Einführung der Version 12.2 von Wolfram Language & Mathematica: 228 neue Funktionen und vieles mehr…
Und doch größer als je zuvor
Als wir im März dieses Jahres Version 12.1 veröffentlichten, konnte ich mit Freude sagen, dass es mit 182 neuen Funktionen die größte .1-Version war, die wir je hatten. Aber nur neun Monate später haben wir ein noch größeres .1-Release herausgebracht! Version 12.2, die heute auf den Markt kommt, hat 228 völlig neue Funktionen!

Wir haben immer ein Portfolio von Entwicklungsprojekten am Laufen, wobei die Fertigstellung eines jeden Projekts zwischen einigen Monaten und mehr als zehn Jahren dauern kann. Und natürlich ist es ein Tribut an unser gesamtes Wolfram Language-Technologiepaket, dass wir in der Lage sind, so viel und so schnell zu entwickeln. Aber die Version 12.2 ist vielleicht noch beeindruckender, weil wir uns erst Mitte Juni dieses Jahres auf ihre endgültige Entwicklung konzentriert haben. Denn zwischen März und Juni haben wir uns auf 12.1.1 konzentriert, das ein „Polishing Release“ war. Keine neuen Funktionen, aber mehr als tausend Fehler behoben (der älteste war ein Dokumentationsfehler aus dem Jahr 1993):

Wie haben wir all die neuen Funktionen und Merkmale entwickelt, die jetzt in 12.2 enthalten sind? Das ist eine Menge Arbeit! Und damit verbringe ich persönlich einen Großteil meiner Zeit (zusammen mit anderen „Kleinigkeiten“ wie Physik usw.). Aber in den letzten Jahren haben wir unser Sprachdesign sehr offen gestaltet – wir haben unsere internen Design-Diskussionen per Livestreaming übertragen und so jede Menge großartiges Feedback in Echtzeit erhalten. Bislang haben wir etwa 550 Stunden aufgezeichnet, wovon mindestens 150 Stunden auf die Version 12.2 entfielen.
Übrigens: Zusätzlich zu all den voll integrierten neuen Funktionen in 12.2 hat sich auch im Wolfram Function Repository einiges getan – allein seit der Veröffentlichung von 12.1 wurden dort 534 neue, kuratierte Funktionen für alle möglichen Spezialzwecke hinzugefügt.
Biomolekulare Sequenzen: Symbolische DNA, Proteine, etc.
Es gibt so viele verschiedene Dinge in so vielen Bereichen in Version 12.2, dass man kaum weiß, wo man anfangen soll. Aber lassen Sie uns über einen völlig neuen Bereich sprechen: die Berechnung von Biosequenzen. Ja, wir haben schon seit mehr als einem JahrzehntGen- und Proteindaten in der Wolfram Language. Aber was in 12.2 neu ist, ist der Beginn der Fähigkeit, flexible, allgemeine Berechnungen mit Biosequenzen durchzuführen. Und zwar auf eine Art und Weise, die zu all den chemischen Berechnungsmöglichkeiten passt, die wir der Wolfram Language in den letzten Jahren hinzugefügt haben..
Hier sehen Sie, wie wir eine DNA-Sequenz darstellen (und ja, das funktioniert auch mit sehr langen Sequenzen):

|
Dabei wird die Sequenz in ein Peptid übersetzt (wie ein „symbolisches Ribosom“):
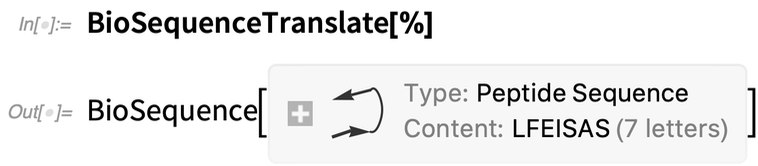
|
Jetzt können wir herausfinden, welches das entsprechende Molekül ist:
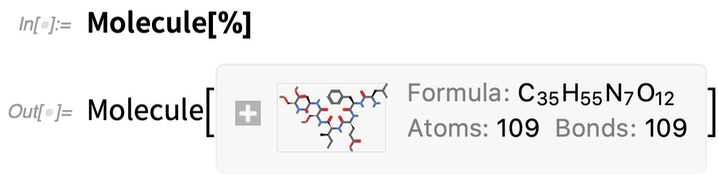
|
Und visualisieren Sie es in 3D (oder berechnen Sie eine Vielzahl von Eigenschaften):
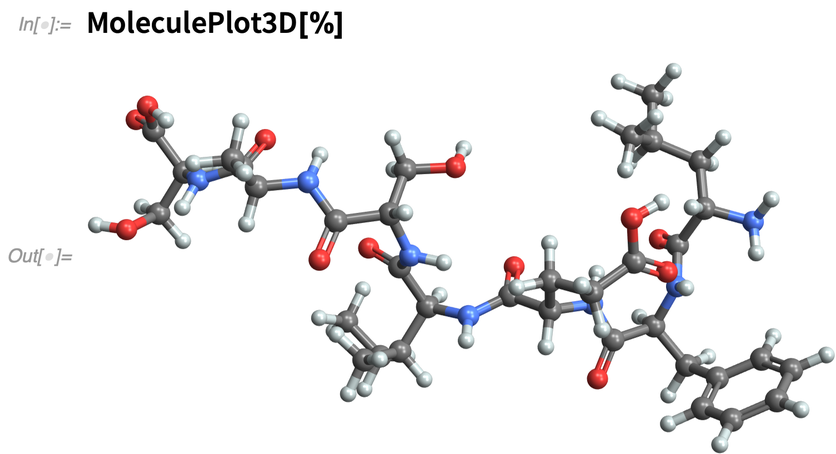
|

|
Man könnte meinen, dass der Umgang mit Genomsequenzen „nur eine String-Manipulation“ ist – und tatsächlich sind unsere String-Funktionen jetzt für die Arbeit mit Biosequenzen eingerichtet:
 |
Aber es gibt auch eine Menge biologiespezifischer Zusatzfunktionen. So wird zum Beispiel eine komplementäre Basenpaar-Sequenz gefunden:

|
Tatsächliche, experimentelle Sequenzen haben oft Basenpaare, die irgendwie unsicher sind – und es gibt Standardkonventionen, um dies darzustellen (z. B. „S“ bedeutet C oder G; „N“ bedeutet eine beliebige Base). Und jetzt verstehen unsere String-Muster solche Dinge auch für Bio-Sequenzen:

|

|
BioSequence ist auch vollständig mit unseren integrierten Genom- und Proteindaten integriert. Hier ist ein Gen, nach dem wir in natürlicher Sprache im Wolfram|Alpha-Stil“ fragen können:
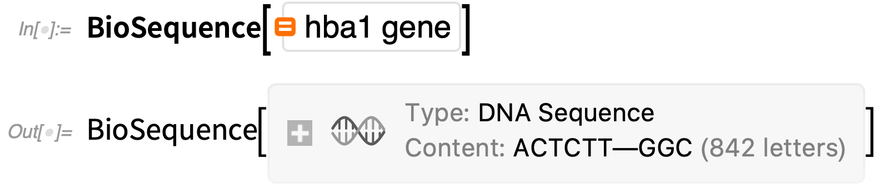 |
Jetzt bitten wir um einen Sequenzabgleich zwischen diesen beiden Genen (in diesem Fall beide menschlich, was natürlich die Standardeinstellung ist):
 |
Was in 12.2 enthalten ist, ist wirklich nur der Anfang dessen, was wir für die Berechnung von Bio-Sequenzen planen. Aber schon jetzt kann man sehr flexibel mit großen Datensätzen arbeiten. So kann ich zum Beispiel mein Genom jetzt ganz einfach aus FASTA-Dateien einlesen und damit beginnen, es zu erforschen…
 |
Räumliche Statistik und Modellierung
Standorte von Vogelnestern, Goldvorkommen, zum Verkauf stehende Häuser, Materialfehler, Galaxien…. Dies sind alles Beispiele für räumliche Punktdatensätze. Und in Version 12.2 haben wir nun eine breite Sammlung von Funktionen für die Bearbeitung solcher Datensätze.
Hier die „räumlichen Punktdaten“ für die Standorte der Hauptstädte der US-Bundesstaaten:
 |
Da es sich um Geodaten handelt, werden sie auf einer Karte dargestellt:
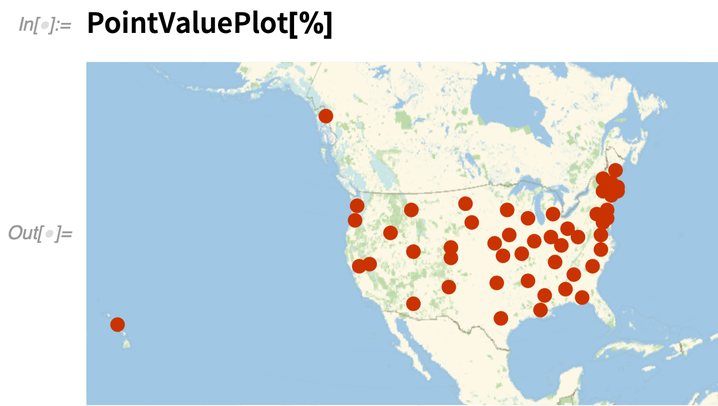 |
Beschränken wir unser Gebiet auf die zusammenhängenden USA:
 |
 |
Jetzt können wir mit der Berechnung von räumlichen Statistiken beginnen. Hier ist zum Beispiel die durchschnittliche Dichte der Hauptstädte der Bundesstaaten:
 |
Angenommen, Sie befinden sich in einer Landeshauptstadt. Hier ist die Wahrscheinlichkeit, die nächstgelegene andere Landeshauptstadt in einer bestimmten Entfernung zu finden::
 |
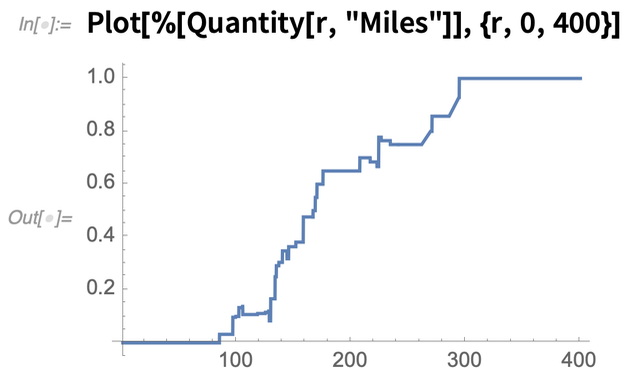 |
Damit wird getestet, ob die Hauptstädte der Bundesstaaten zufällig verteilt sind; das ist natürlich nicht der Fall:
 |
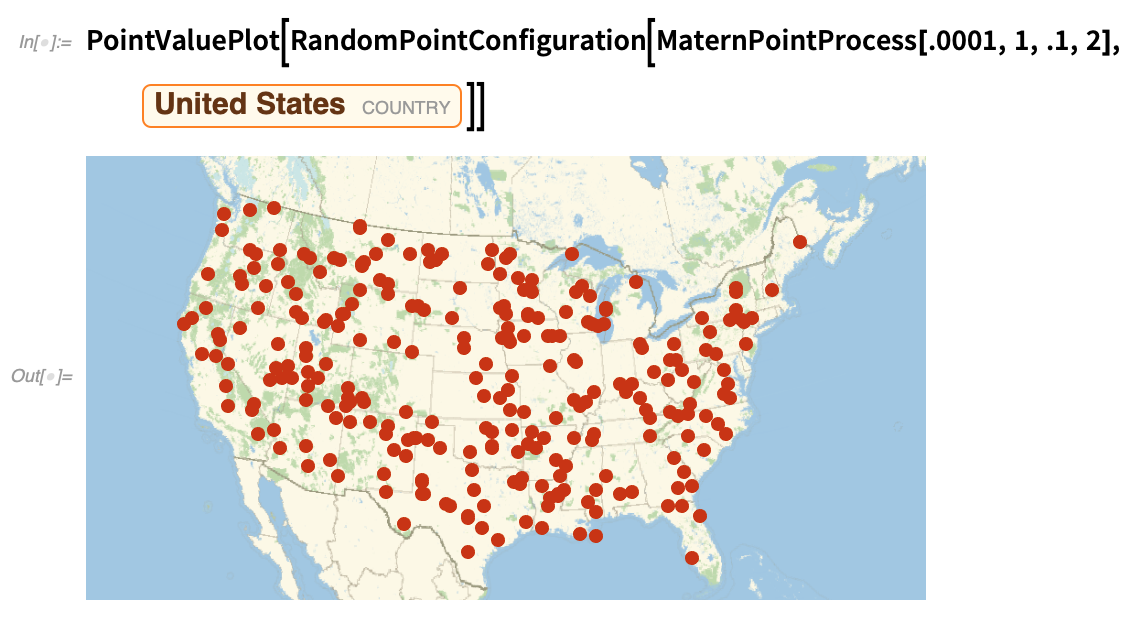 |
Sie können auch den umgekehrten Weg gehen und ein räumliches Modell an die Daten anpassen:
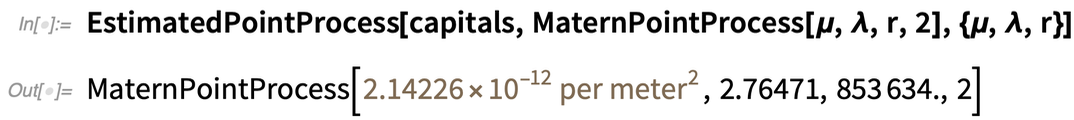 |
Bequeme PDEs aus der realen Welt
In gewisser Weise haben wir seit 30 Jahren darauf hingearbeitet. Wir haben NDSolve zum ersten Mal in Version 2.0 eingeführt und es seitdem ständig verbessert. Aber unser langfristiges Ziel war immer die bequeme Handhabung von realen PDEs, wie sie im High-End-Engineering vorkommen. Und in Version 12.2 haben wir endlich alle Teile der zugrundeliegenden algorithmischen Technologie, um eine wirklich rationalisierte PDE-Lösungserfahrung zu schaffen.
OK, wie spezifiziert man also eine PDE? In der Vergangenheit geschah dies immer explizit in Form von bestimmten Ableitungen, Randbedingungen usw. Die meisten PDEs, die z. B. in der Technik verwendet werden, bestehen jedoch aus übergeordneten Komponenten, die Ableitungen, Randbedingungen usw. „zusammenpacken“, um Merkmale der Physik, der Materialien usw. darzustellen.
Die unterste Ebene unseres neuen PDE-Rahmens besteht aus symbolischen „Termen“, die gängigen mathematischen Konstrukten entsprechen, die in realen PDEs vorkommen. Hier ist zum Beispiel ein 2D-„Laplacian-Term„:
 |
Und das ist alles, was man braucht, um die ersten 5 Eigenwerte der Laplace-Figur in einem regelmäßigen Polygon zu finden:
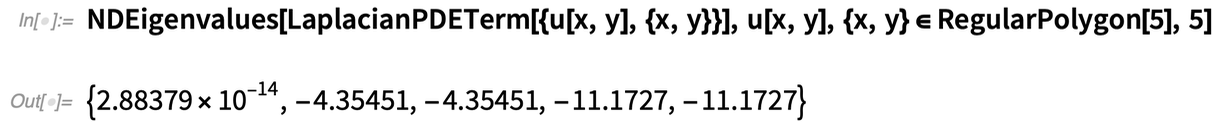 |
Und das Wichtigste ist, dass man diese Art von Operation in eine ganze Pipeline einbauen kann. Wie hier erhalten wir die Region aus einem Bild, lösen die 10. Eigenform und zeichnen das Ergebnis in 3D auf:
 |
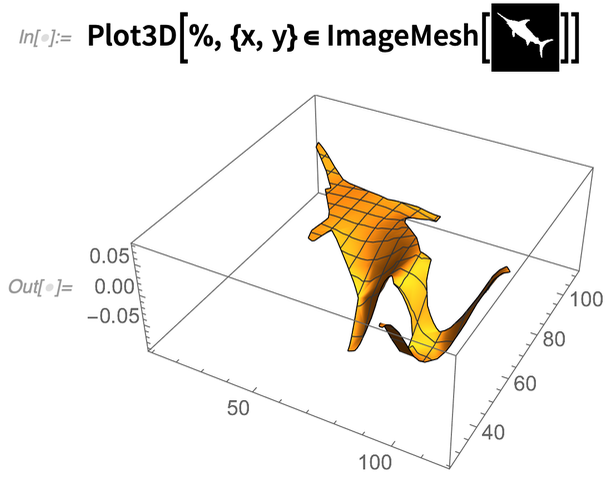 |
 |
Neben einzelnen Begriffen gibt es auch „Komponenten“, die mehrere Begriffe, meist mit verschiedenen Parametern, kombinieren. Hier ist eine Helmholtz-PDE-Komponente:
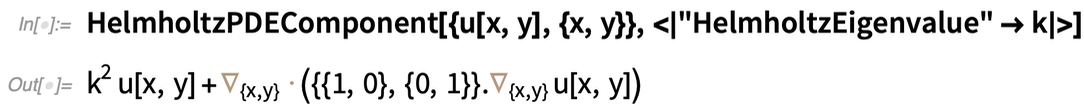 |
Nebenbei sei darauf hingewiesen, dass unsere „Terme“ und „Komponenten“ dazu dienen, die symbolische Struktur von PDEs in einer Form darzustellen, die für strukturelle Manipulationen und für Dinge wie die numerische Analyse geeignet ist. Und um sicherzustellen, dass sie ihre Struktur beibehalten, werden sie normalerweise in einer inaktivierten Form aufbewahrt. Man kann sie aber jederzeit „aktivieren„, wenn man z. B. algebraische Operationen durchführen möchte:
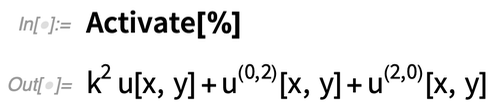 |
Bei realen PDEs hat man es oft mit tatsächlichen, physikalischen Prozessen zu tun, die in tatsächlichen physikalischen Materialien stattfinden. Und in Version 12.2 haben wir sofortige Möglichkeiten, nicht nur Dinge wie Diffusion, sondern auch Akustik, Wärmeübertragung und Stofftransport zu behandeln und Eigenschaften tatsächlicher Materialien einzubringen. Typischerweise ist die Struktur so, dass es eine PDE-„Komponente“ gibt, die das Massenverhalten des Materials darstellt, zusammen mit einer Vielzahl von PDE-„Werten“ oder „Bedingungen“, die Randbedingungen darstellen.
Hier ist eine typische PDE-Komponente, die Materialeigenschaften aus der Wolfram Knowledgebase verwendet:
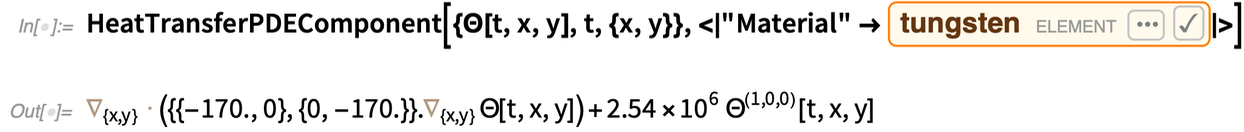 |
Die möglichen Randbedingungen sind sehr vielfältig und komplex. Für die Wärmeübertragung gibt es zum Beispiel HeatFluxValue, HeatInsulationValue und fünf weitere symbolische Konstrukte zur Spezifikation von Randbedingungen. In jedem Fall besteht die Grundidee darin, zu sagen, wo (geometrisch) die Bedingung gilt, worauf sie sich bezieht und welche Parameter mit ihr verbunden sind.
So gibt es zum Beispiel eine Bedingung, die besagt, dass überall außerhalb des (kreisförmigen) Bereichs, der durch x2 + y2 = 1 definiert ist, eine feste „Oberflächentemperatur“ θ0 herrscht:
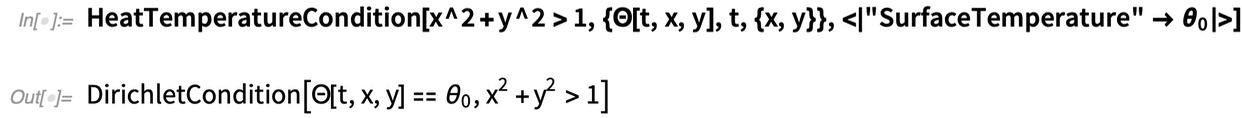 |
Was hier im Grunde passiert, ist, dass unsere hochrangige „Physik“-Beschreibung in explizite „mathematische“ PDE-Strukturen wie Dirichlet-Randbedingungen „kompiliert“ wird
OK, und wie passt das alles in einer realen Situation zusammen? Lassen Sie mich ein Beispiel zeigen. Aber zuerst möchte ich eine Geschichte erzählen. Damals im Jahr 2009 saß ich mit unserem leitenden PDE-Entwickler beim Tee. Ich nahm einen Teelöffel in die Hand und fragte: „Wann werden wir in der Lage sein, die Spannungen darin zu modellieren?“ Unser leitender Entwickler erklärte mir, dass es noch eine ganze Menge zu tun gäbe, um diesen Punkt zu erreichen. Nun, ich freue mich, sagen zu können, dass wir nach 11 Jahren Arbeit mit der Version 12.2 so weit sind. Und um das zu beweisen, hat mir unser Hauptentwickler gerade einen (Rechen-)Löffel geschenkt!

Der Kern der Berechnung ist ein 3D-Diffusions-PDE-Term mit einem „Diffusionskoeffizienten“, der durch einen Tensor vom Rang 4 gegeben ist, der durch den parametrized by Elastizitätsmodul (hier Y) und die Poissonzahl (ν) parametrisiert ist:

Es gibt Randbedingungen, die festlegen, wie der Löffel gehalten und geschoben wird. Die Lösung der PDE (die nur ein paar Sekunden dauert) ergibt das Verschiebungsfeld für den Löffel


Die PDE-Modellierung ist ein kompliziertes Gebiet, und ich halte es für eine große Leistung, dass es uns gelungen ist, sie jetzt so sauber zu „verpacken“. Aber in Version 12.2 ist neben der eigentlichen Technologie der PDE-Modellierung noch etwas anderes wichtig: eine große Sammlung von Aufsätzen über die PDE-Modellierung – insgesamt etwa 400 Seiten mit detaillierten Erklärungen und Anwendungsbeispielen, derzeit in den Bereichen Akustik, Wärmeübertragung und mass transport, aber viele andere Bereiche werden folgen.
Geben Sie einfach TEX ein
In der Wolfram Language geht es darum, sich in präziser Computersprache auszudrücken. Aber in Notizbüchern kann man sich auch mit normalem Text in natürlicher Sprache ausdrücken. Was aber, wenn man darin auch Mathematik darstellen möchte? Seit 25 Jahren verfügen wir über die Infrastruktur für die Darstellung von Mathematik – über unsere Boxsprache. Aber der einzige bequeme Weg, die Mathematik einzugeben, ist über die mathematischen Konstrukte der Wolfram Language, die in gewisser Weise eine rechnerische Bedeutung haben müssen.
Aber was ist mit „Mathematik“, die „nur für menschliche Augen“ gedacht ist? Die ein bestimmtes visuelles Layout hat, das Sie spezifizieren wollen, die aber nicht unbedingt eine bestimmte zugrundeliegende rechnerische Bedeutung hat, die definiert wurde? Nun, seit vielen Jahrzehnten gibt es dank meines Freundes Don Knuth eine gute Möglichkeit, solche Mathematik zu spezifizieren: Verwenden Sie einfach TEX. Und in Version 12.2 unterstützen wir nun die direkte Eingabe von TEX-Mathematik in Wolfram Notebooks, sowohl auf dem Desktop als auch in der Cloud. Darunter wird TEX in unsere Box-Darstellung umgewandelt, so dass es strukturell mit allem anderen interagiert. Aber Sie können es einfach als TEX eingeben und bearbeiten.
Die Schnittstelle ist sehr ähnlich wie die ctrl+= Schnittstelle für natürliche Spracheingaben im Stil von Wolfram|Alpha. Aber für TEX (in Anlehnung an die TEX-Standardbegrenzer) ist es ctrl>+$.
Geben Sie ctrl+$ ein und Sie erhalten ein TEX-Eingabefeld. Wenn Sie mit dem TEX fertig sind, drücken Sie einfach ctrl und er wird gerendert:

Entering TEX in text cells is the most common thing to want. Die Version 12.2 unterstützt aber auch die Eingabe von TEX in Eingabezellen:

Zeichnen Sie einfach irgendetwas
Geben Sie Canvas[] ein und Sie erhalten eine leere Leinwand, auf der Sie zeichnen können, was Sie wollen:
![Canvas[]](https://sciexperts.com/wp-content/uploads/2022/04/just-draw-anything-canvas-02.png)
Wir haben hart daran gearbeitet, die Zeichenwerkzeuge so ergonomisch wie möglich zu gestalten.
Durch die Anwendung von Normal erhalten Sie Grafiken, die Sie dann verwenden oder bearbeiten können:

Wenn Sie eine Leinwand erstellen, kann diese eine beliebige Grafik als anfänglichen Inhalt haben – und sie kann einen beliebigen Hintergrund haben, den Sie wünschen:


Jetzt ist es ein anderes Molekül:
![]()

Die unendliche Geschichte der Mathematik
Mathematik war von Anfang an ein zentraler Anwendungsfall für die Wolfram Language (und Mathematica). Und es war sehr befriedigend, in den letzten drei Jahrhunderten zu sehen, wie viel Mathematik wir in die Lage versetzt haben, Berechnungen durchzuführen. Aber je mehr wir tun, desto mehr erkennen wir, dass es möglich ist, und desto weiter können wir gehen. Es ist für uns in gewisser Weise zur Routine geworden. Es wird einen Bereich der Mathematik geben, den die Leute schon immer von Hand oder stückweise bearbeitet haben. Und wir werden herausfinden: Ja, wir können einen Algorithmus dafür entwickeln! Wir können den gigantischen Turm von Fähigkeiten, den wir in all den Jahren aufgebaut haben, dazu nutzen, noch mehr Mathematik zu systematisieren und zu automatisieren; um noch mehr Mathematik für jeden rechnerisch zugänglich zu machen. Und so ist es mit Version 12.2 geschehen. Eine ganze Sammlung von Stücken des „mathematischen Fortschritts“.
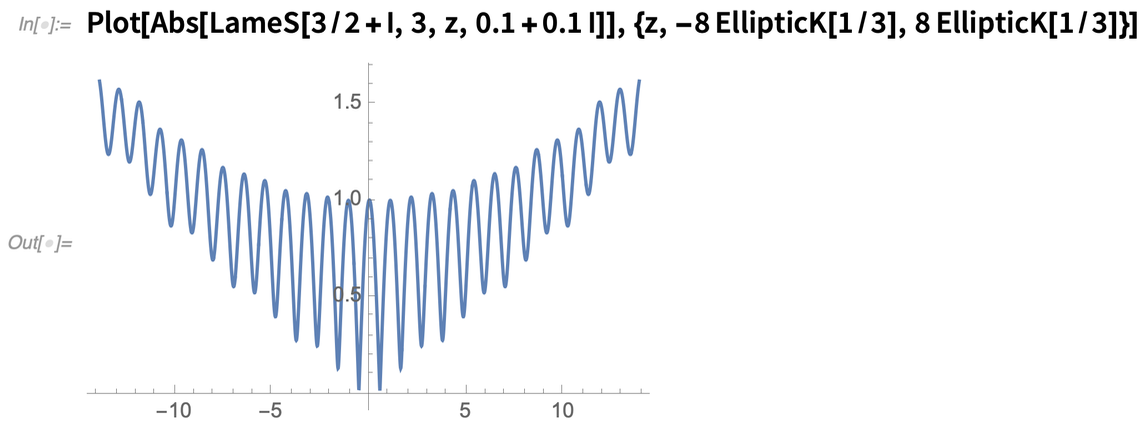
Beginnen wir mit etwas ganz einfachem: spezielle Funktionen. In gewissem Sinne ist jede spezielle Funktion eine Verkapselung eines bestimmten Teils der Mathematik: eine Art, Berechnungen und Eigenschaften für eine bestimmte Art von mathematischem Problem oder System zu definieren. Ausgehend von Mathematica 1.0 haben wir eine hervorragende Abdeckung von Spezialfunktionen erreicht und diese stetig auf immer kompliziertere Funktionen erweitert. Und in Version 12.2 haben wir eine weitere Klasse von Funktionen eingeführt: die Lamé-Funktionen.
Lamé-Funktionen sind Teil der komplizierten Welt des Umgangs mit ellipsoidischen Koordinaten; sie erscheinen als Lösungen der Laplace-Gleichung in einem Ellipsoid. Jetzt können wir sie auswerten, expandieren, transformieren und all die anderen Dinge tun, die mit der Integration einer Funktion in unsere Sprache verbunden sind:

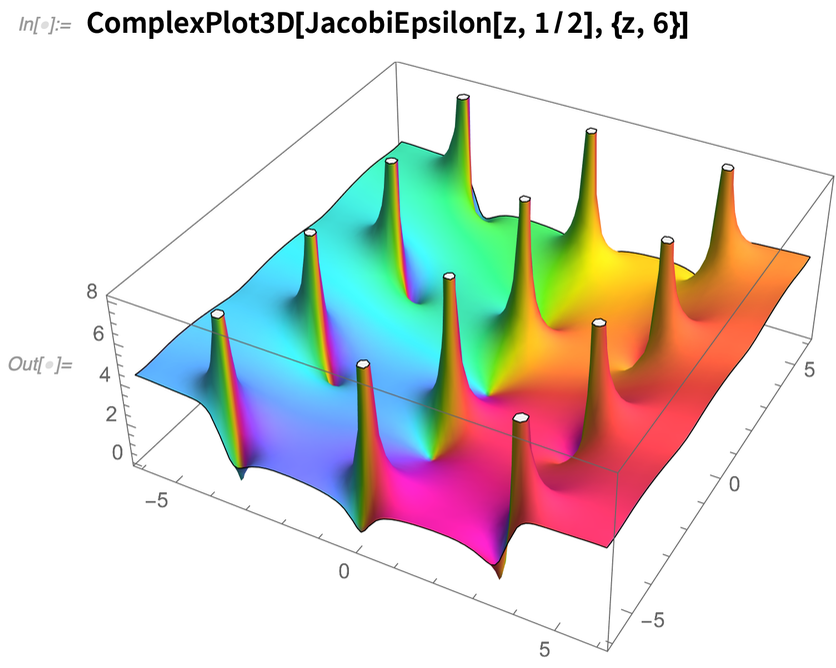
Auch in Version 12.2 haben wir viel an elliptischen Funktionen gearbeitet – wir haben ihre numerische Auswertung drastisch beschleunigt und Algorithmen erfunden, die dies effizient mit beliebiger Genauigkeit tun. Wir haben auch einige neue elliptische Funktionen eingeführt, wie JacobiEpsilon – eine Verallgemeinerung von EllipticE, die Verzweigungsschnitte vermeidet und die analytische Struktur elliptischer Integrale beibehält:
Seit einigen Jahrzehnten sind wir in der Lage, viele symbolische Laplace– und inverse Laplace-Transformationen durchzuführen. Aber in Version 12.2 haben wir das subtile Problem der Konturintegration für inverse Laplace-Transformationen gelöst. Es geht darum, genug über die Struktur von Funktionen in der komplexen Ebene zu wissen, um Verzweigungsschnitte und andere unangenehme Singularitäten zu vermeiden. Ein typisches Ergebnis ist die Summierung über eine unendliche Anzahl von Polen:

Und zwischen Konturintegration und anderen Methoden haben wir auch numerische inverse Laplace-Transformationen hinzugefügt. Am Ende sieht alles ganz einfach aus, aber es ist eine Menge komplizierter algorithmischer Arbeit nötig, um dies zu erreichen:

Ein weiterer neuer Algorithmus, der durch ein feineres „Funktionsverständnis“ ermöglicht wird, hat mit der asymptotischen Entwicklung von Integralen zu tun. Es handelt sich um eine komplexe Funktion, die mit zunehmendem λ immer wackeliger wird:
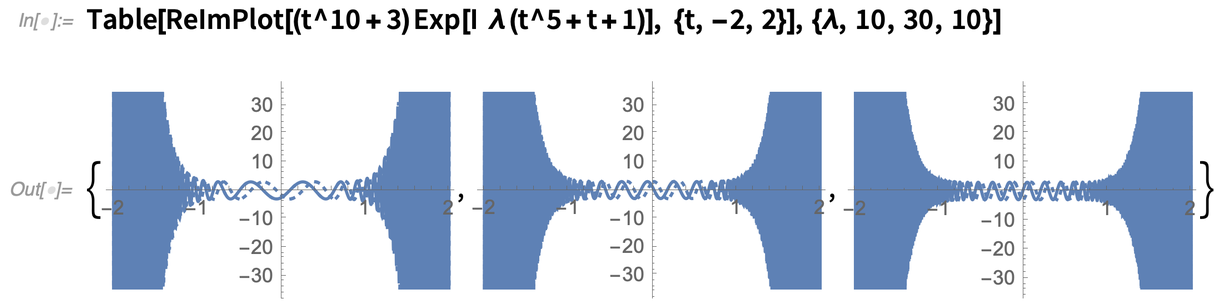
Und hier ist die asymptotische Entwicklung für λ→∞:
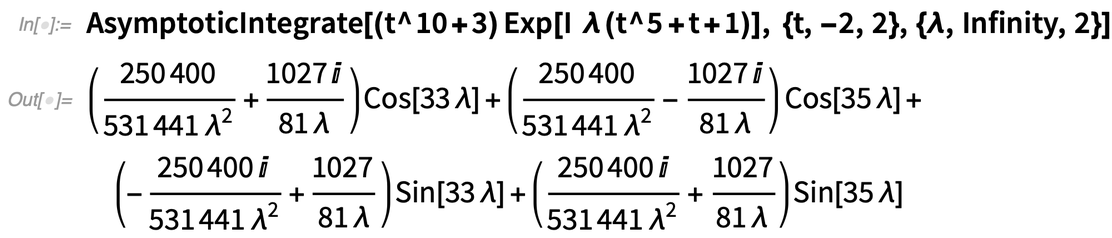
Erzählen Sie mir von dieser Funktion
Es ist eine weit verbreitete Rechenaufgabe, z. B. zu bestimmen, ob eine bestimmte Funktion injektiv ist. Und in einfachen Fällen ist das auch ziemlich einfach zu bewerkstelligen. Aber ein großer Fortschritt in Version 12.2 ist, dass wir jetzt systematisch diese Art von globalen Eigenschaften von Funktionen herausfinden können – nicht nur in einfachen Fällen, sondern auch in sehr schwierigen Fällen. Oft gibt es ganze Netze von Theoremen, die davon abhängen, dass eine Funktion diese oder jene Eigenschaft hat. Jetzt können wir automatisch feststellen, ob eine bestimmte Funktion diese Eigenschaft hat und damit, ob die Theoreme für sie gelten. Und das bedeutet, dass wir systematische Algorithmen entwickeln können, die die Theoreme automatisch anwenden, wenn sie zutreffen.
Hier ist ein Beispiel. Ist Tan[x] injektiv? Nicht global:

Aber über einen bestimmten Zeitraum, ja:
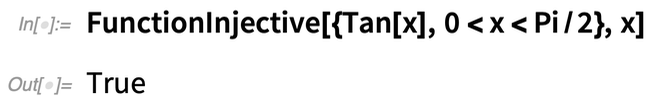
Was ist mit den Singularitäten von Tan[x]? Dies gibt eine Beschreibung der Menge:
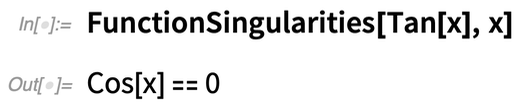
Sie können explizite Werte mit Reduce erhalten:
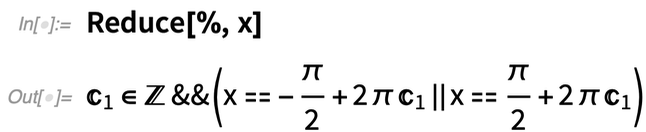
So weit, so einfach. Aber die Dinge werden schnell komplizierter:
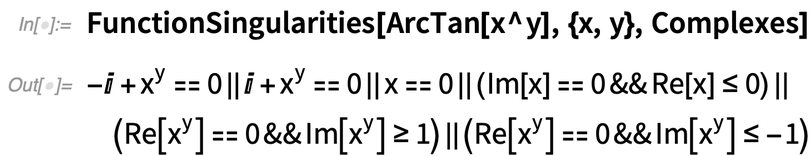
And there are more sophisticated properties you can ask about as well:


Wir haben intern seit langem verschiedene Arten von Funktionstesteigenschaften verwendet. Aber mit Version 12.2 sind die Funktionseigenschaften viel umfassender und für jeden nutzbar. Möchten Sie wissen, ob Sie die Reihenfolge von zwei Grenzwerten vertauschen können? Prüfen Sie FunctionSingularities. Möchten Sie wissen, ob Sie einen multivariaten Variablenwechsel in einem Integral durchführen können? Prüfen SieFunctionInjective.
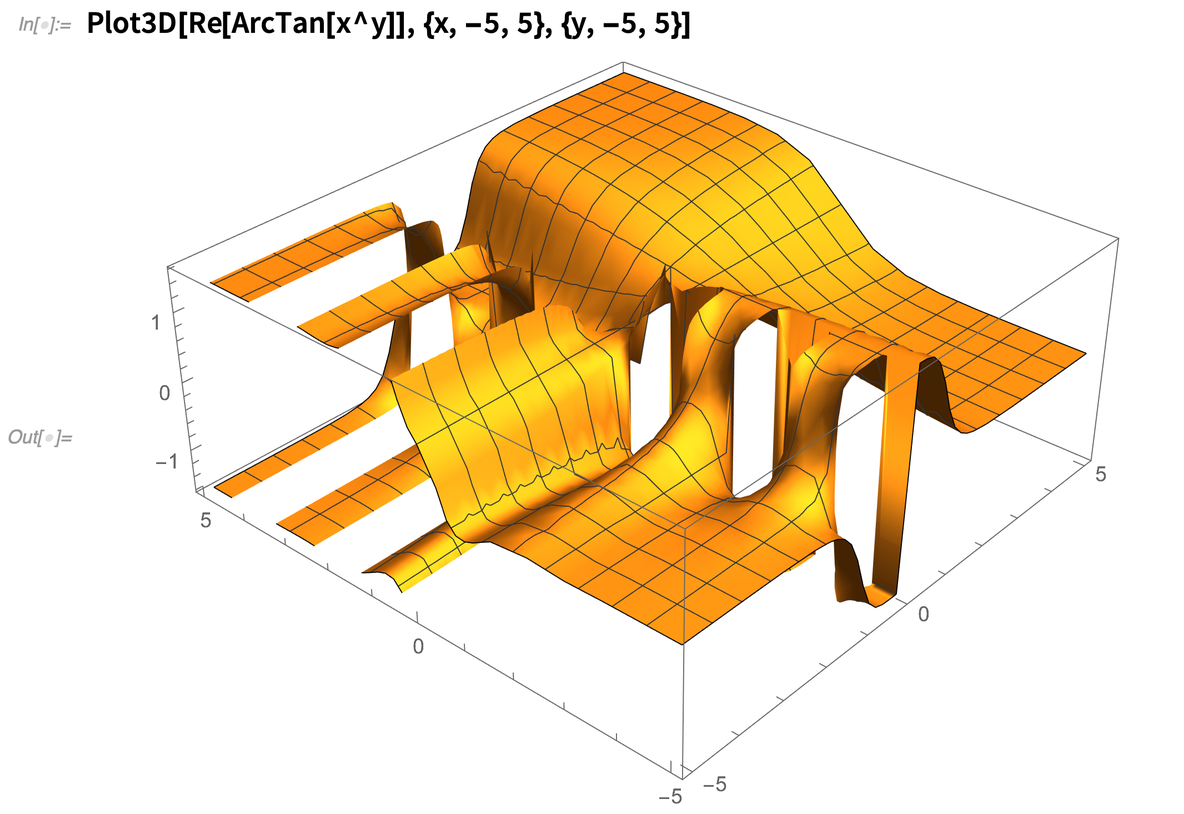
Und ja, auch in Plot3D verwenden wir routinemäßig FunctionSingularities, um herauszufinden, was vor sich geht:
Mainstreaming Video
In Version 12.1 haben wir damit begonnen, Video als integriertes Feature der Wolfram Language einzuführen. Version 12.2 setzt diesen Prozess fort. In Version 12.1 konnten wir Videos nur in Desktop-Notebooks verarbeiten. Jetzt wurde die Funktion auf Cloud-Notebooks ausgeweitet – wenn Sie also ein Video in der Wolfram Language erstellen, kann es sofort in der Cloud bereitgestellt werden.
Eine wichtige neue Video-Funktion in 12.2 ist VideoGenerator. Stellen Sie eine Funktion bereit, die Bilder (und/oder Audio) erzeugt, und VideoGenerator generiert daraus ein Video (hier ein 4-Sekunden-Video):

Um eine Tonspur hinzuzufügen, können wir einfach VideoCombine verwenden:
![]()
Wie würden wir also dieses Video bearbeiten? In Version 12.2 gibt es programmatische Versionen von Standard-Videobearbeitungsfunktionen. VideoSplit zum Beispiel teilt das Video zu bestimmten Zeiten:

Aber die wahre Stärke der Wolfram Language liegt in der systematischen Anwendung beliebiger Funktionen auf Videos. Mit VideoMap können Sie eine Funktion auf ein Video anwenden, um ein anderes Video zu erhalten. Wir könnten zum Beispiel das Video, das wir gerade gemacht haben, schrittweise unscharf machen:
![]()
Außerdem gibt es zwei neue Funktionen für die Analyse von Videos – VideoMapList und VideoMapTimeSeries -, die eine Liste bzw. eine Zeitreihe erzeugen, indem sie eine Funktion auf die Einzelbilder in einem Video bzw. auf die Audiospur anwenden.
Eine weitere neue Funktion, die für die Videoverarbeitung und den Videoschnitt von großer Bedeutung ist, ist VideoIntervals, die die Zeitintervalle bestimmt, in denen ein bestimmtes Kriterium in einem Video gilt:

Jetzt können wir zum Beispiel diese Intervalle im Video löschen:

Eine häufige Operation im praktischen Umgang mit Videos ist die Transkodierung. Und in Version 12.2 können Sie mit der Funktion VideoTranscode ein Video in einen der über 300 von uns unterstützten Container und Codecs umwandeln. Übrigens, 12.2 hat auch neue Funktionen ImageWaveformPlot und ImageVectorscopePlot, die häufig bei der Farbkorrektur von Videos verwendet werden:
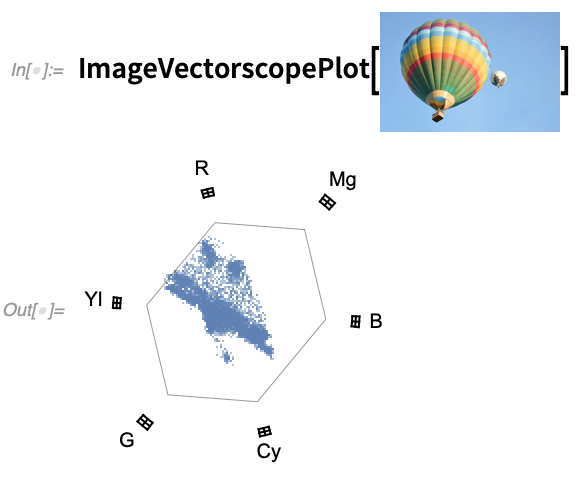
Eines der wichtigsten technischen Probleme bei der Bearbeitung von Videos ist der Umgang mit den großen Datenmengen in einem typischen Video. In Version 12.2 gibt es jetzt eine bessere Kontrolle darüber, wo diese Daten gespeichert werden. Mit der Option GeneratedAssetLocation (mit der Voreinstellung $GeneratedAssetLocation) können Sie zwischen verschiedenen Dateien, Verzeichnissen, lokalen Objektspeichern usw. wählen.
Aber es gibt auch eine neue Funktion in Version 12.2 für den Umgang mit „leichtgewichtigen Videos“, in Form von AnimatedImage. AnimatedImage nimmt einfach eine Liste von Bildern und erzeugt eine Animation, die sofort in Ihrem Notizbuch abgespielt wird – und hat alles direkt in Ihrem Notizbuch gespeichert.

Große Berechnungen? Schicken Sie sie zu einem Cloud-Anbieter!
Diese Frage stellt sich mir recht häufig – vor allem bei unserem Physics Project. Ich habe eine große Berechnung, die ich gerne durchführen würde, aber ich will (oder kann) sie nicht auf meinem Computer durchführen. Stattdessen möchte ich sie als Batch-Auftrag in der Cloud ausführen.
Das ist im Prinzip schon so lange möglich, wie es Cloud-Computing-Anbieter gibt. Aber es war sehr aufwändig und schwierig. Jetzt, in Version 12.2, ist es endlich einfach. Sie können jeden beliebigen Code in der Wolfram Language einfach mit RemoteBatchSubmit als Batch-Job in die Cloud schicken.
Auf der Seite des Batch-Computing-Anbieters ist ein wenig Einarbeitung erforderlich. Zunächst müssen Sie ein Konto bei einem geeigneten Anbieter haben – anfangs unterstützen wir AWS Batch und Charity Engine. Dann müssen Sie die Dinge mit diesem Anbieter konfigurieren (und wir haben Workflows, die beschreiben, wie man das macht). Sobald das erledigt ist, erhalten Sie eine Umgebung für die Remote-Batch-Übermittlung, die im Grunde alles ist, was Sie brauchen, um mit der Übermittlung von Batch-Aufträgen zu beginnen:
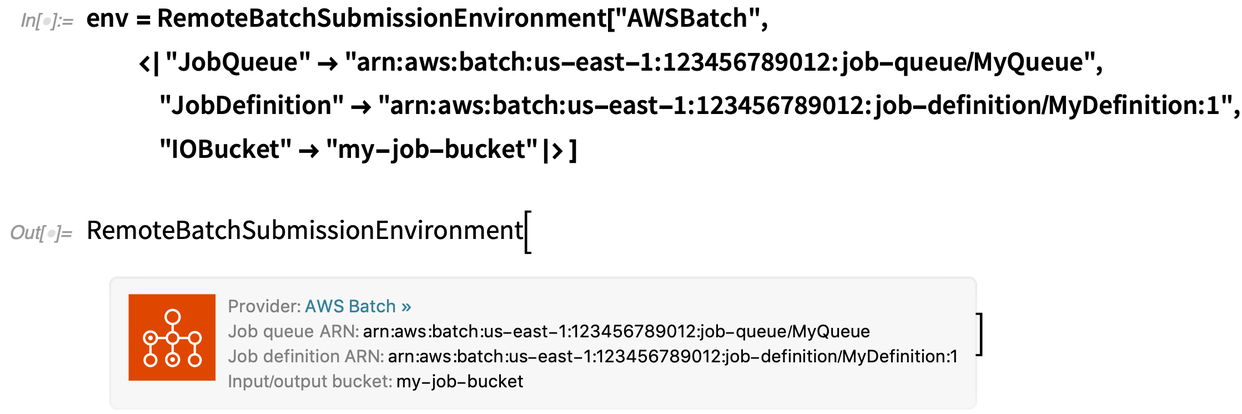
OK, was wäre also zu tun, um beispielsweise ein Training für ein neuronales Netz einzureichen? So würde ich es lokal auf meinem Rechner ausführen (und ja, dies ist ein sehr einfaches Beispiel):

Und hier ist die minimale Art und Weise, wie ich es zur Ausführung in AWS Batch senden würde:

Ich erhalte ein Objekt zurück, das meinen Remote-Batch-Auftrag darstellt und das ich abfragen kann, um herauszufinden, was mit meinem Auftrag passiert ist. Zunächst wird mir nur mitgeteilt, dass mein Auftrag „lauffähig“ ist:

Später heißt es dann „gestartet“, dann „ausgeführt“ und schließlich (wenn alles gut geht) „erfolgreich“. Und wenn der Auftrag beendet ist, können Sie das Ergebnis wie folgt abrufen:

Es gibt viele Details, die Sie abrufen können, was tatsächlich passiert ist. Hier zum Beispiel der Anfang des Rohdatenprotokolls:

Der eigentliche Grund für die Remote-Ausführung von Berechnungen in einer Cloud ist jedoch, dass sie potenziell größer und knackiger sein können als die, die Sie auf Ihren eigenen Rechnern ausführen können. Hier sehen Sie, wie wir dieselbe Berechnung wie oben durchführen könnten, aber jetzt die Verwendung eines Grafikprozessors anfordern:
![]()
RemoteBatchSubmit kann auch parallele Berechnungen durchführen. Wenn Sie einen Multicore-Rechner anfordern, können Sie ParallelMap usw. sofort über dessen Kerne laufen lassen. Mit RemoteBatchMapSubmit können Sie sogar noch weiter gehen. Dabei wird Ihre Berechnung automatisch auf eine ganze Sammlung separater Rechner in der Cloud verteilt.
Hier ist ein Beispiel:

Während er läuft, können wir eine dynamische Anzeige des Status jedes Teils des Auftrags erhalten:
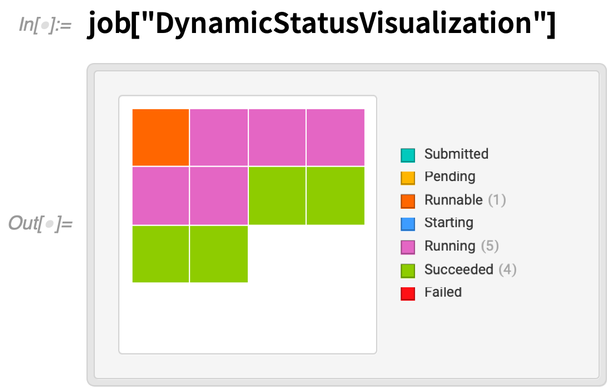
Etwa 5 Minuten später ist die Arbeit beendet:


RemoteBatchSubmit und RemoteBatchMapSubmit bieten Ihnen einen High-Level-Zugang zu Cloud Compute Services für allgemeine Batch-Berechnungen. In Version 12.2 ist aber auch eine direkte Schnittstelle auf niedrigerer Ebene verfügbar, zum Beispiel für AWS.
Verbinden Sie sich mit AWS:

Sobald Sie sich authentifiziert haben, können Sie alle verfügbaren Dienste sehen:

Damit erhalten Sie einen Zugriff auf den Amazon Translate-Dienst:
Damit können Sie nun den Dienst aufrufen:

Natürlich können Sie die Sprachübersetzung auch direkt über die Wolfram Language durchführen:

Können Sie einen 10-dimensionalen Plot erstellen?
Es ist einfach, Daten mit einer, zwei oder drei Dimensionen darzustellen. Für ein paar Dimensionen darüber hinaus können Sie Farben oder andere Gestaltungsmöglichkeiten verwenden. Aber wenn Sie es mit zehn Dimensionen zu tun haben, ist das nicht mehr möglich. Und wenn Sie beispielsweise viele Daten in 10D haben, müssen Sie wahrscheinlich etwas wie DimensionReduce verwenden, um „interessante Merkmale“ herauszufiltern.
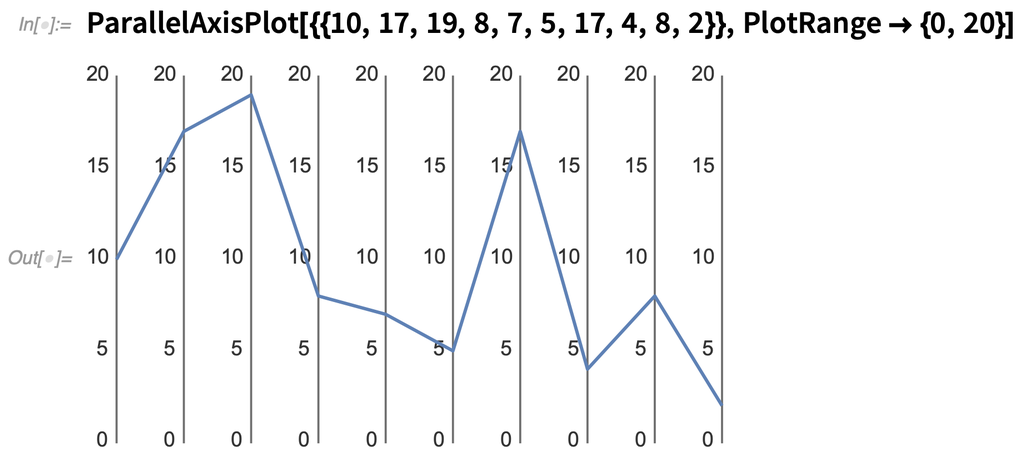
Aber wenn Sie nur mit ein paar „Datenpunkten“ zu tun haben, gibt es andere Möglichkeiten, Dinge wie 10-dimensionale Daten zu visualisieren. Und in Version 12.2 führen wir mehrere Funktionen für diese Zwecke ein.Als erstes Beispiel wollen wir uns ParallelAxisPlot ansehen. Die Idee dabei ist, dass jede „Dimension“ auf einer „separaten Achse“ gezeichnet wird. Für einen einzelnen Punkt ist das nicht so spannend:
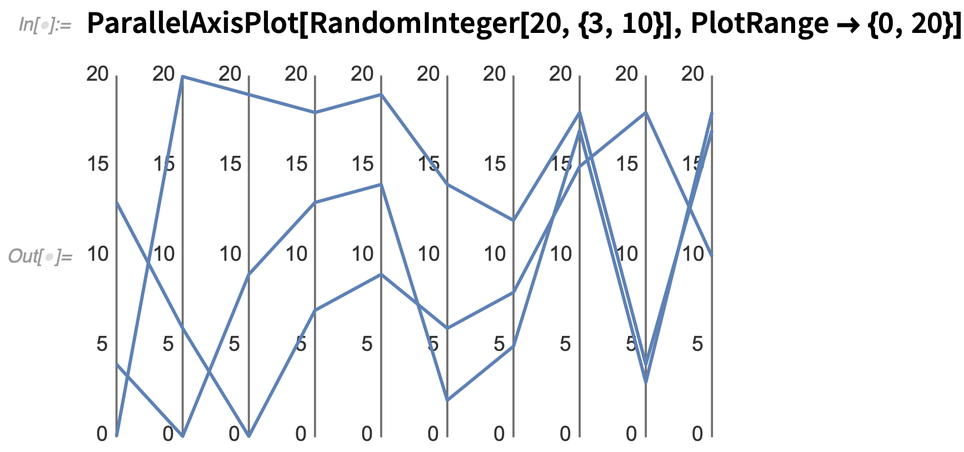
So sieht es aus, wenn wir drei zufällige „10D-Datenpunkte“ aufzeichnen:
Eine der wichtigsten Eigenschaften von ParallelAxisPlot ist jedoch, dass es standardmäßig automatisch die Skala auf jeder Achse bestimmt, so dass die Achsen nicht unbedingt ähnliche Dinge darstellen müssen. Hier sind also zum Beispiel 7 völlig unterschiedliche Größen für alle chemischen Elemente aufgetragen:
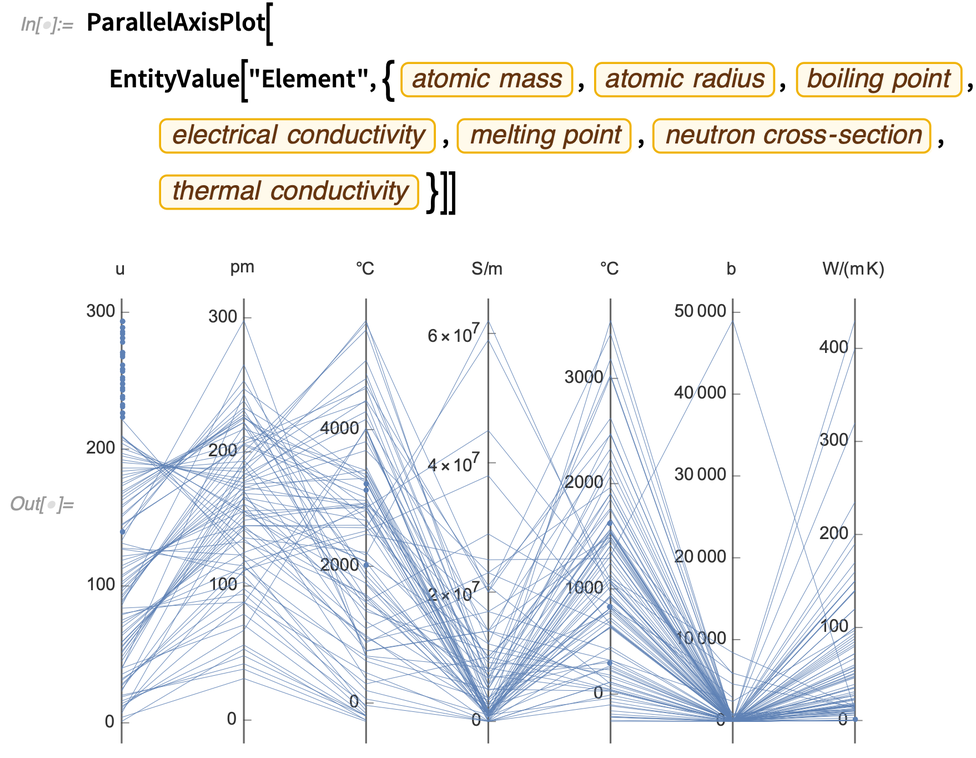
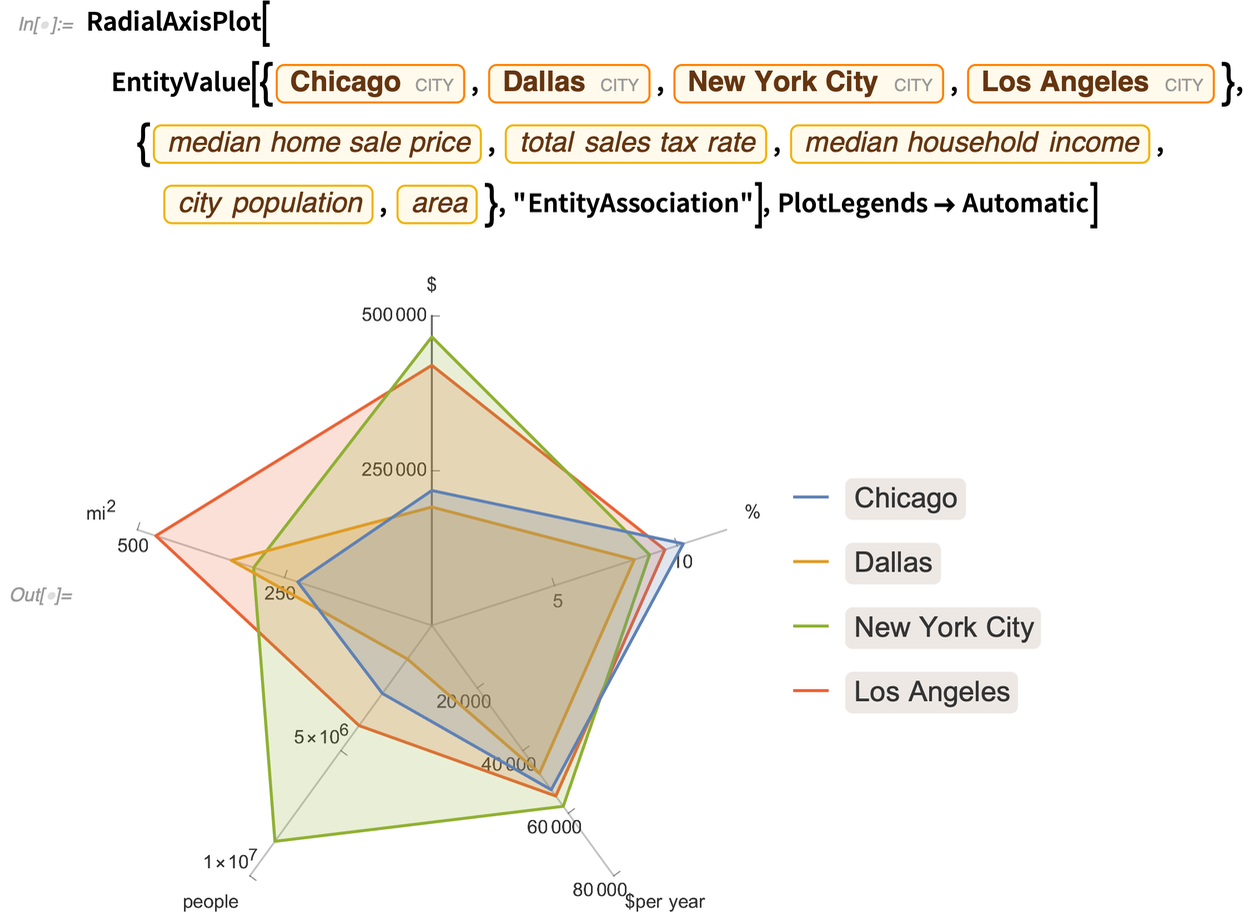
Verschiedene Arten von hochdimensionalen Daten eignen sich am besten für verschiedene Arten von Diagrammen. Eine weitere neue Darstellungsart in Version 12.2 ist RadialAxisPlot. (Diese Darstellungsart wird auch als Radarplot, Spiderplot und Sternplot bezeichnet).
RadialAxisPlot stellt jede Dimension in einer anderen Richtung dar:

Am aufschlussreichsten ist es in der Regel, wenn es nicht zu viele Datenpunkte gibt:
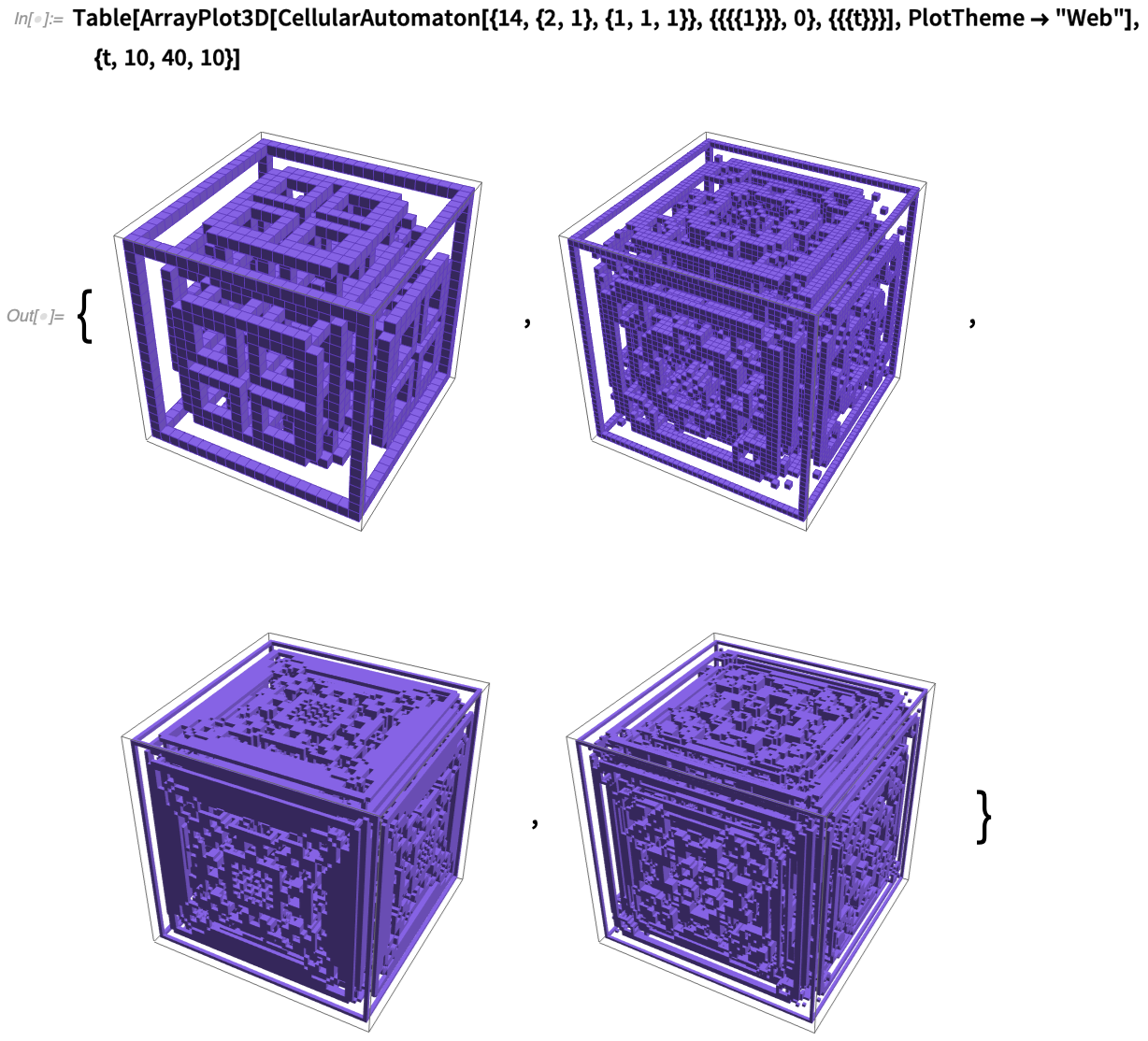
3D-Array-Plots
1984 verwendete ich einen Cray-Supercomputer, um 3D-Bilder von sich zeitlich entwickelnden zellulären 2D-Automaten zu erstellen (ja, auf 35-mm-Dias aufgenommen):

Ich habe 36 Jahre lang darauf gewartet, dass es eine wirklich rationelle Möglichkeit gibt, diese zu reproduzieren. Und jetzt, in Version 12.2, haben wir sie endlich: ArrayPlot3D. Bereits 2012 haben wir Image3D eingeführt, um 3D-Bilder darzustellen und anzuzeigen, die aus 3D-Voxeln mit bestimmten Farben und Opazitäten bestehen. Der Schwerpunkt liegt jedoch auf der Arbeit im „Radiologie-Stil“, bei der eine gewisse Kontinuität zwischen den Voxeln vorausgesetzt wird. Und wenn Sie wirklich eine diskrete Anordnung von diskreten Daten haben (wie bei zellulären Automaten), wird das nicht zu klaren Ergebnissen führen.
Und hier ist ein etwas komplizierterer Fall eines zellulären 3D-Automaten:
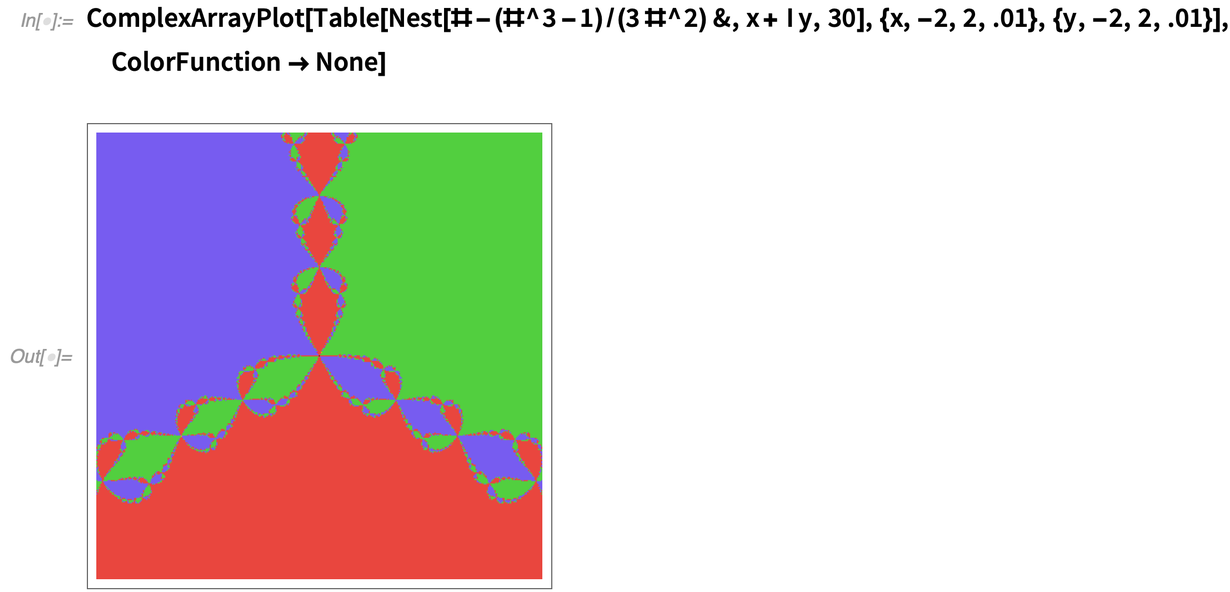
Eine weitere neue Funktion der ArrayPlot-Familie in 12.2 ist ComplexArrayPlot, hier angewandt auf ein Array von Werten aus der Newton-Methode:
Förderung der Computergestützten Ästhetik der Visualisierung
Eines unserer Ziele in der Wolfram Language ist es, Visualisierungen zu haben, die einfach „automatisch gut aussehen“ – weil sie über Algorithmen und Heuristiken verfügen, die eine gute rechnerische Ästhetik effektiv umsetzen. In Version 12.2 haben wir die Berechnungsästhetik für eine Vielzahl von Visualisierungstypen optimiert. In Version 12.1 sah zum Beispiel ein SliceVectorPlot3D standardmäßig so aus:
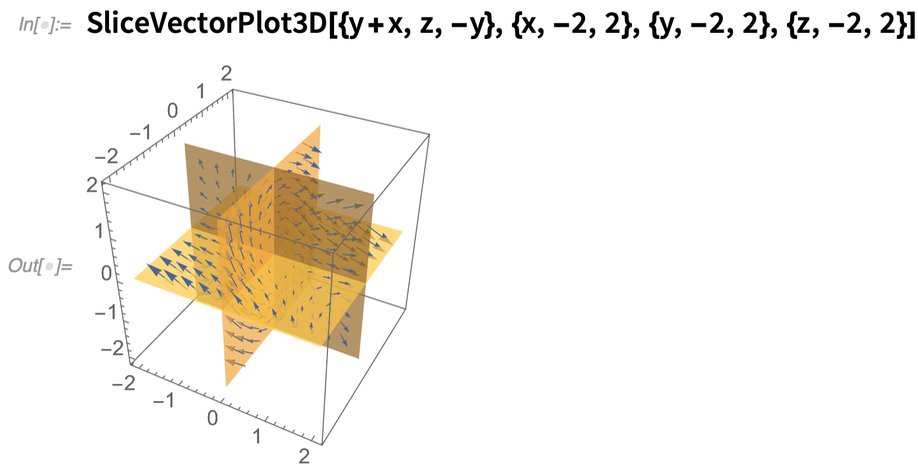
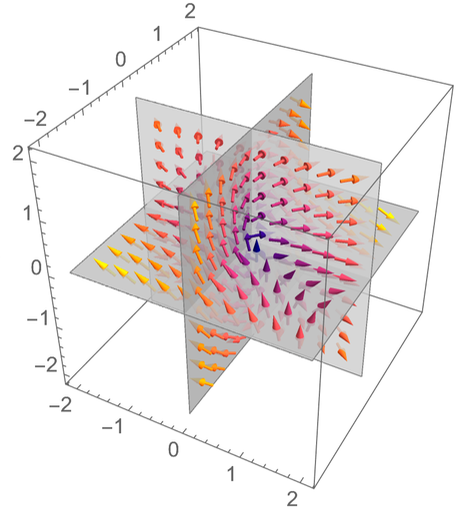
Jetzt sieht es so aus:
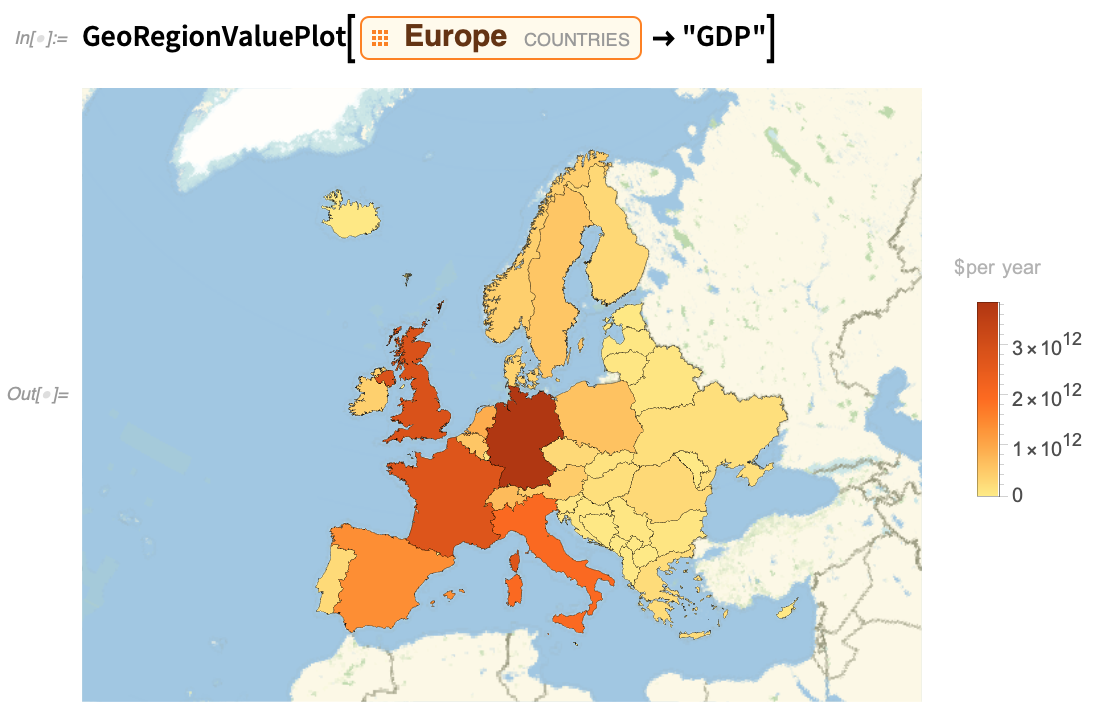
Seit Version 10 machen wir auch zunehmend Gebrauch von unserer PlotTheme-Option, mit der wir detaillierte Optionen „umschalten“ können, um Visualisierungen zu erstellen, die für verschiedene Zwecke geeignet sind und unterschiedliche ästhetische Ziele erfüllen. So haben wir zum Beispiel in Version 12.2 dem GeoRegionValuePlot neue Plot-Themen hinzugefügt. Hier ist ein Beispiel für die Standardeinstellung (die übrigens aktualisiert wurde):
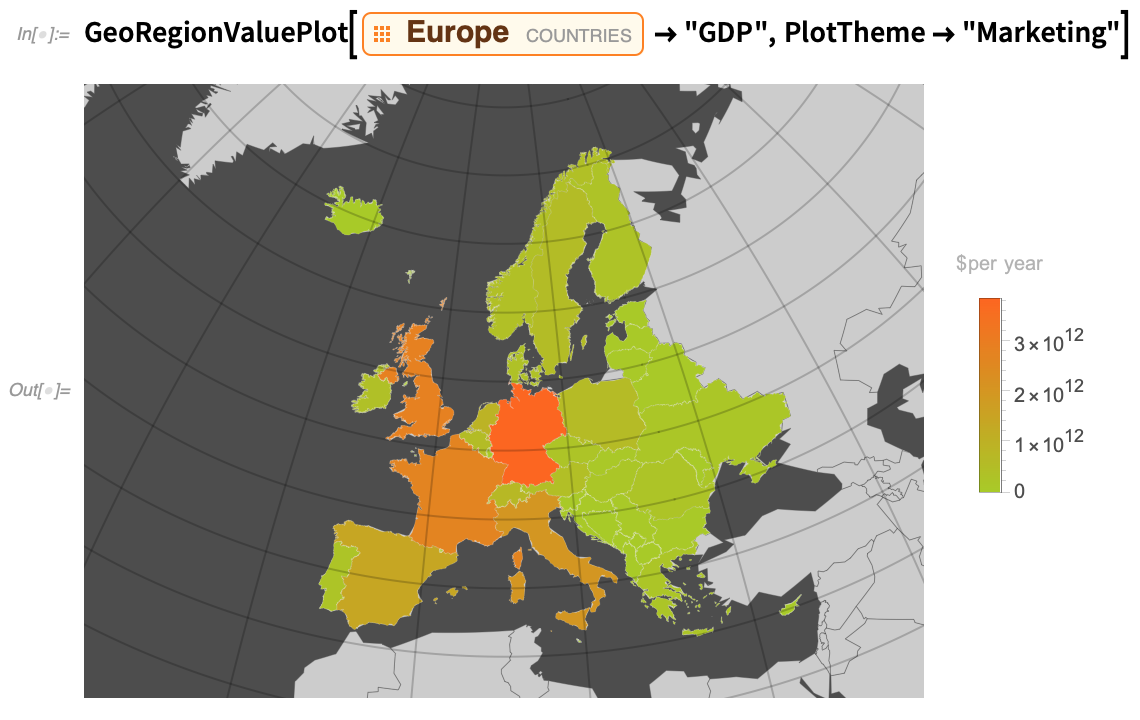
Und hier ist es mit dem Thema „Marketing“:
Eine weitere Neuerung der Version 12.2 ist die Hinzufügung neuer Primitive und neuer „Rohmaterialien“ für die Erstellung ästhetischer visueller Effekte. In Version 12.1 we introduced haben wir Dinge wie HatchFilling für Kreuzschraffuren eingeführt. In Version 12.2 haben wir jetzt auch LinearGradientFilling:

Und wir können diese Art von Effekt nun in die Füllung eines Plots einbauen:

Um noch eleganter zu sein, kann man mit dem neuen ConicGradientFilling zufällige Punkte zeichnen:

Code ein bisschen schöner machen
Ein Hauptziel der Wolfram Language ist es, eine kohärente Computersprache zu definieren, die sowohl von Computern als auch von Menschen leicht verstanden werden kann. Wir (und vor allem ich!) haben viel Mühe in das Design der Sprache gesteckt, zum Beispiel in die Wahl der richtigen Namen für Funktionen. Aber um die Sprache so leicht lesbar wie möglich zu machen, ist es auch wichtig, ihre „nicht-verbalen“ oder syntaktischen Aspekte zu straffen. Bei den Funktionsnamen machen wir uns im Grunde das Verständnis der Menschen für Wörter in der natürlichen Sprache zunutze. Bei der syntaktischen Struktur wollen wir uns das „Umgebungsverständnis“ der Menschen zunutze machen, zum Beispiel aus Bereichen wie der Mathematik.
Vor mehr als einem Jahrzehnt haben wir als Möglichkeit zur Angabe von FunctionFunktionen eingeführt, so dass wir statt
![]()
(oder #2&) könnten Sie schreiben:
![]()
Aber um einzugeben, musste man \[Function] oder zumindest fn eingeben, was sich „ein bisschen schwierig“ anfühlte.
Nun, in der Version 12.2 werden wir „Mainstreaming“ betreiben, indem wir es möglich machen, genauso zu tippen wie |->
![]()
sowie auch Dinge wie:
![]()
In Version 12.2 gibt es außerdem eine weitere neue „Kurzsyntax“: //=Stellen Sie sich vor, Sie haben ein Ergebnis, sagen wir res, erhalten. Nun wollen Sie eine Funktion auf res anwenden und dann „res aktualisieren“. Mit der neuen Funktion ApplyTo (geschrieben //=) ist das leicht möglich:
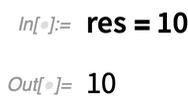
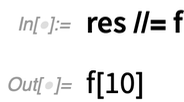

Wir sind immer auf der Suche nach sich wiederholenden „Berechnungsklumpen“, die wir in Funktionen mit „leicht verständlichen Namen“ „verpacken“ können. Und in Version 12.2 haben wir ein paar neue solcher Funktionen: FoldWhile und FoldWhileList. FoldList nimmt normalerweise einfach eine Liste und „faltet“ jedes nachfolgende Element in das Ergebnis, das es aufbaut – bis es zum Ende der Liste kommt:
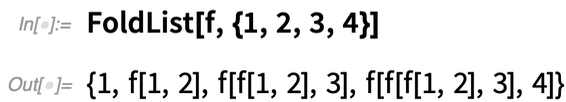
Aber was ist, wenn Sie „früher aufhören“ wollen? Mit FoldWhileList können Sie das tun. Hier dividieren wir also nacheinander durch 1, 2, 3, … und hören auf, wenn das Ergebnis keine ganze Zahl mehr ist:
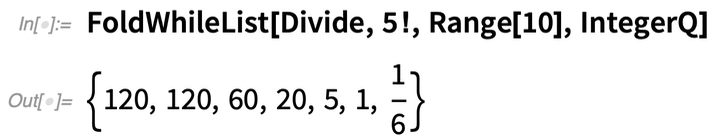
Mehr Array-Gymnastik: Säulenoperationen und ihre Verallgemeinerungen
Nehmen wir an, Sie haben ein Array, etwa:
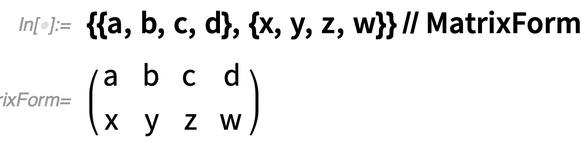
Mit Map können Sie eine Funktion auf die „Zeilen“ dieses Arrays abbilden:
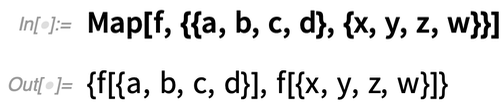
Was aber, wenn Sie auf den „Spalten“ des Arrays operieren wollen, also die erste Dimension des Arrays effektiv „verkleinern“ wollen? In Version 12.2 können Sie dies mit der Funktion ArrayReduce tun:
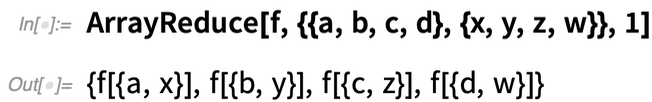
Hier sehen Sie, was passiert, wenn wir ArrayReduce stattdessen anweisen, die zweite Dimension des Arrays zu „reduzieren“:
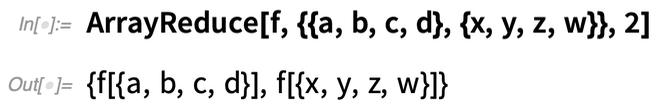
Was ist hier wirklich los? Das Feld hat die Abmessungen 2×4:
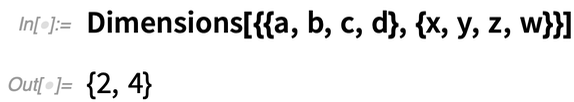
ArrayReduce[f, ..., 1] „reduziert“ die erste Dimension und hinterlässt ein Array mit den Dimensionen {4}.
ArrayReduce[f, ..., 2] reduziert die zweite Dimension und hinterlässt ein Array mit den Dimensionen {2}.
Betrachten wir einen etwas größeren Fall – ein 2×3×4-Array:

Damit entfällt die „erste Dimension“ und es verbleibt ein 3×4-Array:


Auf diese Weise wird die „zweite Dimension“ eliminiert, so dass ein 2×4-Array übrig bleibt:


Warum ist dies nützlich? Ein Beispiel ist, wenn Sie Datenreihen haben, bei denen verschiedene Dimensionen verschiedenen Attributen entsprechen, und Sie dann ein bestimmtes Attribut „ignorieren“ und die Daten in Bezug auf dieses Attribut aggregieren möchten. Nehmen wir an, das Attribut, das Sie ignorieren wollen, befindet sich auf Ebene n in Ihrer Matrix. Dann ist alles, was Sie tun müssen, um es zu „ignorieren“, die Verwendung von ArrayReduce[f, ..., n], wobei f die Funktion ist, die die Werte aggregiert (oft etwas wie Total oder Mean).
Sie können die gleichen Ergebnisse wie mit ArrayReduce durch geeignete Sequenzen von Transpose, Apply usw. erzielen. Aber das ist ziemlich chaotisch, und ArrayReduce bietet eine elegante „Verpackung“ dieser Arten von Array-Operationen.
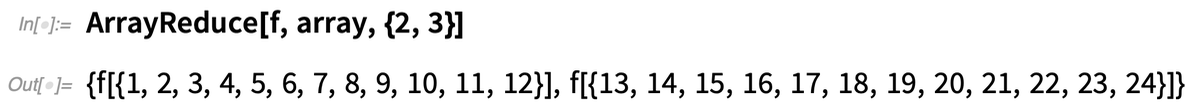
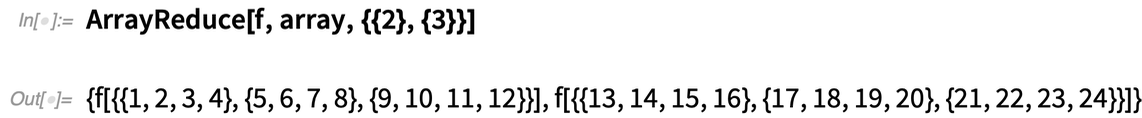
Auf der einfachsten Ebene ist ArrayReduce ein bequemer Weg, um Funktionen „spaltenweise“ auf Arrays anzuwenden. Aber in voller Allgemeinheit ist es ein Weg, um Funktionen auf Subarrays mit beliebigen Indizes anzuwenden. Und wenn Sie an Tensoren denken, ist ArrayReduce eine Verallgemeinerung der Kontraktion, bei der mehr als zwei Indizes beteiligt sein können und Elemente „geglättet“ werden können, bevor die Operation (die nicht unbedingt eine Summierung sein muss) angewendet wird.
Beobachten Sie die Ausführung Ihres Codes: Mehr aus der Echo-Familie
Es ist ein altes Sprichwort beim Debuggen von Code: „Füge eine Druckanweisung ein“. Aber in der Wolfram Language ist es noch eleganter, vor allem dank Echo. Es ist eine einfache Idee: Echo[expr] „echot“ (d.h. druckt) den Wert von expr, gibt diesen Wert dann aber zurück. Das Ergebnis ist, dass Sie Echo an beliebiger Stelle in Ihren Code einfügen können (oft als Echo@…), ohne dass dies Auswirkungen auf die Funktion Ihres Codes hat.
In Version 12.2 there are some new functions that follow the “Echo” pattern. A first example is EchoLabel, which just adds a label to what’s echoed:

Kenner fragen sich vielleicht, warum EchoLabel benötigt wird. Schließlich erlaubt Echo selbst ein zweites Argument, das eine Bezeichnung angeben kann. Die Antwort – und ja, es ist ein wenig subtiler Teil des Sprachdesigns – ist, dass, wenn man Echo einfach als eine Funktion einfügt, die man anwenden will (z. B. mit say with @), dann kann sie nur ein Argument haben, also kein Label. EchoLabel ist so eingerichtet, dass es die Operatorform EchoLabel[label] hat, so dass EchoLabel[label][expr] gleichbedeutend mit Echo[expr,label] ist.
Eine weitere neue „Echo-Funktion“ in 12.2 ist EchoTiming, die das Timing (in Sekunden) dessen anzeigt, was sie auswertet:

Es ist oft hilfreich, sowohl Echo als auch EchoTiming zu verwenden:

Übrigens, wenn Sie die Auswertungszeit immer ausdrucken wollen (so wie es Mathematica 1.0 vor 32 Jahren standardmäßig getan hat), können Sie $Pre=EchoTiming immer global setzen.
Eine weitere neue „Echo-Funktion“ in 12.2 ist EchoEvaluation, die das „Vorher“ und das „Nachher“ einer Auswertung als Echo ausgibt:

Sie fragen sich vielleicht, was mit verschachtelten EchoEvaluation’s passiert. Hier ist ein Beispiel:

Übrigens ist es durchaus üblich, dass man sowohl EchoTiming als auch EchoEvaluation verwenden möchte:

Wenn Sie Echo-Funktionen in Ihrem Code belassen wollen, aber möchten, dass Ihr Code „leise“ läuft, können Sie das neue QuietEcho verwenden, um alle Echos „leise“ zu machen (wie Quiet Nachrichten „leise“ macht):

Code ein bisschen schöner machen
Ist in Ihrem Programm etwas schief gelaufen? Und wenn ja, was sollte das Programm tun? Es kann möglich sein, sehr eleganten Code zu schreiben, wenn man solche Dinge ignoriert. Aber sobald man anfängt, Überprüfungen einzubauen und eine Logik für die Rückabwicklung zu haben, wenn etwas schief geht, wird der Code oft sehr viel komplizierter und weniger lesbar.
Was kann man dagegen tun? Nun, in Version 12.2 haben wir einen symbolischen High-Level-Mechanismus entwickelt, um Dinge zu behandeln, die im Code schief gehen. Die Grundidee ist, dass Sie Confirm (oder verwandte Funktionen) einfügen – ähnlich wie Sie Echo einfügen könnten – um zu „bestätigen“, dass etwas in Ihrem Programm das tut, was es tun soll. Wenn die Bestätigung funktioniert, läuft Ihr Programm einfach weiter. Schlägt sie jedoch fehl, wird das Programm angehalten und zum nächstgelegenen Enclose verzweigt. In gewissem Sinne „umschließt“ Enclose Bereiche Ihres Programms und verhindert, dass etwas, das innerhalb des Programms schief läuft, sofort nach außen dringt.
Schauen wir uns an, wie dies in einem einfachen Fall funktioniert. Hier „bestätigt“ Confirm erfolgreich y, indem es es einfach zurückgibt, und Enclose tut nicht wirklich etwas:
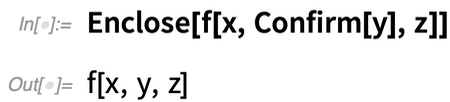
Aber jetzt setzen wir $Failed anstelle von y ein. $Failed ist etwas, das Confirm standardmäßig als Problem betrachtet. Wenn es also $Failed sieht, hält es an und geht zum Enclose, das wiederum ein Failure-Objekt liefert:
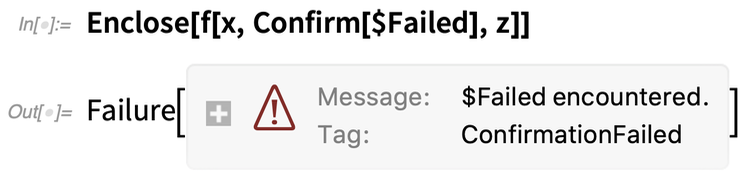
Wenn wir einige Echos einfügen, werden wir sehen, dass x erfolgreich erreicht wird, aber z nicht; sobald die Confirm fehlschlägt, hält sie alles an:
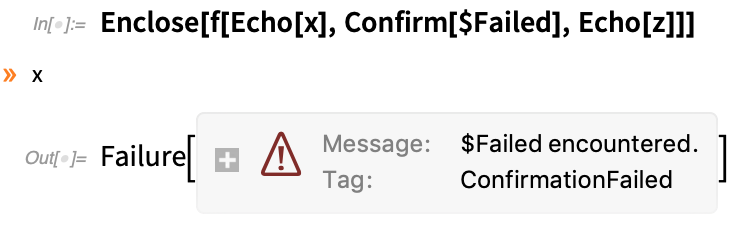
Es kommt sehr häufig vor, dass man bei der Definition einer Funktion Confirm/Enclose verwenden möchte:
![]()
Verwenden Sie Argument 5, und alles funktioniert einfach:
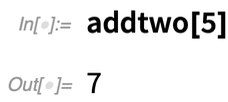
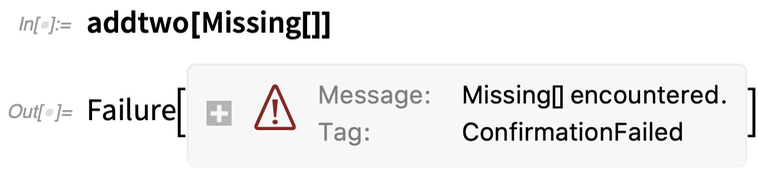
Wenn wir jedoch stattdessen Missing[]verwenden – was Confirm standardmäßig als Problem betrachtet – erhalten wir ein Failure-Objekt zurück:
Wir könnten dasselbe mit If, Return, etc. erreichen. Aber selbst in diesem sehr einfachen Fall würde es nicht so schön aussehen.
Confirm hat einen bestimmten Standardsatz von Dingen, die es als „falsch“ betrachtet ($Failed, Failure[...], Missing[...]. Es gibt jedoch verwandte Funktionen, mit denen Sie bestimmte Tests festlegen können. ConfirmBy wendet zum Beispiel eine Funktion an, die prüft, ob ein Ausdruck bestätigt werden sollte.
Hier bestätigt ConfirmBy, dass 2 eine Zahl ist:

Aber x wird von NumberQ nicht als solches betrachtet:

OK, fügen wir also diese Teile zusammen. Definieren wir eine Funktion, die mit Zeichenketten arbeiten soll:
![]()
Wenn wir ihm eine Schnur geben, ist alles gut:

Wenn wir aber stattdessen eine Zahl angeben, schlägt die ConfirmBy fehl:
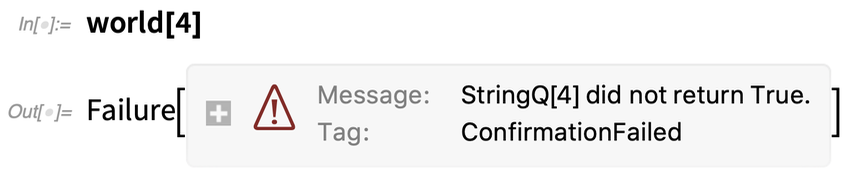
Aber hier fangen die wirklich schönen Dinge an zu passieren. Nehmen wir an, wir wollen die Welt über eine Liste abbilden und dabei immer wieder überprüfen, ob sie ein gutes Ergebnis liefert. Hier ist alles in Ordnung:

Aber jetzt ist etwas schief gelaufen:
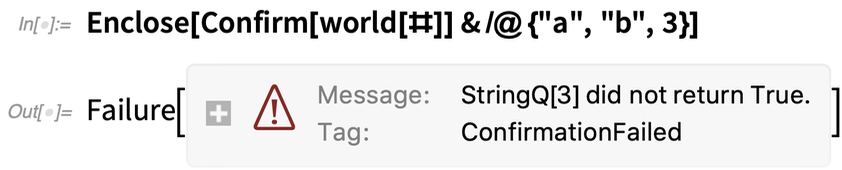
Das ConfirmBy in der Definition von world ist fehlgeschlagen, wodurch das umgebende Enclose ein Failure-Objekt erzeugt hat. Dieses Failure-Objekt führte dann dazu, dass das Confirm innerhalb der Map fehlschlug, und das umgebende Enclose erzeugte ein Failure-Objekt für die ganze Sache. Noch einmal: Wir hätten das Gleiche mit If, Throw, Catch usw. erreichen können. Aber Confirm/Enclose machen es robuster und eleganter.
Das sind alles sehr kleine Beispiele. Aber wo Confirm/Enclose wirklich ihren Wert zeigen, ist in großen Programmen, und bei der Bereitstellung eines klaren, High-Level-Rahmens für die Behandlung von Fehlern und Ausnahmen, und deren Umfang zu definieren.
Zusätzlich zu Confirm und ConfirmBy gibt es auch ConfirmMatch, das bestätigt, dass ein Ausdruck mit einem bestimmten Muster übereinstimmt. Dann gibt es noch ConfirmQuiet, das bestätigt, dass die Auswertung eines Ausdrucks keine Meldungen erzeugt (oder zumindest keine, auf die Sie den Test angesetzt haben). Es gibt auch ConfirmAssert, das einfach eine „Behauptung“ (wiep>0) nimmt und bestätigt, dass sie wahr ist.
Wenn eine Bestätigung fehlschlägt, geht das Programm immer zum nächstgelegenen Enclose und übergibt dem Enclose-Objekt ein Failure-Objekt mit Informationen über den aufgetretenen Fehler. Wenn Sie das Enclose einrichten, können Sie ihm mitteilen, wie es mit den empfangenen Failure-Objekten umgehen soll – entweder indem es sie einfach zurückgibt (vielleicht an die umschließenden Confirm’s und Enclose’s) oder indem es Funktionen auf ihren Inhalt anwendet.
Confirm und Enclose sind ein eleganter Mechanismus für die Behandlung von Fehlern, der sich einfach und sauber in Programme einfügen lässt. Aber es gibt natürlich auch ein paar knifflige Probleme mit ihnen. Lassen Sie mich nur eines davon erwähnen. Die Frage ist: Welche Confirm’s schließt ein bestimmtes Enclose wirklich ein? Wenn Sie ein Stück Code geschrieben haben, das ausdrücklich Enclose und Confirm enthält, ist das ziemlich offensichtlich. Aber was ist, wenn es eine Confirm gibt, die irgendwie – vielleicht dynamisch – tief in einem Stapel von Funktionen erzeugt wird? Die Situation ist ähnlich wie bei benannten Variablen. Das Module sucht einfach direkt („lexikalisch“) nach den Variablen innerhalb seines Körpers. Block sucht nach Variablen („dynamisch“), wo immer sie vorkommen können. Nun, Enclose arbeitet standardmäßig wie Module, indem es „lexikalisch“ nach Confirm’s sucht, die eingeschlossen werden sollen. Wenn Sie jedoch Tags in Confirm und Enclose einfügen, können Sie sie so einrichten, dass sie sich gegenseitig „finden“, auch wenn sie nicht explizit im selben Code-Stück „sichtbar“ sind.
Funktion Robustheit
Confirm/Enclose bieten eine gute Möglichkeit, den „Fluss“ von Dingen, die innerhalb eines Programms oder einer Funktion schief laufen, zu behandeln. Aber was ist, wenn gleich zu Beginn etwas schief läuft? In unseren eingebauten Wolfram Language-Funktionen gibt es eine Reihe von Standardprüfungen, die wir durchführen. Gibt es die richtige Anzahl von Argumenten? Wenn es Optionen gibt, sind diese erlaubt und befinden sie sich an der richtigen Stelle? In Version 12.2 haben wir zwei Funktionen hinzugefügt, die diese Standardprüfungen für von Ihnen geschriebene Funktionen durchführen können.
Dies besagt, dass f zwei Argumente haben sollte, was hier nicht der Fall ist:
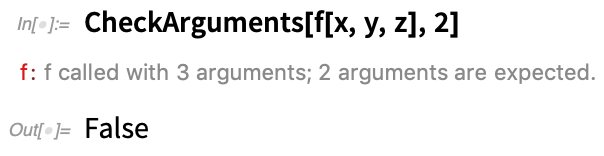
Hier ist eine Möglichkeit, CheckArguments zu einem Teil der grundlegenden Definition einer Funktion zu machen:
![]()
Geben Sie ihr die falsche Anzahl von Argumenten, und sie erzeugt eine Meldung und kehrt dann unausgewertet zurück, genau wie viele eingebaute Wolfram Language-Funktionen es tun:

ArgumentsOptions ist eine weitere neue Funktion in Version 12.2, die „Positionsargumente“ von Optionen in einer Funktion trennt. Legen Sie Optionen für eine Funktion fest:
![]()
Dieser erwartet ein Positionsargument, das er findet:

Wenn es nicht genau ein Positionsargument findet, wird eine Meldung ausgegeben:

Aufräumen nach Ihrem Code
Sie führen ein Stück Code aus und es tut, was es tut – und normalerweise wollen Sie nicht, dass es etwas zurücklässt. Oft können Sie dafür Scoping-Konstrukte wie Module, Block, BlockRandom usw. verwenden. Aber manchmal gibt es etwas, das Sie eingerichtet haben und das explizit „aufgeräumt“ werden muss, wenn Ihr Code fertig ist.
Sie könnten zum Beispiel eine Datei in Ihrem Code erstellen und möchten, dass die Datei entfernt wird, wenn der Code fertig ist. In Version 12.2 gibt es eine praktische neue Funktion, um solche Dinge zu verwalten: WithCleanup.
WithCleanup[expr, cleanup] aus, dann expr, gibt aber das cleanup, gibt aber das Ergebnis von expr zurück. Hier ist ein triviales Beispiel (das mit Block wirklich besser erreicht werden könnte). Sie weisen x einen Wert zu, erhalten dessen Quadrat und löschen x, bevor Sie das Quadrat zurückgeben:
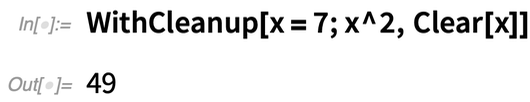
Es ist schon praktisch, ein Konstrukt zu haben, das die Bereinigung vornimmt und gleichzeitig den Hauptausdruck zurückgibt, den Sie ausgewertet haben. Ein wichtiges Detail von WithCleanup ist jedoch, dass es auch die Situation behandelt, in der Sie die Hauptauswertung, die Sie durchführen, abbrechen. Normalerweise würde ein Abbruch alles zum Stillstand bringen. WithCleanup ist jedoch so eingerichtet, dass die Bereinigung auch bei einem Abbruch durchgeführt wird. Wenn die Bereinigung also z. B. das Löschen einer Datei beinhaltet, wird die Datei gelöscht, auch wenn die Hauptoperation abgebrochen wird.
Übrigens, WithCleanup kann auch eine Initialisierung angegeben werden. Hier wird also die Initialisierung durchgeführt, ebenso die Bereinigung, aber die Hauptauswertung wird abgebrochen:
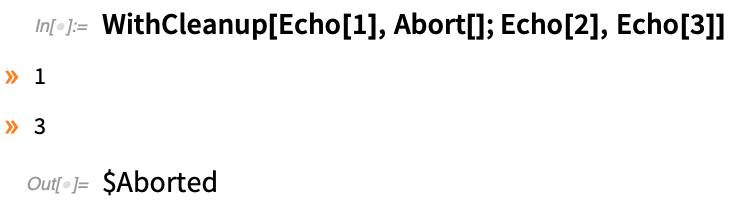
WithCleanup kann übrigens auch in Verbindung mit Confirm/Enclose verwendet werden, um sicherzustellen, dass auch bei einer fehlgeschlagenen Bestätigung bestimmte Aufräumarbeiten durchgeführt werden.
Termine – mit 37 neuen Kalendern
Heute ist der 16. Dezember 2020 – zumindest nach dem Gregorianischen Kalender, der in den USA üblicherweise verwendet wird. Aber es gibt noch viele andere Kalendersysteme, die weltweit für verschiedene Zwecke verwendet werden, und noch mehr, die in der Geschichte schon einmal verwendet wurden.
In früheren Versionen der Wolfram Language haben wir einige wenige gängige Kalendersysteme unterstützt. Aber in Version 12.2 haben wir eine sehr breite Unterstützung für Kalendersysteme hinzugefügt – insgesamt 41 davon. Man kann sich die Kalendersysteme ein bisschen wie Projektionen in der Geodäsie oder Koordinatensysteme in der Geometrie vorstellen. Sie haben eine bestimmte Zeit: Jetzt müssen Sie wissen, wie sie in dem von Ihnen verwendeten System dargestellt wird. Und ähnlich wie bei GeoProjectionData gibt es jetzt CalendarData, das Ihnen eine Liste der verfügbaren Kalendersysteme liefern kann:

Hier ist also die Darstellung von „jetzt“, umgerechnet in verschiedene Kalender:
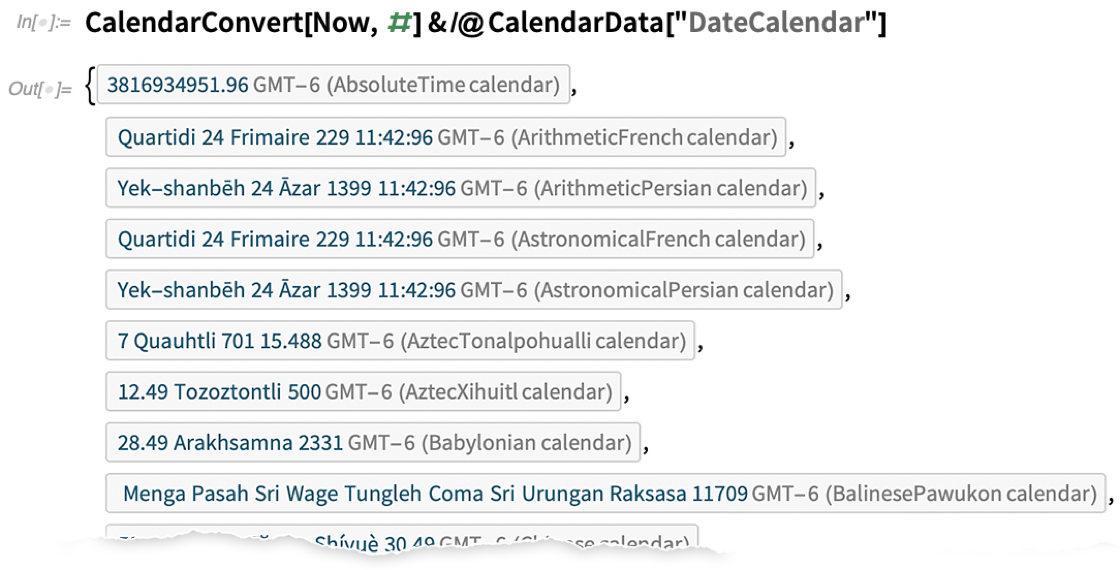
Hier gibt es viele Feinheiten. Einige Kalender sind rein „arithmetisch“, andere beruhen auf astronomischen Berechnungen. Und dann ist da noch die Sache mit den „Schaltvarianten“. Beim gregorianischen Kalender sind wir es gewohnt, einfach einen 29. Februar hinzuzufügen. Aber der Chinese calendarr zum Beispiel kann ganze „Schaltmonate“ innerhalb eines Jahres hinzufügen (so dass es zum Beispiel zwei „vierte Monate“ geben kann). In der Wolfram Language haben wir jetzt eine symbolische Darstellung für solche Dinge, die LeapVariant:

Ein Grund, sich mit verschiedenen Kalendersystemen zu beschäftigen, ist, dass sie in verschiedenen Kulturen zur Festlegung von Feiertagen und Festen verwendet werden. (Ein weiterer Grund, der für jemanden wie mich, der viel Geschichte studiert, besonders wichtig ist, liegt in der Umkehrung historischer Daten: Newtons Geburtstag wurde ursprünglich auf den 25. Dezember 1642 festgelegt, aber wenn man ihn in ein gregorianisches Datum umrechnet, ist es der 4. Januar 1643.)
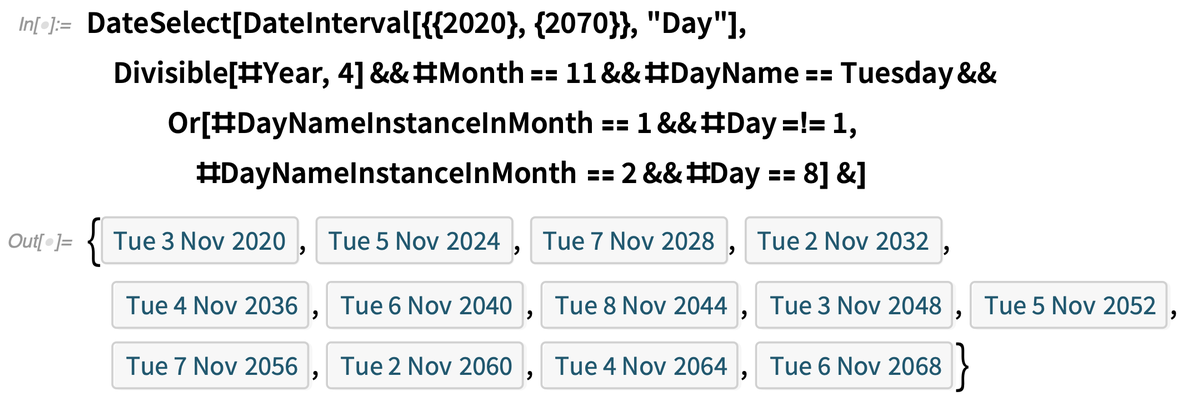
In einem Kalender möchte man oft Termine auswählen, die ein bestimmtes Kriterium erfüllen. Und in Version 12.2 haben wir dafür die Funktion DateSelect eingeführt. So können wir zum Beispiel Termine innerhalb eines bestimmten Intervalls auswählen, die das Kriterium erfüllen, dass sie Mittwoche sind:

Als komplizierteres Beispiel können wir den derzeitigen Algorithmus für die Auswahl der Daten der US-Präsidentschaftswahlen in eine berechenbare Form umwandeln und ihn dann verwenden, um die Daten für die nächsten 50 Jahre zu bestimmen:
Neu in Geo
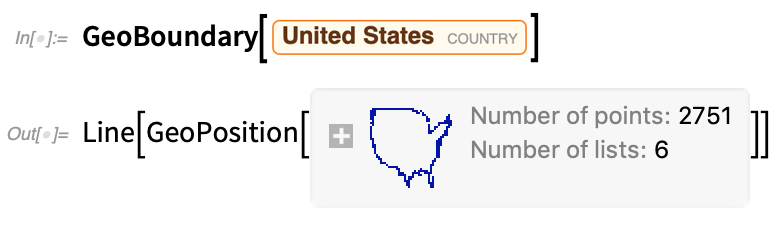
Mittlerweile verfügt die Wolfram Language über starke Fähigkeiten in den Bereichen Geoberechnungen und Geovisualisierung. Aber wir bauen unsere Geofunktionalität weiter aus. Eine wichtige Ergänzung in Version 12.2 ist die räumliche Statistik (siehe oben), die vollständig in die Geo-Funktionalität integriert ist. Aber es gibt auch eine Reihe neuer Geo-Primitive. Eines davon istGeoBoundary, das die Grenzen von Dingen berechnet:

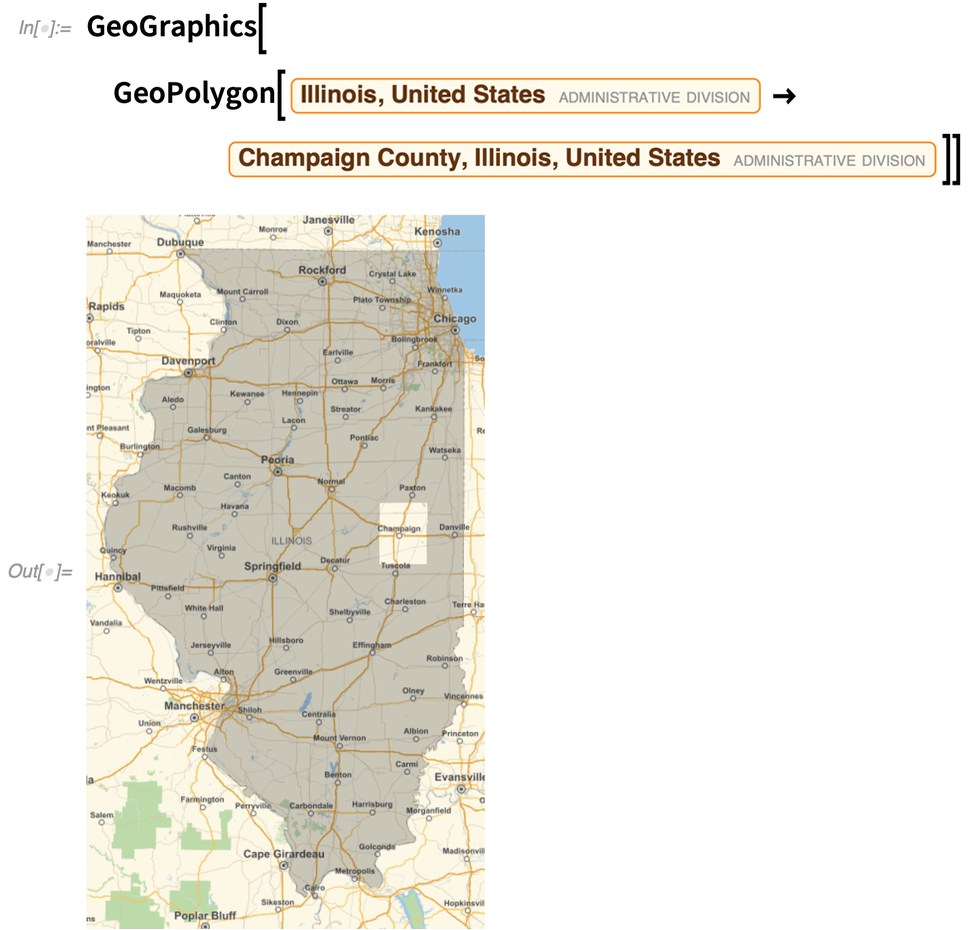
Es gibt auch GeoPolygon, das eine vollständige Geo-Verallgemeinerung von gewöhnlichen Polygonen ist. Eine der kniffligen Fragen, mit denen GeoPolygon umgehen muss, ist die Frage, was als das „Innere“ eines Polygons auf der Erde gilt. Hier wird der größere Bereich gewählt (d.h. der Bereich, der sich um den Globus herum erstreckt):
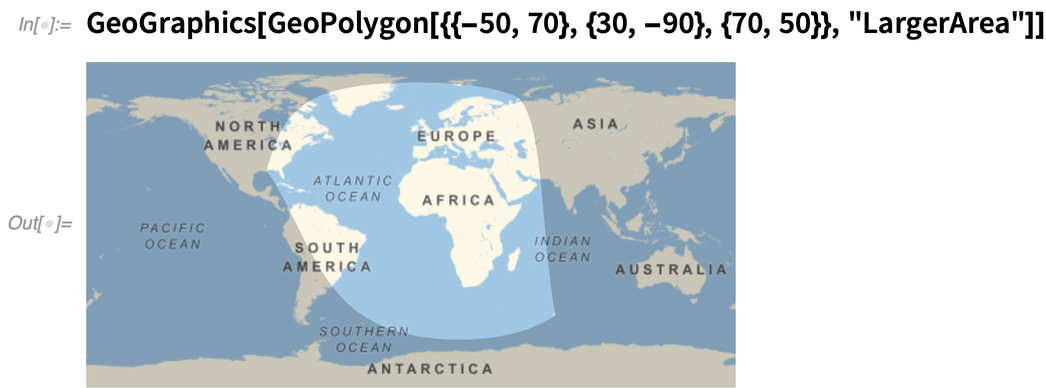
GeoPolygon kann auch – wie Polygon – Löcher oder sogar beliebige Verschachtelungsebenen verarbeiten:
Aber die größte „kommende Attraktion“ von Geo ist das völlig neue Rendering von Geografiegrafiken und Karten. Es ist noch vorläufig (und unvollendet) in Version 12.2, aber es gibt zumindest experimentelle Unterstützung für vektorbasiertes Kartenrendering. Der offensichtlichste Vorteil ist, dass die Karten in allen Maßstäben viel klarer und schärfer aussehen. Ein weiterer Vorteil ist die Möglichkeit, neue Stile für Karten einzuführen, und in Version 12.2 sind acht neue Kartenstile enthalten.
Hier ist unsere „altmodische“ Karte:
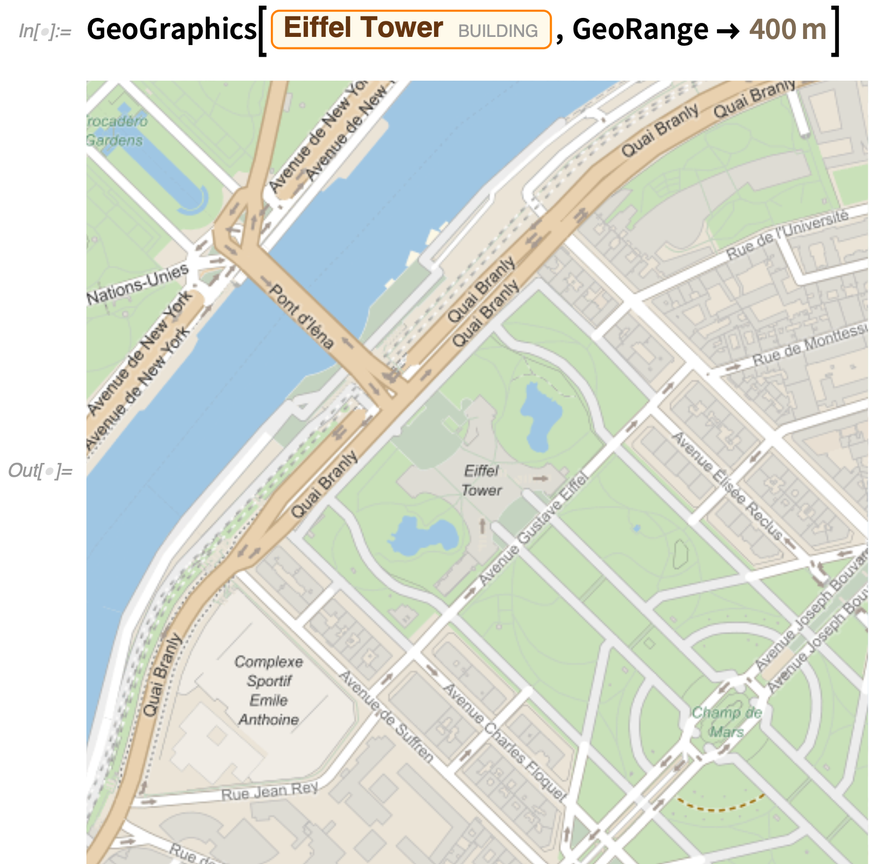
Hier ist die neue Vektorversion dieses „klassischen“ Stils:
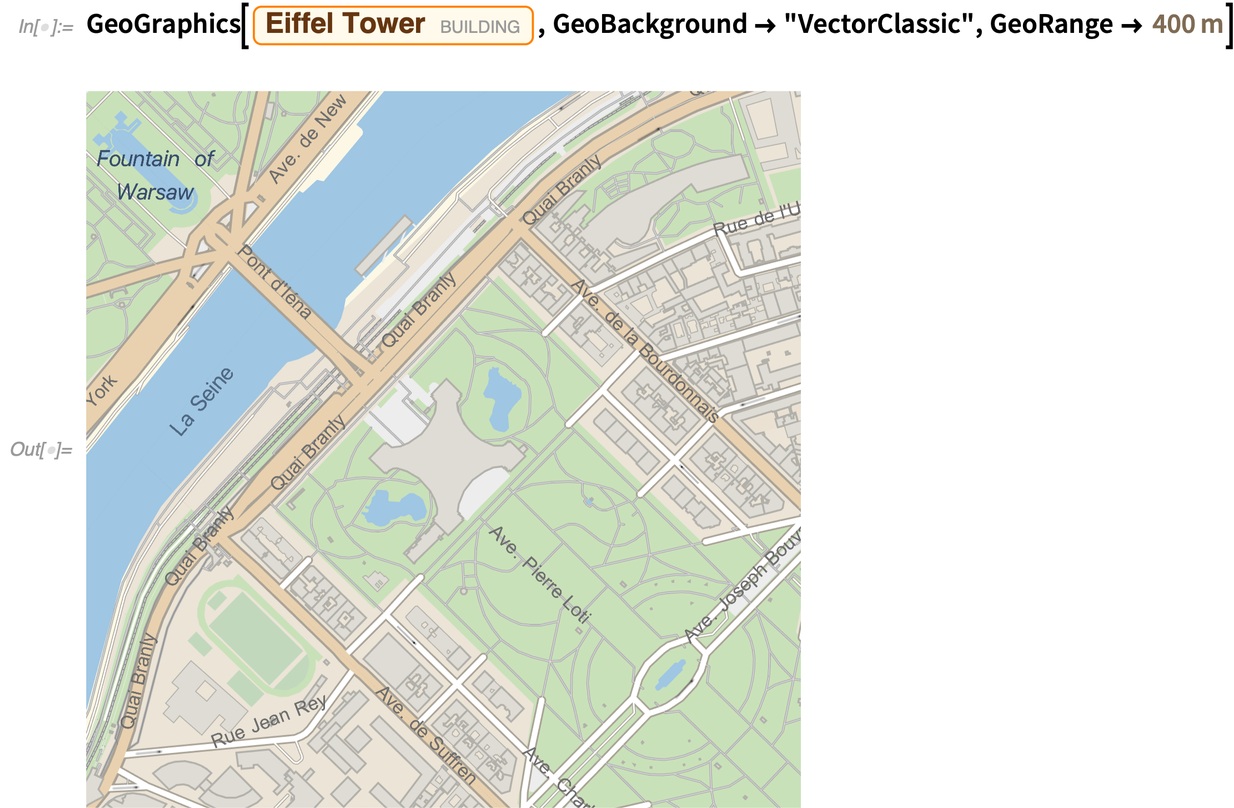
Hier ist ein neuer (Vektor-)Stil, der für das Web gedacht ist:

Und hier ist ein „dunkler“ Stil, der sich für die Überlagerung von Informationen eignet:
PDF importieren
Sie möchten ein Dokument im PDF-Format analysieren? Seit über einem Jahrzehnt können wir grundlegende Inhalte aus PDF-Dateien extrahieren. Aber PDF ist ein sehr komplexes (und sich weiterentwickelndes) Format, und viele Dokumente „in freier Wildbahn“ haben eine komplizierte Struktur. In Version 12.2 haben wir jedoch unsere PDF-Importfunktionen drastisch erweitert, so dass es realistisch ist, z. B. ein beliebiges Papier von arXiv zu importieren:

Standardmäßig erhalten Sie ein hochauflösendes Bild für jede Seite (in diesem speziellen Fall für alle 100 Seiten).
Wenn Sie den Text wünschen, können Sie ihn mit „Klartext“ importieren:

Jetzt können Sie sofort eine Wortwolke aus den Wörtern im Papier erstellen:

Dabei werden alle Bilder aus dem Papier herausgesucht und zu einer Collage zusammengefügt:

Sie können die URLs von jeder Seite abrufen:
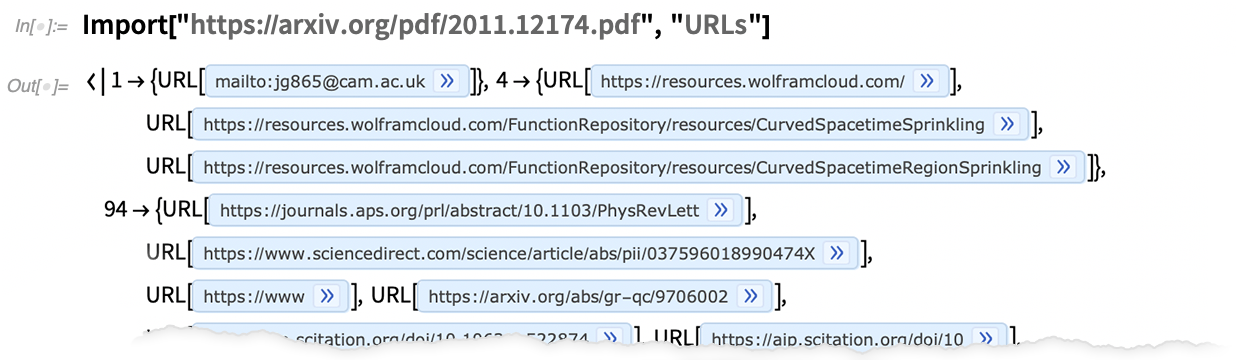
Wählen Sie nun die letzten beiden aus und holen Sie sich Bilder von diesen Webseiten:

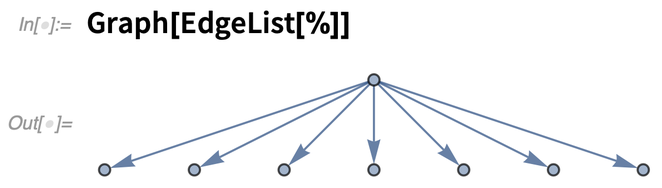
Je nachdem, wie sie erstellt wurden, können PDFs alle möglichen Strukturen aufweisen. „ContentsGraph“ liefert einen Graphen, der die für ein Dokument erkannte Gesamtstruktur darstellt:

Und ja, es ist wirklich ein Diagramm:
Für PDFs, die ausfüllbare Formulare sind, gibt es mehr Struktur zu importieren. Hier habe ich ein zufälliges, nicht ausgefülltes Regierungsformular aus dem Internet genommen. Der Import ergibt eine Assoziation, deren Schlüssel die Namen der Felder sind. Wäre das Formular ausgefüllt worden, hätte es auch deren Werte enthalten, so dass Sie sofort eine Analyse durchführen könnten:

Das Neueste auf dem Gebiet der konvexen Optimierung für den industriellen Einsatz
Ab Version 12.0 haben wir modernste Funktionen zur Lösung großer Optimierungsprobleme hinzugefügt. In Version 12.2 haben wir diese Fähigkeiten weiter vervollständigt.Neu ist die Superfunktion ConvexOptimization, die automatisch das gesamte Spektrum der linearen, linear-fraktionalen, quadratischen, semidefiniten und konischen Optimierung abdeckt und sowohl optimale Lösungen als auch deren duale Eigenschaften liefert. In 12.1 haben wir Unterstützung für ganzzahlige Variablen (d.h. kombinatorische Optimierung) hinzugefügt; in 12.2 werden wir auch Unterstützung für komplexe Variablen hinzufügen.
Die größte Neuerung bei der Optimierung in 12.2 ist jedoch die Einführung der robusten Optimierung und der parametrischen Optimierung. Mit der robusten Optimierung können Sie ein Optimum finden, das für einen ganzen Bereich von Werten einiger Variablen gilt. Mit der parametrischen Optimierung können Sie eine parametrische Funktion ermitteln, die das Optimum für jeden möglichen Wert bestimmter Parameter angibt. So wird zum Beispiel das Optimum für x, y für jeden (positiven) Wert von α gefunden:

Bewerten Sie nun die parametrische Funktion für ein bestimmtes α:

Wie bei allem in der Wolfram Language haben wir uns sehr bemüht, die konvexe Optimierung nahtlos in das übrige System zu integrieren, so dass Sie Modelle symbolisch erstellen und ihre Ergebnisse in andere Funktionen einfließen lassen können. Wir haben auch einige sehr leistungsfähige Löser für konvexe Optimierung integriert. Aber vor allem, wenn Sie gemischte (d. h. reelle + ganzzahlige) Optimierung betreiben oder mit wirklich großen Problemen (z. B. 10 Millionen Variablen) zu tun haben, bieten wir auch Zugang zu anderen, externen Solvern. So können Sie zum Beispiel Ihr Problem mit Wolfram Language als „algebraische Modellierungssprache“ erstellen und dann (vorausgesetzt, Sie haben die entsprechenden externen Lizenzen) einfach die Method auf, sagen wir, „Gurobi“ oder „Mosek“ setzen, um Ihr Problem sofort mit einem externen Solver zu lösen. (Übrigens haben wir jetzt einen offenen Rahmen für das Hinzufügen weiterer Solver.)
Unterstützung von Kombinatoren und anderen formalen Bausteinen
Man kann sagen, dass die ganze Idee der symbolischen Ausdrücke (und ihrer Transformationen), auf die wir uns in der Wolfram Language so sehr verlassen, ihren Ursprung in den Kombinatoren hat, die gerade am 7. Dezember 2020 ihr hundertjähriges Jubiläum feierten. Die Version der symbolischen Ausdrücke, die wir in der Wolfram Language haben, ist in vielerlei Hinsicht weitaus fortschrittlicher und brauchbarer als rohe Kombinatoren. Aber in Version 12.2 wollten wir – auch um die Kombinatoren zu feiern – einen Rahmen für rohe Kombinatoren hinzufügen.
So haben wir jetzt zum Beispiel CombinatorS, CombinatorK usw., die entsprechend gerendert werden:

Aber wie sollen wir die Anwendung eines Kombinators auf einen anderen darstellen? Heute schreiben wir so etwas wie:

In den Anfängen der mathematischen Logik gab es jedoch eine andere Konvention, nämlich die linksassoziative Anwendung, bei der man erwartete, dass der „Kombinator-Stil“ „Funktionen“ und nicht „Werte“ aus der Anwendung von Funktionen auf Dinge erzeugt. Daher führen wir in Version 12.2 einen neuen „Anwendungsoperator“ Application ein, der als angezeigt wird (und als \[Application] oder ap eingegeben wird):


Übrigens erwarte ich, dass Application – als neuer, grundlegender „Konstruktor“ – eine Vielzahl von Verwendungen (ganz zu schweigen von „Anwendungen“) beim Aufbau von allgemeinen Strukturen in der Wolfram Language haben wird.
Die Regeln für Kombinatoren sind mit Hilfe von Mustertransformationen in der Wolfram Language trivial zu spezifizieren:
![]()
Aber man kann Kombinatoren auch „algebraischer“ als Beziehungen zwischen Ausdrücken betrachten – und dafür gibt es jetzt eine Theorie in der AxiomaticTheory.
Und in 12.2 wurden einige weitere Theorien zur AxiomaticTheory hinzugefügt, ebenso wie einige neue Eigenschaften.
Euklidische Geometrie wird interaktiv
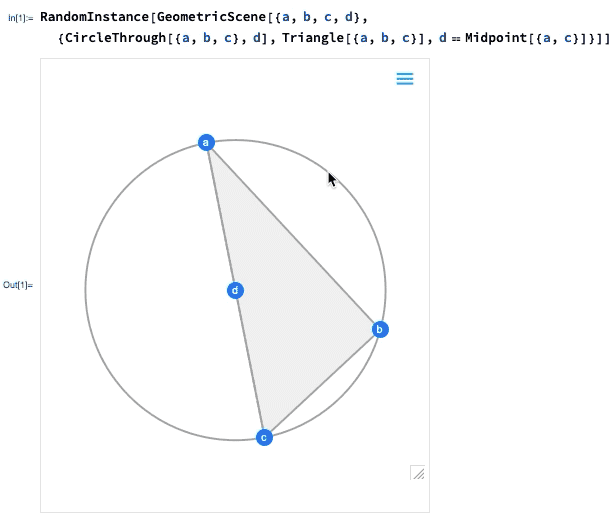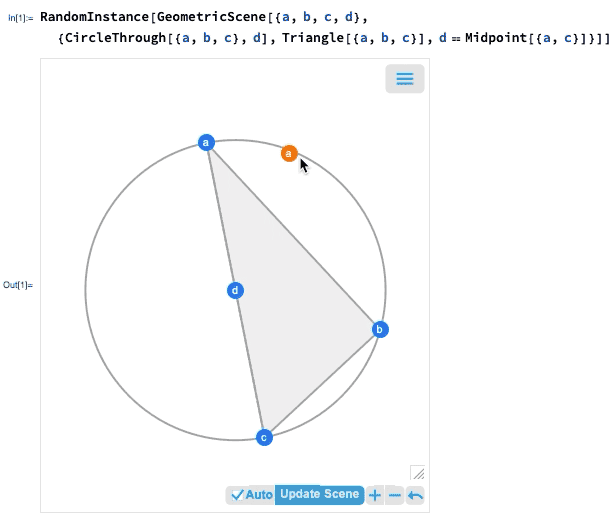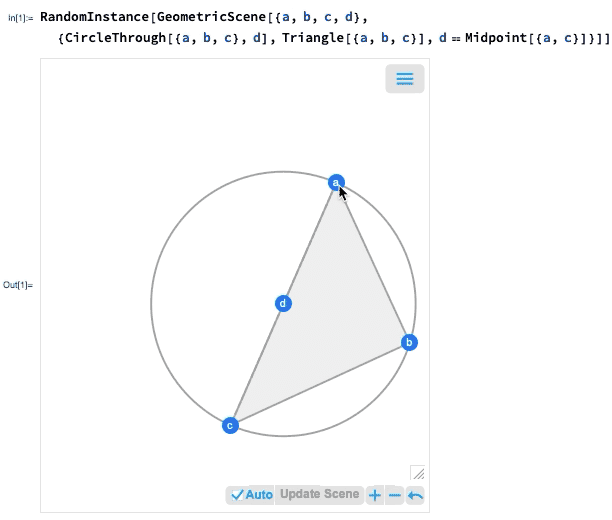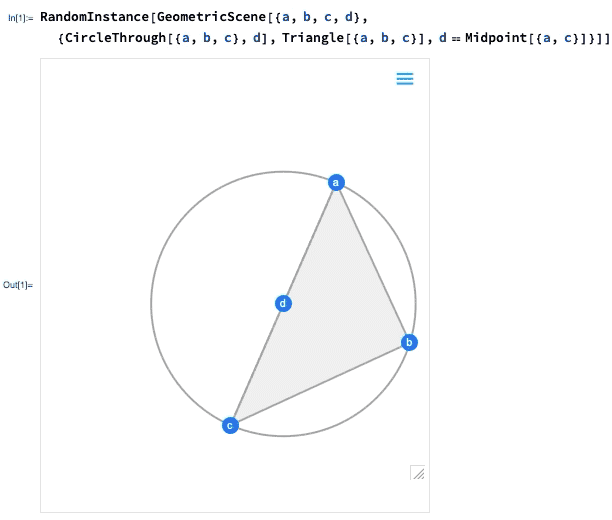
Einer der wichtigsten Fortschritte in Version 12.0 war die Einführung einer symbolischen Darstellung der euklidischen Geometrie: Sie spezifizieren eine symbolische GeometricScene mit einer Vielzahl von Objekten und Randbedingungen, und die Wolfram Language kann sie „lösen“ und ein Diagramm einer zufälligen Instanz zeichnen, die die Randbedingungen erfüllt. In Version 12.2 haben wir dies interaktiv gemacht, so dass Sie die Punkte im Diagramm verschieben können, und alles wird (wenn möglich) interaktiv neu angeordnet, so dass die Beschränkungen eingehalten werden.
Hier ist ein zufälliges Beispiel für eine einfache geometrische Szene:
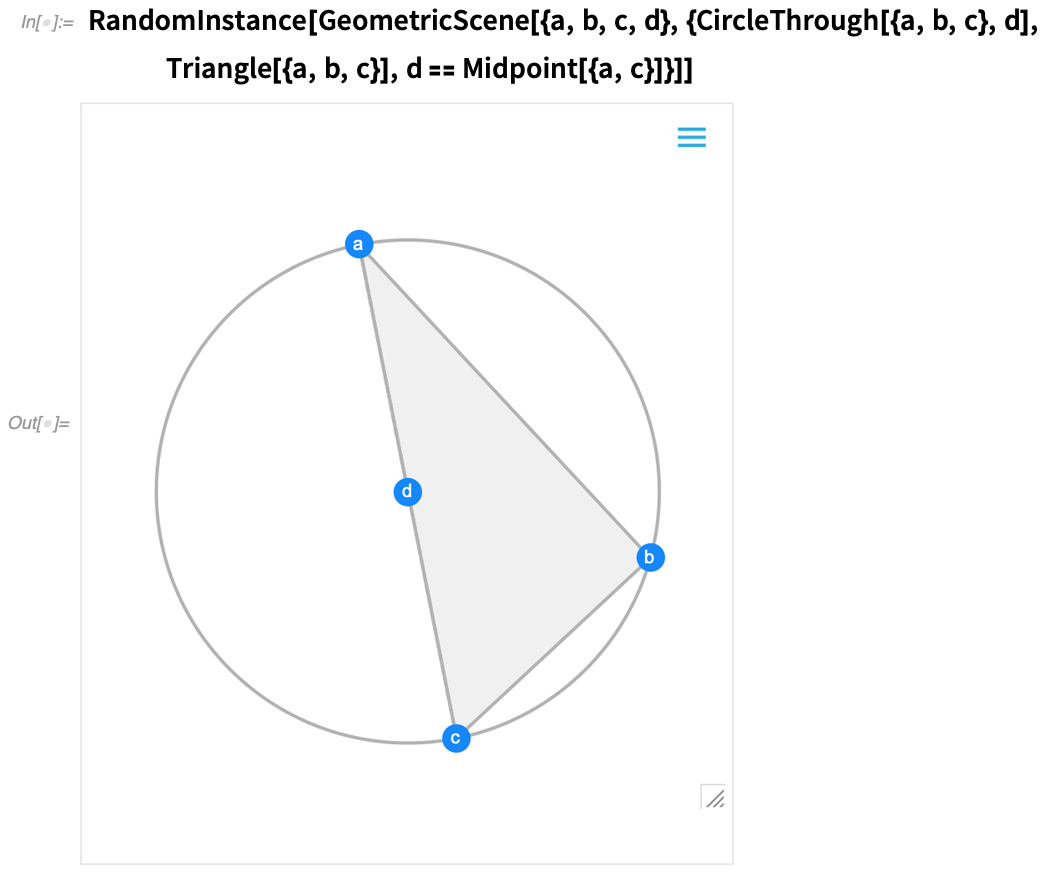
Wenn Sie einen der Punkte verschieben, werden die anderen Punkte interaktiv neu angeordnet, so dass die in der symbolischen Darstellung der geometrischen Szene definierten Beschränkungen erhalten bleiben:
Was geht hier wirklich vor? Im Grunde wird die Geometrie in Algebra umgewandelt. Und wenn Sie wollen, können Sie die algebraische Formulierung erhalten:
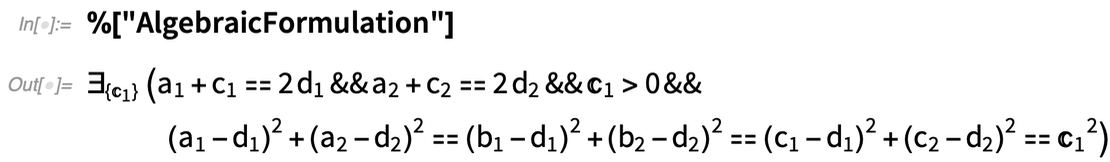
Und natürlich können Sie diese mit Hilfe der vielen leistungsstarken algebraischen Berechnungsfunktionen der Wolfram Language manipulieren.Neben der Interaktivität ist eine weitere wichtige neue Funktion in 12.2 die Fähigkeit, nicht nur komplette geometrische Szenen zu bearbeiten, sondern auch geometrische Konstruktionen, die den Aufbau einer Szene in mehreren Schritten beinhalten. Hier ist ein Beispiel, das zufällig direkt von Euklid stammt:

Das erste Bild, das Sie erhalten, ist im Grunde das Ergebnis der Konstruktion. Und wie alle anderen geometrischen Szenen ist es jetzt interaktiv. Aber wenn Sie mit der Maus darüberfahren, erhalten Sie Steuerelemente, mit denen Sie zu früheren Schritten wechseln können:
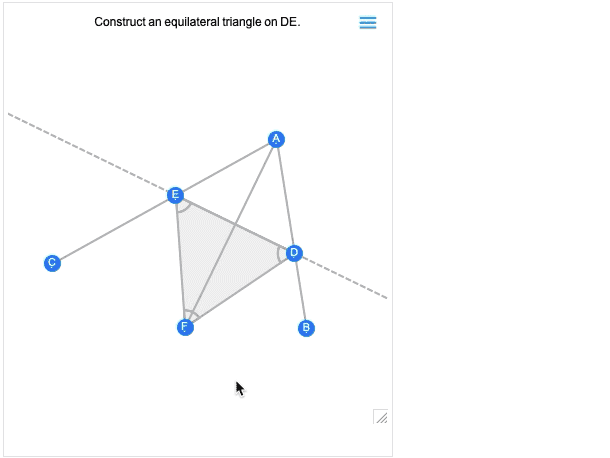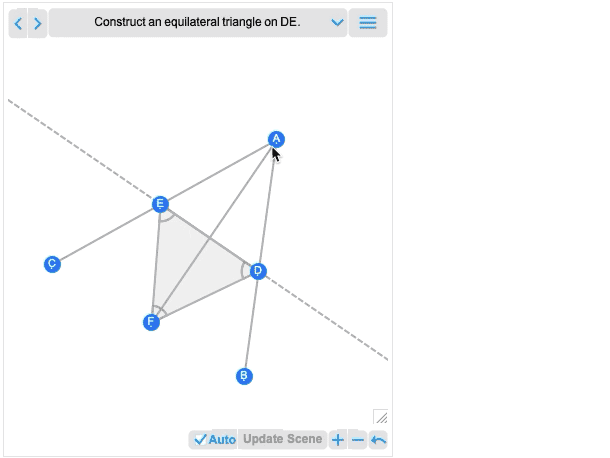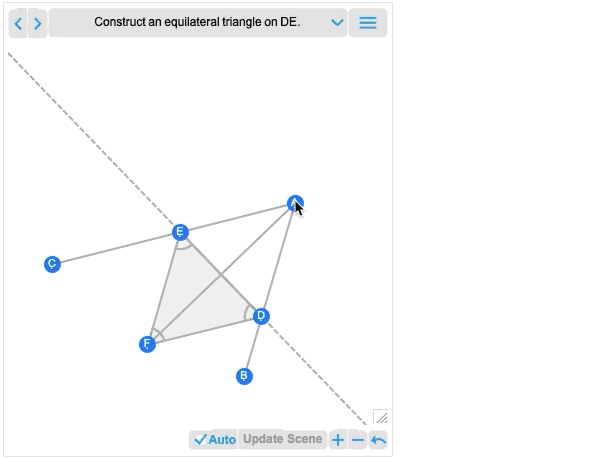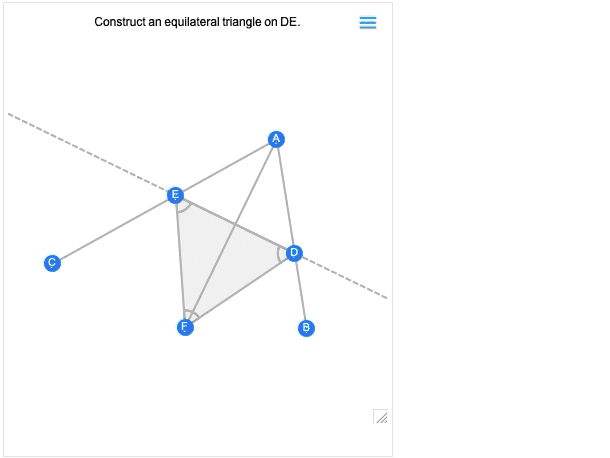
Wenn Sie einen Punkt in einem früheren Schritt verschieben, werden Sie sehen, welche Auswirkungen dies auf spätere Schritte in der Konstruktion hat.Euklids Geometrie ist das allererste axiomatische System für die Mathematik, das wir kennen. Über 2000 Jahre später ist es spannend, dass wir es endlich berechenbar machen können. (Und ja, es wird schließlich mit AxiomaticTheory, FindEquationalProof usw. verbunden sein).
Aber in Anerkennung der Bedeutung von Euklids ursprünglicher Formulierung der Geometrie haben wir berechenbare Versionen seiner Sätze (sowie eine Reihe anderer „berühmter geometrischer Theoreme“) hinzugefügt. Das obige Beispiel stellt sich als Satz 9 in Euklids Buch 1 heraus. Und jetzt können wir zum Beispiel seine Originalaussage auf Griechisch erhalten:

Und hier ist sie in moderner Wolfram Language – in einer Form, die sowohl von Computern als auch von Menschen verstanden werden kann:

Noch mehr Arten von Wissen für die Wissensdatenbank
Ein wichtiger Teil der Geschichte der Wolfram Language als vollwertige Computersprache ist ihr Zugang zu unserer riesigen Wissensdatenbank mit Daten über die Welt. Die Wissensdatenbank wird ständig aktualisiert und erweitert, und tatsächlich wurden in der Zeit seit Version 12.1 in fast allen Domänen Daten (und oft eine beträchtliche Menge) aktualisiert oder Entitäten hinzugefügt oder geändert.
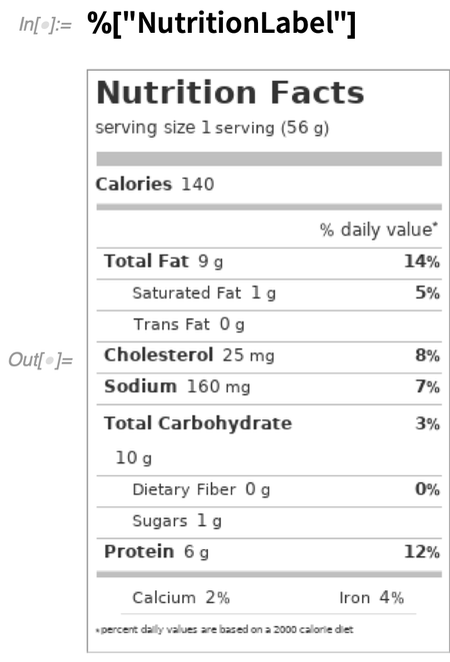
Aber lassen Sie mich als Beispiele dafür, was getan wurde, ein paar Ergänzungen nennen. Ein Bereich, dem viel Aufmerksamkeit geschenkt wurde, sind Lebensmittel. Inzwischen liegen uns Daten über mehr als eine halbe Million Lebensmittel vor (zum Vergleich: ein typisches großes Lebensmittelgeschäft führt vielleicht 30.000 verschiedene Artikel). Wählen Sie ein beliebiges Lebensmittel aus:

Erstellen Sie nun eine Nährwertkennzeichnung:
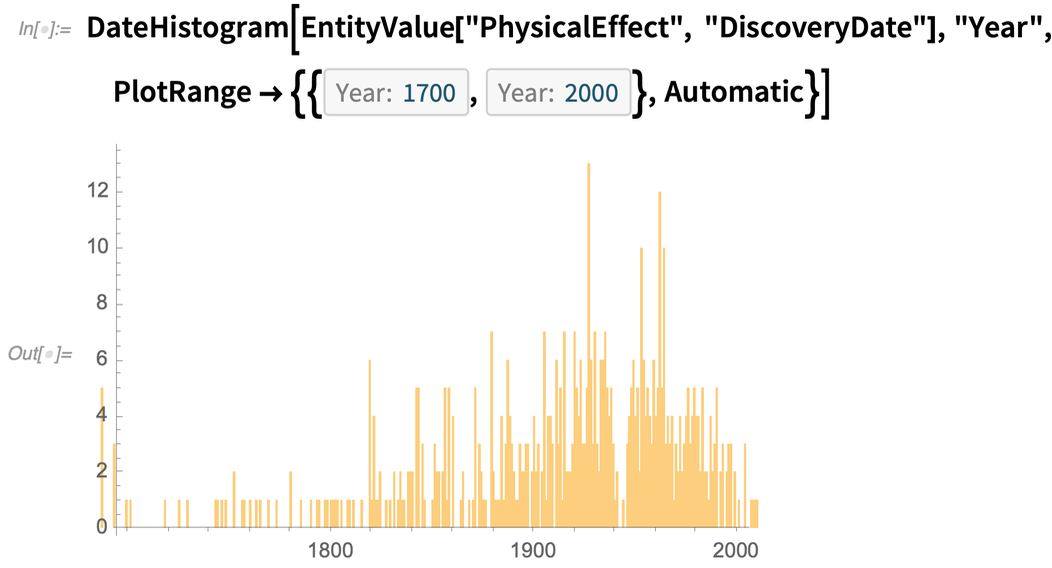
Ein weiteres Beispiel für eine neue Art von Entität, die hinzugefügt wurde, sind physikalische Effekte. Hier sind einige zufällige Effekte:

And as an example of something that can be done with all the data in this domain, here’s a histogram of the dates when these effects were discovered:
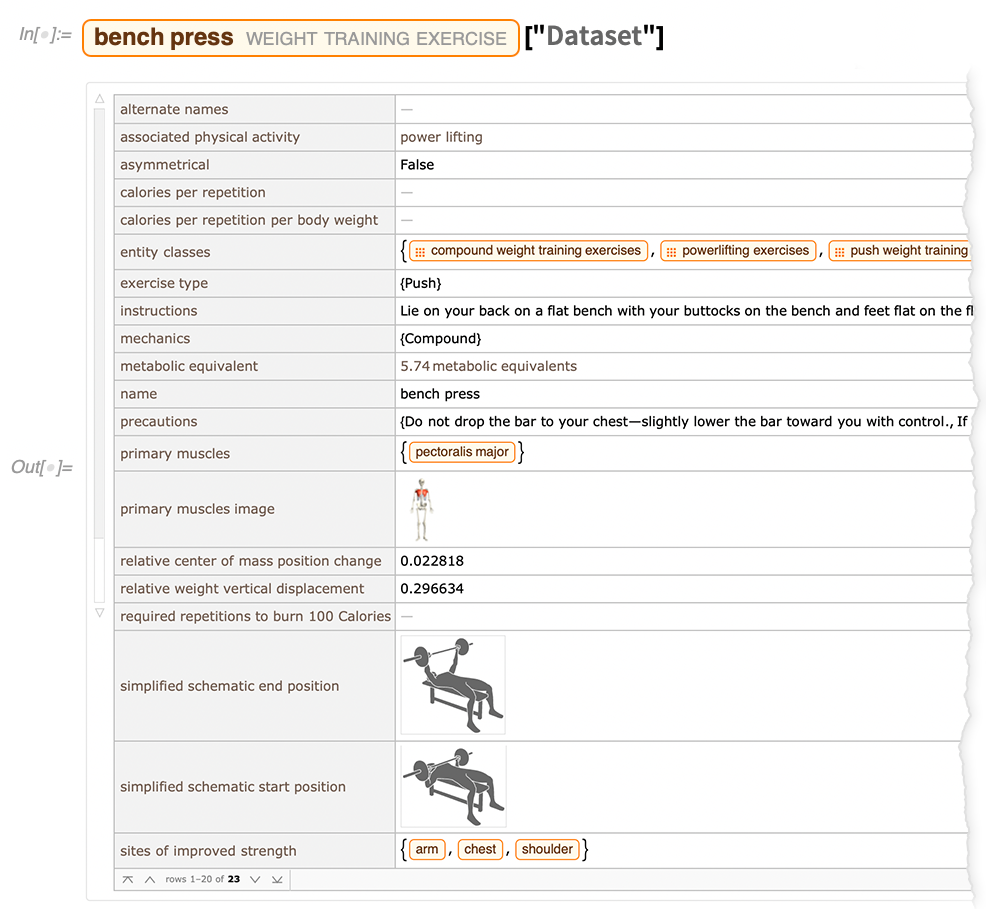
Als weiteres Beispiel für unsere Arbeit gibt es jetzt auch einen Bereich, den man (augenzwinkernd) als „Schwergewicht“ bezeichnen könnte – Übungen zum Gewichtstraining:
Ein wichtiges Merkmal der Wolfram Knowledgebase ist, dass sie symbolische Objekte enthält, die nicht nur „einfache Daten“ – wie Zahlen oder Zeichenketten – repräsentieren können, sondern auch vollständige Berechnungsinhalte. In Version 12.2 kann man beispielsweise direkt in der Knowledgebase auf das Wolfram Demonstrations Project zugreifen – mit all seinem aktiven Wolfram Language Code und seinen Notebooks. Hier sind einige zufällige Demonstrationen:

Die Werte von Eigenschaften können dynamische interaktive Objekte sein:
Und weil alles berechenbar ist, kann man zum Beispiel sofort eine Bildcollage aller Demonstrationen zu einem bestimmten Thema erstellen:

Die fortlaufende Geschichte des maschinellen Lernens
Es ist fast 7 Jahre her, dass wir Classify und Predict eingeführt haben und damit begonnen haben, neuronale Netze vollständig in die Wolfram Language zu integrieren. Es gibt zwei Hauptrichtungen: Die erste ist die Entwicklung von „Superfunktionen“, wie Classify und Predict, die – so automatisch wie möglich – auf maschinellem Lernen basierende Operationen durchführen. Die zweite Richtung ist die Bereitstellung eines leistungsstarken symbolischen Rahmens, um die neuesten Fortschritte bei neuronalen Netzen zu nutzen (insbesondere durch das Wolfram Neural Net Repository) und um eine flexible Weiterentwicklung und Experimente zu ermöglichen.
Die Version 12.2 hat in beiden Bereichen Fortschritte gemacht. Ein Beispiel für eine neue Superfunktion ist FaceRecognize. Geben Sie ihr eine kleine Anzahl markierter Beispiele von Gesichtern, und sie wird versuchen, diese in Bildern, Videos usw. zu erkennen. Holen wir uns einige Trainingsdaten aus Websuchen (und ja, sie sind etwas verrauscht):

Erstellen Sie nun einen Gesichtserkenner mit diesen Trainingsdaten:

Jetzt können wir damit herausfinden, wer in jedem Bild eines Videos auf dem Bildschirm zu sehen ist:

Stellen Sie nun die Ergebnisse dar:

Im Wolfram Neural Net Repository werden regelmäßig neue Netze hinzugefügt. Seit Version 12.1 wurden etwa 20 neue Arten von Netzen hinzugefügt – darunter viele neue Transformator-Netze sowie EfficientNet und zum Beispiel Feature-Extraktoren wie BioBERT und SciBERT, die speziell auf Text aus wissenschaftlichen Arbeiten trainiert wurden.
In jedem Fall sind die Netze über NetModel sofort zugänglich und nutzbar. Eine Neuerung in Version 12.2 ist die visuelle Darstellung von Netzwerken:
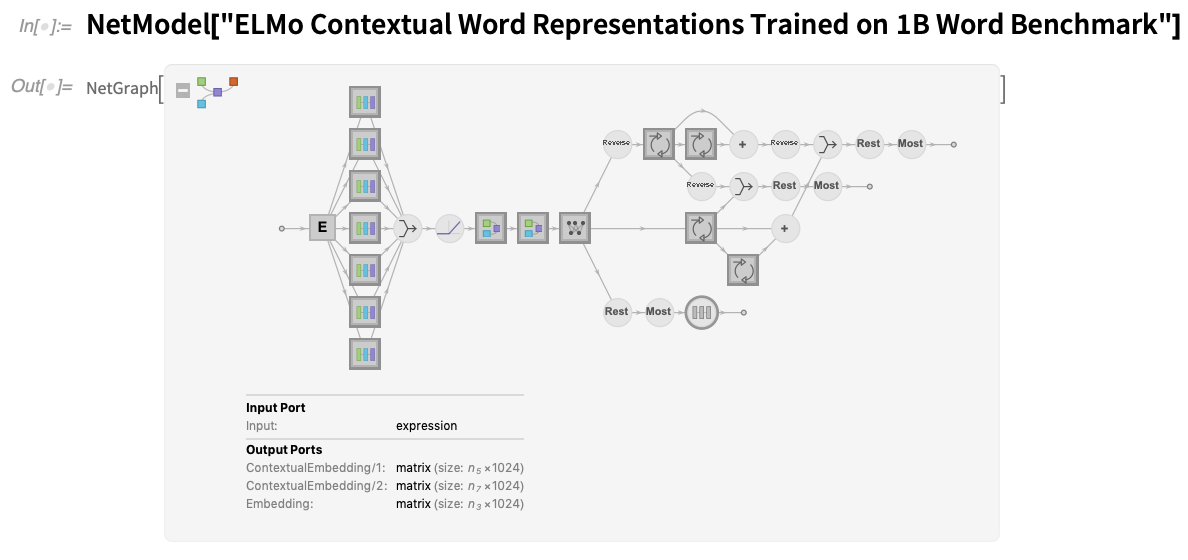
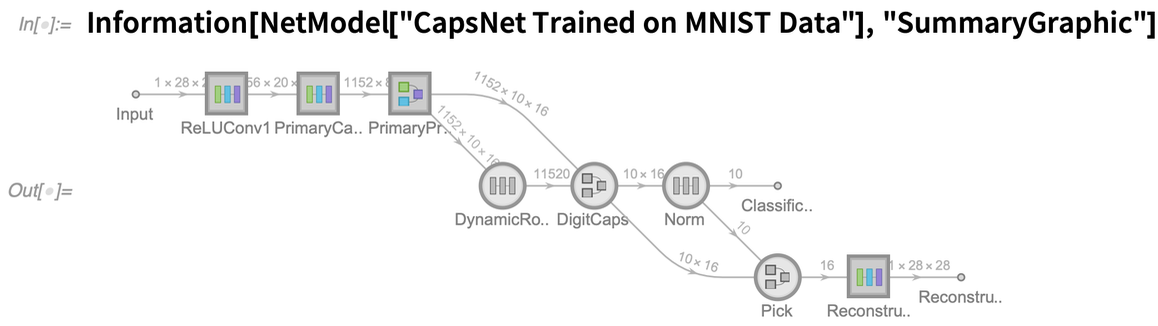
Es gibt viele neue Symbole, aber es gibt jetzt auch eine klare Konvention, dass Kreise feste Elemente eines Netzes darstellen, während Quadrate trainierbare Elemente repräsentieren. Außerdem bedeutet ein dicker Rand in einem Symbol, dass es ein zusätzliches Netz gibt, das man durch Anklicken sehen kann.Unabhängig davon, ob es sich um ein Netz handelt, das aus NetModel stammt, oder um ein von Ihnen selbst konstruiertes Netz (oder eine Kombination aus beidem), ist es oft praktisch, die „zusammenfassende Grafik“ für das Netz zu extrahieren, um sie z. B. in die Dokumentation oder eine Veröffentlichung aufzunehmen. Information bietet mehrere Ebenen von Zusammenfassungsgrafiken:
Es gibt mehrere wichtige Ergänzungen zu unserem Kern-Framework für neuronale Netze, die das Spektrum der Funktionen neuronaler Netze erweitern, auf die wir zugreifen können. Die erste ist, dass wir in Version 12.2 native Kodierer für Graphen und Zeitreihen haben. Hier erstellen wir zum Beispiel eine Merkmalsraumdarstellung von 20 zufällig benannten Graphen:

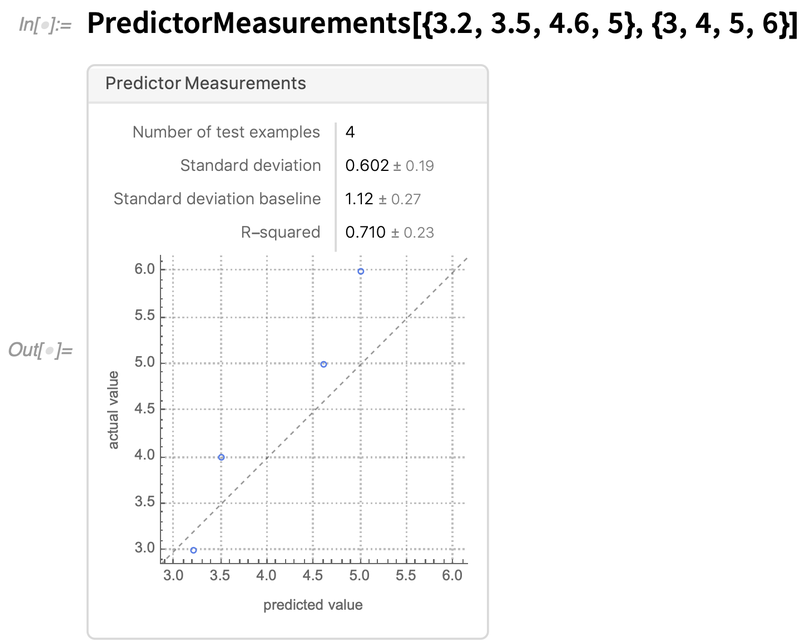
Eine weitere Verbesserung des Rahmens betrifft die Diagnose von Modellen. Wir haben vor vielen Jahren PredictorMeasurements und ClassifierMeasurements eingeführt, um eine symbolische Darstellung der Leistung von Modellen zu ermöglichen. In Version 12.2 haben wir – als Reaktion auf zahlreiche Anfragen – die Möglichkeit geschaffen, ein PredictorMeasurements-Objekt mit endgültigen Vorhersagen und nicht mit einem Modell zu füttern, und wir haben das Erscheinungsbild und die Funktionsweise von PredictorMeasurements-Objekten optimiert:
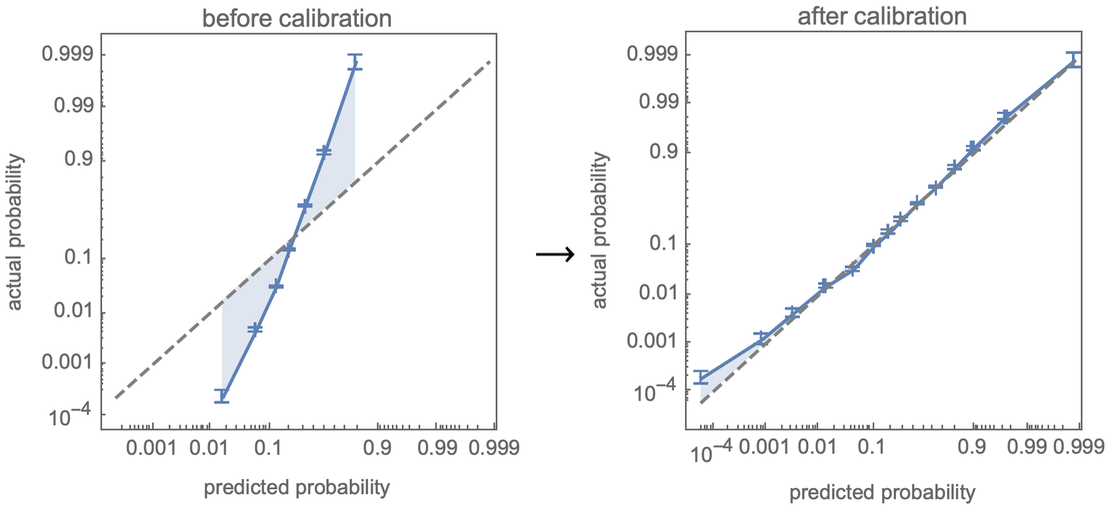
Eine wichtige neue Funktion von ClassifierMeasurements ist die Fähigkeit, eine Kalibrierungskurve zu berechnen, die die tatsächlichen Wahrscheinlichkeiten, die bei der Probenahme einer Testmenge beobachtet wurden, mit den Vorhersagen des Klassifikators vergleicht. Noch wichtiger ist jedoch, dass Classify seine Wahrscheinlichkeiten automatisch kalibriert und somit versucht, die Kalibrierungskurve zu „formen“:
Mit Version 12.2 wurde auch die Art und Weise, wie neuronale Netze aufgebaut werden können, grundlegend überarbeitet. Der grundlegende Aufbau bestand schon immer darin, eine bestimmte Sammlung von Schichten zusammenzustellen, die so etwas wie Array-Indizes darstellen, die durch explizite Kanten in einem Graphen verbunden sind. Version 12.2 führt nun FunctionLayer ein, was es Ihnen ermöglicht, etwas zu erstellen, das viel näher an gewöhnlichem Wolfram Language-Code liegt. Hier ist ein Beispiel für eine bestimmte Funktionsschicht:

Und hier ist die Darstellung dieser Funktionsschicht als expliziter NetGraph:
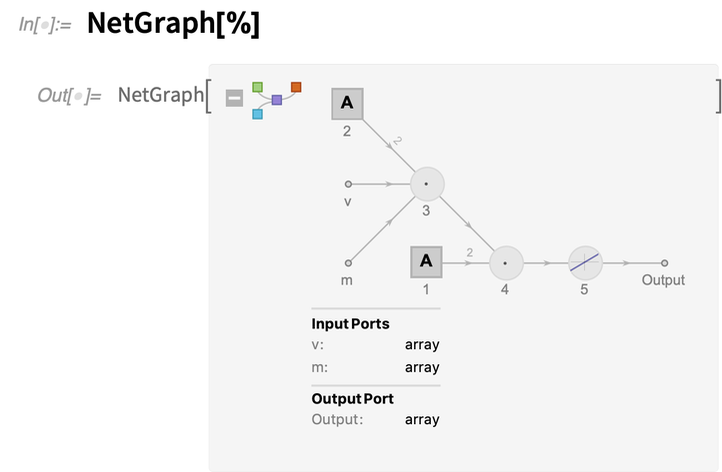
v und m werden als „Eingangsanschlüsse“ bezeichnet. Das NetArray – erkennbar an den quadratischen Symbolen im Netzgraphen – ist ein lernbares Array, das hier nur zwei Elemente enthält.
Es gibt Fälle, in denen es einfacher ist, den „blockbasierten“ (oder „grafischen“) Programmieransatz zu verwenden, bei dem die Schichten einfach miteinander verbunden werden (und wir haben hart daran gearbeitet, dass die Verbindungen so automatisch wie möglich hergestellt werden können). Aber es gibt auch Fälle, in denen es einfacher ist, den „funktionalen“ Programmieransatz von FunctionLayer zu verwenden. Im Moment unterstützt FunctionLayer nur eine Teilmenge der Konstrukte, die in der Wolfram Language verfügbar sind – obwohl dies bereits viele Standard-Array- und funktionale Programmier-Operationen umfasst, und weitere werden in der Zukunft hinzugefügt werden.
Ein wichtiges Merkmal von FunctionLayer ist, dass das von ihm erzeugte neuronale Netz so effizient wie jedes andere neuronale Netz ist und auf GPUs usw. laufen kann. Aber was kann man mit Wolfram Language-Konstrukten machen, die noch nicht nativ von FunctionLayer unterstützt werden? In Version 12.2 fügen wir eine weitere neue experimentelle Funktion hinzu – CompiledLayer – die den Bereich von Wolfram Language-Code erweitert, der effizient verarbeitet werden kann.
Es lohnt sich vielleicht, ein wenig zu erklären, was im Inneren passiert. Unser Haupt-Framework für neuronale Netze ist im Wesentlichen eine symbolische Schicht, die Dinge für eine optimierte Low-Level-Implementierung organisiert, wobei derzeit MXNet verwendet wird. FunctionLayer übersetzt bestimmte Wolfram Language-Konstrukte direkt in MXNet. CompiledLayer übersetzt Wolfram Language in LLVM und dann in Maschinencode und fügt diesen in den Ausführungsprozess in MXNet ein. CompiledLayer nutzt den neuen Wolfram Language Compiler und seine umfangreichen Mechanismen zur Typinferenz und Typdeklaration.
OK, nehmen wir an, man hat ein großartiges neuronales Netz in unserem Wolfram Language Framework gebaut. Alles ist so eingerichtet, dass das Netz sofort in einer ganzen Reihe von Wolfram Language-Superfunktionen (Classify, FeatureSpacePlot, AnomalyDetection, FindClusters, …) verwendet werden kann. Was aber, wenn man das Netz „standalone“ in einer externen Umgebung nutzen möchte? In Version 12.2 führen wir die Möglichkeit ein, praktisch jedes Netz in der kürzlich entwickelten ONNX-Standarddarstellung zu exportieren.
Und sobald man ein Netzwerk in ONNX-Form hat, kann man das ganze Ökosystem externer Tools nutzen, um es in einer Vielzahl von Umgebungen einzusetzen. Ein bemerkenswertes Beispiel – das jetzt ein ziemlich rationalisierter Prozess ist – ist die Verwendung eines vollständig in der Wolfram-Sprache erstellten neuronalen Netzes, das in CoreML auf einem iPhone ausgeführt wird, so dass es beispielsweise direkt in eine mobile Anwendung integriert werden kann.
Formular Notizbücher
Wie kann man am besten strukturiertes Material sammeln? Wenn Sie nur ein paar Elemente erfassen wollen, kann ein gewöhnliches Formular, das mit FormFunction erstellt (und beispielsweise in der Cloud bereitgestellt) wurde, gut funktionieren. Was aber, wenn Sie versuchen, längeres, umfangreicheres Material zu sammeln?
Nehmen wir zum Beispiel an, Sie erstellen ein Quiz, bei dem die Schüler eine ganze Reihe komplexer Antworten eingeben sollen. Oder Sie erstellen eine Vorlage, in der die Teilnehmer eine Dokumentation zu einem bestimmten Thema ausfüllen sollen. In diesen Fällen benötigen Sie ein neues Konzept, das wir in Version 12.2 einführen: Formularnotizbücher.
Ein Formular-Notizbuch ist im Grunde ein Notizbuch, das so eingerichtet ist, dass es als komplexes „Formular“ verwendet werden kann, wobei die Eingaben im Formular alle Arten von Dingen sein können, die Sie von einem Notizbuch gewohnt sind.Der grundlegende Arbeitsablauf für Formular-Notizbücher sieht folgendermaßen aus. Zunächst erstellen Sie ein Formular-Notizbuch und definieren die verschiedenen „Formularelemente“ (oder Bereiche), die der Benutzer des Formular-Notizbuchs ausfüllen soll. Als Teil des Erstellungsprozesses legen Sie fest, was mit dem Material geschehen soll, das der Benutzer des Formular-Notizbuchs eingibt, wenn er das Formular-Notizbuch verwendet (z. B. Ablage des Materials in einem Wolfram Data Drop Databin, Senden des Materials an eine Cloud-API, Senden des Materials als symbolischer Ausdruck per E-Mail usw.).
Nachdem Sie das Formular-Notizbuch erstellt haben, generieren Sie eine aktive Version, die an die Personen gesendet werden kann, die das Formular-Notizbuch verwenden werden. Sobald jemand sein Material in seine Kopie des Formular-Notizbuchs eingetragen hat, drückt er eine Schaltfläche, in der Regel „Submit, und sein Material wird dann als strukturierter symbolischer Ausdruck an das vom Autor des Formular-Notizbuchs angegebene Ziel gesendet.
Es ist vielleicht erwähnenswert, wie sich Formular-Notizbücher zu etwas verhalten, das ähnlich klingt: Vorlagen-Notizbücher. In gewissem Sinne ist ein Vorlagen-Notizbuch das Gegenteil eines Formular-Notizbuchs. Bei einem Formular-Notizbuch geht es darum, dass ein Benutzer Material eingibt, das dann bearbeitet wird. Bei einem Vorlagen-Notizbuch hingegen geht es darum, dass der Computer Material generiert, das dann zum Auffüllen eines Notizbuchs verwendet wird, dessen Struktur durch das Vorlagen-Notizbuch definiert ist.
OK, wie fangen Sie also mit Formularnotizbüchern an? Gehen Sie einfach auf File > New > Programmatic Notebook > Form Notebook Authoring:
Es handelt sich dabei um ein Notizbuch, in das Sie beliebige Inhalte eingeben können, z. B. eine Erklärung, was die Benutzer tun sollen, wenn sie das Formular ausfüllen. Aber dann gibt es spezielle Zellen oder Zellfolgen im Formularnotizbuch, die wir „Formularelemente“ und „bearbeitbare Notizbuchbereiche“ nennen. Diese sind es, die der Benutzer des Formularnotizbuchs „ausfüllt“, um seine „Antworten“ einzugeben, und das Material, das er bereitstellt, wird gesendet, wenn er die Schaltfläche „Absenden“ drückt (oder was auch immer für eine endgültige Aktion definiert wurde).
Im Autoren-Notizbuch finden Sie in der Symbolleiste ein Menü mit möglichen Formularelementen, die Sie einfügen können:
Nehmen wir als Beispiel das „Eingabefeld“:
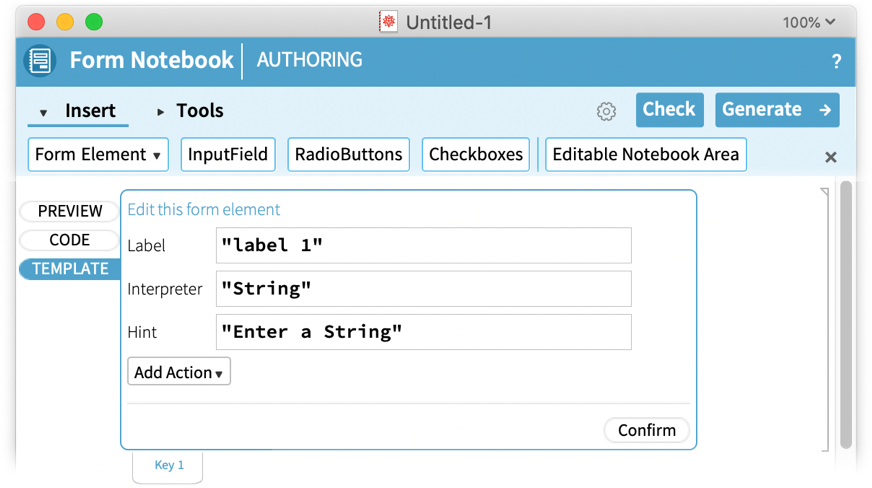
Was bedeutet das alles? Grundsätzlich wird ein Formularelement durch einen sehr flexiblen symbolischen Wolfram Language-Ausdruck dargestellt, und dies gibt Ihnen die Möglichkeit, den gewünschten Ausdruck zu spezifizieren. Sie können eine Beschriftung und einen Hinweis in das Eingabefeld eingeben. Aber erst mit dem Interpreter wird die Leistungsfähigkeit der Wolfram Language richtig deutlich. Denn der Interpreter nimmt alles, was der Benutzer des Formular-Notizbuchs in dieses Eingabefeld eingibt, und interpretiert es als berechenbares Objekt. Standardmäßig wird es einfach als Zeichenkette behandelt. Aber es könnte zum Beispiel ein „Country“ oder ein „MathExpression“ sein. Bei diesen Optionen wird das Material automatisch als Land, mathematischer Ausdruck usw. interpretiert, wobei der Benutzer normalerweise gefragt wird, wenn seine Eingabe nicht wie angegeben interpretiert werden kann.
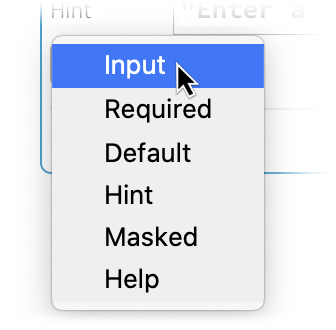
Es gibt viele Optionen für die Details, wie ein Eingabefeld funktionieren kann. Einige davon werden im Menü „Aktion hinzufügen“ angeboten:
Aber was „ist“ dieses Formularelement eigentlich? Drücken Sie auf die Registerkarte CODE auf der linken Seite, um es zu sehen:

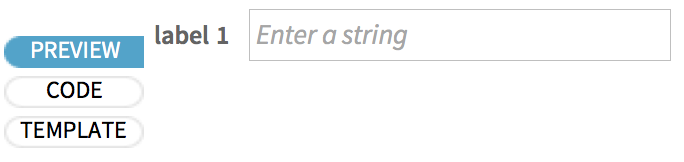
Was würde ein Benutzer des Formular-Notizbuchs hier sehen? Klicken Sie auf die Registerkarte PREVIEW, um das herauszufinden:
Neben Eingabefeldern gibt es viele andere mögliche Formularelemente. Es gibt Dinge wie Kontrollkästchen, Optionsfelder und Schieberegler. Und im Allgemeinen ist es möglich, jedes der reichhaltigen symbolischen Benutzeroberflächenkonstrukte zu verwenden, die in der Wolfram Language existieren.
Wenn Sie mit dem Verfassen fertig sind, drücken Sie auf Generieren, um ein Formular-Notizbuch zu erzeugen, das den Benutzern zum Ausfüllen zur Verfügung gestellt werden kann. In den Einstellungen wird festgelegt, wie die „Submit“-Aktion angegeben werden soll und was geschehen soll, wenn das Formular-Notizbuch abgeschickt wird:

Was ist also das „Ergebnis“ eines eingereichten Formularnotizbuchs? Im Grunde ist es eine Assoziation, die angibt, was in die einzelnen Bereiche des Formularnotizbuchs eingegeben wurde. (Die Bereiche werden durch Schlüssel in der Assoziation identifiziert, die bei der ersten Definition der Bereiche im Notizbuch angegeben wurden).
Schauen wir uns an, wie dies in einem einfachen Fall funktioniert. Hier ist das Autoren-Notebook für ein Formular-Notebook:
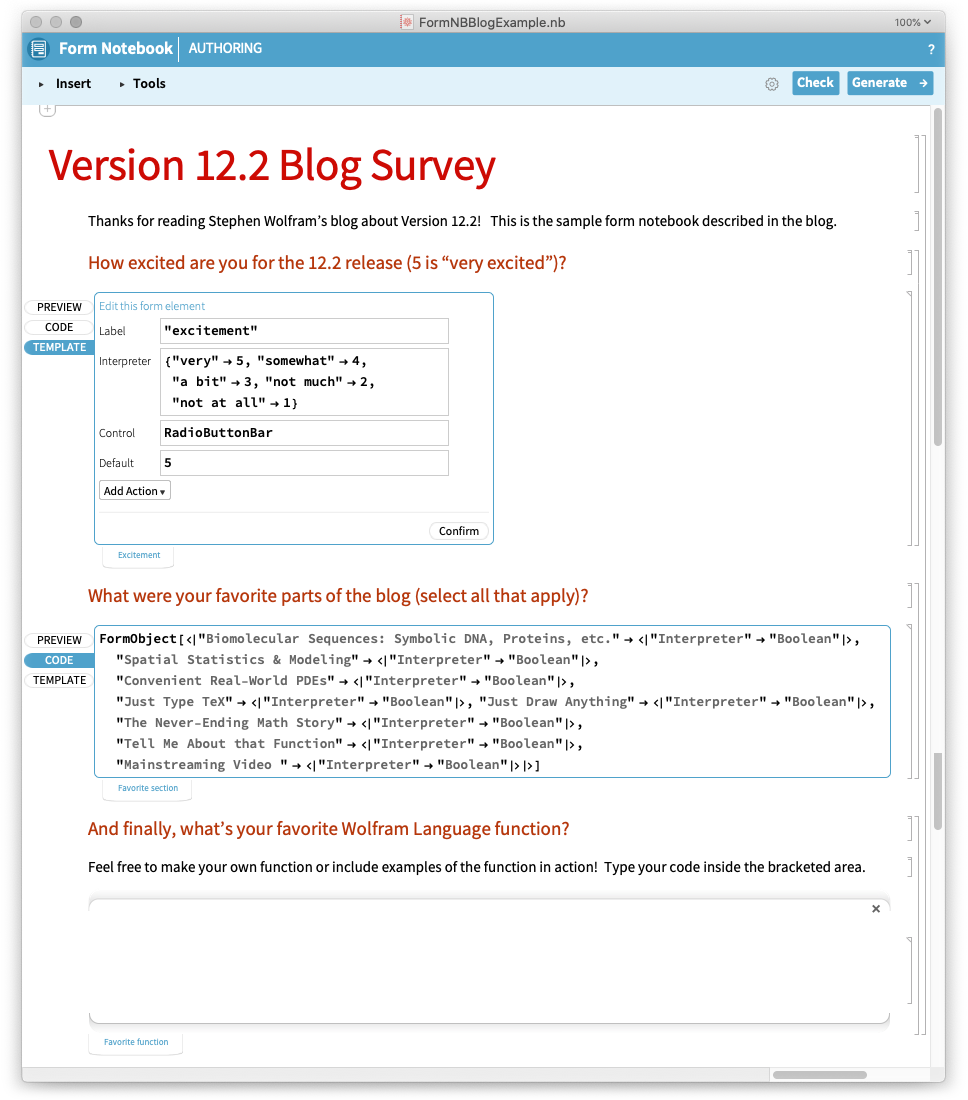
Hier sehen Sie das generierte Formularheft, das Sie ausfüllen können:
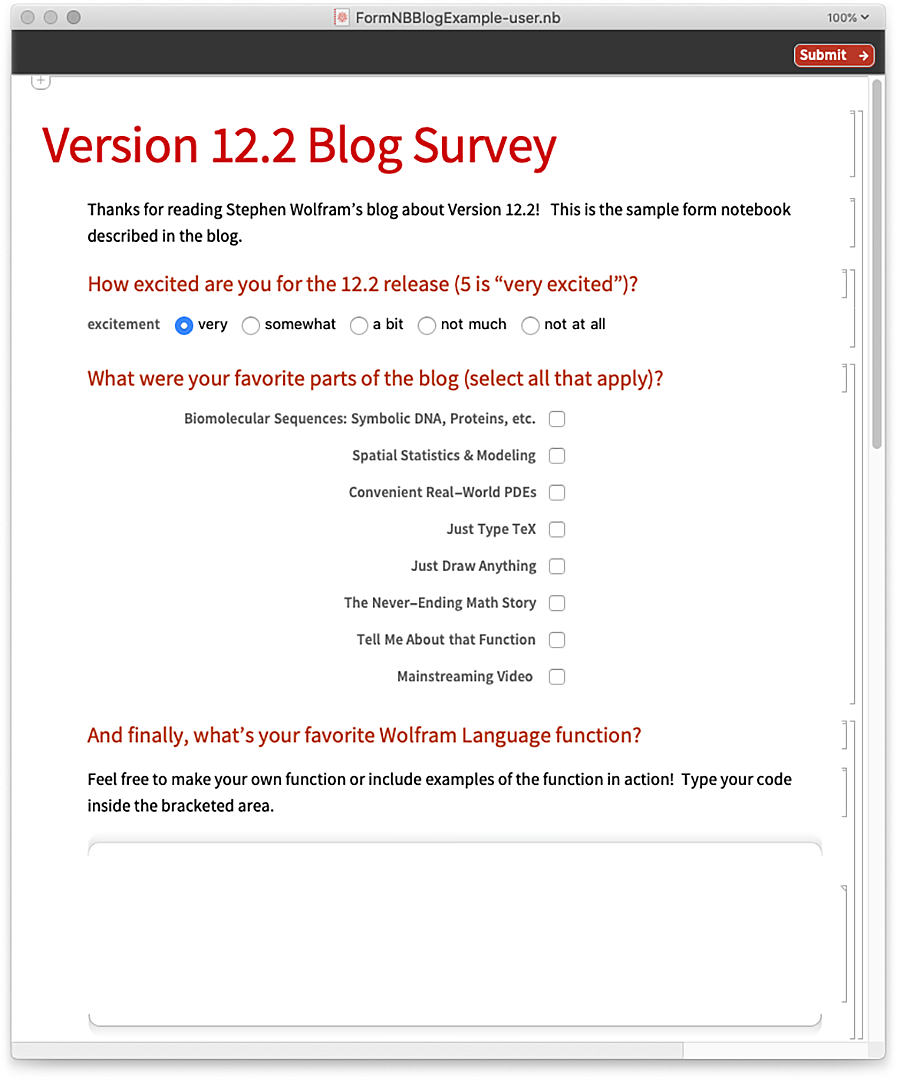
Hier ist ein Beispiel dafür, wie das Formular ausgefüllt werden könnte:
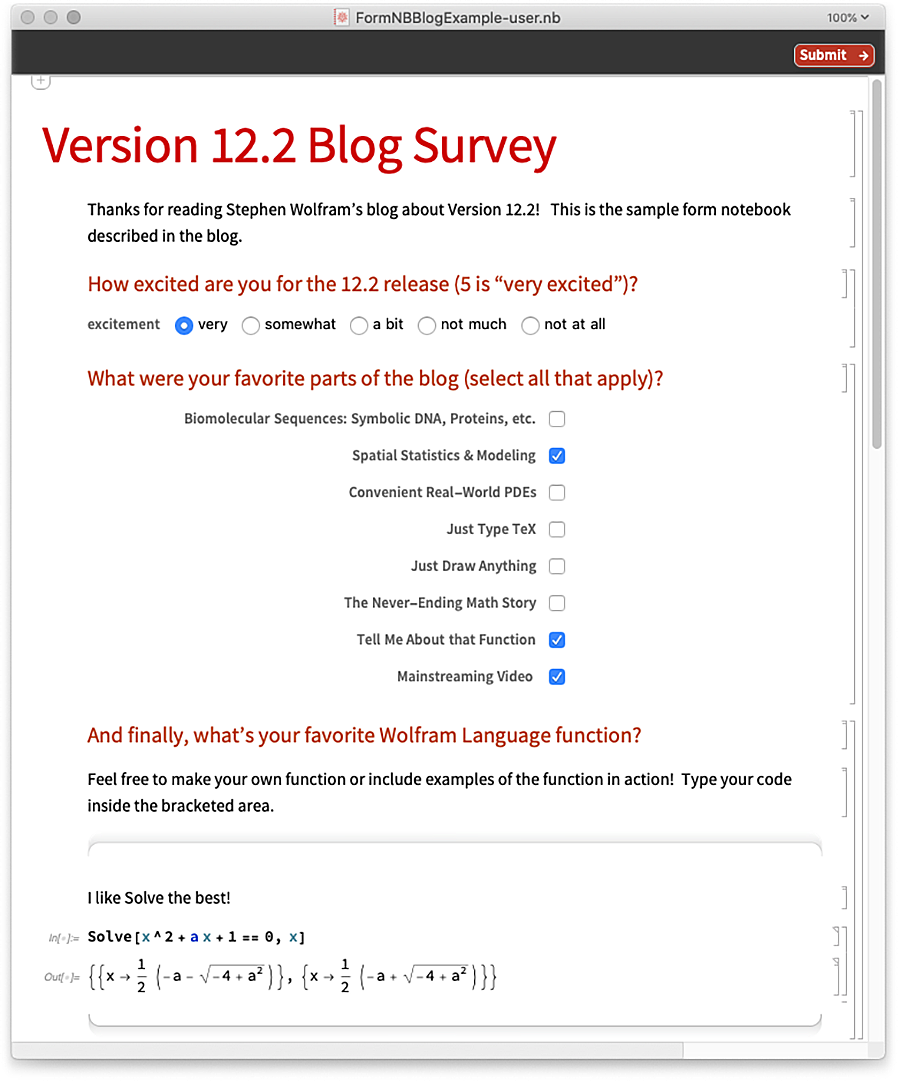
Und das ist es, was „zurückkommt“, wenn Submit gedrückt wird:

Zu Testzwecken können Sie diese Assoziation einfach interaktiv in einem Notizbuch ablegen. In der Praxis ist es jedoch üblicher, die Assoziation an eine Datenablage zu senden, sie in einem Cloud-Objekt zu speichern oder sie generell an einem „zentraleren“ Ort abzulegen.
Beachten Sie, dass am Ende dieses Beispiels ein bearbeitbarer Notizbuchbereich vorhanden ist, in den Sie Freiform-Notizbuchinhalte (mit Zellen, Überschriften, Code, Ausgaben usw.) eingeben können, die alle erfasst werden, wenn das Formularnotizbuch übermittelt wird.Formularhefte sind eine sehr nützliche Idee, und Sie werden sie überall finden. Als erstes Beispiel werden die verschiedenen Einreichungsnotizbücher für das Wolfram Function Repository, das Wolfram Demonstrations Project, etc. zu Formularnotizbüchern. Wir erwarten auch, dass Formular-Notizbücher im Bildungsbereich häufig verwendet werden. Und als Teil davon bauen wir ein System auf, das die Wolfram Language für die Bewertung von Antworten in Formularnotizbüchern (und anderswo) nutzt.
Die Anfänge dazu sind in Version 12.2 mit der experimentellen Funktion AssessmentFunction zu sehen, die ähnlich wie Interpreter in Formularnotizbücher eingebunden werden kann. Aber auch ohne den vollen Funktionsumfang von AssessmentFunction gibt es unglaublich viele Möglichkeiten, Formularnotizbücher im Bildungsbereich und anderswo zu nutzen.
Übrigens sollte man sich darüber im Klaren sein, dass Formular-Notizbücher letztlich in jedem Fall sehr einfach zu verwenden sind. Ja, sie haben eine große Tiefe, die es ihnen erlaubt, eine sehr breite Palette von Dingen zu tun. Und sie sind im Grunde nur möglich aufgrund der gesamten symbolischen Struktur der Wolfram Language und der Tatsache, dass Wolfram Notebooks letztlich als symbolische Ausdrücke dargestellt werden. Aber wenn es darum geht, sie für einen bestimmten Zweck zu verwenden, sind sie sehr stromlinienförmig und einfach, und es ist absolut realistisch, ein nützliches Formular-Notizbuch in nur wenigen Minuten zu erstellen.
Noch mehr Notebookery
Wir haben Notebooks – mit all ihren grundlegenden Merkmalen wie hierarchischen Zellen usw. – bereits 1987 erfunden. Aber seit einem Drittel des Jahrhunderts haben wir ihre Funktionsweise immer weiter verfeinert und gestrafft. Und in Version 12.2 gibt es eine ganze Reihe nützlicher und praktischer neuer Notizbuchfunktionen.
ClickToCopy
Es ist eine sehr einfache Funktion, aber sie ist sehr nützlich. Sie sehen etwas in einem Notizbuch und wollen es eigentlich nur kopieren (oder vielleicht etwas, das damit zusammenhängt). Dann verwenden Sie einfach

Wenn Sie etwas unbewertet per Mausklick kopieren wollen, verwenden Sie Defer:
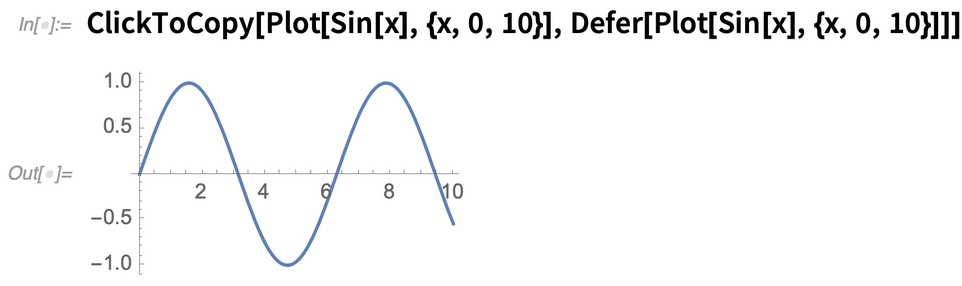
Rationalisiertes Hyperlinking (und Hyperlink-Bearbeitung)
++h hat seit 1996 einen Hyperlink in ein Wolfram Notebook eingefügt. Aber in Version 12.2 gibt es zwei wichtige Neuerungen bei Hyperlinks. Erstens, automatisches Hyperlinking, das eine breite Palette von verschiedenen Situationen handhabt. Und zweitens ein modernisierter und gestraffter Mechanismus für die Erstellung und Bearbeitung von Hyperlinks.

Angehängte Zellen
In Version 12.2 stellen wir etwas zur Verfügung, das wir intern schon seit einiger Zeit haben: die Möglichkeit, eine schwebende, voll funktionsfähige Zelle an eine beliebige Zelle (oder Box oder ein ganzes Notizbuch) anzuhängen. Der Zugriff auf diese Funktion erfordert symbolische Notizbuchprogrammierung, ermöglicht aber sehr mächtige Dinge – insbesondere die Einführung von kontextbezogenen und „Just-in-Time“-Schnittstellen. Hier ist ein Beispiel, das einen dynamischen Zähler, der in Primzahlen zählt, auf den rechten unteren Teil der Zellklammer setzt:

Vorlage Box InfrastrukturManchmal ist es sinnvoll, dass das, was Sie sehen, nicht das ist, was Sie haben. So kann es z. B. sein, dass Sie etwas in einem Notizbuch als J0(x) anzeigen möchten, es aber in Wirklichkeit BesselJ[0, x] ist. Seit vielen Jahren haben wir mit Interpretation eine Möglichkeit, dies für bestimmte Ausdrücke einzurichten. Aber wir haben auch einen allgemeineren Mechanismus – die TemplateBox – mit dem Sie Ausdrücke nehmen und separat angeben können, wie sie angezeigt und interpretiert werden sollen.
In Version 12.2 haben wir die TemplateBox weiter verallgemeinert und vereinfacht, so dass sie beliebige Elemente der Benutzeroberfläche einbinden kann und auch Dinge wie das Kopierverhalten spezifizieren kann. Unser neuer TEX-Eingabemechanismus zum Beispiel ist im Grunde nur eine Anwendung der neuen TemplateBox.
In diesem Fall bezieht sich "TeXAssistantTemplate" auf eine Funktion, die im Stylesheet des Notizbuchs definiert ist und deren Parameter durch die in der TemplateBox angegebene Assoziation festgelegt werden:

Die Desktop-Schnittstelle zur Cloud
Ein wichtiges Merkmal von Wolfram Notebooks ist, dass sie sowohl auf dem Desktop als auch in der Cloud eingesetzt werden können. Und auch zwischen den einzelnen Versionen der Wolfram Language gibt es viele continued enhancement in der Art und Weise, wie Notebooks in der Cloud funktionieren. Aber in Version 12.2 wurde insbesondere die Schnittstelle für Notebooks zwischen Desktop und Cloud optimiert.
Ein besonders schöner Mechanismus, der bereits seit einigen Jahren in jedem Desktop-Notizbuch verfügbar ist, ist der Menüpunkt File > Publish to Cloud…, mit dem Sie das Notizbuch sofort als veröffentlichtes Cloud-Notizbuch zur Verfügung stellen können, auf das jeder mit einem Webbrowser zugreifen kann. In Version 12.2 haben wir den Prozess der Veröffentlichung von Notizbüchern gestrafft.
Wenn ich eine Präsentation halte, erstelle ich in der Regel nach und nach ein Desktop-Notizbuch (oder verwende vielleicht ein bereits vorhandenes). Und am Ende der Präsentation veröffentliche ich es üblicherweise in der Cloud, damit jeder im Publikum damit interagieren kann. Aber wie kann ich allen die URL für das Notizbuch geben? In einer virtuellen Umgebung kann man einfach den Chat benutzen. Aber bei einer physischen Präsentation ist das keine Option. In Version 12.2 haben wir eine bequeme Alternative geschaffen: Das Ergebnis von Publish to Cloud enthält einen QR code, den die Teilnehmer mit ihren Handys erfassen können, um dann sofort die URL aufzurufen und mit dem Notizbuch auf ihren Handys zu interagieren.
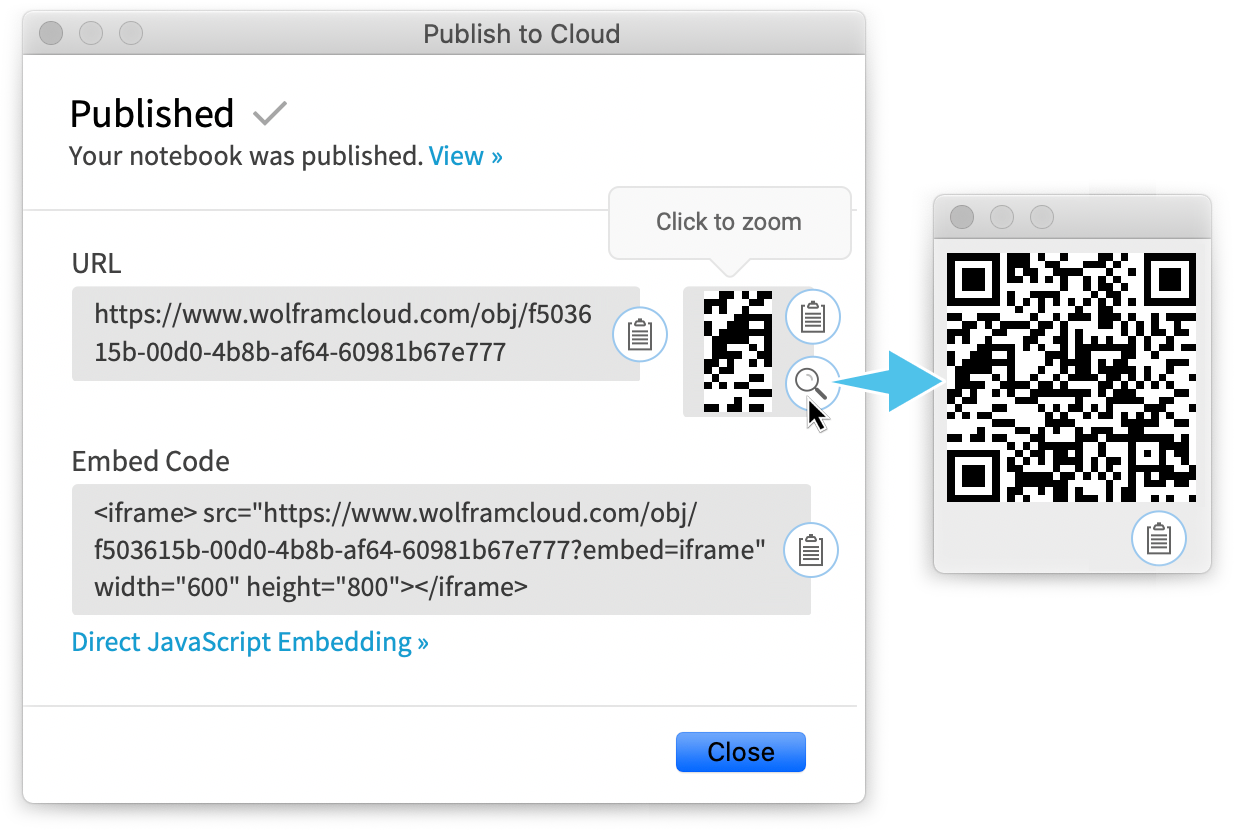
Es gibt eine weitere bemerkenswerte Neuerung, die im Ergebnis von Publish to Cloud sichtbar wird: „Direkte JavaScript-Einbettung“. Dies ist ein Link zum Wolfram Notebook Embedder, mit dem Cloud-Notebooks direkt über JavaScript in Webseiten eingebettet werden können.
Es ist immer einfach, einen iframe zu verwenden, um eine Webseite in eine andere einzubetten. Aber iframes haben viele Einschränkungen, wie z.B. dass ihre Größe im Voraus definiert werden muss. Der Wolfram Notebook Embedder ermöglicht eine voll funktionsfähige, fließende Einbettung von Cloud-Notebooks sowie eine skriptfähige Steuerung der Notebooks von anderen Elementen einer Webseite aus. Und da der Wolfram Notebook Embedder so eingerichtet ist, dass er den oEmbed-Einbettungsstandard verwendet, kann er sofort in praktisch allen Standard-Web-Content-Management-Systemen eingesetzt werden.
Wir haben bereits über das Senden von Notebooks vom Desktop in die Cloud gesprochen. Aber eine weitere Neuerung in Version 12.2 ist das schnellere und einfachere Durchsuchen Ihres Cloud-Dateisystems vom Desktop aus – wie es von File > Open from Cloud… and File > Save to Cloud…
Kryptographie und Sicherheit
Eines unserer Ziele mit der Wolfram Language ist es, die Verbindung mit so ziemlich jedem externen System so einfach wie möglich zu gestalten. Und in der heutigen Zeit ist ein wichtiger Teil davon die Möglichkeit, kryptographische Protokolle bequem zu handhaben. Und seit wir vor fünf Jahren damit begonnen haben, Kryptographie direkt in die Wolfram Language einzuführen, bin ich überrascht, wie sehr der symbolische Charakter der Wolfram Language es uns ermöglicht hat, Dinge, die mit Kryptographie zu tun haben, zu klären und zu rationalisieren.
Ein besonders dramatisches Beispiel dafür ist die Integration von Blockchains in die Wolfram Language (und in Version 12.2 kommt bloxberg hinzu, weitere sind in Vorbereitung). Und in aufeinanderfolgenden Versionen behandeln wir verschiedene Anwendungen der Kryptographie. In Version 12.2 liegt ein Schwerpunkt auf symbolischen Fähigkeiten zur Schlüsselverwaltung. In Version 12.1 wurde bereits SystemCredential für die Verwaltung lokaler „Schlüsselbund“-Schlüssel eingeführt (z.B. zur Unterstützung von „remember me“ in Authentifizierungsdialogen). In 12.2 werden wir auch mit PEM-Dateien arbeiten.
Wenn wir eine PEM-Datei importieren, die einen privaten Schlüssel enthält, erhalten wir eine schöne, symbolische Darstellung des privaten Schlüssels:
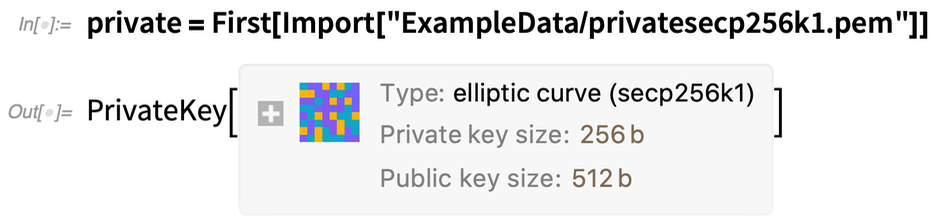
Jetzt können wir einen öffentlichen Schlüssel ableiten:

Wenn wir eine digitale Signatur für eine Nachricht unter Verwendung des privaten Schlüssels erzeugen

dann wird die Unterschriftmit dem abgeleiteten öffentlichen Schlüssel überprüft:

Ein wichtiger Bestandteil der modernen Sicherheitsinfrastruktur ist das Konzept des Sicherheitszertifikats – ein digitales Konstrukt, das es einem Dritten ermöglicht, die Echtheit eines bestimmten öffentlichen Schlüssels zu bestätigen. In Version 12.2 gibt es nun eine symbolische Darstellung für Sicherheitszertifikate, die es Programmen ermöglicht, sichere Kommunikationskanäle mit externen Stellen einzurichten, ähnlich wie es bei https der Fall ist:
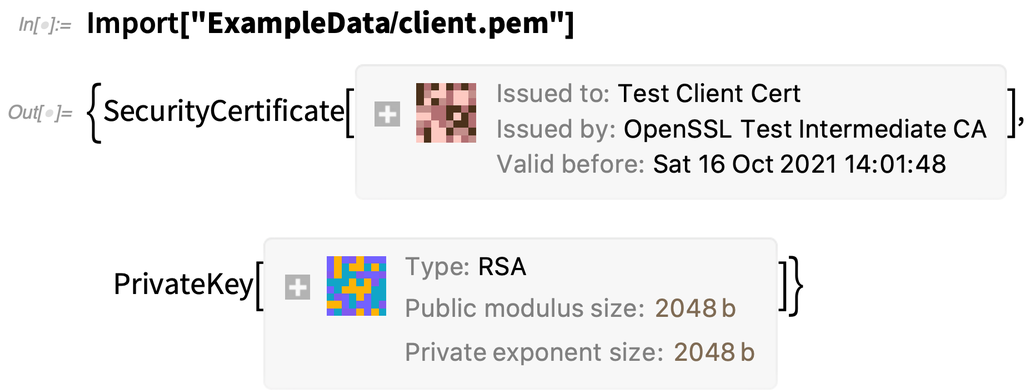
Einfach SQL eingeben
In Version 12.0 haben wir leistungsstarke Funktionen für die symbolische Abfrage von relationalen Datenbanken in der Wolfram Language eingeführt. Hier sehen Sie, wie wir uns mit einer Datenbank verbinden:

So verbinden wir die Datenbank, so dass ihre Tabellen wie Entity-Typen aus der integrierten Wolfram Knowledgebase behandelt werden können:

Jetzt können wir zum Beispiel nach einer Liste von Entitäten eines bestimmten Typs fragen:

Neu in 12.2 ist, dass wir bequem „unter“ diese Schicht gehen können, um SQL-Abfragen direkt gegen die zugrunde liegende Datenbank auszuführen und die komplette Datenbanktabelle als Dataset-Ausdruck zu erhalten:
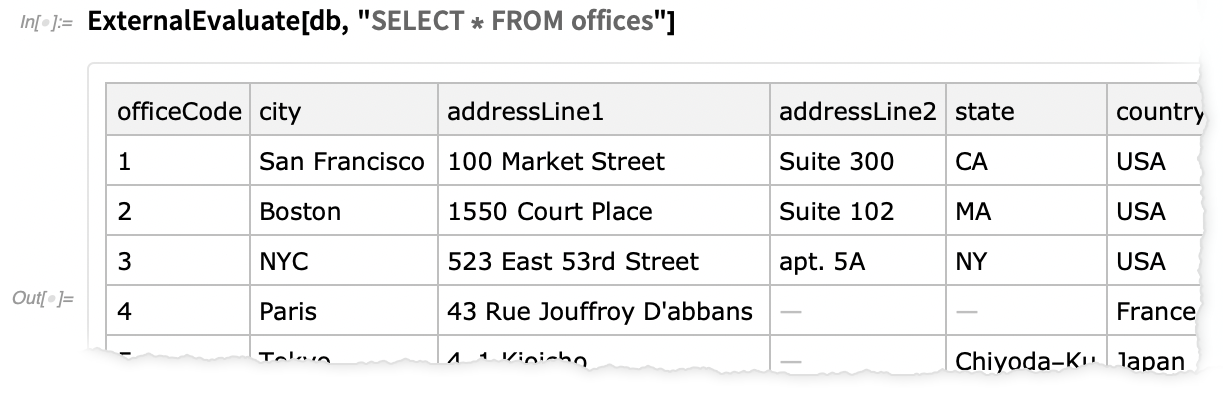
Diese Abfragen können nicht nur aus der Datenbank lesen, sondern auch in sie schreiben. Und um die Sache noch bequemer zu machen, können wir SQL in einem Notebook praktisch wie jede andere „externe Sprache“ behandeln.
Zunächst müssen wir unsere Datenbank registrieren, um zu sagen, gegen was wir unser SQL laufen lassen wollen:

Und jetzt können wir einfach SQL als Eingabe eingeben – und erhalten die Wolfram Language-Ausgabe direkt im Notebook zurück:

Mikrocontroller-Unterstützung wird auf 32 Bit erweitert
Sie haben ein Steuerungssystem oder eine Signalverarbeitung in der Wolfram Language entwickelt. Wie setzen Sie es nun auf einer eigenständigen Elektronikeinheit ein? In Version 12.0 haben wir das Microcontroller-Kit eingeführt, mit dem Sie aus symbolischen Wolfram Language-Strukturen direkt in Mikrocontroller-Code kompilieren können.
Wir haben viele Rückmeldungen erhalten, in denen wir gebeten wurden, die Palette der von uns unterstützten Mikrocontroller zu erweitern. Daher freue ich mich, Ihnen mitteilen zu können, dass wir in Version 12.2 die Unterstützung für 36 neue Mikrocontroller, insbesondere 32-Bit-Mikrocontroller, hinzufügen werden:

Hier ist ein Beispiel, in dem wir einen symbolisch definierten digitalen Filter für einen bestimmten Mikrocontroller einsetzen und den vereinfachten C-Quellcode zeigen, der für diesen speziellen Mikrocontroller erzeugt wurde:
![]()


WSTPServer: Ein neuer Einsatz der Wolfram Engine
Unser langfristiges Ziel ist es, die Wolfram Language und die von ihr bereitgestellte Rechenintelligenz so allgegenwärtig wie möglich zu machen. Dazu gehört auch die Einrichtung der Wolfram Engine, die die Sprache so implementiert, dass sie in einer möglichst breiten Palette von Recheninfrastrukturen eingesetzt werden kann.
Wolfram Desktop – wie auch das klassische Mathematica – bieten in erster Linie eine Notebook-Schnittstelle zur Wolfram Engine, die auf einem lokalen Desktop-System läuft. Es ist auch möglich, die Wolfram Engine direkt als Kommandozeilenprogramm (z. B. über WolframScript) auf einem lokalen Computersystem auszuführen. Und natürlich kann man die Wolfram Engine in der Cloud betreiben, entweder über die vollständige Wolfram Cloud (öffentlich oder privat) oder über leichtere Cloud- und Server-Angebote (sowohl bestehende als auch künftige).
Aber mit Version 12.2 gibt es einen neuen Einsatz der Wolfram Engine: WSTPServer. Wenn Sie die Wolfram Engine in der Cloud verwenden, kommunizieren Sie normalerweise über http oder ähnliche Protokolle mit ihr. Aber seit mehr als dreißig Jahren hat die Wolfram Language ihr eigenes Protokoll für die Übertragung von symbolischen Ausdrücken und allem, was damit zusammenhängt. Ursprünglich nannten wir es MathLink, aber in den letzten Jahren, als es nach und nach erweitert wurde, haben wir es WSTP genannt: das Wolfram Symbolic Transfer Protocol. WSTPServer ist, wie der Name schon sagt, ein leichtgewichtiger Server, der die Wolfram-Engines bereitstellt und Sie direkt mit ihnen in
Warum ist das wichtig? Grundsätzlich, weil es Ihnen eine Möglichkeit gibt, Pools von persistenten Wolfram Language-Sitzungen zu verwalten, die als Dienste für andere Anwendungen dienen können. Zum Beispiel erhalten Sie normalerweise jedes Mal, wenn Sie WolframScript aufrufen, eine neue, frische Wolfram Engine. Aber durch die Verwendung von wolframscript -wstpserver mit einem bestimmten „WSTP-Profilnamen“ kann man jedes Mal, wenn man WolframScript aufruft, die gleiche Wolfram-Engine erhalten. Sie können dies direkt auf Ihrem lokalen Rechner tun – oder auf entfernten Rechnern.
Eine wichtige Anwendung von WSTPServer ist die Bereitstellung von Wolfram-Engine-Pools, auf die über die neue RemoteEvaluate-Funktion in Version 12.2 zugegriffen werden kann. Es ist auch möglich, WSTPServer zu verwenden, um Wolfram Engines zur Verwendung durch ParallelMap usw. freizugeben. Und schließlich, da WSTP (seit fast 30 Jahren!) die Art und Weise ist, wie das Notebook-Frontend mit dem Wolfram-Engine-Kernel kommuniziert, ist es jetzt möglich, WSTPServer zu verwenden, um einen zentralisierten Kernel-Pool einzurichten, mit dem Sie das Notebook-Frontend verbinden können, so dass Sie zum Beispiel eine bestimmte Sitzung (oder sogar eine bestimmte Berechnung) im Kernel weiterlaufen lassen können, auch wenn Sie zu einem anderen Notebook-Frontend auf einem anderen Computer wechseln.
RemoteEvaluate: Berechnen Sie irgendwo anders…
Ganz nach dem Motto „Wolfram Language überall verwenden“ ist eine weitere neue Funktion in Version 12.2 RemoteEvaluate. Wir haben CloudEvaluate, das eine Berechnung in der Wolfram Cloud oder einer Enterprise Private Cloud durchführt. Wir haben ParallelEvaluate, das Berechnungen auf einer vordefinierten Sammlung von parallelen Subkernels durchführt. Und in Version 12.2 haben wir RemoteBatchSubmit, das Batch-Berechnungen an Cloud-Berechnungsanbieter übermittelt.
RemoteEvaluate is a general, lightweight “evaluate now” function that lets you do a computation on any specified remote machine that has an accessible Wolfram Engine. You can connect to the remote machine using ssh or wstp (or http with a Wolfram Cloud endpoint).

Manchmal werden Sie RemoteEvaluate verwenden wollen, um Dinge wie die Systemadministration über eine Reihe von Rechnern hinweg durchzuführen. Manchmal möchten Sie vielleicht Daten sammeln oder an entfernte Geräte senden. Zum Beispiel könnten Sie ein Netzwerk von Raspberry Pi Computern haben, die alle mit der Wolfram Engine ausgestattet sind – und dann können Sie RemoteEvaluate verwenden, um Daten von diesen Maschinen abzurufen. Übrigens können Sie ParallelEvaluate auch innerhalb von RemoteEvaluate verwenden, so dass Sie einen entfernten Rechner als Master für eine Sammlung paralleler Subkerne verwenden.
Manchmal möchten Sie, dass RemoteEvaluate eine neue Instanz der Wolfram Engine startet, wenn Sie eine Auswertung durchführen. Aber mit WSTPServer können Sie auch eine persistente Wolfram Language Sitzung verwenden. RemoteEvaluate und WSTPServer sind der Anfang eines allgemeinen symbolischen Frameworks zur Darstellung laufender Wolfram-Engine-Prozesse. Version 12.2 hat bereits RemoteKernelObject und $DefaultRemoteKernel, die symbolische Wege zur Darstellung von entfernten Wolfram Language Instanzen bieten.
Und noch mehr (AKA “Keines der oben genannten”)
Ich habe zumindest berührt auf viele der größeren neuen Funktionen der Version 12.2. Aber es gibt noch viel mehr. Zusätzliche Funktionen, Verbesserungen, Fehlerbehebungen und allgemeines Abrunden und Polieren.
Wie in der numerischen Geometrie befasst sich ConvexHullRegion nun mit Regionen, nicht nur mit Punkten. Und es gibt Funktionen wie CollinearPoints und CoplanarPoints, die auf Kollinearität und Koplanarität prüfen oder Bedingungen für deren Erreichen angeben.
Es gibt mehr Import- und Exportformate. Wie there’s jetzt Unterstützung für die Archivformate: „7z„, „ISO„, „RAR„, „ZSTD„. Außerdem gibt es FileFormatQ und ByteArrayFormatQ um zu testen, ob etwas einem bestimmten Format entspricht.
In Bezug auf die Kernsprache gibt es Dinge wie Aktualisierungen des kompliziert zu definierenden ValueQ. Außerdem gibt es RandomGeneratorState, das eine symbolische Darstellung von Zufallsgeneratorzuständen bietet.
Im Editor des Desktop-Pakets (d.h. der .wl-Datei) gibt es eine neue (etwas experimentelle) Schaltfläche „Zelle formatieren„, die den Code neu formatiert – mit einer Kontrolle darüber, wie „luftig“ er sein soll (d.h. wie dicht er an Zeilenumbrüchen sein soll).
In Wolfram|Alpha-Mode-Notebooks (wie sie standardmäßig in der Wolfram|Alpha Notebook Edition verwendet werden) gibt es weitere neue Features, wie z.B. Funktionsdokumentation, die auf eine bestimmte Funktionsverwendung ausgerichtet ist.
Außerdem gibt es mehr in TableView sowie eine große Anzahl neuer Paclet-Authoring-Tools, die auf experimenteller Basis enthalten sind.
Ich finde es erstaunlich, wie viel wir in der Version 12.2 zusammenbringen konnten, und wie immer freue ich mich, dass sie jetzt verfügbar ist und von allen genutzt werden kann…