsgálni…
 |
Térbeli statisztika és modellezés
Madárfészkek, aranylelőhelyek, eladó házak, anyaghibák, galaxisok helyei…. Ezek mind példák a térbeli pontadatkészletekre. A 12.2-es verzióban már az ilyen adathalmazok kezelésére szolgáló funkciók széles választékával rendelkezünk.
Itt vannak a „térbeli pontadatok” az amerikai államok fővárosainak helyére vonatkozóan:
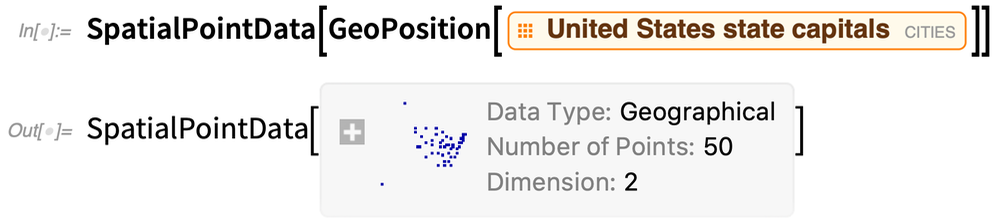 |
Mivel ez egy térinformatikai adat, egy térképen ábrázolva van:
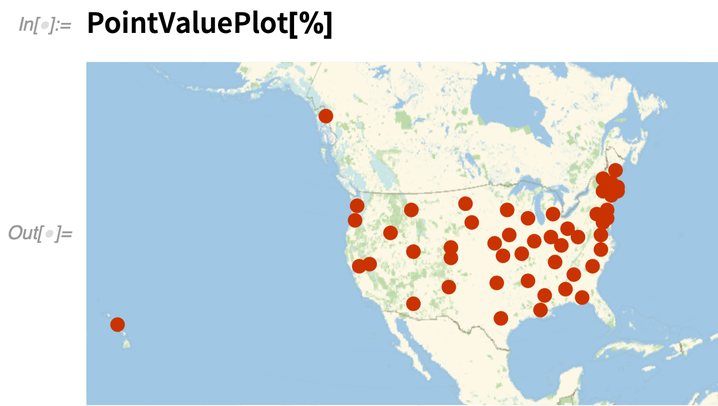 |
Szűkítsük a tartományunkat az Egyesült Államok határaira:
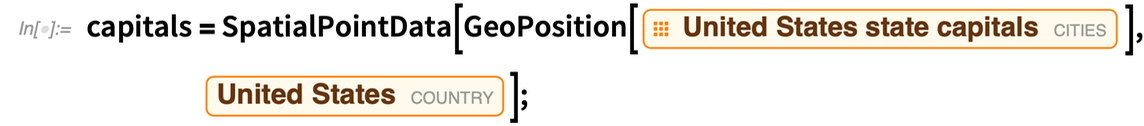 |
 |
Most már elkezdhetjük a térbeli statisztikák kiszámítását. Például itt van az államok fővárosainak átlagos sűrűsége:
 |
Tegyük fel, hogy egy állam fővárosában vagy. Itt a valószínűség, hogy megtaláld a legközelebbi másik állam fővárosát bizonyos távolságban:
 |
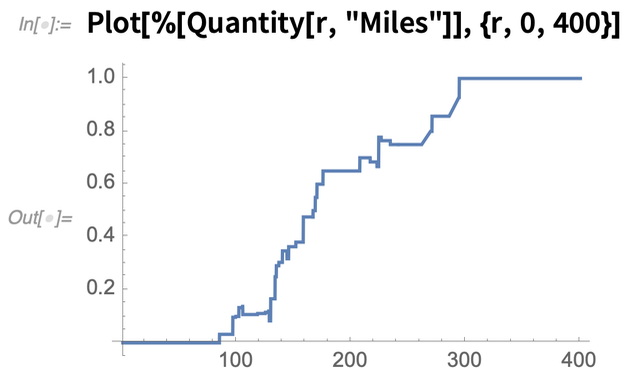 |
Ez azt vizsgálja, hogy az államok fővárosai véletlenszerűen vannak-e elosztva; mondanom sem kell, hogy nem:
 |
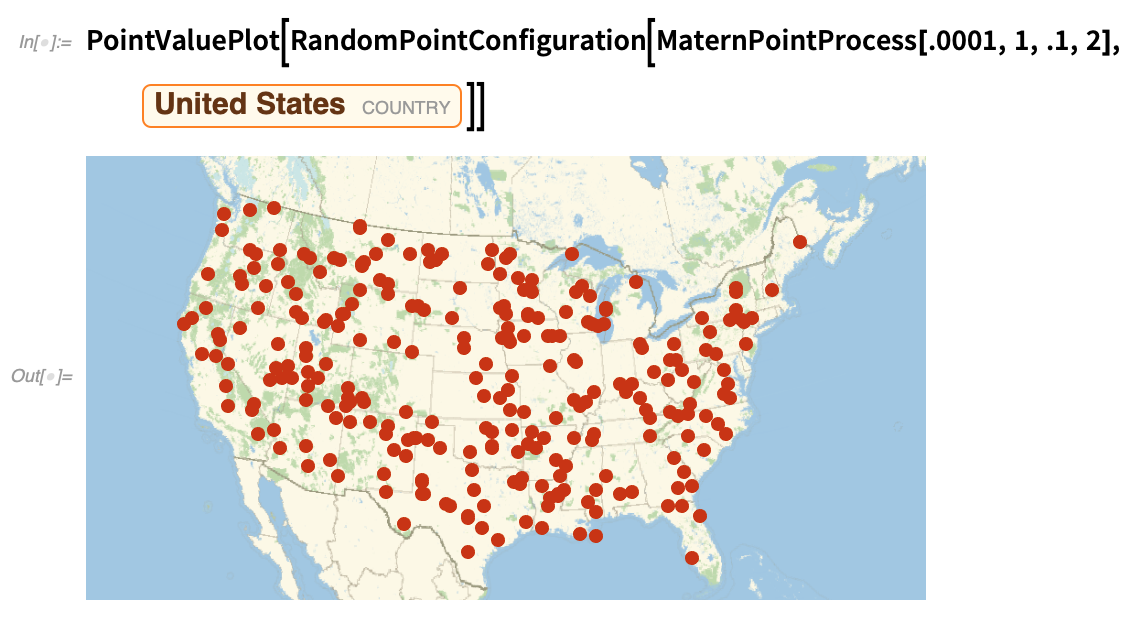 |
Fordítva is megteheti, és egy térbeli modellt illeszthet az adatokhoz:
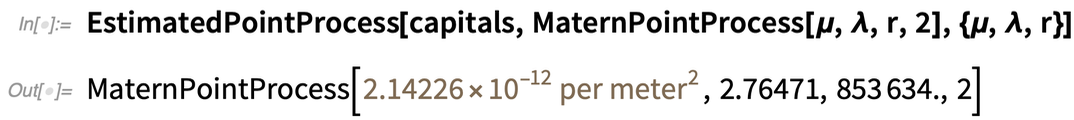 |
Kényelmes valós világbeli PDE-k
Bizonyos szempontból már 30 éve dolgozunk ezen. Az NDSolve-ot először a 2.0-s verzióban mutattuk be, és azóta folyamatosan fejlesztjük. Hosszú távú célunk azonban mindig is a valós PDE-k kényelmes kezelése volt, olyanoké, amelyek a csúcstechnológiában mindenütt előfordulnak. A 12.2-es verzióban pedig végre a mögöttes algoritmikus technológia minden darabja megvan ahhoz, hogy egy igazán áramvonalas PDE-megoldási élményt tudjunk létrehozni.
Oké, akkor hogyan adunk meg egy PDE-t? A múltban ez mindig explicit módon történt, bizonyos deriváltak, peremfeltételek stb. formájában. De a legtöbb PDE, amelyet például a mérnöki tudományokban használnak, magasabb szintű komponensekből áll, amelyek „összecsomagolják” a deriváltakat, peremfeltételeket stb. a fizika, az anyagok stb. jellemzőinek ábrázolására.
Az új PDE keretrendszerünk legalacsonyabb szintje szimbolikus „kifejezésekből” áll, amelyek a valós PDE-kben előforduló általános matematikai konstrukcióknak felelnek meg. Itt van például egy 2D-s „Laplacian-terminus„:
 |
És most már csak ennyi kell ahhoz, hogy megtaláljuk a Laplacian első 5 sajátértékét egy szabályos sokszögben:
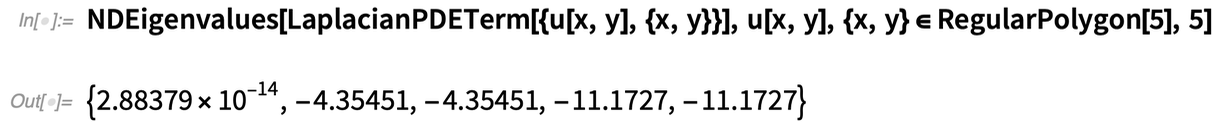 |
És az a fontos, hogy ezt a fajta műveletet egy egész csővezetékbe lehet illeszteni. Például itt megkapjuk a régiót egy képből, megoldjuk a 10. sajátmódot, majd 3D-s ábrázoljuk az eredményt::
 |
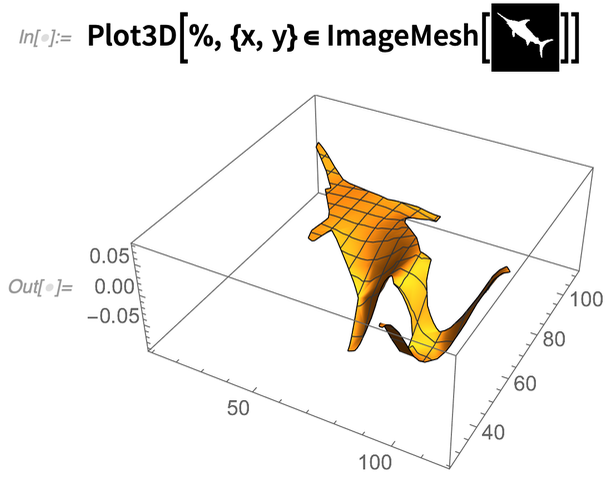 |
 |
Az egyes kifejezéseken túl vannak olyan „összetevők” is, amelyek több kifejezést kombinálnak, általában különböző paraméterekkel. Itt van egy Helmholtz PDE komponens:
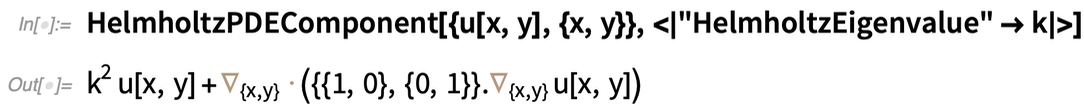 |
Egyébként érdemes rámutatni, hogy a „kifejezéseink” és „komponenseink” úgy vannak beállítva, hogy a PDE-k szimbolikus szerkezetét olyan formában ábrázolják, amely alkalmas a szerkezeti manipulációra és olyan dolgokra, mint a numerikus analízis. És annak érdekében, hogy megőrizzék a struktúrájukat, általában inaktivált formában tartjuk őket. De bármikor „aktiválhatjuk” őket, ha olyan dolgokat akarunk csinálni, mint az algebrai műveletek:
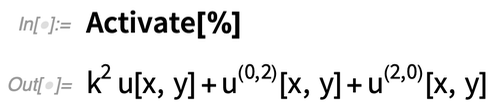 |
A valós PDE-kben gyakran tényleges fizikai folyamatokkal van dolgunk, amelyek tényleges fizikai anyagokban zajlanak. A 12.2-es verzióban már nemcsak a diffúzióval, hanem az akusztikával, a hőátvitellel és a tömegszállítással is foglalkozhatunk, és a tényleges anyagok tulajdonságait is be tudjuk táplálni. A szerkezet jellemzően úgy épül fel, hogy van egy PDE „komponens”, amely az anyag ömlesztett viselkedését reprezentálja, valamint különböző PDE „értékek” vagy „feltételek”, amelyek a peremfeltételeket képviselik.
Íme egy tipikus PDE komponens, amely a Wolfram Knowledgebase-ből származó anyagtulajdonságokat használja:
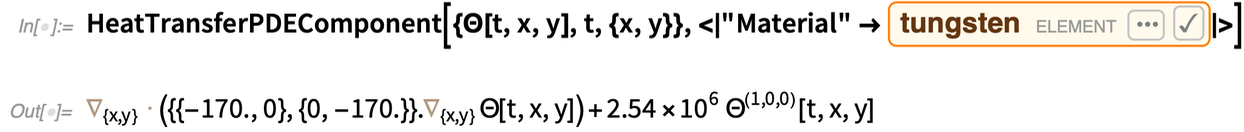 |
A lehetséges peremfeltételek eléggé változatosak és összetettek. Például a hőátadáshoz létezik HeatFluxValue, HeatInsulationValue és öt másik szimbolikus peremfeltétel-specifikációs konstrukció. Az alapötlet minden esetben az, hogy meg kell mondani, hogy (geometriai szempontból) hol érvényes a feltétel, aztán, hogy mire vonatkozik, és milyen paraméterek kapcsolódnak hozzá.
Itt van például egy olyan feltétel, amely meghatározza, hogy az x2 + y2 = 1 által meghatározott (kör alakú) tartományon kívül mindenhol van egy fix „felületi hőmérséklet” θ0:
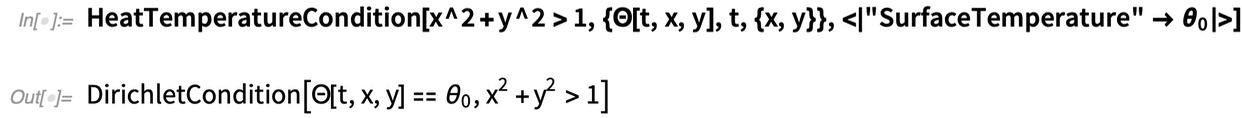 |
Itt alapvetően az történik, hogy a magas szintű „fizikai” leírásunkat explicit „matematikai” PDE-struktúrákba „fordítjuk” – például Dirichlet peremfeltételekbe.
Oké, de hogyan illeszkedik mindez a valós életben? Hadd mutassak egy példát. De előbb hadd meséljek el egy történetet. 2009-ben éppen a vezető PDE-fejlesztőnkkel teáztam. Felkaptam egy teáskanalat, és megkérdeztem: „Mikor leszünk képesek modellezni a feszültségeket ebben?”. A vezető fejlesztőnk elmagyarázta, hogy még elég sokat kell építeni ahhoz, hogy eljussunk odáig. Nos, izgatottan mondhatom, hogy 11 év munka után, a 12.2-es verzióban már ott vagyunk. És hogy ezt bebizonyítsam, a vezető fejlesztőnk most adott nekem… egy (számítási) kanalat!

A számítás lényege egy 3D-s diffúziós PDE kifejezés, amelynek „diffúziós együtthatóját” egy 4. rangú tenzor adja, amelyet a Young-modul (itt Y) és a Poisson-szám (ν) paraméterez:

Vannak peremfeltételek, amelyek meghatározzák, hogy a kanalat hogyan tartják és tolják. Ezután a PDE megoldása (ami csak néhány másodpercet vesz igénybe) megadja a kanál elmozdulási mezőjét


A PDE modellezés egy bonyolult terület, és nagy eredménynek tartom, hogy most sikerült ilyen tisztán „becsomagolni”. De a 12.2-es verzióban a PDE-modellezés tényleges technológiáján kívül valami más is fontos: a PDE-modellezésről szóló számítási esszék nagy gyűjteménye – összesen mintegy 400 oldalnyi részletes magyarázat és alkalmazási példák, jelenleg az akusztika, a hőátvitel és a tömegszállítás területén, de még sok más területen is.
Csak írja be a TEX-et
A Wolfram Nyelv lényege, hogy pontos számítási nyelven fejezd ki magad. A jegyzetfüzetekben azonban közönséges szöveggel, természetes nyelven is kifejezheted magad. De mi van akkor, ha matematikát is szeretnél megjeleníteni benne? Már 25 éve megvan az infrastruktúra a matematikai megjelenítéshez – a doboznyelvünkön keresztül. De a matematika bevitelének egyetlen kényelmes módja a Wolfram Language matematikai konstrukcióin keresztül történik – amelyeknek bizonyos értelemben számítási jelentéssel kell rendelkezniük.
De mi a helyzet a „matematikával”, amely „csak emberi szemnek” szól? Amelynek van egy bizonyos vizuális elrendezése, amit meg akarsz határozni, de aminek nem feltétlenül van semmilyen meghatározott számítási jelentés a hátterében? Nos, sok évtizede van egy jó módszer az ilyen matematika specifikálására, hála Don Knuth barátomnak: egyszerűen használjuk a TEX-et. A 12.2-es verzióban pedig már támogatjuk a Wolfram Notebooks, mind az asztali számítógépen, mind a felhőben. Alatta a TEX-et a mi dobozos reprezentációnkba alakítjuk át, így strukturálisan együttműködik minden mással. De egyszerűen csak beírhatod – és szerkesztheted – mint a TEX-et.
A felület nagyon hasonlít a Wolfram|Alpha stílusú természetes nyelvi bevitelhez használt ctrl+= felülethez. De a TEX esetében (a szabványos TEX elválasztókra bólintva) ez a ctrl>+$.
Írja be a ctrl+$ billentyűkombinációt, és megjelenik a TEX beviteli mező. Ha befejezted a TEX-et, csak nyomd meg a ctrl billentyűt, és máris megjelenik:

A TEX szöveges cellákba történő beírása a leggyakoribb dolog, amit szeretnénk. A 12.2-es verzió azonban támogatja a TEX beviteli cellákba történő beírását is:

Csak rajzolj bármit
Írja be a Canvas[] parancsot, és egy üres vásznat kap, amire azt rajzolhat, amit csak akar:
![Canvas[]](https://sciexperts.com/wp-content/uploads/2022/04/just-draw-anything-canvas-02.png)
Keményen dolgoztunk azon, hogy a rajzeszközök a lehető legergonomikusabbak legyenek.
A Normal alkalmazásával olyan grafikákat kapsz, amelyeket aztán felhasználhatsz vagy manipulálhatsz:
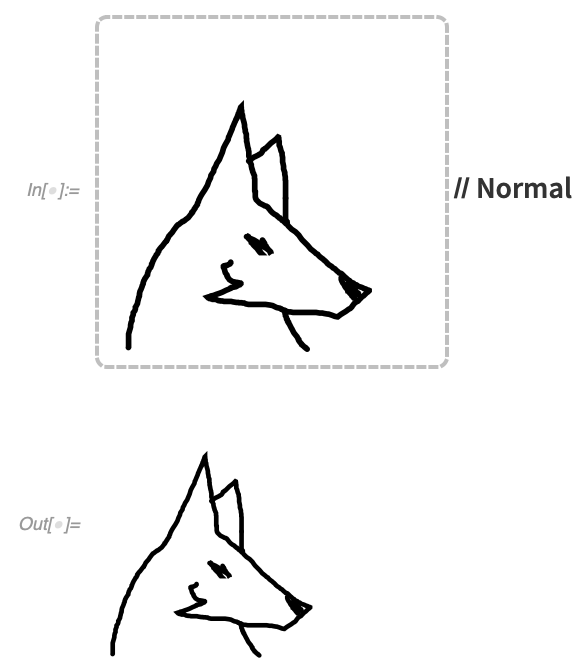

Amikor létrehoz egy vásznat, annak kezdeti tartalma bármilyen grafika lehet – és bármilyen háttérrel rendelkezhet:


Ez már egy másik molekula:
![]()

A soha véget nem érő matematikai történet
A matematika a kezdetektől fogva a Wolfram Language (és a Mathematica) egyik fő felhasználási területe. És nagyon kielégítő volt az elmúlt harmad évszázad során látni, hogy mennyi matematikai feladatot tudtunk számításossá tenni. De minél többet teszünk, annál többre jövünk rá, hogy lehetséges, és annál messzebbre juthatunk. Ez bizonyos értelemben rutinná vált számunkra. Lesz olyan területe a matematikának, amit az emberek mindig is kézzel vagy apránként végeztek. Mi pedig rájövünk: igen, erre is tudunk algoritmust készíteni! A képességek óriási tornyát, amit az évek során felépítettünk, arra használhatjuk, hogy még több matematikát rendszerezzünk és automatizáljunk; hogy még több matematikát tegyünk számítással bárki számára hozzáférhetővé. Így történt ez a 12.2-es verzióval. A „matematikai fejlődés” darabjainak egész gyűjteménye.
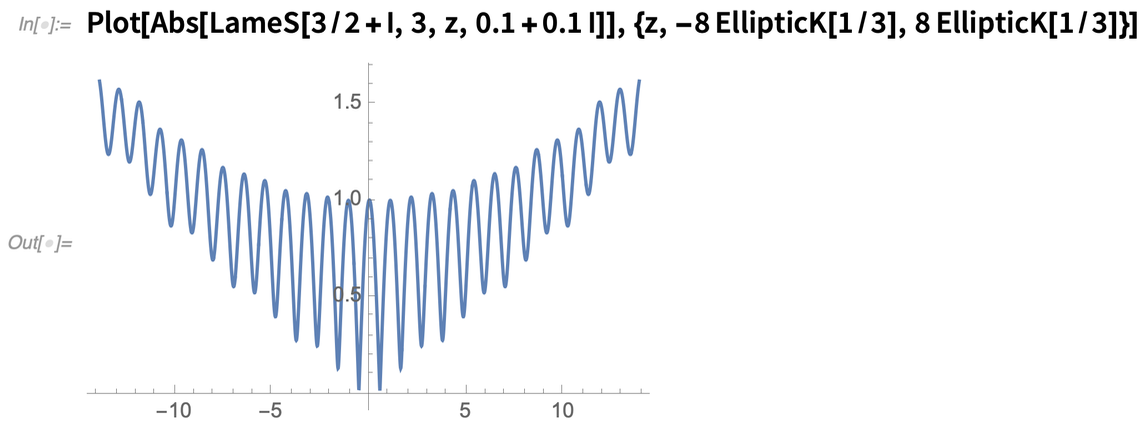
Kezdjük egy meglehetősen egyszerű dologgal: a speciális funkciókkal. Bizonyos értelemben minden speciális függvény a matematika egy bizonyos rögét foglalja magába: a számítások és tulajdonságok meghatározásának egy módja egy bizonyos típusú matematikai probléma vagy rendszer számára. A Mathematica 1.0-tól kezdve kiváló lefedettséget értünk el a speciális függvények terén, és folyamatosan bővültünk egyre bonyolultabb függvényekkel. A 12.2-es verzióban pedig a függvények egy újabb osztályát kaptuk meg: a Lamé-függvényeket.
A Lamé-függvények az ellipszoid koordináták kezelésének bonyolult világához tartoznak; a Laplace-egyenlet megoldásaként jelennek meg egy ellipszoidban. És most kiértékelhetjük őket, kiterjeszthetjük, transzformálhatjuk őket, és elvégezhetjük az összes olyan egyéb dolgot, ami egy függvény nyelvünkbe való integrálásával jár:

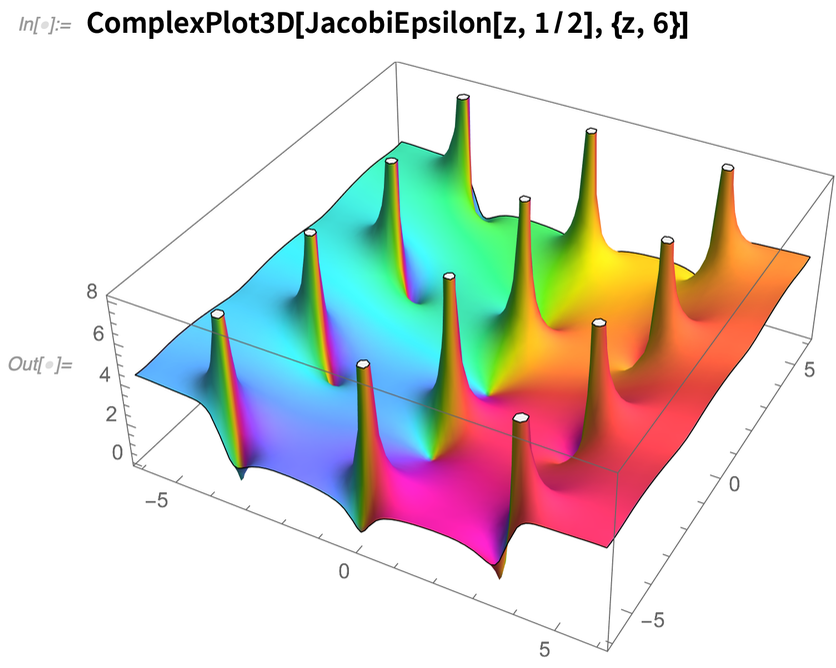
A 12.2-es verzióban is sokat dolgoztunk az elliptikus függvényeken – drámaian felgyorsítottuk a numerikus kiértékelésüket, és olyan algoritmusokat találtunk ki, amelyek ezt hatékonyan, tetszőleges pontossággal végzik. Bevezettünk néhány új elliptikus függvényt is, például a JacobiEpsilon-t, amely az EllipticE egy olyan általánosítását adja, amely elkerüli az elágazásvágásokat és megőrzi az elliptikus integrálok analitikus szerkezetét:
Néhány évtizede már sok szimbolikus Laplace– és inverz Laplace-transzformációt tudunk elvégezni. A 12.2-es verzióban azonban megoldottuk azt a finom problémát, hogy a kontúrintegrációt használjuk az inverz Laplace-transzformációk elvégzéséhez. A komplex síkban lévő függvények szerkezetének elégséges ismeretéről van szó, hogy elkerüljük az ágvágásokat és más kellemetlen szingularitásokat. Egy tipikus eredmény gyakorlatilag végtelen számú pólus felett összegez:

A kontúrintegráció és más módszerek közé pedig numerikus inverz Laplace-transzformációt is beillesztettünk. Mindez végül is egyszerűnek tűnik, de nagyon sok bonyolult algoritmikus munkára van szükség ehhez:

Egy másik új algoritmus, amelyet a finomabb „függvényértés” tesz lehetővé, az integrálok aszimptotikus kiterjesztéséhez kapcsolódik. Íme egy komplex függvény, amely λ növekedésével egyre kacskaringósabbá válik:
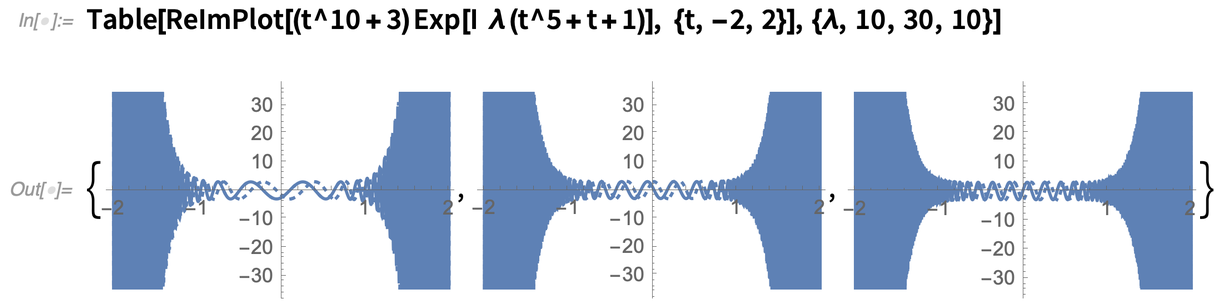
És itt van a λ→∞ aszimptotikus kiterjesztése:
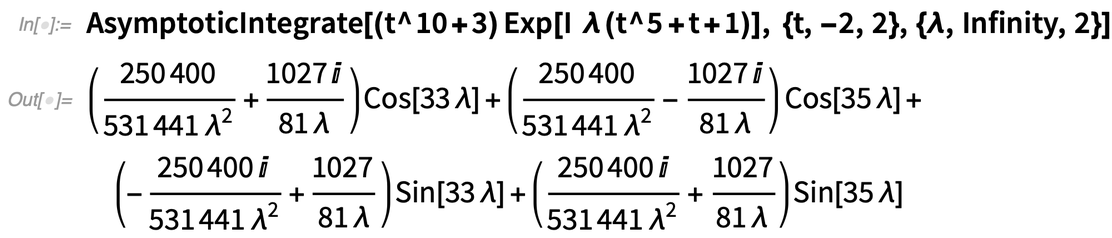
Meséljen nekem erről a funkcióról
Nagyon gyakori matematikai feladat például annak meghatározása, hogy egy adott függvény injektív-e. És ezt könnyű esetekben elég egyszerűen meg is lehet tenni. A 12.2-es verzióban azonban nagy előrelépés, hogy most már szisztematikusan ki tudjuk számolni a függvények ilyen globális tulajdonságait – nemcsak a könnyű, hanem a nagyon nehéz esetekben is. Gyakran vannak olyan tételek egész hálózatai, amelyek attól függnek, hogy a függvények rendelkeznek-e ilyen vagy olyan tulajdonsággal. Nos, most már automatikusan meg tudjuk határozni, hogy egy adott függvény rendelkezik-e ezzel a tulajdonsággal, és így, hogy a tételek érvényesek-e rá. És ez azt jelenti, hogy szisztematikus algoritmusokat hozhatunk létre, amelyek automatikusan használják a tételeket, amikor azok érvényesek.
Íme egy példa. Injektív a Tan[x]? Globálisan nem:

De egy bizonyos intervallumon igen:
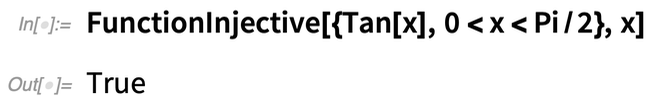
Mi a helyzet a Tan[x] szingularitásával? Ez a halmaz leírását adja:
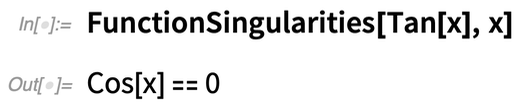
Kifejezett értékeket kaphat a Reduce:
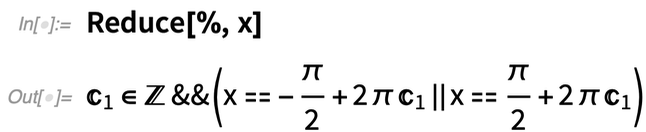
Eddig meglehetősen egyszerű. De a dolgok gyorsan bonyolultabbá válnak:
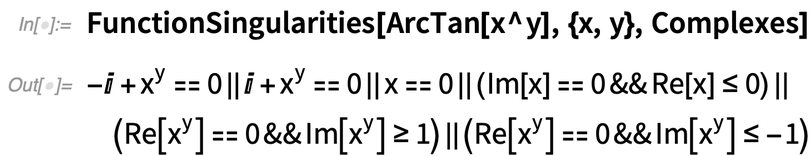
És vannak kifinomultabb tulajdonságok is, amelyekről szintén kérdezhet:


Belsőleg már régóta használunk különféle funkciótesztelő tulajdonságokat. A 12.2-es verzióval azonban a függvénytulajdonságok sokkal teljesebbek és teljes mértékben hozzáférhetőek bárki számára. Szeretné tudni, hogy felcserélhető-e két határérték sorrendje? Nézze meg a FunctionSingularities-t. Szeretné tudni, hogy végezhet-e többváltozós változást egy integrálban? Ellenőrizze a FunctionInjectivet.
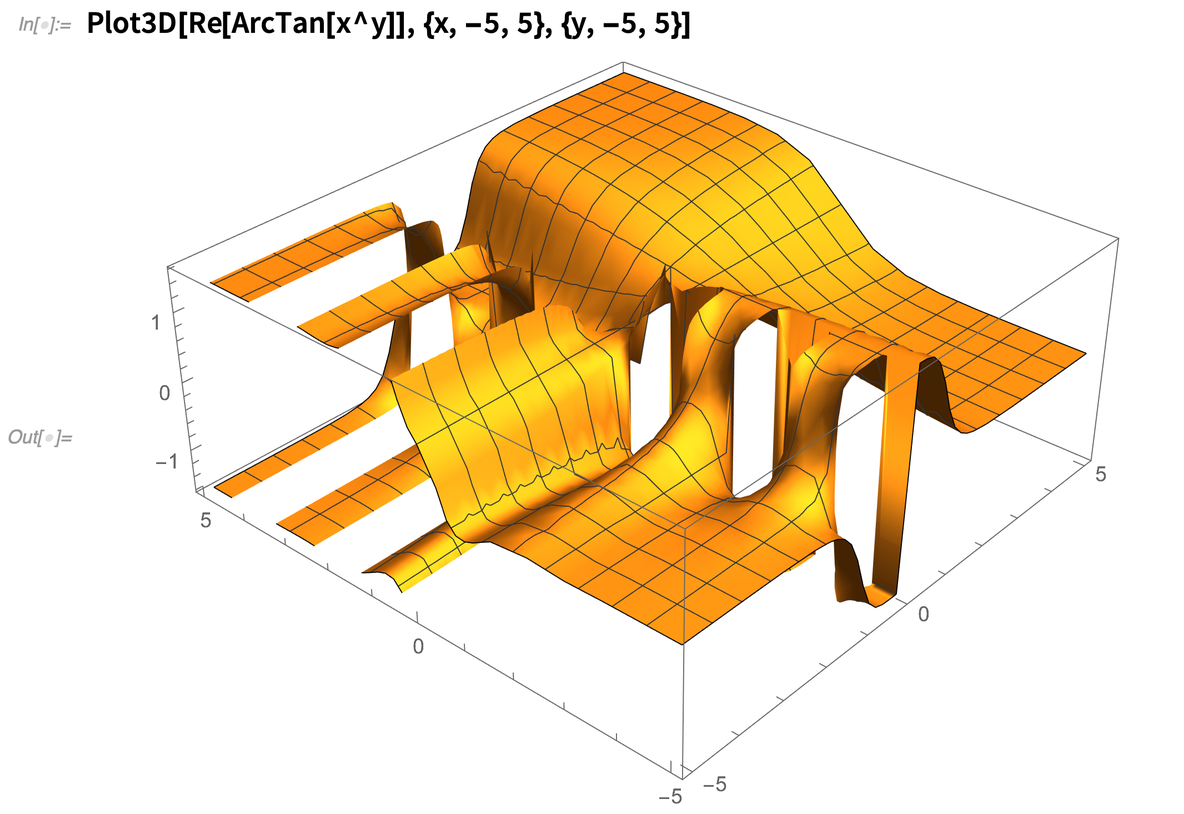
És igen, még a Plot3D-ben is rutinszerűen használjuk a FunctionSingularities-t, hogy kitaláljuk, mi történik:
Mainstreaming Video
A 12.1-es verzióban kezdtük el a videó bevezetését a Wolfram Language beépített funkciójaként. A 12.2-es verzió folytatja ezt a folyamatot. A 12.1-ben csak asztali noteszekben tudtuk kezelni a videót; most már a felhő noteszekre is kiterjesztettük – így amikor a Wolfram Language-ben videót készít, az azonnal telepíthető a felhőbe.
A 12.2 fontos új videós funkciója a VideoGenerator. Adjon meg egy függvényt, amely képeket (és/vagy hangot) készít, és a VideoGenerator ezekből videót generál (itt egy 4 másodperces videót):

A hangsáv hozzáadásához egyszerűen használhatjuk a VideoCombine-t:
![]()
Hogyan szerkeszthetnénk ezt a videót? A 12.2-es verzióban a szabványos videószerkesztési funkciók programozott változatai állnak rendelkezésünkre. A VideoSplit például meghatározott időpontokban felosztja a videót:

A Wolfram Language igazi ereje azonban abban rejlik, hogy szisztematikusan tetszőleges függvényeket alkalmazhat videókra. A VideoMap segítségével egy függvényt alkalmazhat egy videóra, hogy egy másik videót kapjon. Például fokozatosan elhomályosíthatjuk az imént készített videót:
![]()
A videók elemzéséhez két új függvény is rendelkezésre áll – a VideoMapList és a VideoMapTimeSeries—which respectively generate a list and a -, amelyek egy függvénynek a videó képkockáira, illetve hangsávjára való alkalmazásával listát, illetve idősorokat generálnak.
Egy másik új, a videofeldolgozás és -szerkesztés szempontjából rendkívül fontos funkció a VideoIntervals, amely meghatározza azokat az időintervallumokat, amelyeken belül egy adott kritérium egy videóban érvényesül:

Most például törölhetjük ezeket az intervallumokat a videóban:

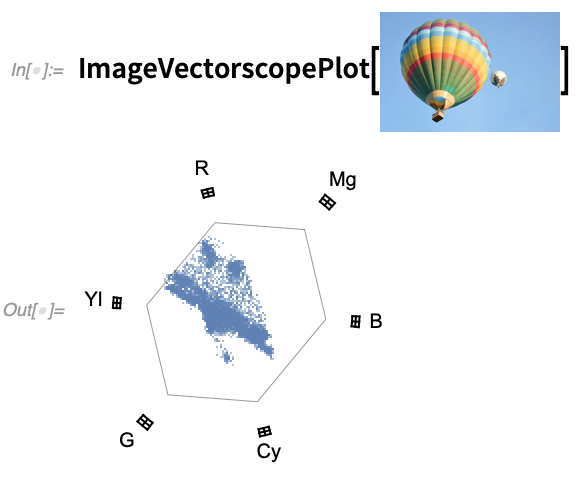
A videók gyakorlati kezelésében gyakori művelet az átkódolás. A 12.2-es verzióban a VideoTranscode funkcióval a több mint 300 támogatott konténer és kodek közül bármelyikbe konvertálhat egy videót. A 12.2 egyébként új ImageWaveformPlot és ImageVectorscopePlot függvényeket is tartalmaz, amelyeket gyakran használnak a videók színkorrekciójában:
A videók kezelésének egyik fő technikai problémája a tipikus videók nagy adatmennyiségének kezelése. A 12.2-es verzióban már finomabban szabályozható, hogy hol tárolja ezeket az adatokat. A GeneratedAssetLocation opcióval (alapértelmezett $GeneratedAssetLocation) választhat különböző fájlok, könyvtárak, helyi objektumtárolók stb. között.
De a 12.2-es verzióban van egy új funkció is a „könnyű videó” kezelésére, az AnimatedImage formájában. Az AnimatedImage egyszerűen fogadja a képek listáját, és létrehoz egy animációt, amely azonnal lejátszódik a jegyzetfüzetben – és mindent közvetlenül a jegyzetfüzetben tárol.

Nagy számítások? Küldje őket egy felhőszolgáltatóhoz!
Ez elég gyakran felmerül bennem – különösen a Physics Project-ünk miatt. Van egy nagy számítás, amit szeretnék elvégezni, de nem akarom (vagy nem tudom) a számítógépemen elvégezni. És ehelyett azt szeretném, hogy a felhőben futtassam le kötegelt feladatként.
Ez elvileg már azóta lehetséges, amióta a számítási felhőszolgáltatók léteznek. De ez nagyon bonyolult és nehézkes volt. Nos, most, a 12.2-es verzióban ez végre egyszerű. A Wolfram Language kód bármelyik darabját egyszerűen a RemoteBatchSubmit segítségével elküldheti, hogy a felhőben kötegelt feladatként futtassák.
A kötegelt számítási szolgáltató oldalán egy kis beállításra van szükség. Először is, rendelkeznie kell egy fiókkal egy megfelelő szolgáltatónál – és kezdetben az AWS Batch és a Charity Engine-t támogatjuk. Ezután konfigurálnia kell a dolgokat az adott szolgáltatóval (és vannak munkafolyamataink, amelyek leírják, hogyan kell ezt megtennie). De amint ez megtörtént, kap egy távoli kötegelt küldési környezetet, amely alapvetően minden, amire szüksége van a kötegelt feladatok küldésének megkezdéséhez:
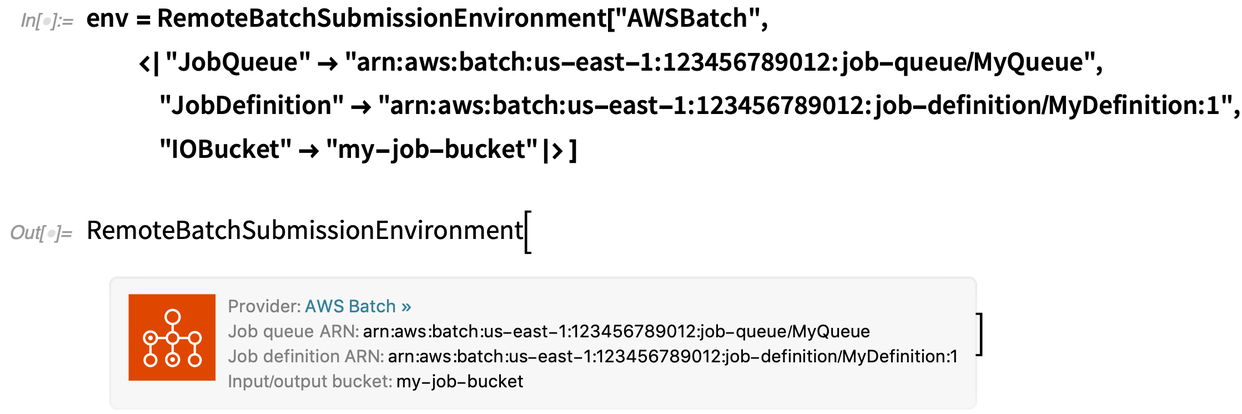
Oké, akkor mi lenne mondjuk egy neurális háló képzésének benyújtása? Itt van, hogyan futtatnám azt helyben a gépemen (és igen, ez egy nagyon egyszerű példa):

És itt van a minimális módja annak, ahogyan elküldeném, hogy fusson az AWS Batch-on:

Visszakapok egy objektumot, amely a távoli kötegelt munkámat képviseli – ezt lekérdezhetem, hogy megtudjam, mi történt a munkámmal. Először csak annyit mond, hogy a munkám „futtatható”:

Később azt fogja mondani, hogy „elindul”, majd „fut”, majd (ha minden jól megy) „sikeres”. És ha a munka befejeződött, akkor így kapod vissza az eredményt:

Rengeteg részletet lehet visszakeresni arról, hogy mi is történt valójában. Például itt van a nyers munkanapló eleje:

De a számítások távoli futtatásának igazi lényege az, hogy a számítások potenciálisan nagyobbak és ropogósabbak lehetnek, mint azok, amelyeket a saját gépein futtathat. Íme, hogyan futtathatnánk ugyanazt a számítást, mint fentebb, de most egy GPU használatát kérve:
![]()
A RemoteBatchSubmit párhuzamos számításokat is tud kezelni. Ha többmagos gépet kér, akkor azonnal futtathatja a ParallelMap stb. programot annak magjain. De még tovább mehet a RemoteBatchMapSubmit segítségével – amely automatikusan szétosztja a számításait a felhőben lévő különálló gépek egész gyűjteményén.
Íme egy példa:

Futás közben dinamikusan megjeleníthetjük a feladat egyes részeinek állapotát:
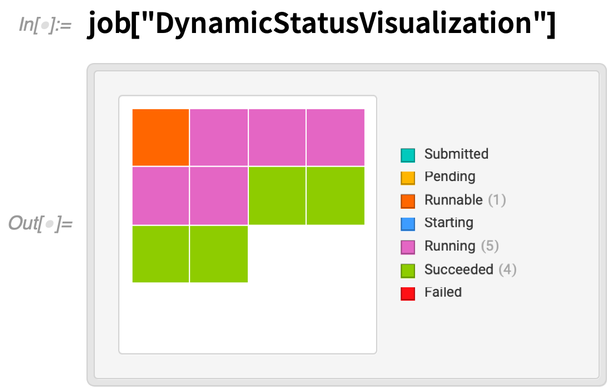
Körülbelül 5 perc múlva a munka befejeződik:


A RemoteBatchSubmit és a RemoteBatchMapSubmit magas szintű hozzáférést biztosít a felhőalapú számítási szolgáltatásokhoz általános kötegelt számításokhoz. A 12.2-es verzióban azonban közvetlen alacsonyabb szintű interfész is rendelkezésre áll, például az AWS számára.
Csatlakozás az AWS-hez:

A hitelesítés után láthatja az összes elérhető szolgáltatást:

Ez adja meg az Amazon Translate szolgáltatás fogantyúját:
Most ezt használhatja a szolgáltatás hívására:
 Természetesen a nyelvi fordítást közvetlenül a Wolfram Language programon keresztül is elvégezheti:
Természetesen a nyelvi fordítást közvetlenül a Wolfram Language programon keresztül is elvégezheti:

Tudsz-e 10 dimenziós cselekményt készíteni?
Egyszerű az egy, két vagy három dimenzióval rendelkező adatok ábrázolása. Az ennél több dimenzió esetén használhat színeket vagy más stílusjegyeket. De mire tíz dimenzióval foglalkozik, ez már nem működik. És ha például rengeteg 10D-s adatod van, akkor valószínűleg valami olyasmit kell használnod, mint a DimensionReduce, hogy megpróbáld kiszűrni az „érdekes jellemzőket”.
Ha azonban csak néhány „adatponttal” van dolgunk, más módon is megjeleníthetünk például 10 dimenziós adatokat. A 12.2-es verzióban több függvényt is bevezetünk erre a célra. Első példaként nézzük meg a ParallelAxisPlotot. Ennek lényege, hogy minden „dimenzió” egy „külön tengelyen” kerül ábrázolásra. Egyetlen pont esetében ez nem olyan izgalmas:
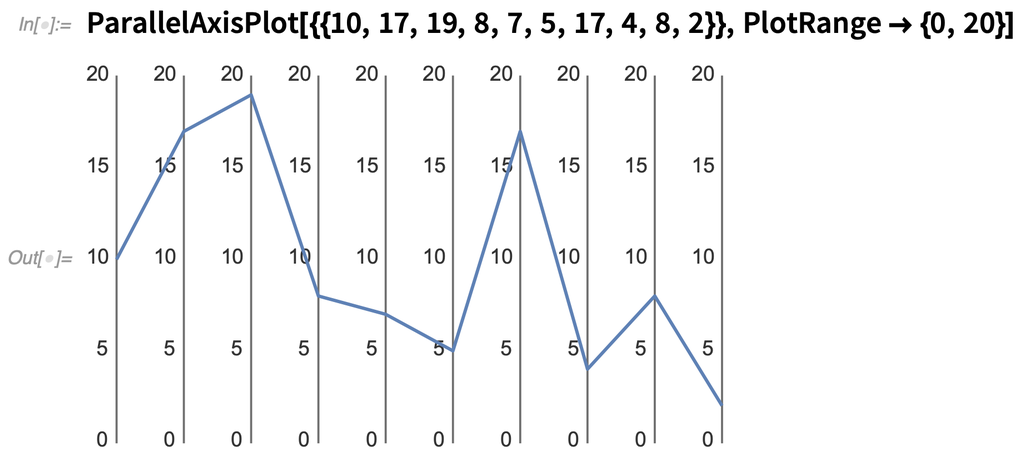
Íme, mi történik, ha három véletlenszerű „10D adatpontot” ábrázolunk:
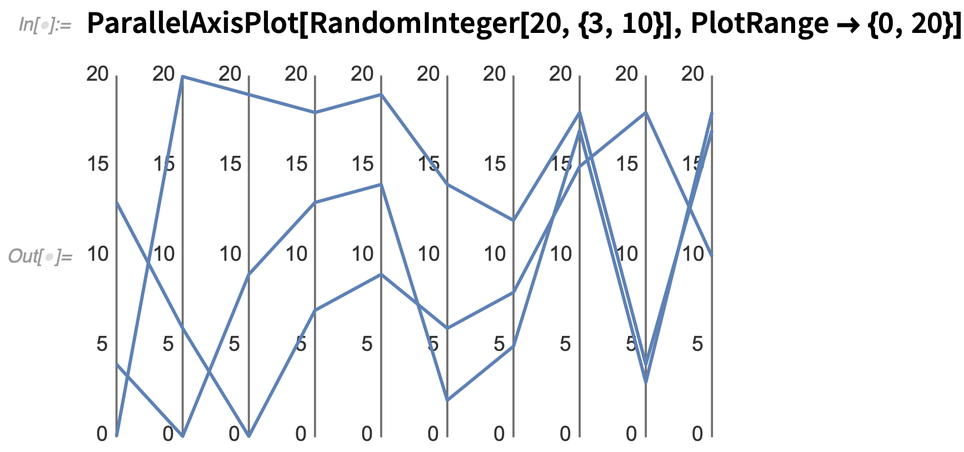
A ParallelAxisPlot egyik fontos jellemzője azonban az, hogy alapértelmezés szerint automatikusan meghatározza a tengelyek méretarányát, így nem szükséges, hogy a tengelyek hasonló dolgokat ábrázoljanak. Így például itt 7 teljesen különböző mennyiséget ábrázolunk az összes kémiai elemre vonatkozóan:
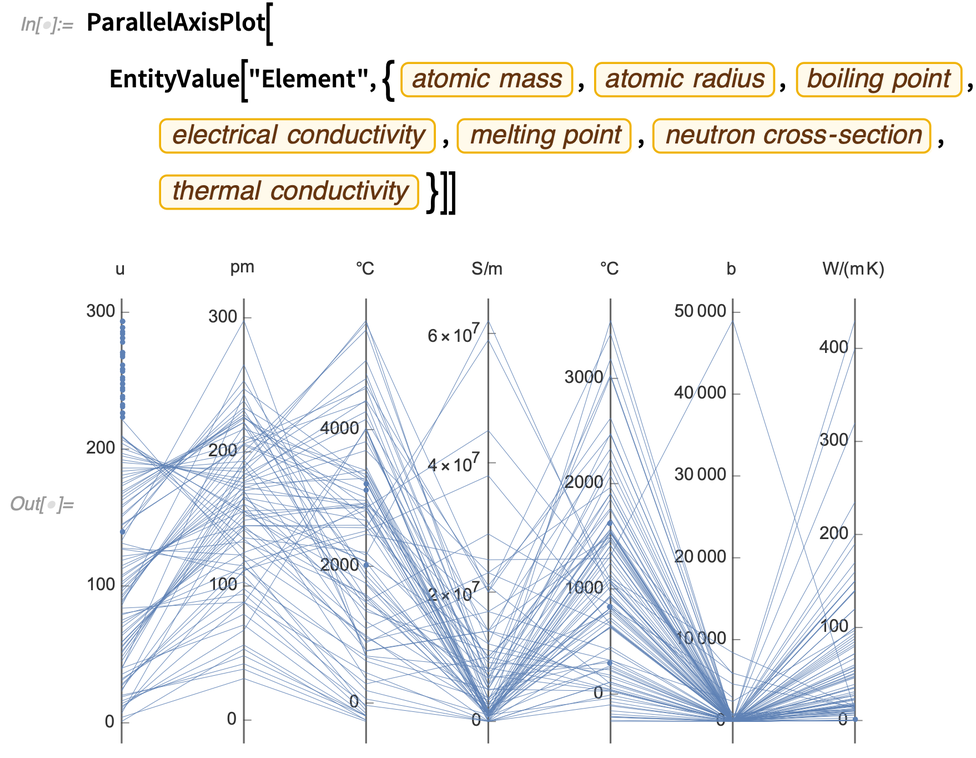
A különböző típusú nagydimenziós adatok különböző típusú ábrákon jelennek meg a legjobban. A 12.2-es verzió másik új plot-típusa a RadialAxisPlot. (Ez a plot-típus olyan neveken is ismert, mint a radar plot, a spider plot és a star plot.)
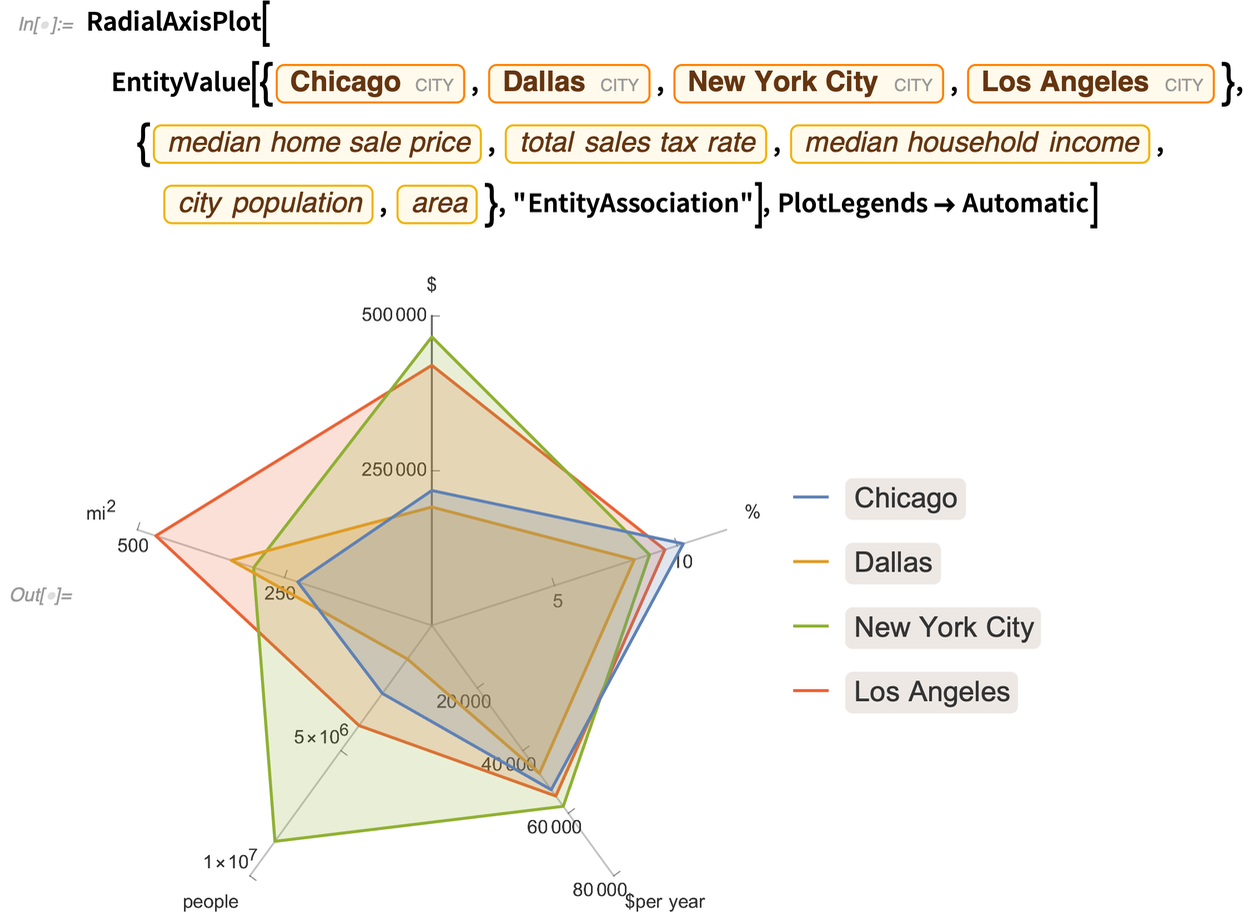
A RadialAxisPlot minden dimenziót más-más irányban ábrázol:

Általában akkor a leginformatívabb, ha nincs túl sok adatpont:
3D Array ábrák
1984-ben egy Cray szuperszámítógépet használtam arra, hogy 3D-s képeket készítsek az időben fejlődő 2D-s celluláris automatákról (igen, 35 mm-es diafilmeken rögzítve):

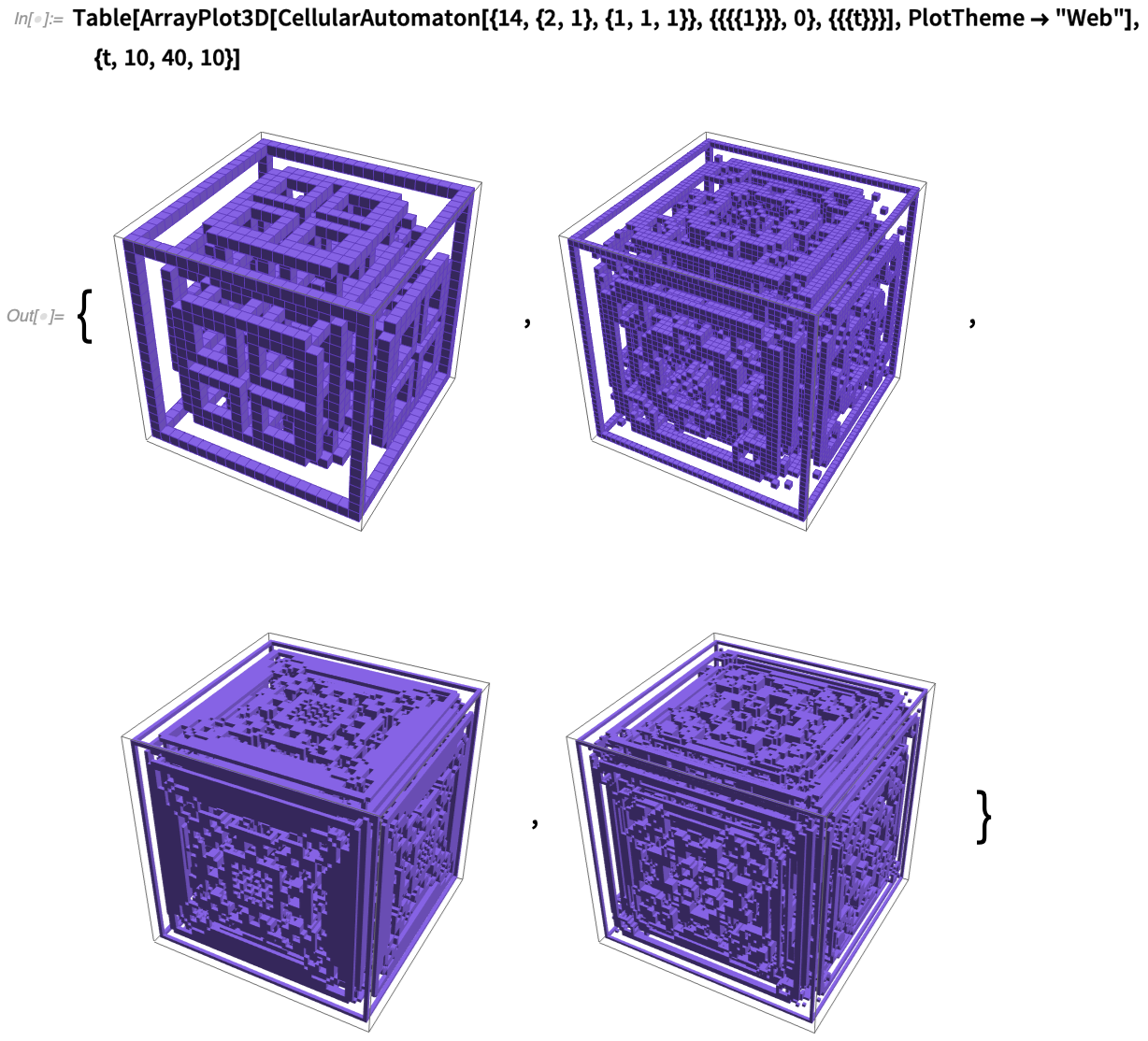
Már 36 éve várok arra, hogy egy igazán áramvonalas módon reprodukálhassam ezeket. És most végre a 12.2-es verzióban meg is van: ArrayPlot3D. Már 2012-ben bevezettük az Image3D-t a meghatározott színű és opacitású 3D voxelekből álló 3D képek ábrázolására és megjelenítésére. De a hangsúly a „radiológiai stílusú” munkán van, ahol a voxelek között bizonyos folytonosságot feltételezünk. És ha valóban diszkrét adatok diszkrét tömbjéről van szó (mint a celluláris automaták esetében), akkor ez nem vezet éles eredményekhez.
És itt van egy 3D-s cellás automata kissé bonyolultabb esete:
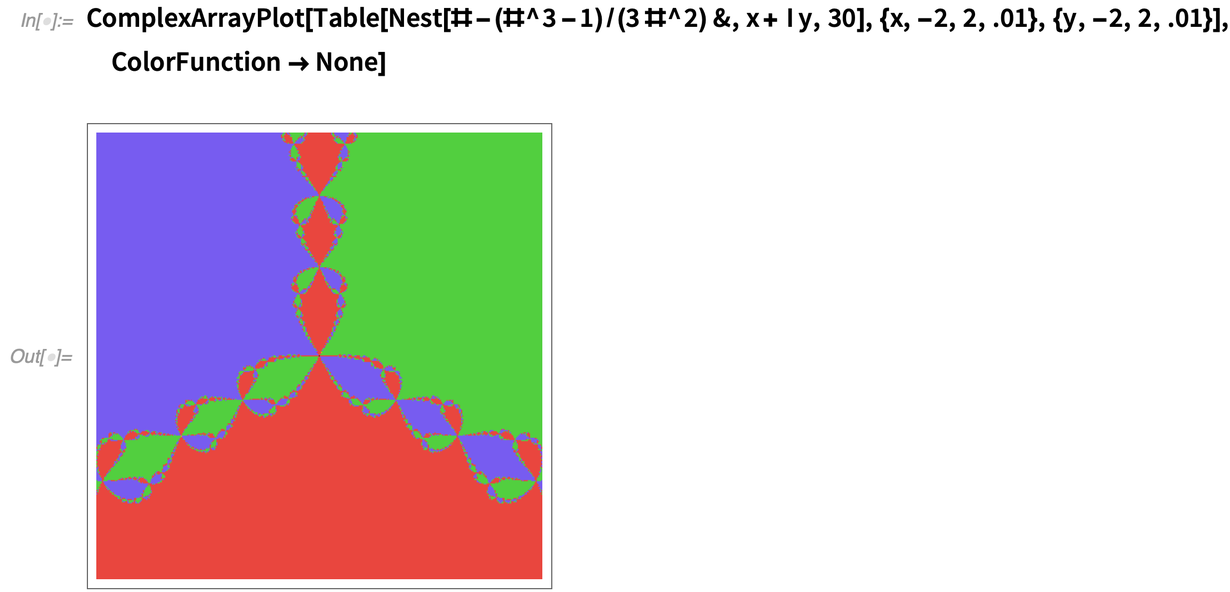
A 12.2 másik új ArrayPlot-családbeli függvénye a ComplexArrayPlot, amelyet itt a Newton-módszerből származó értékek tömbjére alkalmazunk:
A vizualizáció számítógépes esztétikájának fejlesztése
A Wolfram Language egyik célja, hogy olyan vizualizációkat készítsünk, amelyek egyszerűen „automatikusan jól néznek ki” – mert olyan algoritmusokkal és heurisztikákkal rendelkeznek, amelyek hatékonyan megvalósítják a jó számítási esztétikát. A 12.2-es verzióban a számítási esztétikát különböző vizualizációs típusokhoz hangoltuk. A 12.1-ben például alapértelmezés szerint így nézett ki egy SliceVectorPlot3D:
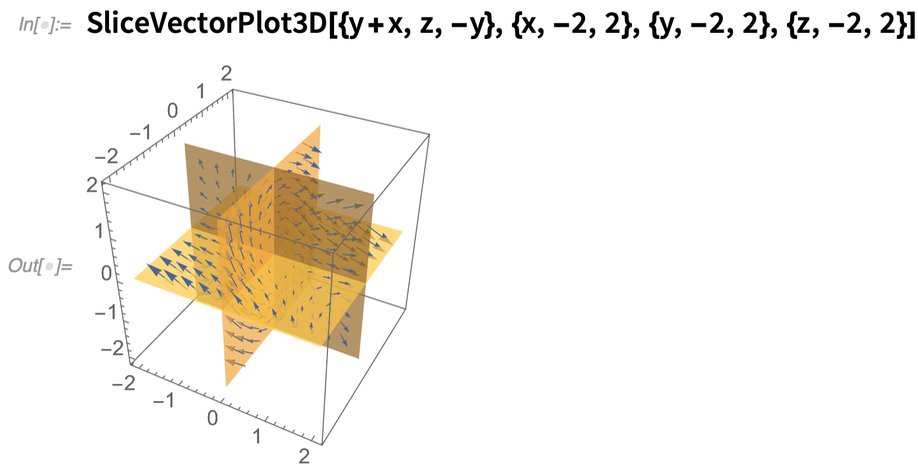
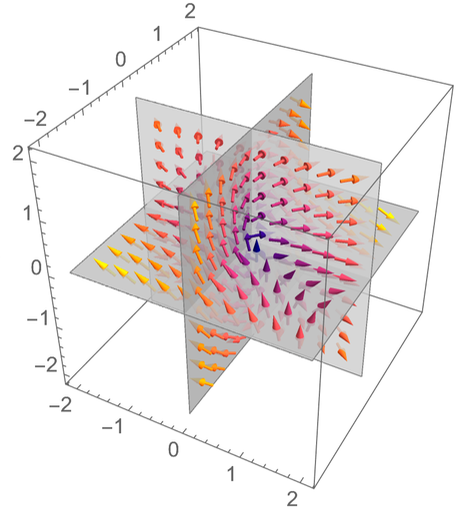
Most így néz ki:
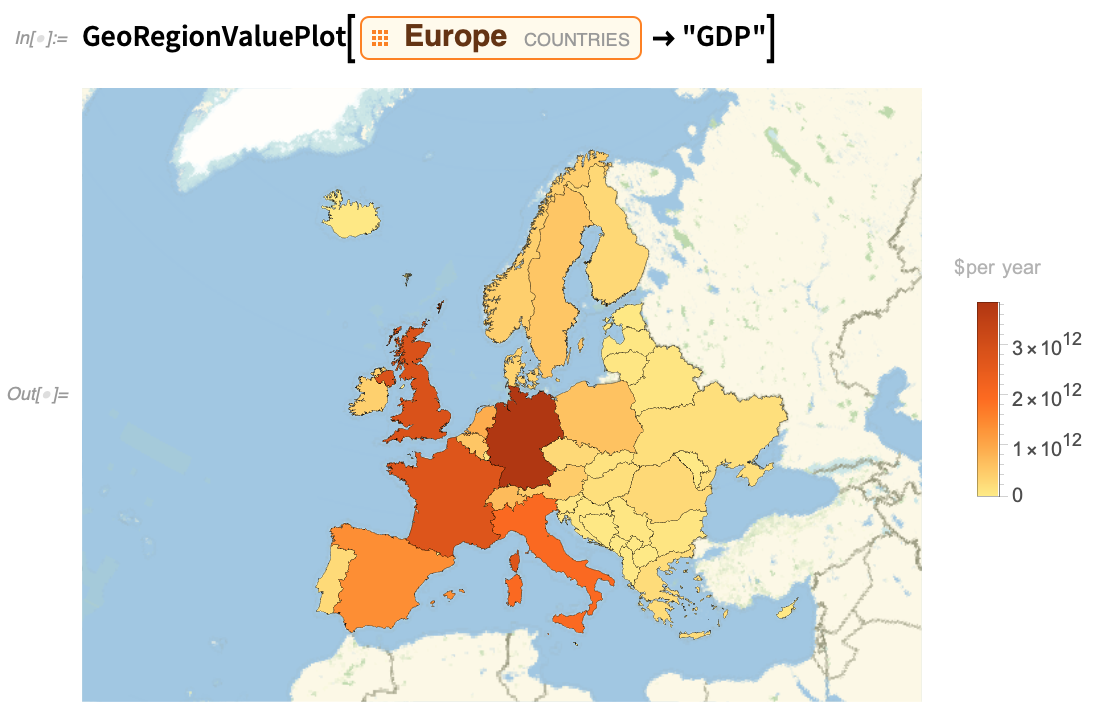
A 10-es verzió óta egyre gyakrabban használjuk a PlotTheme opciót is, hogy „bankváltással” részletes beállításokat készítsünk különböző célokra alkalmas, különböző esztétikai céloknak megfelelő megjelenítéseket. Így például a 12.2-es verzióban a GeoRegionValuePlothoz plot-témákat adtunk hozzá. Itt egy példa az alapértelmezettre (amelyet egyébként frissítettünk):
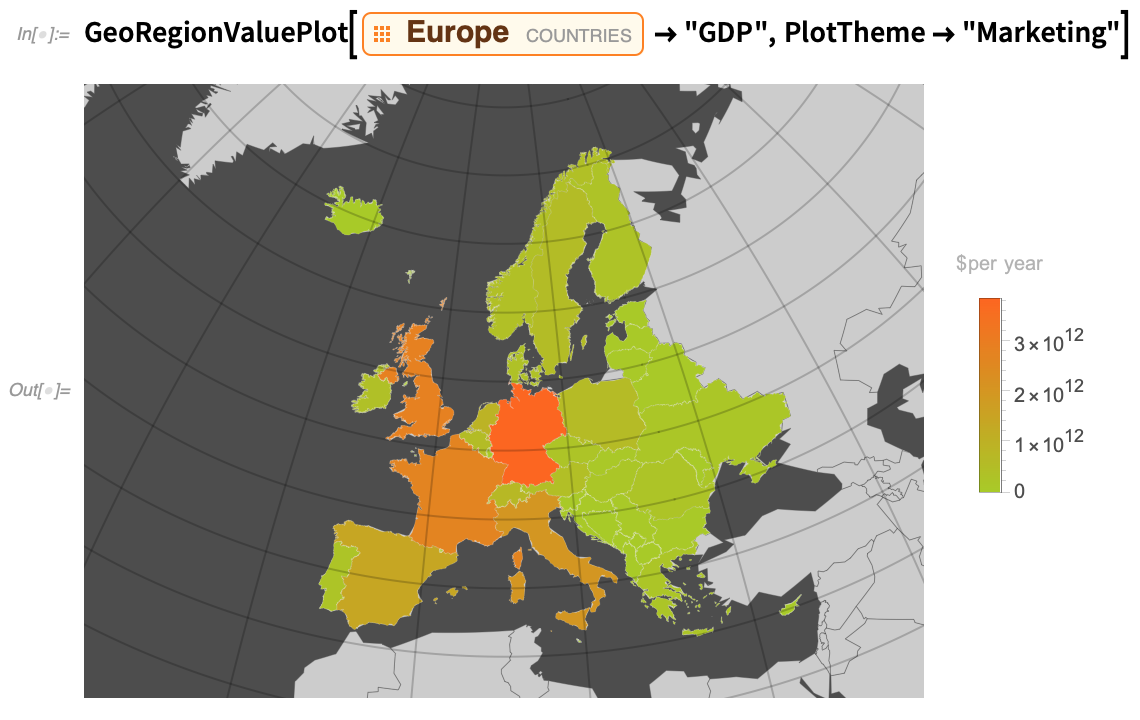
És itt van a „Marketing” cselekménytéma:
A 12.2-es verzióban egy másik dolog az új primitívek és új „nyersanyagok” hozzáadása az esztétikus vizuális hatások létrehozásához. A 12.1-es verzióban olyan dolgokat vezettünk be, mint a HatchFilling a kereszt-satírozáshoz. A 12.2-es verzióban már a LinearGradientFilling is rendelkezésünkre áll:

És most már hozzáadhatjuk ezt a fajta hatást a plot kitöltéséhez:

Hogy még stílusosabbak legyünk, az új ConicGradientFilling segítségével véletlenszerű pontokat is ábrázolhatunk:

A kód egy kicsit szebbé tétele
A Wolfram Nyelv alapvető célja egy olyan koherens számítási nyelv meghatározása, amelyet a számítógépek és az emberek egyaránt könnyen megérthetnek. Mi (és különösen én!) sok energiát fektettünk a nyelv megtervezésébe, és olyan dolgokba, mint például a függvények megfelelő nevének kiválasztása. De a nyelv minél könnyebben olvashatóvá tétele során fontos a nyelv „nem verbális” vagy szintaktikai aspektusainak egyszerűsítése is. A függvénynevek esetében alapvetően az emberek természetes nyelvi szavakkal kapcsolatos ismereteit használjuk ki. A szintaktikai struktúra esetében az emberek „környezeti megértését” szeretnénk kihasználni, például a matematikához hasonló területekről.
Több mint egy évtizeddel ezelőtt bevezettük az -t, mint a Function függvények megadásának módját, így ahelyett, hogy a
![]()
(vagy #2&) írhatnád:
![]()
De a bevitelhez -t be kellett írni \[Function] vagy legalábbis fn , ami általában „kicsit nehézkesnek” tűnt.
Nos, a 12.2-es verzióban „általánossá tesszük”, hogy lehetővé tesszük a |-> beírását.
![]()
valamint olyan dolgok, mint:
![]()
A 12.2-es verzióban van egy másik új „rövid szintaxis” is: //=Képzeljük el, hogy van egy eredmény, mondjuk a neve res. Most egy függvényt akarsz alkalmazni az res-re, majd „frissíteni a res-t”. Az új ApplyTo függvény (írva //=) megkönnyíti ezt:
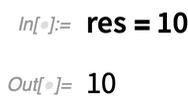
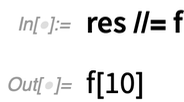

Mindig olyan ismétlődő „számítási csomók” után kutatunk, amelyeket „könnyen érthető nevű” függvényekbe „csomagolhatunk”. A 12.2-es verzióban van néhány új ilyen függvényünk: FoldWhile és FoldWhileList. A FoldList általában csak egy listát vesz, és minden egyes egymást követő elemet „belehajtogat” a felépített eredménybe – egészen addig, amíg a lista végére nem ér:
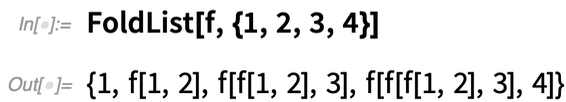
De mi van akkor, ha „korán le akarsz állni”? A FoldWhileList lehetővé teszi ezt. Itt tehát egymás után osztunk 1-gyel, 2-vel, 3-mal, …, és akkor állunk meg, amikor az eredmény már nem egész szám:
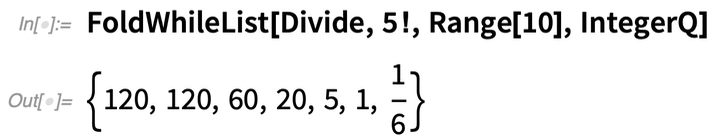
Bővebben Array Gymnastics: Oszlopműveletek és általánosításaik
Tegyük fel, hogy van egy tömböd, például:
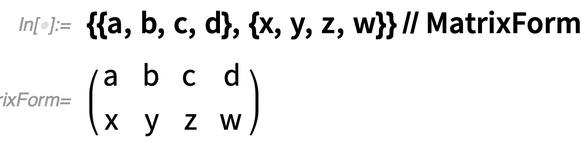
A Map lehetővé teszi egy függvény leképezését a tömb „soraira”:
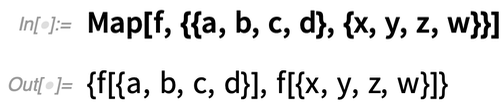
De mi van akkor, ha a tömb „oszlopain” akarunk operálni, gyakorlatilag „lecsökkentve” a tömb első dimenzióját? A 12.2-es verzióban az ArrayReduce függvény lehetővé teszi ezt:
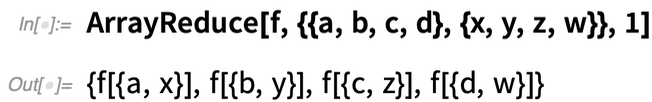
A következő történik, ha ehelyett azt mondjuk az ArrayReduce-nak, hogy „csökkentse ki” a tömb második dimenzióját:
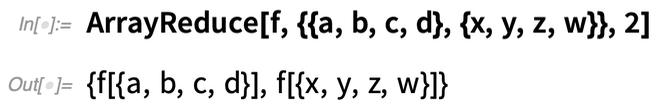
Mi folyik itt valójában? A tömb mérete 2×4:
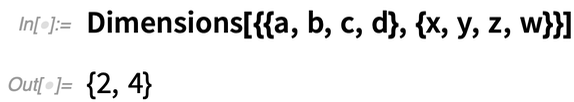
Az ArrayReduce[f, ..., 1] „csökkenti” az első dimenziót, így egy {4} dimenziójú tömb marad. Az
ArrayReduce[f, ..., 2] csökkenti a második dimenziót, így egy {2} dimenziójú tömb marad.
Nézzünk egy kicsit nagyobb esetet – egy 2×3×4-es tömböt:

Ez most megszünteti az „első dimenziót”, így egy 3×4-es tömb marad:


Ez viszont megszünteti a „második dimenziót”, így marad egy 2×4-es tömb:


Miért hasznos ez? Az egyik példa erre az, amikor olyan adattömbökkel rendelkezünk, amelyek különböző dimenziói különböző attribútumoknak felelnek meg, majd egy adott attribútumot „figyelmen kívül akarunk hagyni”, és az adatokat annak tekintetében szeretnénk aggregálni. Tegyük fel, hogy a figyelmen kívül hagyni kívánt attribútum a tömb n. szintjén található. Ekkor csak annyit kell tennie, hogy „figyelmen kívül hagyja”, hogy az ArrayReduce[f, ..., n] függvényt használja, ahol f az értékeket összesítő függvény (gyakran valami olyasmi, mint Total vagy Mean).
A Transpose, Apply stb. megfelelő sorozataival ugyanazokat az eredményeket érheti el, mint az ArrayReduce. De ez elég rendetlen, és az ArrayReduce elegáns „csomagolást” biztosít az ilyen típusú tömbműveleteknek.
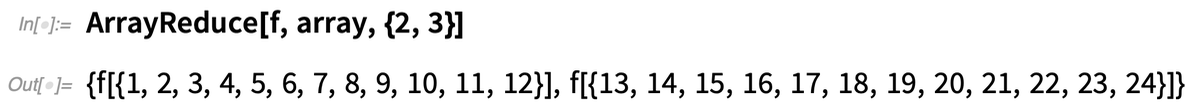
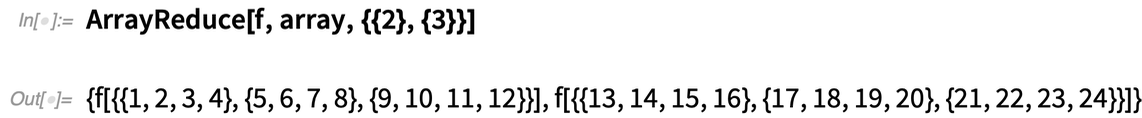
A legegyszerűbb szinten az ArrayReduce egy kényelmes módja annak, hogy a függvényeket „oszloponként” alkalmazzuk a tömbökre. De teljes általánosságban ez egy módja annak, hogy függvényeket alkalmazzunk tetszőleges indexű altáblákra. Ha pedig tenzorokban gondolkodunk, az ArrayReduce a kontrakció általánosítása, amelyben kettőnél több index is szerepelhet, és az elemek „ellapíthatók”, mielőtt a műveletet (amelynek nem feltétlenül összegzésnek kell lennie) alkalmaznánk.
Nézd a kódodat: Az Echo családban
Ez egy régi mondás a kód hibakeresésénél: „tegyél be egy nyomtatási utasítást”. De a Wolfram Nyelvben ez sokkal elegánsabb, különösen az Echonak köszönhetően. Ez egy egyszerű ötlet: Echo[expr] „visszhangozza” (azaz kiírja) azexpr értékét, de aztán visszaadja ezt az értéket. Az eredmény tehát az, hogy az Echot bárhová beillesztheted a kódodba (gyakran Echo@… néven) anélkül, hogy befolyásolná a kódod működését.
A 12.2-es verzióban van néhány új funkció, amelyek az „Echo” mintát követik. Az első példa az EchoLabel, amely egyszerűen hozzáad egy címkét a visszhangzott tartalomhoz:

A rajongók talán elgondolkodnak azon, hogy miért van szükség az EchoLabelre. Hiszen az Echo maga is megenged egy második argumentumot, amely megadhatja a címkét. A válasz – és igen, ez a nyelvtervezés egy kissé finom darabja – az, hogy ha az Echot csak egy függvényként akarjuk beilleszteni (mondjuk az @ segítségével), akkor csak egy argumentuma lehet, tehát nincs címke. Az EchoLabel úgy van beállítva, hogy az EchoLabel[label] operátor formájú legyen, így az EchoLabel[label][expr] egyenértékű az Echo[expr,label]-lel.
A 12.2 másik új „echo funkciója” az EchoTiming, amely megjeleníti az általa kiértékelt értékek időzítését (másodpercben):

Gyakran hasznos mind az Echo, mind az EchoTiming használata:

És egyébként, ha mindig ki akarod nyomtatni a kiértékelési időt (ahogy a Mathematica 1.0 alapértelmezésben tette 32 évvel ezelőtt), akkor mindig globálisan beállíthatod a $Pre=EchoTiming értéket.
Egy másik új „echo funkció” a 12.2-ben az EchoEvaluation, amely visszhangozza az „előtte” és „utána” értékelést:

Kíváncsi lehetsz, mi történik az egymásba ágyazott EchoEvaluation-ökkel. Íme egy példa:

Egyébként elég gyakori, hogy mind az EchoTimingot, mind az EchoEvaluationt használni akarjuk:

Végül, ha meg akarod hagyni az echo függvényeket a kódodban, de azt akarod, hogy a kódod „csendben” fusson, akkor használhatod az új QuietEcho-t az összes echo „elcsendesítésére” (ahogy a Quiet „elcsendesíti” az üzeneteket):

A kód egy kicsit szebbé tétele
Valami elromlott a programodban? És ha igen, mit kellene tennie a programnak? Nagyon elegáns kódot lehet írni, ha az ember figyelmen kívül hagyja az ilyen dolgokat. Amint azonban elkezdünk ellenőrzéseket beépíteni, és logikát alkalmazunk a dolgok feloldására, ha valami rosszul sül el, a kód általában sokkal bonyolultabbá válik, és sokkal kevésbé olvashatóvá.
Mit lehet ez ellen tenni? Nos, a 12.2-es verzióban kifejlesztettünk egy magas szintű szimbolikus mechanizmust a kódban elromló dolgok kezelésére. Az alapötlet az, hogy a Confirm (vagy a kapcsolódó függvények) beillesztésével – kicsit úgy, mintha az Echo-t illesztenénk be – „megerősítjük”, hogy valami a programunkban azt csinálja, amit kell. Ha a megerősítés működik, akkor a programod egyszerűen csak megy tovább. De ha nem sikerül, akkor a program megáll – és kilép a legközelebbi Enclose-ba. Bizonyos értelemben az Enclose „körülzárja” a programod területeit, nem engedi, hogy bármi, ami belül elromlik, azonnal kifelé terjedjen.
Lássuk, hogyan működik ez egy egyszerű esetben. Itt a Confirm sikeresen „megerősíti” y-t, csak visszaadja, és az Enclose nem csinál semmit:
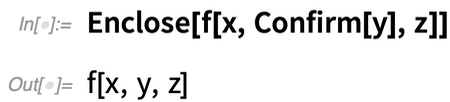
But now let’s put $Failed in place of y-et. A $Failed olyasvalami, amit a Confirm alapértelmezés szerint problémának tekint. Tehát amikor $Failed-et lát, megáll, és kilép az Enclose-ba, ami viszont egy Failure objektumot ad ki:
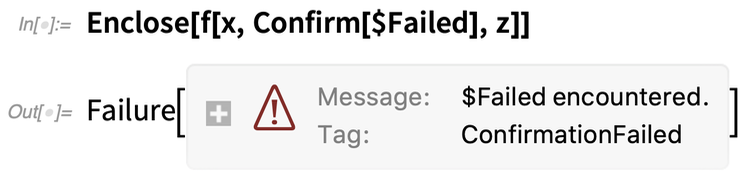
Ha beírunk néhány visszhangot, látni fogjuk, hogy x-et sikeresen elérjük, de z-t nem; amint a Confirm sikertelen, mindent leállít:
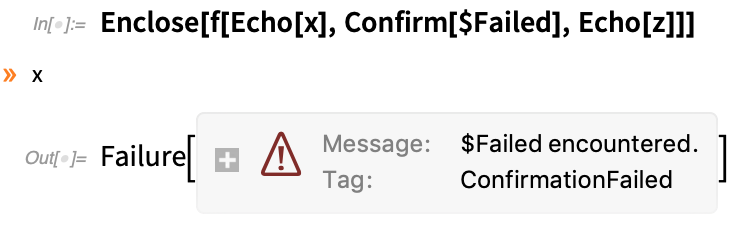
Nagyon gyakori, hogy egy függvény definiálásakor a Confirm/Enclose funkciót szeretnénk használni:
![]()
Használja az 5. érvet, és minden működik:
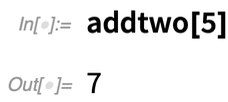
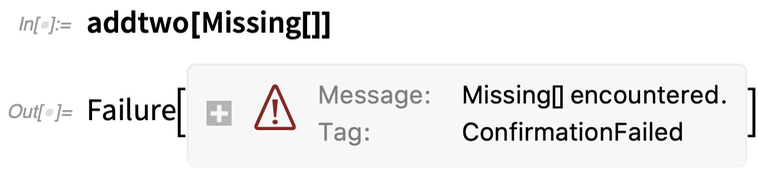
De ha ehelyett a Missing[]-t használjuk – amit a Confirm alapértelmezés szerint problémának tekint -, akkor egy Failure objektumot kapunk vissza:
Ugyanezt elérhetnénk az If, Return stb. használatával. De még ebben a nagyon egyszerű esetben sem nézne ki olyan szépen.
A Confirmnak van egy bizonyos alapértelmezett készlete a dolgoknak, amelyeket „rossznak” tekint ($Failed, Failure[...], Missing[...]] a példák). De vannak kapcsolódó függvények, amelyek lehetővé teszik, hogy konkrét teszteket adjunk meg. Például a ConfirmBy egy olyan függvényt alkalmaz, amely teszteli, hogy egy kifejezést meg kell-e erősíteni.
Itt a ConfirmBy megerősíti, hogy a 2 egy szám:

De az x-et a NumberQ nem tekinti annak:

Oké, rakjuk össze ezeket a darabokat. Definiáljunk egy függvényt, amelynek stringekkel kell operálnia:
![]()
Ha adunk neki egy stringet, minden rendben van:

De ha helyette egy számot adunk meg, a ConfirmBy nem sikerül:
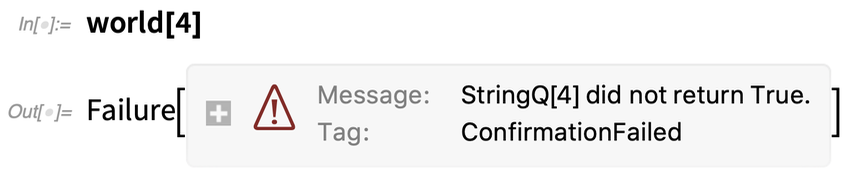
De itt kezdődnek az igazán szép dolgok. Tegyük fel, hogy le akarjuk térképezni a világot egy lista fölé, mindig megerősítve, hogy jó eredményt kapjunk. Itt minden rendben van:

De most valami rosszul sült el:
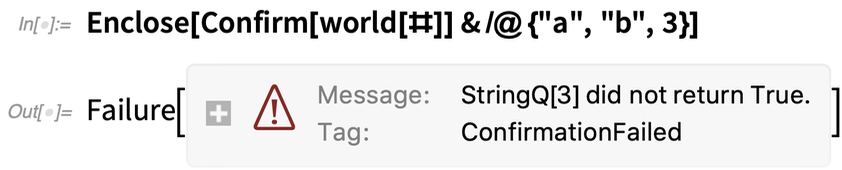
A world definíciójában lévő ConfirmBy sikertelen volt, ami miatt a körülvevő Enclose egy Failure objektumot eredményezett. Ezután ez a Failure objektum okozta a Map-en belüli Confirm hibáját, és az azt körülvevő Enclose egy Failure objektumot adott az egészhez. Ismétlem, ugyanezt elérhettük volna If, Throw, Catch stb. segítségével is. De a Confirm/Enclose sokkal robusztusabban és elegánsabban csinálja.
Ezek mind nagyon apró példák. De ahol a Confirm/Enclose igazán megmutatja az értékét, az a nagy programoknál van, és a hibák és kivételek kezelésének világos, magas szintű keretrendszerének biztosításában, valamint azok hatókörének meghatározásában.
A Confirm és ConfirmBy mellett létezik a ConfirmMatch is, amely megerősíti, hogy egy kifejezés megfelel egy megadott mintának. Aztán ott van a ConfirmQuiet, amely megerősíti, hogy egy kifejezés kiértékelése nem generál semmilyen üzenetet (vagy legalábbis nem olyan üzenetet, amelyre a programnak azt mondtad, hogy tesztelje). Van még a ConfirmAssert is, amely egyszerűen egy „állítást” (például p>0) vesz, és megerősíti, hogy az igaz.
Ha egy visszaigazolás sikertelen, a program mindig kilép a legközelebbi bezáró Enclose-hoz, és az Enclose-nak átad egy Failure objektumot a bekövetkezett sikertelenségről szóló információval. Amikor beállítjuk az Enclose-t, megmondhatjuk neki, hogyan kezelje a kapott hibaobjektumokat – vagy csak visszaadja őket (esetleg a körülzáró Confirm-oknak és Enclose-oknak), vagy függvényeket alkalmaz a tartalmukra.
A Confirm és az Enclose egy elegáns mechanizmus a hibák kezelésére, amelyet könnyen és tisztán be lehet illeszteni a programokba. De – mondanom sem kell – határozottan van néhány trükkös kérdés körülöttük. Hadd említsek csak egyet. A kérdés az, hogy egy adott Enclose valójában melyik Confirm-ot zárja be? Ha írtál már olyan kódot, amely kifejezetten Enclose-t és Confirm-ot tartalmaz, akkor ez elég nyilvánvaló. De mi van akkor, ha van egy Confirm, ami valahogyan generálódik – talán dinamikusan – mélyen a függvények halmazában? Ez hasonló a helyzet, mint a megnevezett változók esetében. A Module csak közvetlenül („lexikálisan”) keresi a változókat a testén belül. A Block a változókat („dinamikusan”) keresi, bárhol is forduljanak elő. Nos, az Enclose alapértelmezés szerint úgy működik, mint a Module, „lexikailag” keresi a Confirm-okat, amelyeket be kell zárni. De ha a Confirm és az Enclose címkéket tartalmazza, akkor beállíthatja őket úgy, hogy „megtalálják egymást”, még akkor is, ha nem kifejezetten „láthatóak” ugyanabban a kódrészletben.
Funkció robusztálás
A Confirm/Enclose egy jó magas szintű módot biztosít arra, hogy kezeljük a programban vagy függvényben rosszul működő dolgok „áramlását”. De mi van akkor, ha már az elején valami baj van? A beépített Wolfram Language függvényeinkben van egy szabványos ellenőrzéskészlet, amelyet alkalmazunk. Megfelelő az argumentumok száma? Ha vannak opciók, akkor azok engedélyezett opciók, és a megfelelő helyen vannak-e? A 12.2-es verzióban két olyan függvényt adtunk hozzá, amelyek elvégezhetik ezeket a szabványos ellenőrzéseket az Ön által írt függvényeknél.
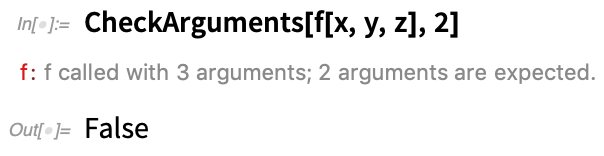
Ez azt mondja, hogy f-nek két argumentummal kell rendelkeznie, ami itt nincs:
Íme egy módja annak, hogy a CheckArguments a függvény alapvető definíciójának részévé váljon:
![]()
Ha rossz számú argumentumot adsz meg neki, akkor üzenetet generál, majd kiértékeletlenül tér vissza, ahogy sok beépített Wolfram Language függvény teszi:

Az ArgumentsOptions egy másik új függvény a 12.2-es verzióban, amely elválasztja a „pozicionális argumentumokat” a függvény opcióitól. Beállítja egy függvény opcióit:
![]()
Ez egy pozicionális érvet vár, amit meg is talál:

Ha nem talál pontosan egy pozicionális argumentumot, akkor üzenetet generál:

Tisztítás a kódod után
Lefuttatsz egy kódot, és az megteszi, amit kell – és általában nem akarod, hogy bármit is hátrahagyjon. Gyakran használhatsz olyan scoping konstrukciókat, mint a Module, Block, BlockRandom, stb. ennek eléréséhez. De néha lesz valami, amit beállítasz, amit kifejezetten „el kell takarítani”, amikor a kódod befejeződik.
Például létrehozhat egy fájlt a kódrészletben, és azt szeretné, ha a fájl eltávolításra kerülne, amikor az adott kódrészlet befejeződik. A 12.2-es verzióban van egy új, kényelmes funkció az ilyen dolgok kezelésére: WithCleanup.
A WithCleanup[expr, cleanup] kiértékeli az expr-t, majd a cleanup-ot, de visszaadja az expr eredményét. Íme egy triviális példa (amit valójában jobban el lehetne érni Block segítségével). Hozzárendelsz egy értéket x-hez, megkapod a négyzetét – majd törlöd x-et, mielőtt visszaadnád a négyzetet:
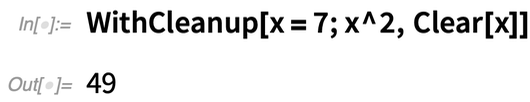
Már az is kényelmes, ha van egy olyan konstrukció, amely tisztítást végez, miközben visszaadja a fő kifejezést, amelyet kiértékeltél. De a WithCleanup fontos részlete, hogy azt a helyzetet is kezeli, amikor a fő kiértékelést megszakítjuk. Normális esetben a megszakítás kiadása azt eredményezné, hogy minden leáll. A WithCleanup azonban úgy van beállítva, hogy a tisztítás akkor is megtörténjen, ha megszakítás történik. Tehát ha a tisztítás például egy fájl törlésével jár, a fájl akkor is törlődik, ha a fő művelet megszakad.
A WithCleanup lehetővé teszi az inicializálás megadását is. Tehát itt az inicializálás megtörténik, ahogy a tisztítás is, de a fő kiértékelés megszakad:
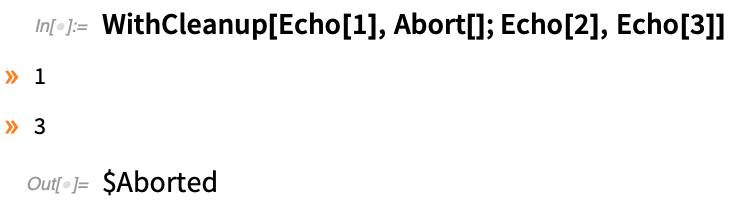
A WithCleanup egyébként a Confirm/Enclose funkcióval együtt is használható, hogy bizonyos takarítások akkor is megtörténjenek, ha a visszaigazolás sikertelen.
Dátumok – 37 új naptárral
Ma 2020. december 16-a van – legalábbis az Egyesült Államokban általában használt Gergely-naptár szerint. A világon azonban számos más naptárrendszert is használnak különböző célokra, és még több olyan is van, amelyet a történelem során valamikor használtak.
A Wolfram Language korábbi verzióiban néhány gyakori naptárrendszert támogattunk. A 12.2-es verzióban azonban nagyon széles körű támogatást adtunk a naptárrendszerekhez – összesen 41-et. A naptárrendszerekre úgy is gondolhatunk, mint a geodéziában a vetületekre vagy a geometriában a koordinátarendszerekre. Van egy bizonyos idő: most már tudnia kell, hogy ez hogyan jelenik meg az Ön által használt rendszerben. És a GeoProjectionData-hoz hasonlóan most már létezik a CalendarData is, amely megadja a rendelkezésre álló naptárrendszerek listáját:

Itt van tehát a „most” ábrázolása különböző naptárakra átszámítva:
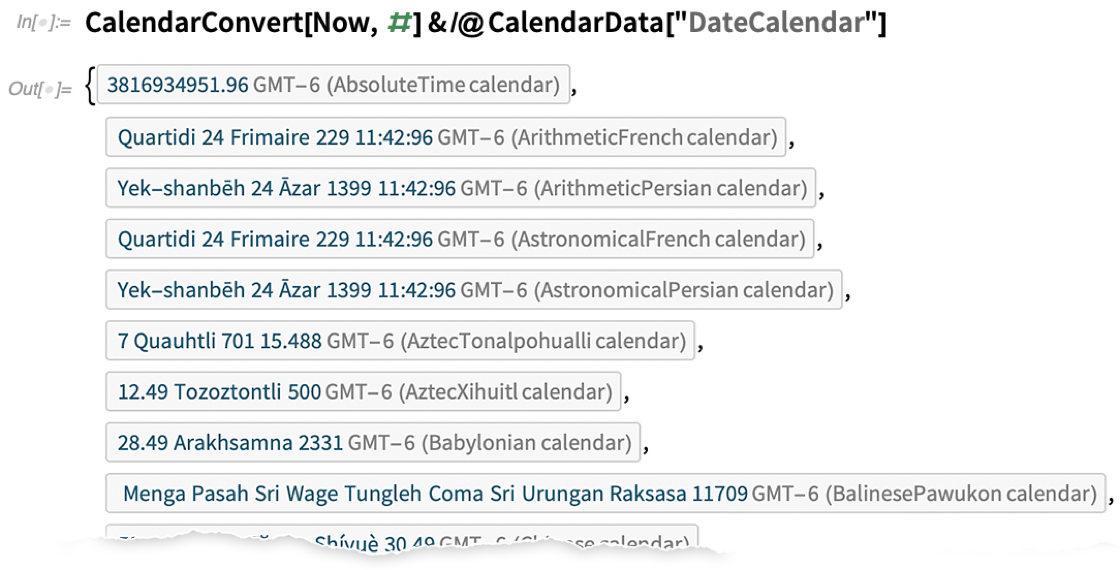
Itt sok finomság van. Egyes naptárak tisztán „számtani” jellegűek; mások csillagászati számításokra támaszkodnak. És ott van még a „szökőévváltozatok” kérdése. A Gergely-naptár esetében megszoktuk, hogy egyszerűen hozzáadunk egy február 29-ét. De a kínai naptár például egész „szökőhónapokat” is hozzáadhat egy éven belül (így például két „negyedik hónap” is lehet). A Wolfram Nyelvben most már van egy szimbolikus reprezentációnk az ilyen dolgokra, a LeapVariant segítségével:

A különböző naptárrendszerekkel való foglalkozás egyik oka, hogy a különböző kultúrákban az ünnepek és fesztiválok meghatározására használják őket. (Egy másik ok, amely különösen fontos a hozzám hasonló, történelmet sokat tanulmányozó ember számára, a történelmi dátumok átváltása: Newton születésnapját eredetileg 1642. december 25-én jegyezték fel, de ha átváltjuk gregorián dátumra, akkor 1643. január 4.).
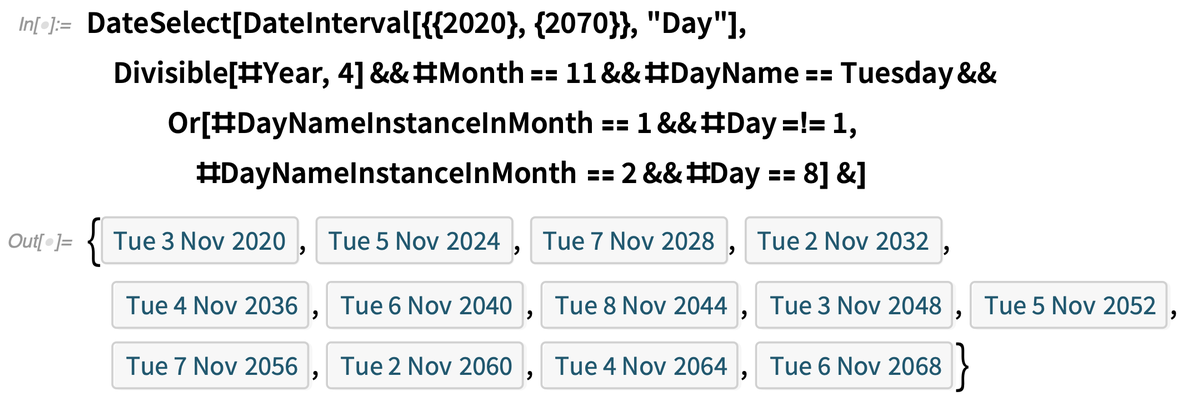
Egy naptár ismeretében gyakran szeretnénk kiválasztani olyan dátumokat, amelyek megfelelnek egy adott kritériumnak. A 12.2-es verzióban erre a célra bevezettük a DateSelect függvényt. Így például egy adott intervallumon belül kiválaszthatjuk azokat a dátumokat, amelyek megfelelnek annak a feltételnek, hogy szerdai napok legyenek:

Egy bonyolultabb példaként átalakíthatjuk az amerikai elnökválasztások időpontjának kiválasztására szolgáló jelenlegi algoritmust számítható formába, majd felhasználhatjuk azt a következő 50 év időpontjainak meghatározására:
Új a Geo területén
Mostanra a Wolfram Language erős képességekkel rendelkezik a térinformatikai számítások és a térinformatikai megjelenítés terén. De tovább bővítjük geofunkcióinkat. A 12.2-es verzióban fontos újdonság a térbeli statisztika (fentebb már említettük) – amely teljesen integrálva van a geo-val. De van néhány új geo primitív is. Az egyik a GeoBoundary, amely a dolgok határait számítja ki:
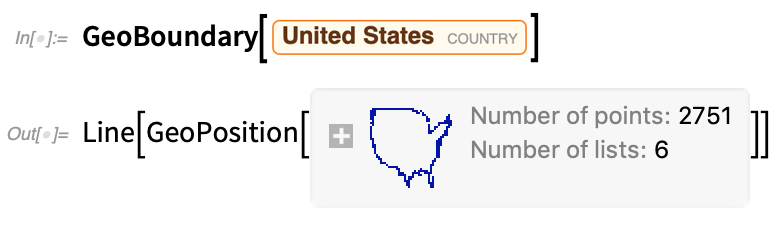

Ott van még a GeoPolygon, amely a közönséges poligonok teljes geo általánosítása. A GeoPolygon egyik kényes kérdése, hogy mi számít a poligon „belsejének” a Földön. Itt a nagyobb területet választja (azaz azt, amelyik körbeöleli a földgömböt):
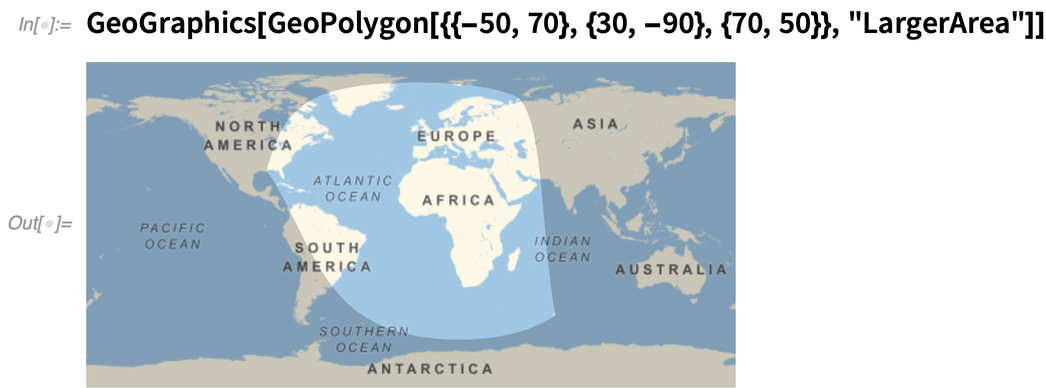
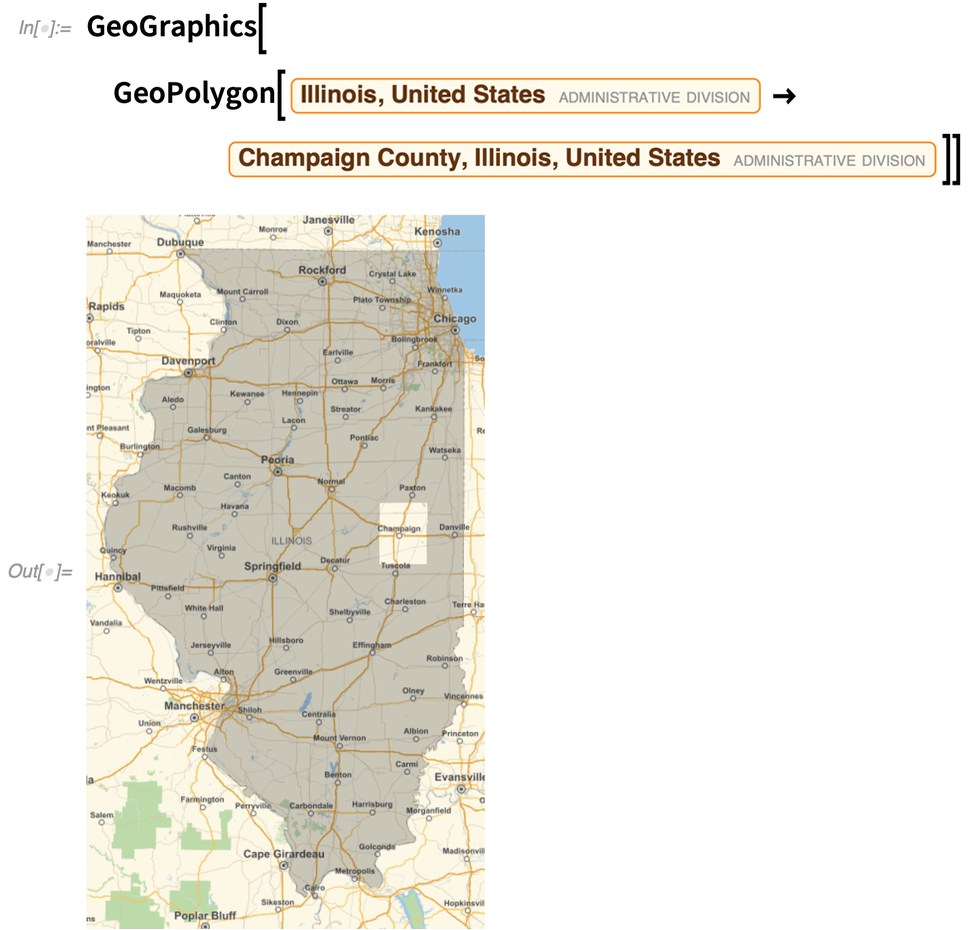
A GeoPolygon a Polygonhoz hasonlóan képes kezelni a lyukakat, illetve a tetszőleges szintű beágyazást is:
De a geo legnagyobb „vonzereje” a geográfiai grafikák és térképek teljesen új renderelése. A 12.2-es verzióban ez még csak előzetes (és befejezetlen), de legalább kísérleti támogatás van a vektoralapú térképek renderelésére. Ennek legnyilvánvalóbb hozadéka, hogy a térképek minden méretarányban sokkal élesebbnek és élesebbnek tűnnek. A másik előnye azonban az, hogy új stílusokat tudunk bevezetni a térképekhez, és a 12.2-es verzióban nyolc új térképstílus szerepel.
Itt a „régi stílusú” térképünk:
Itt van ennek a „klasszikus” stílusnak az új, vektoros változata:
Itt egy új (vektoros) stílus, amelyet a webre szánunk:

És itt van egy „sötét” stílus, amely alkalmas arra, hogy információkat helyezzenek rá:
PDF importálása
Szeretne elemezni egy PDF formátumú dokumentumot? Már jóval több mint egy évtizede képesek vagyunk alapvető tartalmakat kinyerni PDF-fájlokból. A PDF azonban rendkívül összetett (és fejlődő) formátum, és sok „vadon” lévő dokumentum szerkezete bonyolult. A 12.2-es verzióban azonban drámaian kibővítettük a PDF-importálási lehetőségeinket, így reálissá vált például egy véletlenszerűen kiválasztott dokumentum importálása az arXivról:

Alapértelmezés szerint minden oldalhoz (ebben az esetben mind a 100 oldalhoz) egy nagy felbontású képet kap.
Ha a szövegre van szüksége, azt a „Plaintext” opcióval importálhatja:

Most már azonnal készíthetsz egy szófelhőt az újságban szereplő szavakból:

Ez kiemeli az összes képet a papírból, és kollázst készít belőlük:

Az URL-címeket minden oldalról lekérheti:
Most vegye ki az utolsó kettőt, és szerezzen képeket ezekről a weboldalakról:

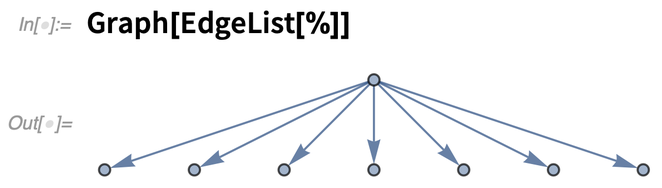
Attól függően, hogy hogyan készültek, a PDF-ek mindenféle szerkezetűek lehetnek. A „ContentsGraph” egy grafikon, amely a dokumentum észlelt általános szerkezetét ábrázolja:

És igen, ez tényleg egy grafikon:
A kitölthető űrlapokból álló PDF-ek esetében több struktúrát kell importálni. Itt egy véletlenszerű, kitöltetlen kormányzati űrlapot kaptam le a netről. Az Import egy asszociációt ad, amelynek kulcsai a mezők nevei – és ha az űrlap ki lett volna töltve, akkor az értékeiket is megadta volna, így azonnal elemzést végezhetünk rajtuk:

A legújabb ipari szintű konvex optimalizálás
A 12.0-s verziótól kezdve a legmodernebb képességekkel bővítettük a nagyméretű optimalizálási problémák megoldását. A 12.2-es verzióban tovább kerekítettük ezeket a képességeket. Az egyik újdonság a ConvexOptimization szuperfunkció, amely automatikusan kezeli a lineáris, lineáris-frakcionális, kvadratikus, féldefinit és kúpos optimalizálás teljes spektrumát – optimális megoldásokat és azok duális tulajdonságait is megadva. A 12.1-ben hozzáadtuk az egész számú változók támogatását (azaz a kombinatorikus optimalizálást); a 12.2-ben hozzáadjuk a komplex változók támogatását is.
A 12.2 legnagyobb újdonsága azonban a robusztus optimalizálás és a parametrikus optimalizálás bevezetése. A robusztus optimalizálással olyan optimumot találhat, amely néhány változó értékének teljes értéktartományában érvényes. A parametrikus optimalizálással olyan parametrikus függvényt kaphat, amely az egyes paraméterek bármely lehetséges értékére megadja az optimumot. Így például ez megtalálja az optimumot x, y-ra az α bármely (pozitív) értékére:

Most értékeljük ki a parametrikus függvényt egy adott α-ra:

Mint a Wolfram Nyelvben minden, nagy erőfeszítéseket tettünk annak érdekében, hogy a konvex optimalizálás zökkenőmentesen integrálódjon a rendszer többi részébe – így a modelleket szimbolikusan állíthatod fel, és eredményeiket más függvényekbe áramoltathatod. Néhány nagyon hatékony konvex optimalizációs megoldót is beépítettünk. De különösen akkor, ha vegyes (azaz valós+számjegyű) optimalizálást végez, vagy ha igazán hatalmas (pl. 10 millió változós) problémákkal foglalkozik, hozzáférést biztosítunk más, külső megoldókhoz is. Így például beállíthatod a problémádat a Wolfram Language használatával, mint „algebrai modellező nyelv”, majd (feltéve, hogy rendelkezel a megfelelő külső licencekkel) csak a Method beállításával mondjuk a „Gurobi” vagy a „Mosek” segítségével azonnal lefuttathatod a problémádat egy külső megoldóval. (És mellesleg most már van egy nyitott keretrendszerünk további megoldók hozzáadására.)
Kombinátorok és egyéb formális építőelemek támogatása
Azt mondhatjuk, hogy a szimbolikus kifejezések (és transzformációik) egész ötlete, amelyre a Wolfram Nyelvben oly sokat támaszkodunk, a kombinátorokból származik – amelyek 2020. december 7-én ünnepelték századik születésnapjukat. A szimbolikus kifejezéseknek a Wolfram Language-ben található változata sok szempontból sokkal fejlettebb és használhatóbb, mint a nyers kombinátorok. De a 12.2-es verzióban – részben a kombinátorok ünneplése jegyében – a nyers kombinátorok keretrendszerét is hozzá akartuk adni.
Így most például a CombinatorS, CombinatorK, stb. megfelelően renderelve van:

De hogyan ábrázoljuk az egyik kombinátor alkalmazását a másikra? Ma valami ilyesmit írunk:

De a matematikai logika kezdeti időszakában egy másik konvenció volt – ez a bal-asszociatív alkalmazást jelentette, amelyben „kombinátor stílusban” azt vártuk, hogy a függvények dolgokra való alkalmazásából „függvényeket” és nem „értékeket” generáljunk. Ezért a 12.2-es verzióban bevezetünk egy új „alkalmazási operátort”, az Applicationt, amely -ként jelenik meg (és \[Application] vagy ap -ként írható be):


Egyébként pedig teljes mértékben számítok arra, hogy az Application – mint egy új, alapvető „konstruktor” – sokféleképpen használható lesz (az „alkalmazásokról” nem is beszélve) a Wolfram Language általános struktúráinak létrehozásában.
A kombinátorok szabályai triviálisan megadhatók a Wolfram Nyelv mintatranszformációinak segítségével:
![]()
De gondolhatunk a kombinátorokra „algebraibb” módon is, mint a kifejezések közötti kapcsolatok meghatározására – és erre most már van egy elmélet az AxiomaticTheoryban.
A 12.2-ben pedig néhány további elmélettel bővült az AxiomaticTheory, valamint számos új tulajdonsággal.
Az euklideszi geometria interaktívvá válik
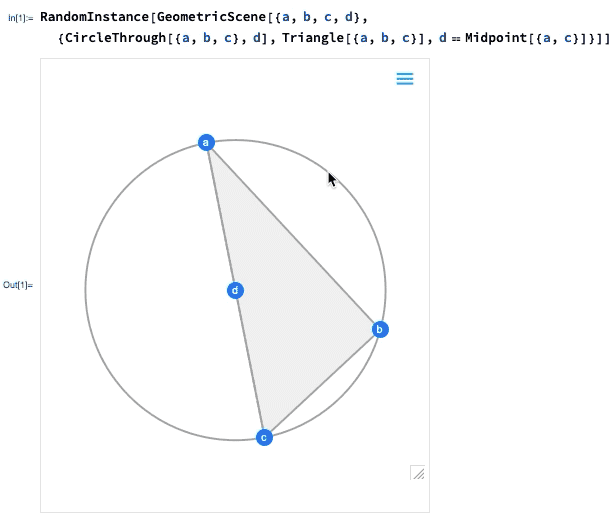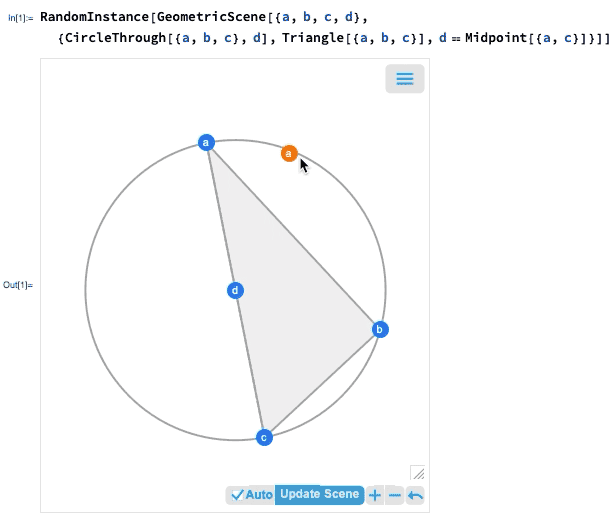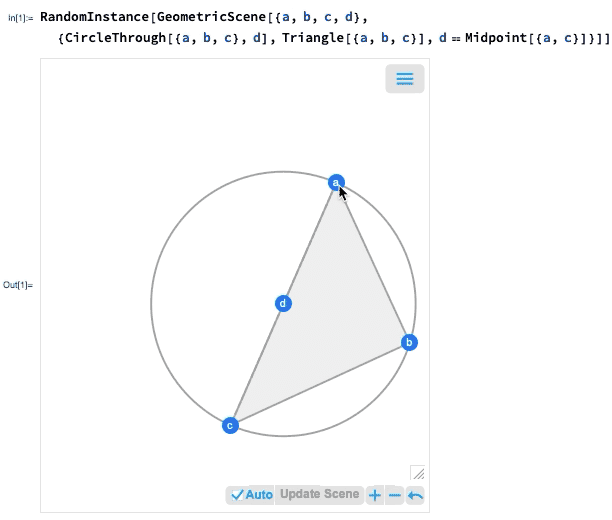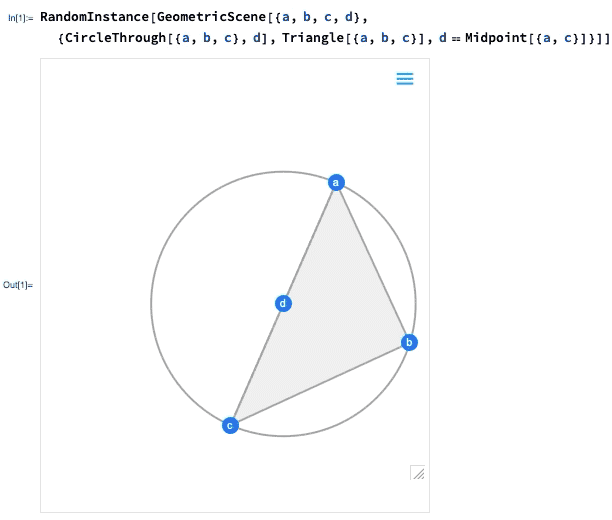
A 12.0 verzió egyik legnagyobb előrelépése az euklideszi geometria szimbolikus reprezentációjának bevezetése volt: megadunk egy szimbolikus GeometricScene-t, megadva különböző objektumokat és kényszereket, és a Wolfram Language képes „megoldani” azt, és megrajzolni egy véletlenszerű, a kényszereket kielégítő példány diagramját. A 12.2-es verzióban ezt interaktívvá tettük, így a diagram pontjait mozgathatjuk, és minden (ha lehetséges) interaktívan átrendeződik úgy, hogy a kényszerek fennmaradjanak.
Íme egy egyszerű geometriai jelenet véletlenszerű példája:
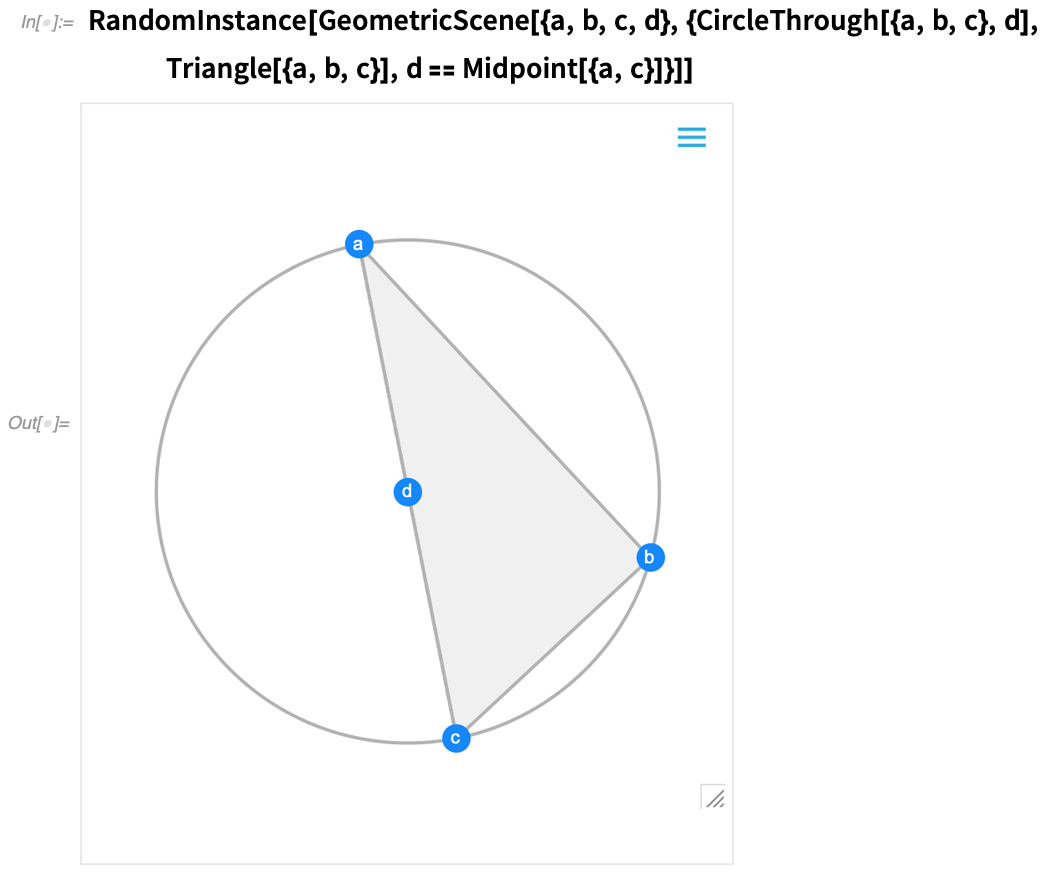
Ha az egyik pontot elmozdítja, a többi pont interaktív módon átrendeződik úgy, hogy a geometriai jelenet szimbolikus reprezentációjában meghatározott kényszereket fenntartsa:
Mi folyik itt valójában? Alapvetően a geometria algebrává alakul át. És ha akarod, megkaphatod az algebrai megfogalmazást:
És mondanom sem kell, hogy ezt a Wolfram Language számos erőteljes algebrai számítási lehetőségével manipulálhatod. Az interaktivitás mellett a 12.2 másik fontos újdonsága, hogy nem csak teljes geometriai jeleneteket, hanem olyan geometriai konstrukciókat is képes kezelni, amelyek több lépésben építik fel a jelenetet. Íme egy példa, amely történetesen közvetlenül Euklidészből származik:

Az első kép, amit kap, alapvetően a konstrukció eredménye. És – mint minden más geometriai jelenet – most már interaktív. De ha az egérrel fölé mész, olyan vezérlőket kapsz, amelyekkel korábbi lépésekre léphetsz:
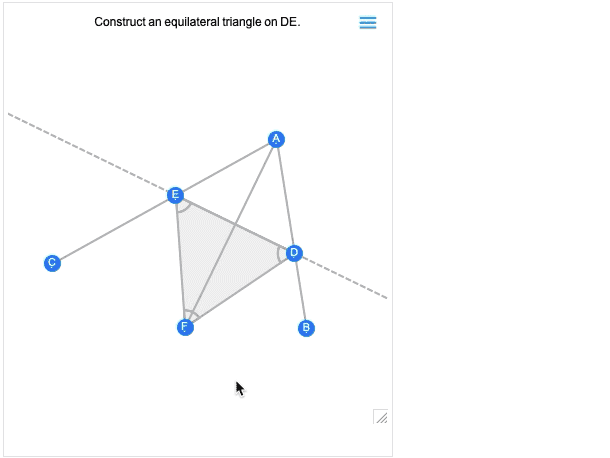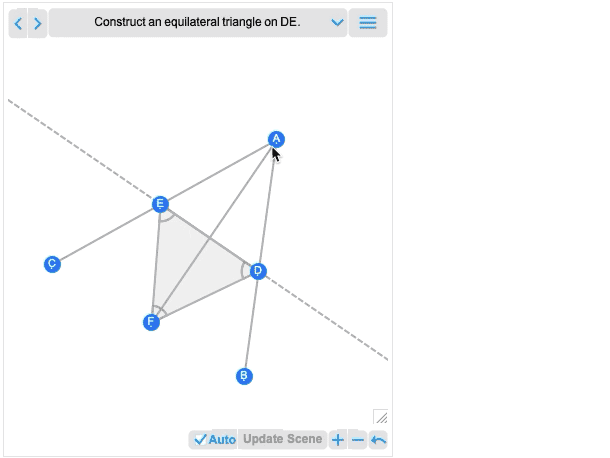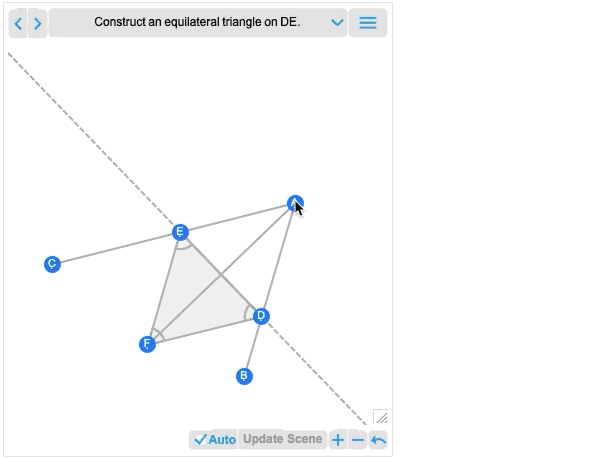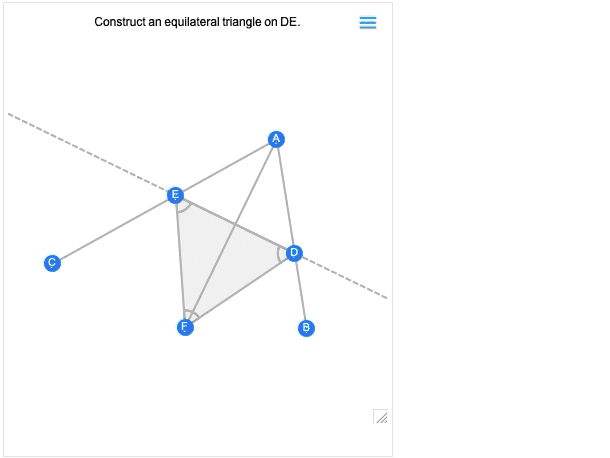
Mozgass el egy pontot egy korábbi lépésben, és látni fogod, hogy ez milyen következményekkel jár a konstrukció későbbi lépéseire nézve. Euklidész geometriája a matematika legelső axiomatikus rendszere, amelyről tudunk. Így több mint 2000 évvel később izgalmas, hogy végre kiszámíthatóvá tehetjük. (És igen, ez végül össze fog kapcsolódni az AxiomaticTheory, FindEquationalProof, stb. programokkal.)
De Euklidész eredeti geometriai megfogalmazásának jelentőségét elismerve, a tételek számítható változatait (valamint egy csomó más „híres geometriai tételt”) is hozzáadtuk. A fenti példáról kiderül, hogy Euklidész 1. könyvének 9. tétele. És most például megkaphatjuk az eredeti tételét görögül:

És itt van ez a modern Wolfram Language nyelven – olyan formában, amelyet a számítógépek és az emberek egyaránt megérthetnek:

Még többféle tudás a Tudásbázis számára
A Wolfram Language mint teljes körű számítási nyelv történetének fontos része, hogy hozzáfér a világról szóló hatalmas tudásbázisunkhoz. A tudásbázis folyamatosan frissül és bővül, és valóban, a 12.1-es verzió óta eltelt időben lényegében minden tartományban frissültek (és gyakran jelentős mennyiségű) adatok, vagy entitások kerültek hozzá vagy módosultak.
De példaként hadd említsek néhány kiegészítést. Az egyik terület, amely nagy figyelmet kapott, az élelmiszer. Mostanra már több mint félmillió élelmiszerről rendelkezünk adatokkal (összehasonlításképpen: egy tipikus nagy élelmiszerboltban talán 30 000 féle terméket tartunk). Válasszon ki egy tetszőleges élelmiszert:

Most generáljon egy tápértékjelölést:
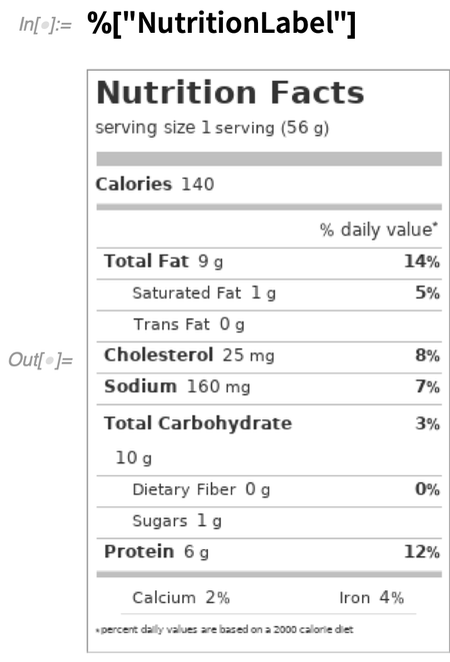
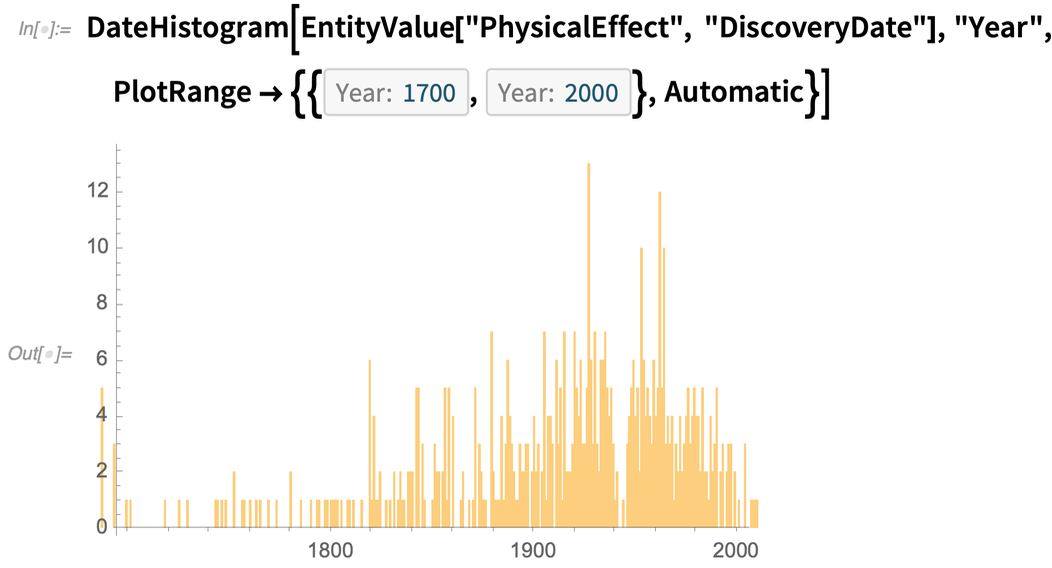
Egy másik példaként egy új entitás típus, amely hozzá lett adva, a fizikai hatások. Itt van néhány véletlenszerű:

És egy példa arra, hogy mit lehet tenni az összes adattal ebben a tartományban, itt van egy hisztogram az időpontokról, amikor ezeket a hatásokat felfedezték:
Egy másik példa arra, hogy mit csináltunk, most már van egy olyan terület is, amit (nyelves szemmel) „nehézsúlyú” tartománynak nevezhetnénk – a súlyzós edzésgyakorlatok:
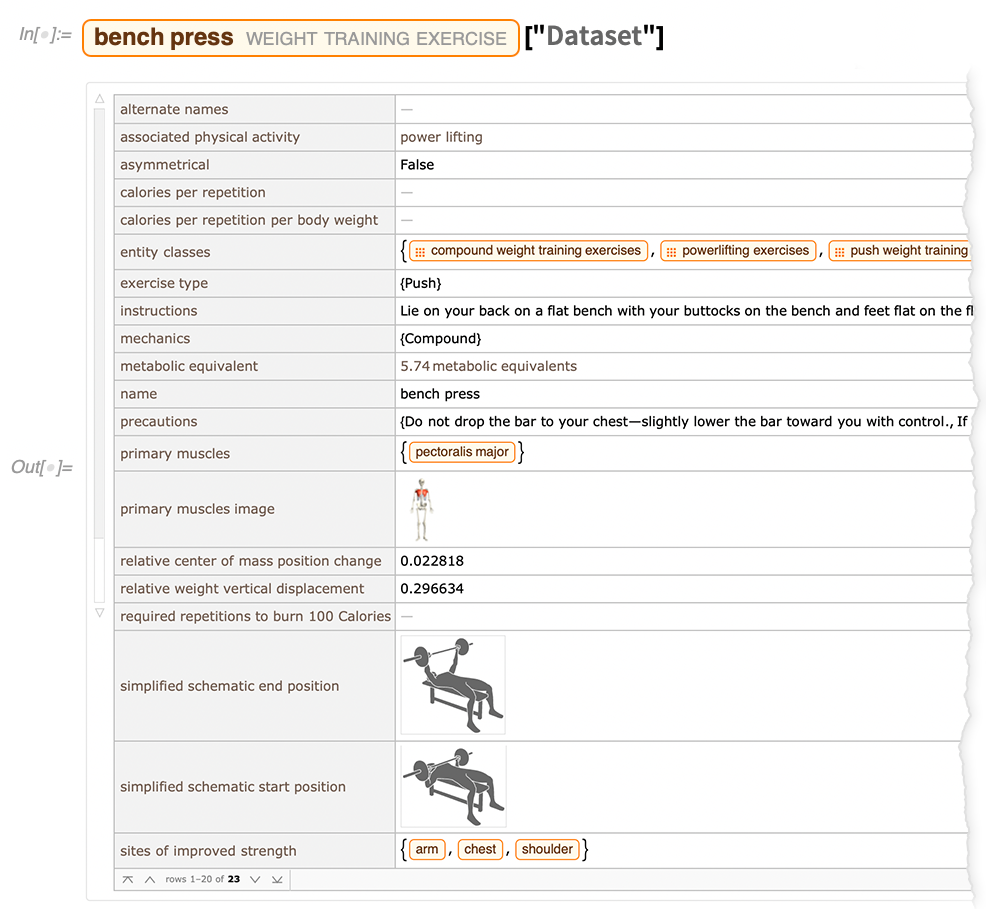 A Wolfram Tudásbázis fontos jellemzője, hogy szimbolikus objektumokat tartalmaz, amelyek nem csak „egyszerű adatokat” – például számokat vagy karakterláncokat -, hanem teljes számítási tartalmat is reprezentálhatnak. Ennek példájaként a 12.2-es verzió lehetővé teszi, hogy a Wolfram Demonstrations Projectet – annak összes aktív Wolfram Language kódjával és jegyzetfüzetével– közvetlenül a tudásbázisban érjük el. Íme néhány véletlenszerű Demonstráció:
A Wolfram Tudásbázis fontos jellemzője, hogy szimbolikus objektumokat tartalmaz, amelyek nem csak „egyszerű adatokat” – például számokat vagy karakterláncokat -, hanem teljes számítási tartalmat is reprezentálhatnak. Ennek példájaként a 12.2-es verzió lehetővé teszi, hogy a Wolfram Demonstrations Projectet – annak összes aktív Wolfram Language kódjával és jegyzetfüzetével– közvetlenül a tudásbázisban érjük el. Íme néhány véletlenszerű Demonstráció:

A tulajdonságok értékei lehetnek dinamikus interaktív objektumok:
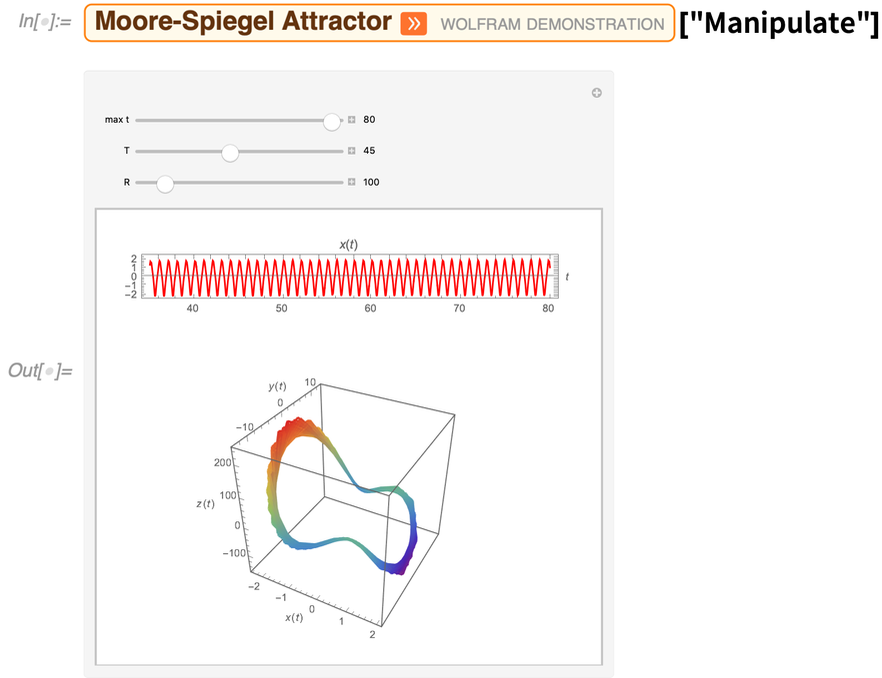
És mivel minden kiszámítható, például azonnal készíthetünk egy képkollázst az összes bemutatóról egy adott témában:

A gépi tanulás folytatódó története
Közel 7 év telt el azóta, hogy először mutattuk be a Classify és Predict programokat, és elkezdtük a neurális hálózatok teljes integrálását a Wolfram Language nyelvbe. Két fő irányvonal volt: az első a „szuperfunkciók” kifejlesztése, mint például a Classify és a Predict, amelyek – a lehető legautomatikusabban – gépi tanuláson alapuló műveleteket végeznek. A második irány egy erős szimbolikus keretrendszer biztosítása a neurális hálókkal kapcsolatos legújabb fejlesztések kihasználásához (különösen a Wolfram Neural Net Repository révén), valamint a rugalmas folyamatos fejlesztés és kísérletezés lehetővé tétele.
A 12.2-es verzió mindkét területen előrelépés történt. Egy példa az új szuperfunkcióra a FaceRecognize. Adjunk meg neki egy kis számú megjelölt arcpéldát, és megpróbálja azonosítani őket képeken, videókon stb. Szerezzünk néhány gyakorló adatot webes keresésekből (és igen, ez kissé zajos):

Most hozzon létre egy arcfelismerőt ezekkel a képzési adatokkal:

Ezt most arra használhatjuk, hogy megtudjuk, ki van a képernyőn egy videó minden egyes képkockájában:

Most ábrázolja az eredményeket:

A Wolfram Neural Net Repositoryban rendszeresen új hálózatok kerülnek fel. A 12.1-es verzió óta körülbelül 20 újfajta hálózat került hozzá – köztük számos új transzformátorháló, valamint az EfficientNet és például a BioBERT és a SciBERT típusú, kifejezetten tudományos cikkek szövegén képzett jellemző-kivonó hálózatok.
A hálózatok minden esetben azonnal elérhetőek – és használhatóak – a NetModel segítségével. A 12.2-es verzióban frissült a hálózatok vizuális megjelenítése:
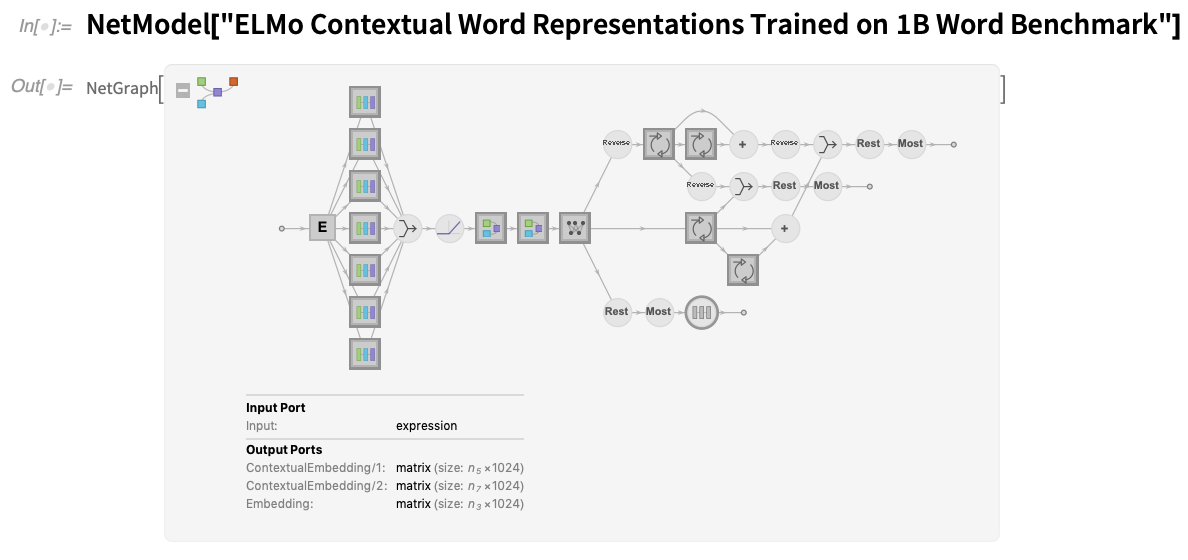
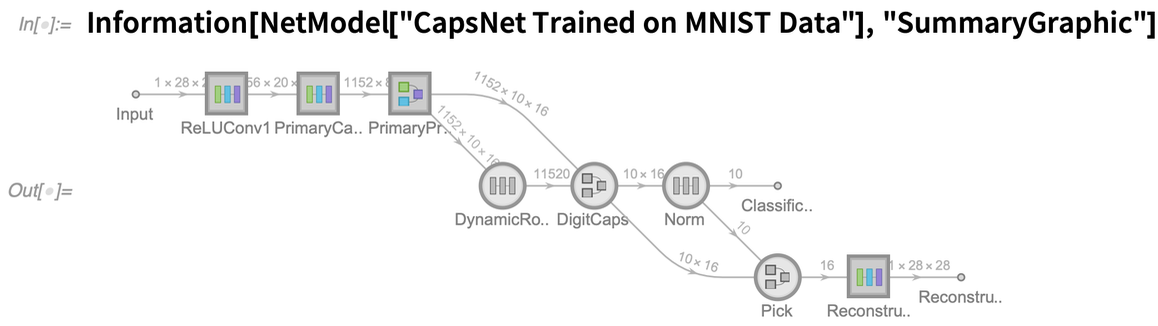
Rengeteg új ikon van, de most már egyértelmű az a konvenció is, hogy a körök a háló rögzített elemeit, míg a négyzetek a képezhető elemeket jelölik. Ezen kívül, ha egy ikonban vastag keret van, az azt jelenti, hogy van benne egy további hálózat, amit kattintással láthatunk. Akár a NetModelből származó hálózatról van szó, akár a saját maga által készített hálózatról (vagy a kettő kombinációjáról), gyakran kényelmes a hálózat „összefoglaló grafikáját” kinyerni, például azért, hogy a dokumentációban vagy egy kiadványban elhelyezhesse. Az Information több szintű összefoglaló grafikát biztosít:
Az alapvető neurális hálós keretrendszerünkhöz több fontos kiegészítés is tartozik, amelyek kibővítik a neurális hálós funkciók körét, amelyekhez hozzáférhetünk. Az első az, hogy a 12.2-es verzióban natív kódolókkal rendelkezünk a gráfok és az idősorok számára. Tehát itt például 20 véletlenszerűen megnevezett gráfból készítünk egy feature space plotot:

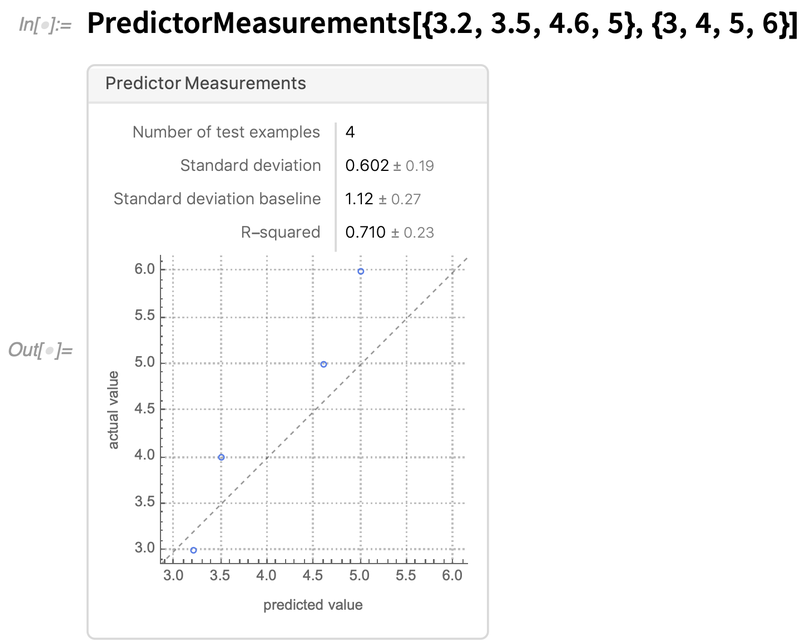
A keretrendszer másik fejlesztése a modellek diagnosztikájához kapcsolódik. Sok évvel ezelőtt bevezettük a PredictorMeasurements és a ClassifierMeasurements modellek teljesítményének szimbolikus ábrázolására. A 12.2-es verzióban – számos kérésre válaszolva – lehetővé tettük, hogy a PredictorMeasurements objektum létrehozásához a modell helyett a végleges előrejelzéseket tápláljuk be, és egyszerűsítettük a PredictorMeasurements objektumok megjelenését és működését:
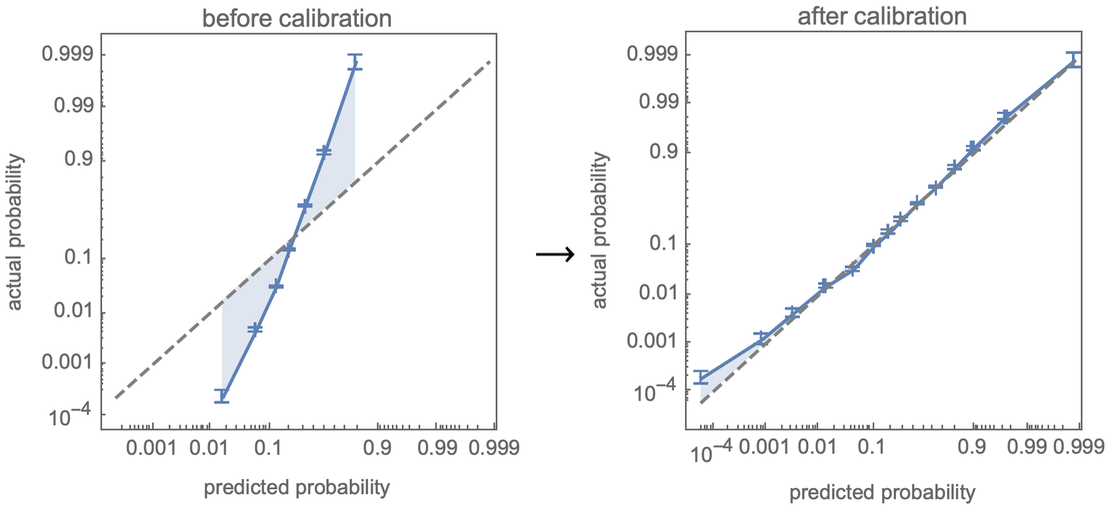
A ClassifierMeasurements fontos új funkciója, hogy képes egy kalibrációs görbe kiszámítására, amely összehasonlítja a tesztkészlet mintavételezése során megfigyelt tényleges valószínűségeket az osztályozó előrejelzéseivel. Ami azonban még ennél is fontosabb, hogy a Classify automatikusan kalibrálja a valószínűségeit, és ezzel tulajdonképpen megpróbálja „megformálni” a kalibrációs görbét:
A 12.2-es verzióban a neurális hálózatok felépítésének módja is jelentős frissítésen megy keresztül. Az alapvető beállítás mindig is az volt, hogy rétegek egy bizonyos gyűjteményét állítottuk össze, amelyek olyan tömbindexeket mutatnak, amelyek egy gráfban explicit élekkel vannak összekötve. A 12.2-es verzió most bevezeti a FunctionLayer-t, amely lehetővé teszi, hogy valami olyasmit adjunk meg, ami sokkal közelebb áll a közönséges Wolfram Language kódhoz. Példaként itt van egy bizonyos függvényréteg:

És itt van ennek a függvényrétegnek a reprezentációja explicit NetGraphként:
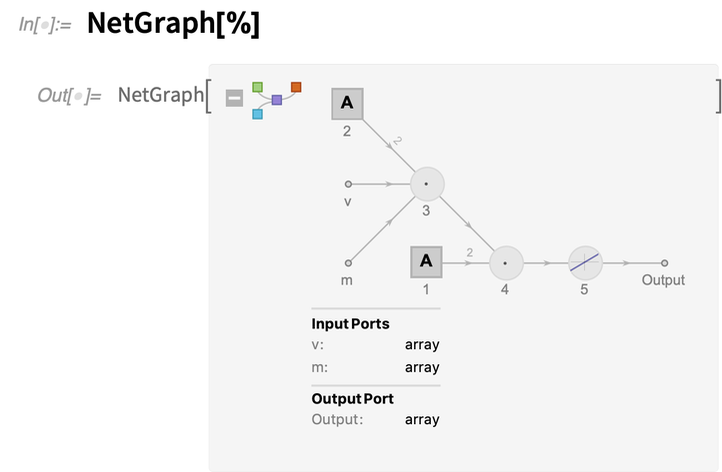
v és m a „bemeneti portok” nevet viseli. A NetArray – amit a négyzet alakú ikonok jeleznek a hálógráfban – egy tanulható tömb, itt csak két elemet tartalmaz.
Vannak olyan esetek, amikor egyszerűbb a „blokk-alapú” (vagy „grafikus”) programozási megközelítést használni, amikor egyszerűen összekötjük a rétegeket (és keményen dolgoztunk azon, hogy a kapcsolatok a lehető legautomatikusabban létrejöjjenek). De vannak olyan esetek is, amikor egyszerűbb a FunctionLayer „funkcionális” programozási megközelítését használni. A FunctionLayer egyelőre csak a Wolfram Nyelvben elérhető konstrukciók egy részhalmazát támogatja – bár ez már most is számos szabványos tömb- és funkcionális programozási műveletet tartalmaz, és a jövőben még többel bővülni fog.
A FunctionLayer fontos jellemzője, hogy az általa előállított neurális háló ugyanolyan hatékony lesz, mint bármely más neurális háló, és futtatható GPU-kon stb. De mit tehetünk azokkal a Wolfram Language-konstrukciókkal, amelyeket a FunctionLayer még nem támogat natívan? A 12.2-es verzióban egy másik új kísérleti funkcióval – a CompiledLayer-rel – bővítjük a hatékonyan kezelhető Wolfram Language kódok körét.
Talán érdemes egy kicsit elmagyarázni, hogy mi történik odabent. A fő neurális hálós keretrendszerünk lényegében egy szimbolikus réteg, amely megszervezi a dolgokat az optimalizált alacsony szintű megvalósításhoz, jelenleg az MXNet-et használva. A FunctionLayer gyakorlatilag bizonyos Wolfram Language-konstrukciókat fordít le közvetlenül az MXNet-re. A tt>CompiledLayer a Wolfram Language-t LLVM-re, majd gépi kódra fordítja, és ezt beilleszti az MXNet-en belüli végrehajtási folyamatba. A CompiledLayer az új Wolfram Language fordítót és annak kiterjedt típuskövetkeztetési és típusdeklarációs mechanizmusait használja.
Oké, tegyük fel, hogy valaki felépített egy csodálatos neurális hálót a Wolfram Language keretrendszerünkben. Minden úgy van beállítva, hogy a hálózat azonnal használható legyen a Wolfram Language szuperfunkciók egész sorában (Classify, FeatureSpacePlot, AnomalyDetection, FindClusters, …). De mi van akkor, ha valaki a hálózatot „önállóan” szeretné használni egy külső környezetben? A 12.2-es verzióban bevezetjük azt a képességet, hogy lényegében bármilyen hálózatot exportálhatunk a nemrég kifejlesztett ONNX szabványos reprezentációban.
És ha már van egy hálózat ONNX-formában, akkor a külső eszközök teljes ökoszisztémáját használhatjuk a legkülönfélébb környezetekben történő telepítéshez. Egy figyelemre méltó példa – ez ma már egy meglehetősen egyszerűsített folyamat -, hogy egy teljes Wolfram Language által létrehozott neurális hálót CoreML-ben futtatunk egy iPhone-on, hogy például közvetlenül beépíthessük egy mobilalkalmazásba.
Formanyomtatvány füzetek
Mi a legjobb módja a strukturált anyaggyűjtésnek? Ha csak néhány elemet szeretne összegyűjteni, egy FormFunction segítségével létrehozott (és például a felhőben telepített) közönséges űrlap is jól működhet. De mi a helyzet akkor, ha hosszabb, gazdagabb anyagot szeretne gyűjteni?
Tegyük fel például, hogy egy olyan kvízt készít, ahol a tanulóknak komplex válaszok egész sorát kell beírniuk. Vagy mondjuk, hogy egy sablont hoz létre, hogy az emberek kitöltsenek valaminek a dokumentációját. Ezekben az esetekben egy új fogalomra van szüksége, amelyet a 12.2-es verzióban vezetünk be: az űrlapfüzetekre.
Az űrlapfüzet alapvetően egy olyan jegyzetfüzet, amely úgy van beállítva, hogy komplex „űrlapként” használható legyen, ahol az űrlap bemenetei lehetnek minden olyan dolog, amit egy jegyzetfüzetben megszoktunk. Az űrlapfüzetek alapvető munkafolyamata a következő. Először is létrehoz egy űrlapfüzetet, meghatározva a különböző „űrlapelemeket” (vagy területeket), amelyeket az űrlapfüzet felhasználójának ki kell töltenie. A szerzői folyamat részeként meghatározza, hogy mi történjen az űrlapfüzet felhasználója által beírt anyaggal, amikor az űrlapfüzetet használja (pl. az anyagot egy Wolfram Data Drop adattárba helyezi, az anyagot elküldi egy felhő felhő API-nak, az anyagot szimbolikus kifejezésként elküldi e-mailben stb.)
Miután elkészítette az űrlapfüzetet, létrehozhat egy aktív verziót, amelyet elküldhet annak, aki használni fogja az űrlapfüzetet. Miután valaki kitöltötte az anyagát a telepített űrlapfüzet saját példányában, megnyom egy gombot, általában a „Submit„-ot, és az anyagát strukturált szimbolikus kifejezésként elküldi a rendszer abba a célállomásra, amelyet az űrlapfüzet szerzője megadott.
Talán érdemes megemlíteni, hogy az űrlapfüzetek hogyan kapcsolódnak valami hasonlóan hangzó dologhoz: a sablonfüzetekhez. Bizonyos értelemben a sablonfüzet a formanyomtatványfüzet fordítottja. Az űrlapfüzet arról szól, hogy a felhasználó beírja az anyagot, amelyet aztán feldolgozunk. A sablonfüzet ezzel szemben arról szól, hogy a számítógép olyan anyagot generál, amelyből aztán feltölthető egy olyan füzet, amelynek szerkezetét a sablonfüzet határozza meg.
Oké, hogyan kezdjünk neki a formanyomtatványfüzeteknek? Csak menjen a File > New > Programmatic Notebook > Form Notebook Authoring menüpontra:
Ez csak egy jegyzetfüzet, ahová bármilyen tartalmat beírhatsz – mondjuk egy magyarázatot arra, hogy mit szeretnél, mit tegyenek az emberek, amikor „kitöltik” az űrlapfüzetet. Vannak azonban speciális cellák vagy cellasorozatok az űrlapfüzetben, amelyeket „űrlapelemeknek” és „szerkeszthető jegyzetfüzetterületeknek” nevezünk. Ezeket „tölti ki” az űrlapfüzet felhasználója, hogy megadja a „válaszait”, és az általuk megadott anyag az, ami elküldésre kerül, amikor megnyomják a „Submit” gombot (vagy bármilyen más, meghatározott végső műveletet).
A szerzői jegyzetfüzetben az eszköztár egy menüt ad a lehetséges űrlapelemekből, amelyeket beilleszthet:
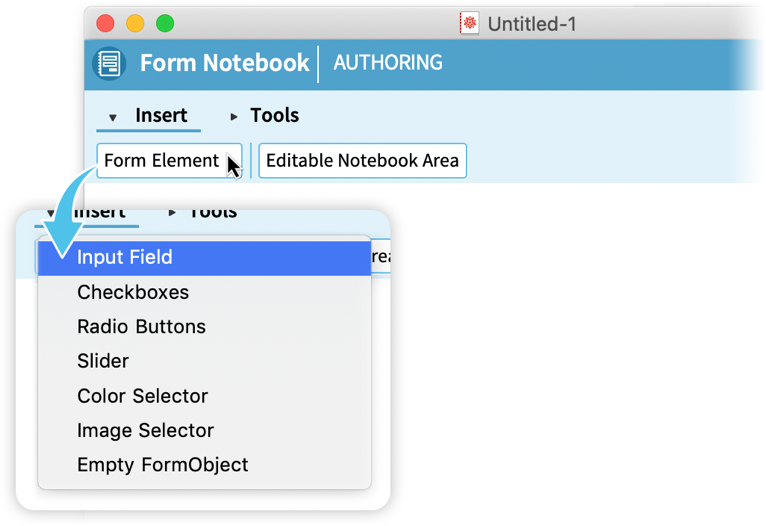
Vegyük példának a „Beviteli mezőt”:
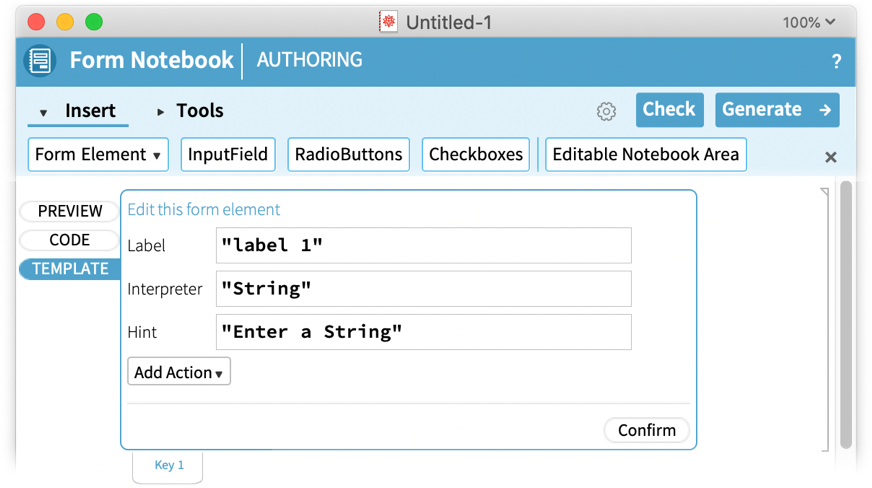
Mit jelent mindez? Alapvetően egy űrlapelemet egy nagyon rugalmas szimbolikus Wolfram Language kifejezés reprezentál, és ez lehetőséget ad arra, hogy megadjuk a kívánt kifejezést. Megadhatsz egy címkét és egy tippet, amit a beviteli mezőbe helyezhetsz. De az Interpreterrel kezded meglátni a Wolfram Language erejét. Ugyanis az Interpreter az, ami fogadja azt, amit az űrlapfüzetek felhasználója beír ebbe a beviteli mezőbe, és számítható objektumként értelmezi. Az alapértelmezett az, hogy csak egy sztringként kezeli. De lehet például egy „Country” vagy egy „MathExpression” is. És ezekkel a választásokkal az anyag automatikusan országként, matematikai kifejezésként stb. értelmeződik, és a felhasználó általában felszólítást kap, ha a bevitele nem értelmezhető a megadott módon.
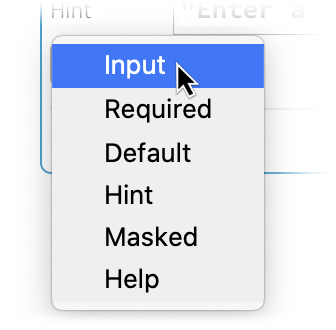
Rengeteg lehetőség van arra, hogy akár egy beviteli mező hogyan működhet. Ezek közül néhányat az Add Action menüpontban talál:
De mi is valójában ez a formaelem? Nyomja meg a CODE fület a bal oldalon, hogy megnézze:

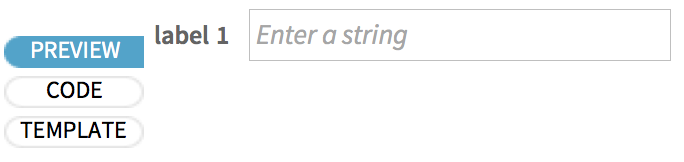
Mit látna itt az űrlapfüzet felhasználója? Nyomja meg az PREVIEW lapot, hogy megtudja:
A beviteli mezőkön kívül sok más lehetséges űrlapelem is létezik. Vannak például jelölőnégyzetek, rádiógombok és csúszkák. És általánosságban a Wolfram Nyelvben létező gazdag szimbolikus felhasználói felület konstrukciók bármelyikét használhatjuk.
Miután befejezte a szerzői munkát, megnyomja a Generate gombot, hogy létrehozzon egy űrlapfüzetet, amelyet készen áll a felhasználók rendelkezésére bocsátani, hogy kitöltsék. A Beállítások olyan dolgokat határoznak meg, mint például, hogy hogyan kell megadni a „submit” műveletet, és hogy mi történjen, amikor az űrlapfüzetet elküldik:

Mi tehát az „eredménye” egy beküldött űrlapfüzetnek? Alapvetően egy asszociáció, amely megmondja, hogy mit töltöttek ki az űrlapfüzet egyes területein. (A területeket az asszociációban szereplő kulcsok azonosítják, amelyeket akkor adtak meg, amikor a területeket először definiálták a szerzői jegyzetfüzetben).
Nézzük meg, hogyan működik ez egy egyszerű esetben. Itt van egy űrlapfüzet szerzői jegyzetfüzete:
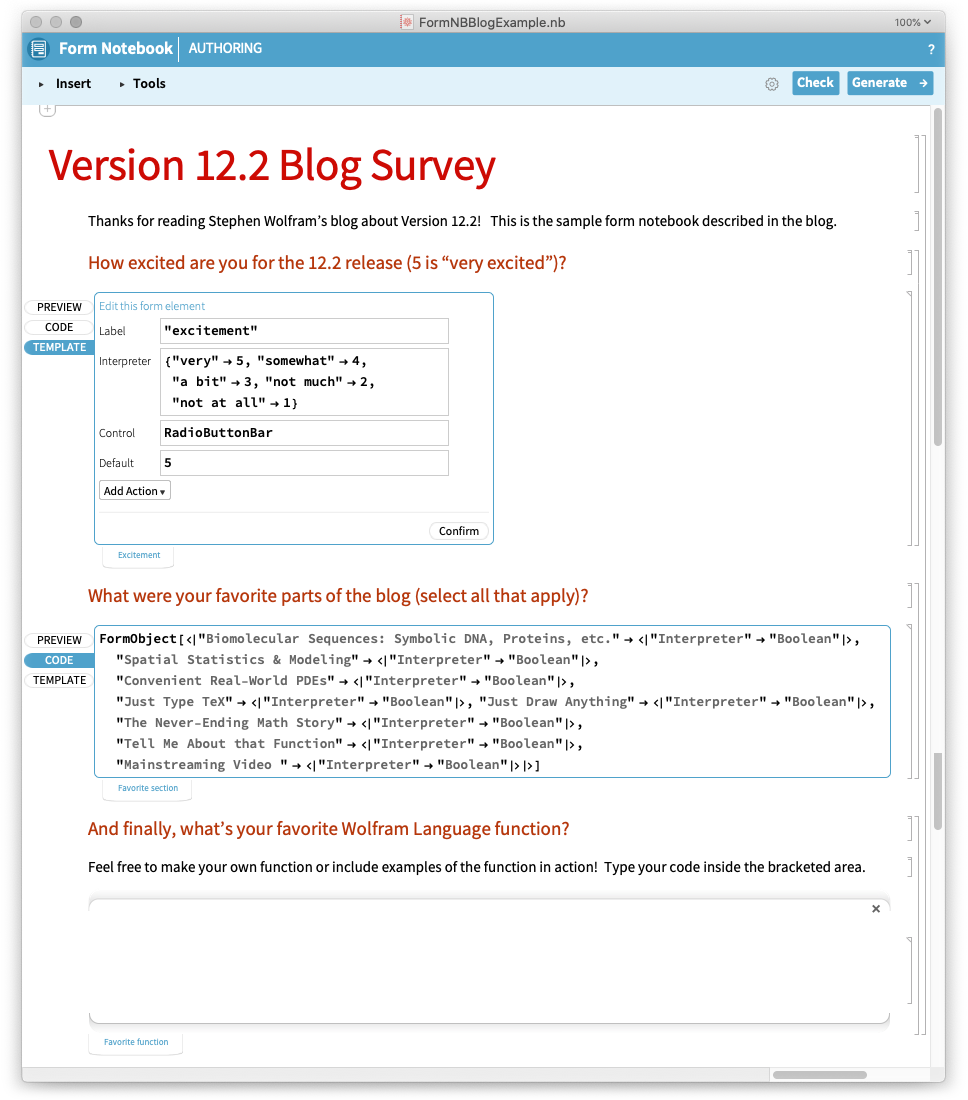
Itt van a generált űrlapfüzet, kitöltésre készen:
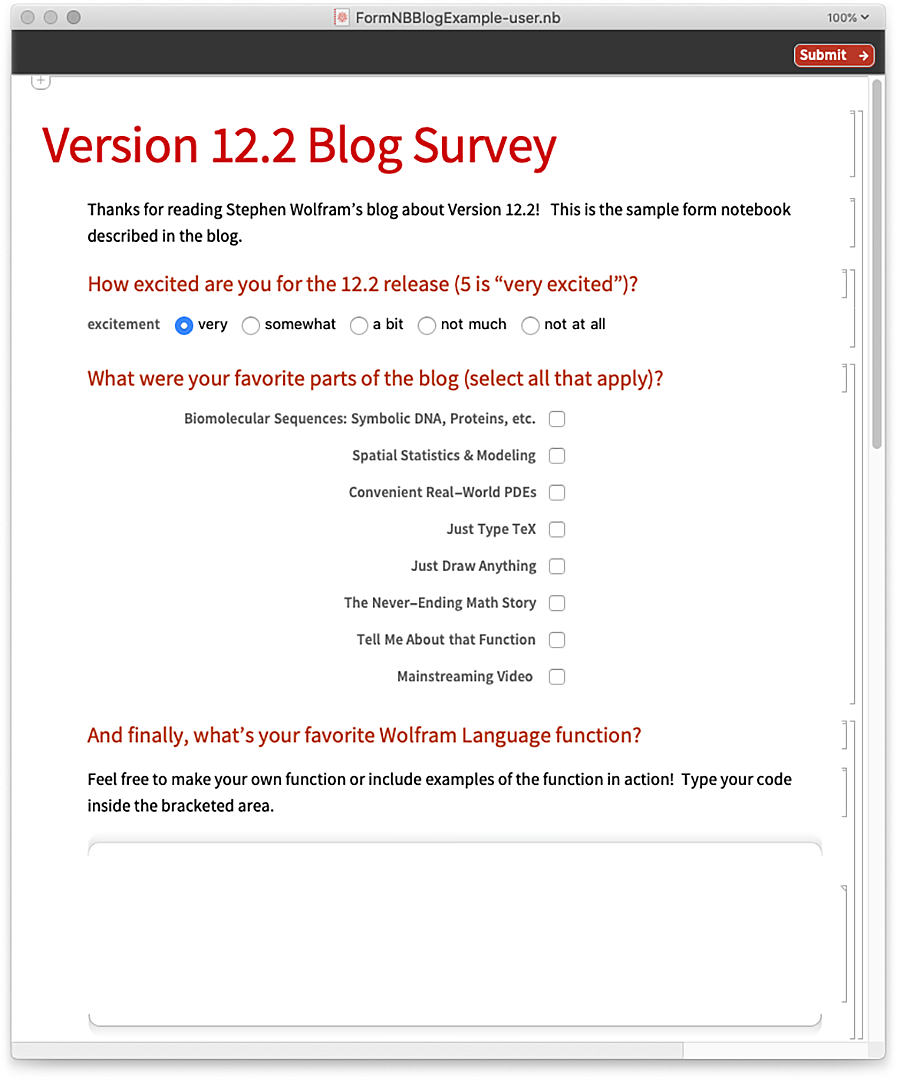
Íme egy példa arra, hogyan lehet kitölteni az űrlapfüzetet:
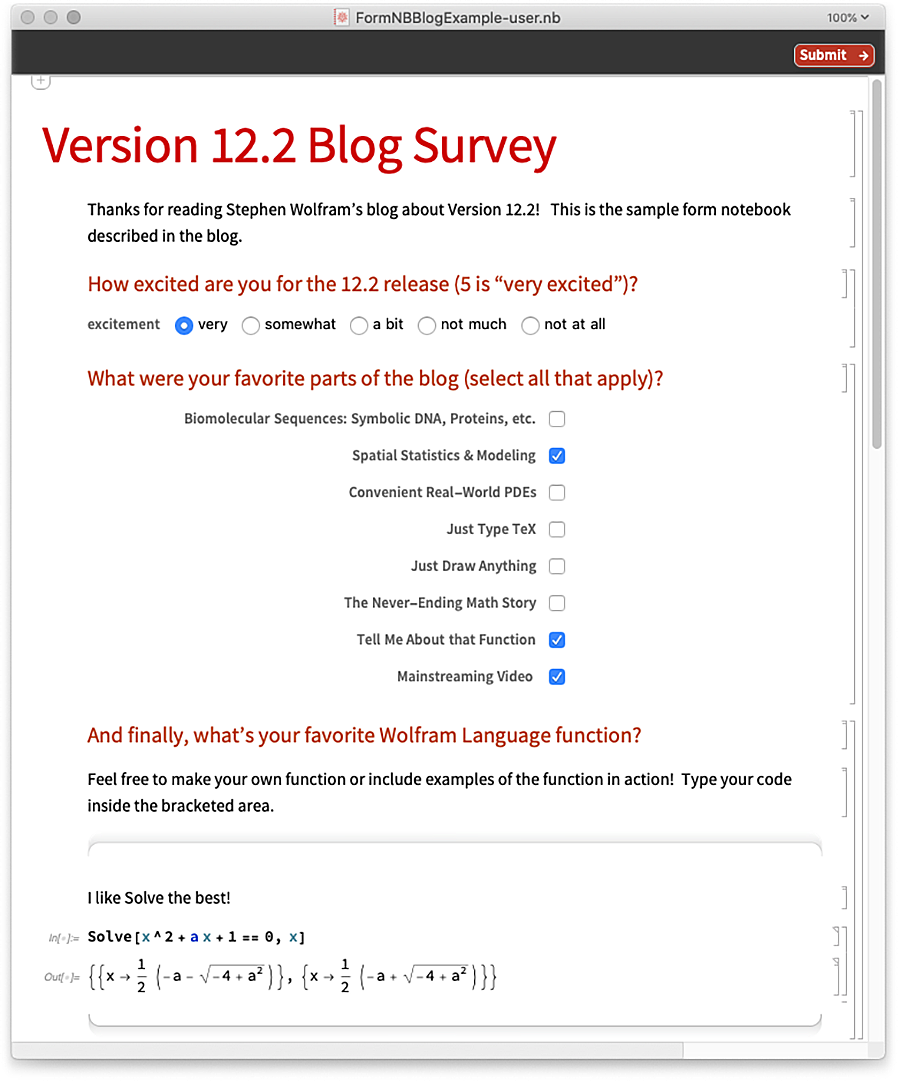
És ez az, ami „visszajön”, amikor a Submitot megnyomják:

A teszteléshez ezt az asszociációt egyszerűen interaktívan elhelyezheti egy jegyzetfüzetben. A gyakorlatban azonban gyakoribb, hogy az asszociációt elküldjük egy adattárba, egy felhőobjektumban tároljuk, vagy általában egy „központosított” helyre tesszük.
Vegye észre, hogy a példa végén van egy szerkeszthető jegyzetfüzet terület – ahol szabad formájú jegyzetfüzet tartalmat adhat meg (cellákkal, címekkel, kóddal, kimenettel stb.), amely mind rögzítésre kerül, amikor az űrlapfüzetet elküldi. Az űrlapfüzetek nagyon hatékony ötlet, és mindenhol látni fogod őket használni. Első példaként a Wolfram Function Repository, a Wolfram Demonstrations Project stb. különböző benyújtási notebookjai válnak form notebookokká. Arra is számítunk, hogy az oktatási környezetben is sokan fogják használni a form notebookokat. És ennek részeként egy olyan rendszert építünk, amely a Wolfram Language-t használja fel az űrlapfüzetekben (és máshol) szereplő válaszok értékelésére.
Ennek kezdeteit a 12.2-es verzióban láthatjuk az AssessmentFunction kísérleti függvénnyel – amely az Interpreterhez hasonlóan az űrlapfüzetekbe kapcsolható. De még az AssessmentFunction tervezett teljes képességei nélkül is hihetetlenül sok mindent el lehet végezni – oktatási és egyéb környezetben – az űrlapfüzetek használatával.
Érdemes egyébként megérteni, hogy az űrlapfüzeteket végső soron minden esetben nagyon egyszerű használni. Igen, rengeteg mélységgel rendelkeznek, ami nagyon sokféle dolog elvégzését teszi lehetővé. És ezek alapvetően csak a Wolfram Nyelv egész szimbolikus struktúrája miatt lehetségesek, és azért, mert a Wolfram Notebookok végső soron szimbolikus kifejezésekként reprezentálódnak. De amikor egy adott célra kell használni őket, akkor nagyon áramvonalasak és egyszerűek, és teljesen reális, hogy néhány perc alatt létrehozzunk egy hasznos formanyomtatványfüzetet.
Még több jegyzetfüzet
A jegyzetfüzeteket – a hierarchikus cellák stb. alapvető jellemzőivel együtt – 1987-ben találtuk fel. De egy harmadik évszázadon keresztül fokozatosan csiszoltuk és egyszerűsítettük a működésüket. A 12.2-es verzióban pedig mindenféle hasznos és kényelmes új jegyzetfüzetfunkciót találunk.
ClickToCopy
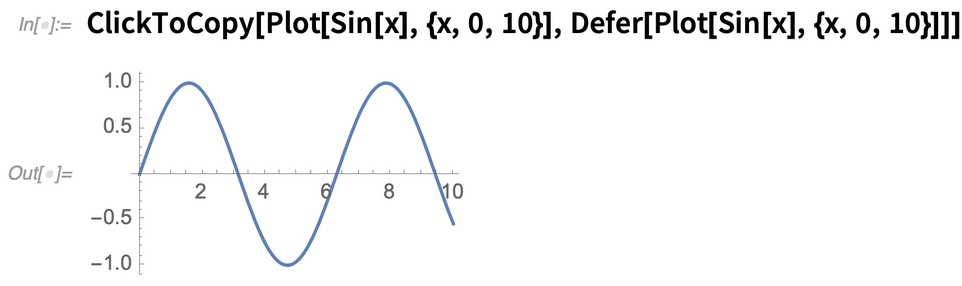
Ez egy nagyon egyszerű funkció, de nagyon hasznos. Lát valamit a jegyzetfüzetben, és igazából csak annyit szeretne vele tenni, hogy másolja (vagy esetleg másoljon valamit, ami kapcsolódik hozzá). Nos, akkor csak használja a

Ha valami kiértékeletlen dolgot akarsz kattintással átmásolni, használd a Defert:
Egyszerűsített hiperhivatkozás (és hiperhivatkozás-szerkesztés)
A ++h 1996 óta beilleszt egy hiperhivatkozást a Wolfram Notebookba. A 12.2-es verzióban azonban két fontos újdonság van a hiperhivatkozásokkal kapcsolatban. Először is, az automatikus hiperhivatkozás, amely a legkülönbözőbb helyzeteket kezeli. Másodszor pedig egy modernizált és egyszerűsített mechanizmus a hiperhivatkozások létrehozására és szerkesztésére.

Csatolt cellák
A 12.2-es verzióban felfedünk valamit, ami már egy ideje belsőleg is megvan: a lebegő, teljesen működőképes cellák bármelyik cellához (vagy dobozhoz, vagy az egész notebookhoz) való csatolásának lehetőségét. Ehhez a funkcióhoz szimbolikus notebookprogramozásra van szükség, de nagyon hatékony dolgokat tesz lehetővé – különösen a kontextuális és a „just-in-time” felületek bevezetésében. Íme egy példa, amely egy dinamikus számlálót helyez el, amely a prímszámokat számolja a cellák zárójelének jobb alsó részén:

Sablon doboz infrastruktúraNéha hasznos, ha az, amit látsz, nem az, amid van. Például, ha valamit J0(x)-ként akarsz megjeleníteni egy jegyzetfüzetben, de valójában BesselJ[0, x]. Sok éven át volt az Interpretation, mint lehetőségünk arra, hogy ezt beállítsuk bizonyos kifejezésekhez. De volt egy általánosabb mechanizmusunk is – a TemplateBox -, amely lehetővé teszi, hogy kifejezéseket vegyünk, és külön megadjuk, hogyan kell megjeleníteni és értelmezni őket.
A 12.2-es verzióban tovább általánosítottuk – és egyszerűsítettük – a TemplateBox-ot, lehetővé téve, hogy tetszőleges felhasználói felület elemeket építsen be, valamint hogy olyan dolgokat is megadjon, mint a másolási viselkedés. Az új TEX beviteli mechanizmusunk például alapvetően nem más, mint az új TemplateBox alkalmazása.
Ebben az esetben a "TeXAssistantTemplate" a notebook stíluslapjában definiált funkcióra utal, amelynek paramétereit a TemplateBox-ban megadott asszociáció határozza meg:

Az asztali interfész a felhőhöz
A Wolfram Notebooks fontos jellemzője, hogy úgy vannak beállítva, hogy asztali számítógépen és felhőben is működjenek. És még a Wolfram Language verziók között is rengeteg folyamatos fejlesztés történt a jegyzetfüzetek felhőben való működésében. A 12.2-es verzióban azonban a jegyzetfüzetek interfészét különösen egyszerűsítették az asztali és a felhő között.
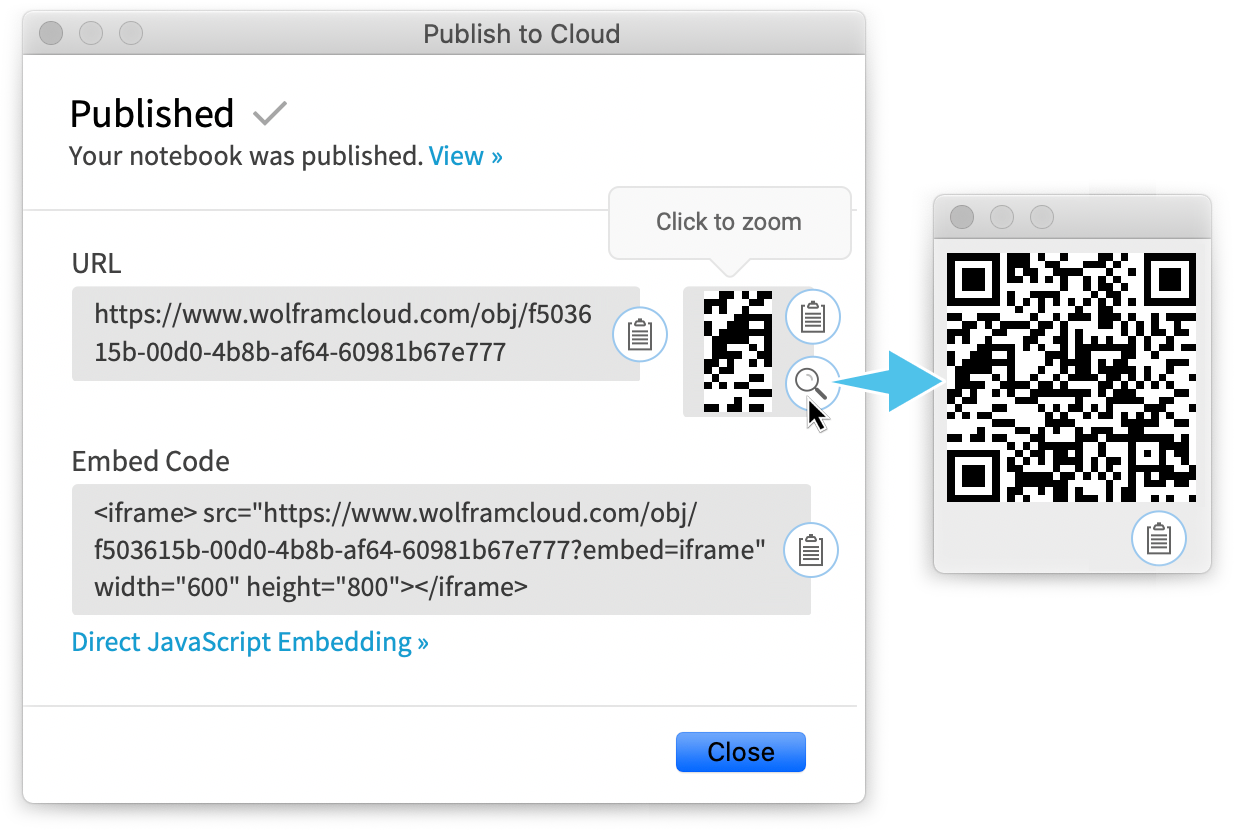
Egy különösen szép mechanizmus, amely már néhány éve elérhető bármely asztali jegyzetfüzetben, a File > Publish to Cloud… menüpont, amely lehetővé teszi, hogy a jegyzetfüzetet azonnal elérhetővé tegye egy közzétett felhőjegyzetfüzetként, amelyet bárki elérhet egy webböngészővel. A 12.2-es verzióban egyszerűsítettük a notebook közzétételének folyamatát.
Amikor prezentációt tartok, általában egy asztali jegyzetfüzetet készítek menet közben (vagy esetleg egy már létezőt használok). A prezentáció végén pedig szokásommá vált, hogy közzéteszem a felhőben, hogy a hallgatóságból bárki interakcióba léphessen vele. De hogyan adhatom meg mindenkinek a notebook URL-címét? Virtuális környezetben egyszerűen használhatod a csevegést. De egy tényleges fizikai előadáson ez nem lehetséges. A 12.2-es verzióban pedig egy kényelmes alternatívát kínálunk: a Publish to Cloud eredménye tartalmaz egyQR kódot, amelyet az emberek a telefonjukkal rögzíthetnek, majd azonnal az URL-címre léphetnek, és a telefonjukon interakcióba léphetnek a jegyzetfüzettel.
Van még egy másik figyelemre méltó új elem, amely a Publish to Cloud eredményében látható: „Közvetlen JavaScript-beágyazás”. Ez egy link a Wolfram Notebook Embedderhez, amely lehetővé teszi a felhőalapú jegyzetfüzetek JavaScript segítségével történő közvetlen beágyazását weboldalakra.
Mindig könnyű egy iframe segítségével beágyazni egy weboldalt egy másikba. Az iframe-eknek azonban számos korlátja van, például előre meg kell határozni a méretüket. A Wolfram Notebook Embedder lehetővé teszi a felhőfüzetek teljes funkcionalitású, folyékony beágyazását – valamint a jegyzetfüzetek szkriptelhető vezérlését a weboldal más elemeiből. És mivel a Wolfram Notebook Embedder úgy van beállítva, hogy az oEmbed beágyazási szabványt használja, alapvetően minden szabványos webes tartalomkezelő rendszerben azonnal használható.
Beszéltünk már arról, hogy a notebookokat az asztali számítógépről a felhőbe küldjük. A 12.2-es verzió másik újdonsága azonban a felhőfájlrendszer gyorsabb és egyszerűbb böngészése az asztalról – ahogyan azt a következő oldalról elérhetjük: File > Open from Cloud… and File > Save to Cloud…
Kriptográfia és biztonság
Az egyik dolog, amit a Wolfram Nyelvvel szeretnénk elérni, hogy a lehető legegyszerűbben kapcsolódhasson szinte bármilyen külső rendszerhez. És a modern időkben ennek fontos része, hogy kényelmesen tudja kezelni a kriptográfiai protokollokat. És amióta öt évvel ezelőtt elkezdtük bevezetni a kriptográfiát közvetlenül a Wolfram Nyelvbe, meglepett, hogy a Wolfram Nyelv szimbolikus jellege mennyire lehetővé tette számunkra a kriptográfiával kapcsolatos dolgok tisztázását és egyszerűsítését.
Ennek különösen drámai példája volt, ahogyan a blokkláncokat sikerült integrálni a Wolfram Language nyelvbe (a 12.2-es verzió pedig a bloxberget</a is hozzáadta, és még több ilyen is készül). Az egymást követő verziókban pedig a kriptográfia különböző alkalmazásait kezeljük. A 12.2-es verzióban nagy hangsúlyt kapnak a kulcskezelés szimbolikus képességei. A 12.1-es verzió már bevezette a SystemCredential-t a helyi „kulcstár” kulcskezelés kezelésére (támogatva például a „remember me” funkciót a hitelesítési párbeszédpanelekben). A 12.2-ben már a PEM fájlokkal is foglalkozunk.
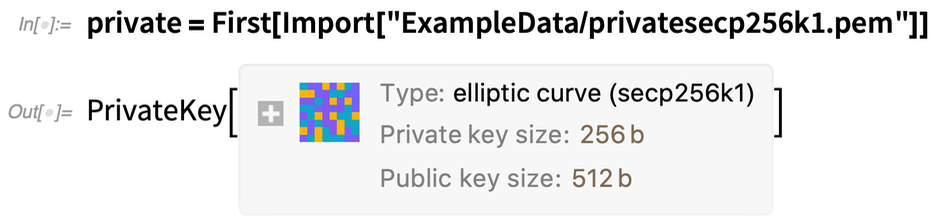
Ha importálunk egy privát kulcsot tartalmazó PEM fájlt, akkor egy szép, szimbolikus ábrázolást kapunk a privát kulcsról:
Most levezethetünk egy nyilvános kulcsot:

Ha egy üzenethez digitális aláírást készítünk a magánkulccsal

akkor ez ellenőrzi az aláírást az általunk levezetett nyilvános kulcs segítségével:

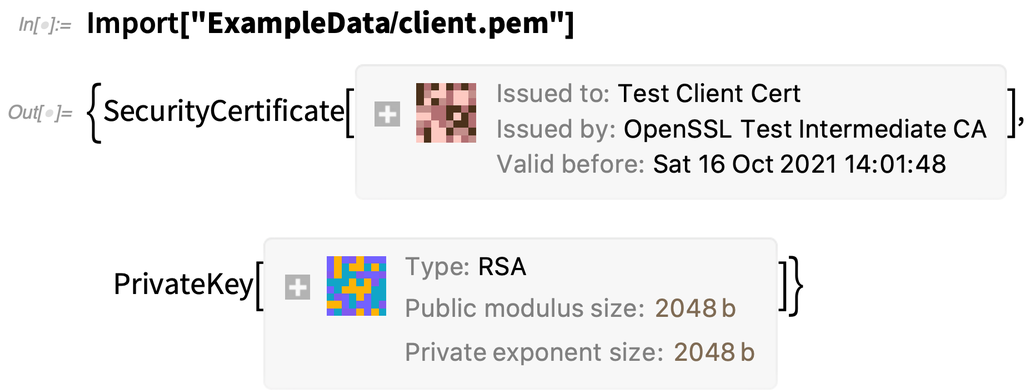
A modern biztonsági infrastruktúra fontos része a biztonsági tanúsítvány fogalma – ez egy olyan digitális konstrukció, amely lehetővé teszi egy harmadik fél számára, hogy tanúsítsa egy adott nyilvános kulcs hitelességét. A 12.2-es verzióban már szimbolikus reprezentációval rendelkezünk a biztonsági tanúsítványokhoz – ez biztosítja, ami szükséges ahhoz, hogy a programok biztonságos kommunikációs csatornákat hozzanak létre külső entitásokkal, ugyanúgy, ahogyan a https teszi:
Csak írja be az SQL-t
A 12.0 verzióban bevezettük a relációs adatbázisok szimbolikus lekérdezésének hatékony funkcióit a Wolfram Nyelvben. Így csatlakozunk egy adatbázishoz::

Az alábbiakban bemutatjuk, hogyan csatlakoztatjuk az adatbázist, hogy a tábláit úgy kezeljük, mint a beépített Wolfram Tudásbázisból származó entitástípusokat:

Most már kérhetünk például egy listát egy adott típusú entitásokról:

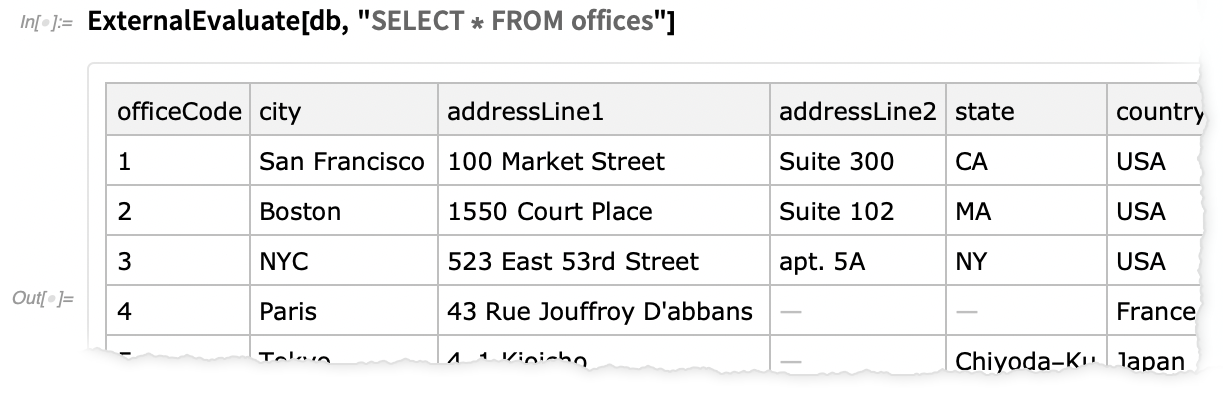
A 12.2 újdonsága, hogy kényelmesen „alá” mehetünk ennek a rétegnek, hogy közvetlenül SQL-lekérdezéseket hajtsunk végre a mögöttes adatbázissal szemben, és a teljes adatbázis-táblát megkapjuk Dataset-kifejezésként:
Ezek a lekérdezések nemcsak olvasni tudnak az adatbázisból, hanem írni is. És hogy még kényelmesebbé tegyük a dolgot, az SQL-t gyakorlatilag úgy kezelhetjük, mint bármely más „külső nyelvet” egy notebookban.
Először is regisztrálnunk kell az adatbázisunkat, hogy megmondjuk, mi ellenében akarjuk futtatni az SQL-t:

És most már csak beírhatjuk az SQL-t bemenetként – és visszakapjuk a Wolfram Language kimenetet, közvetlenül a notebookban:

A mikrokontroller-támogatás 32 bites lesz
Ön kifejlesztett egy vezérlőrendszert vagy jelfeldolgozást a Wolfram Language nyelven. Most hogyan telepítheti azt egy önálló elektronikai eszközre? A 12.0 verzióban bevezettük a Microcontroller Kitet, amellyel szimbolikus Wolfram Language struktúrákból közvetlenül mikrokontroller kódba fordíthatsz.
Rengeteg visszajelzést kaptunk ezzel kapcsolatban, és kérték, hogy bővítsük a támogatott mikrokontrollerek körét. Így a 12.2-es verzióban örömmel mondhatom, hogy 36 új mikrokontrollert támogatunk, különösen a 32 biteseket:

Íme egy példa, amelyben egy szimbolikusan definiált digitális szűrőt telepítünk egy bizonyos típusú mikrokontrollerre, bemutatva az adott mikrokontrollerhez generált egyszerűsített C forráskódot:
![]()


WSTPServer: Wolfram Engine új telepítése
Hosszú távú célunk, hogy a Wolfram Nyelv és az általa nyújtott számítási intelligencia a lehető legelterjedtebb legyen. Ennek része az is, hogy a nyelvet megvalósító Wolfram Engine-t úgy állítsuk fel, hogy az a számítási infrastruktúrák minél szélesebb körében alkalmazható legyen.
A Wolfram Desktop – valamint a klasszikus Mathematica – elsősorban a Wolfram Engine notebookos felületét biztosítja, amely egy helyi asztali rendszeren fut. Lehetőség van a Wolfram Engine közvetlen futtatására is – parancssori programként (pl. WolframScript segítségével) – egy helyi számítógépes rendszeren. És természetesen a Wolfram Engine-t a felhőben is futtathatjuk, akár a teljesWolfram Cloud (nyilvános vagy privát), akár a könnyebb felhő- és szerverajánlatokon keresztül (a már létező és a hamarosan megjelenő).
A 12.2-es verzióval azonban a Wolfram Engine új telepítésű: WSTPServer. Ha a Wolfram Engine-t a felhőben használja, akkor jellemzően http vagy hasonló protokollokon keresztül kommunikál vele. De a Wolfram Language több mint harminc éve rendelkezik saját dedikált protokollal a szimbolikus kifejezések és minden, ami körülöttük van, átvitelére. Eredetileg MathLinknek hívtuk, de az utóbbi években, ahogy fokozatosan bővült, WSTP-nek neveztük el: Wolfram Symbolic Transfer Protocol. A WSTPServer, ahogy a neve is mutatja, egy könnyű szervert biztosít, amely a Wolfram Engines-t szállítja, és lehetővé teszi, hogy közvetlenül kommunikáljon velük natív WSTP-ben.
Miért fontos ez? Alapvetően azért, mert ez lehetővé teszi, hogy olyan tartós Wolfram Language munkameneteket kezeljen, amelyek más alkalmazások számára szolgáltatásként működhetnek. Például általában minden egyes alkalommal, amikor meghívod a WolframScriptet, egy új, friss Wolfram Engine-t kapsz. De a wolframscript -wstpserver használatával egy adott „WSTP profilnévvel” mindig ugyanazt a Wolfram Engine-t kapod meg, amikor meghívod a WolframScript-et. Ezt közvetlenül a helyi gépeden – vagy távoli gépeken – is megteheted.
A WSTPServer fontos felhasználási módja a Wolfram Engines-ek pooljainak közzététele, amelyek a 12.2 verzió új RemoteEvaluate funkcióján keresztül érhetők el. A WSTPServer segítségével a Wolfram Engines-t a ParallelMap stb. által történő használatra is ki lehet tenni. És végül, mivel a notebook frontend (közel 30 éve!) a WSTP segítségével kommunikál a Wolfram Engine kernellel, mostantól lehetőség van a WSTPServer segítségével egy központi kernel pool létrehozására, amelyhez a notebook frontend csatlakoztatható, lehetővé téve például, hogy egy adott munkamenetet (vagy akár egy adott számítást) a kernelben futtassunk akkor is, ha egy másik számítógépen egy másik notebook frontendre váltunk.
RemoteEvaluate: Számítás valahol máshol…
A „használd a Wolfram nyelvet mindenhol” elv mentén egy másik új funkció a 12.2-es verzióban a RemoteEvaluate. Van CloudEvaluate, amely a Wolfram Cloudban vagy egy Enterprise Private Cloudban végez számításokat. Van ParallelEvaluate, amely párhuzamos almagos almagosok előre meghatározott gyűjteményén végez számításokat. A 12.2-es verzióban pedig van RemoteBatchSubmit, amely kötegelt számításokat küld a felhőalapú számítási szolgáltatóknak.
A RemoteEvaluate egy általános, könnyű „evaluate now” funkció, amely lehetővé teszi, hogy számításokat végezzen bármely megadott távoli gépen, amely rendelkezik elérhető Wolfram Engine-rel. A távoli géphez ssh vagy wstp (vagy http egy Wolfram Cloud végponttal) segítségével csatlakozhatsz.

Néha a RemoteEvaluate-et olyan feladatokra szeretné használni, mint például a rendszerfelügyelet több gépen keresztül. Néha adatokat szeretne gyűjteni vagy küldeni távoli eszközökre. Például lehet, hogy van egy Raspberry Pi számítógépekből álló hálózata, amelyek mindegyike rendelkezik Wolfram Engine-nel – és akkor a RemoteEvaluate segítségével például adatokat kérhet le ezekről a gépekről. Egyébként a ParallelEvaluate-et is használhatja a RemoteEvaluate-ből, így egy távoli gép lesz a mestere egy párhuzamos almagos almagosok gyűjteményének.
Néha azt szeretné, ha a RemoteEvaluate minden kiértékeléskor új példányt indítana a Wolfram Engine-ből. De a WSTPServer segítségével egy állandó Wolfram Language munkamenetet is használhat. A RemoteEvaluate és a WSTPServer egy általános szimbolikus keretrendszer kezdete a futó Wolfram Engine folyamatok ábrázolására. A 12.2-es verzió már rendelkezik a RemoteKernelObject és a $DefaultRemoteKernel programokkal, amelyek szimbolikus módot biztosítanak a távoli Wolfram Language példányok reprezentálására.
És még több (alias „egyik sem”)
A 12.2-es verzió számos nagyobb újdonságát már érintettem. De van még sok más is. További funkciók, fejlesztések, javítások és általános lekerekítés és csiszolás.
A számítási geometriához hasonlóan a ConvexHullRegion most már régiókkal foglalkozik, nem csak pontokkal. És vannak olyan függvények, mint a CollinearPoints és CoplanarPoints, amelyek tesztelik a kollinearitást és a koplanaritást, vagy feltételeket adnak ezek eléréséhez.
Több importálási és exportálási formátum létezik. Mint ahogy most már az archív formátumokat is támogatják: „7z„, „ISO„, „RAR„, „ZSTD„. Van FileFormatQ és ByteArrayFormatQ is, hogy tesztelhessük, hogy a dolgok megfelelnek-e bizonyos formátumoknak.
Az alapnyelvet tekintve vannak olyan dolgok, mint a bonyolultan definiálható ValueQ frissítései. Van még egy RandomGeneratorState, amely a véletlengenerátorok állapotainak szimbolikus reprezentációját adja.
Az asztali csomag (azaz .wl fájl) szerkesztőjében van egy új (kissé kísérleti) Format Cell gomb, amely újraformázza a kódot – és szabályozható, hogy mennyire legyen „szellős” (azaz mennyire legyen sűrű az újsor).
A Wolfram|Alpha-módú jegyzetfüzetekben (ahogyan azt a Wolfram|Alpha Notebook Edition alapértelmezés szerint használja) más új funkciók is vannak, mint például a függvények dokumentációja, amely az adott függvények használatára irányul.
A TableView-ban is több van, valamint egy nagyszámú új paclet szerzői eszköz, amelyek kísérleti jelleggel szerepelnek.
Számomra eléggé elképesztő, hogy mennyi mindent sikerült összehoznunk a 12.2-es verzióban, és mint mindig, most is izgatott vagyok, hogy ez most megjelent és mindenki számára elérhetővé vált.