Lancement de la version 12.2 de Wolfram Language & Mathematica : 228 nouvelles fonctions et bien plus encore…
Mais plus grand que jamais
Lorsque nous avons publié la version 12.1 en mars de cette année, j’étais heureux de pouvoir dire qu’avec ses 182 nouvelles fonctions, il s’agissait de la plus importante version .1 que nous ayons jamais publiée. Mais à peine neuf mois plus tard, nous avons une version .1 encore plus importante ! La version 12.2, lancée aujourd’hui, comporte 228 fonctions entièrement nouvelles !

Nous avons toujours un portefeuille de projets de développement en cours, dont la réalisation peut prendre de quelques mois à plus de dix ans. Et bien sûr, c’est un hommage à l’ensemble de notre pile technologique Wolfram Language que nous soyons capables de développer autant, si rapidement. Mais la version 12.2 est peut-être d’autant plus impressionnante que nous ne nous sommes pas concentrés sur son développement final avant la mi-juin de cette année. En effet, entre mars et juin, nous nous sommes concentrés sur la 12.1.1, qui était une « version de polissage ». Pas de nouvelles fonctionnalités, mais plus de mille bogues corrigés (le plus ancien étant un bogue de documentation datant de 1993) :

Comment avons-nous conçu toutes ces nouvelles fonctions et ces nouvelles caractéristiques qui se trouvent maintenant dans la 12.2 ? C’est beaucoup de travail ! Et c’est ce à quoi je consacre personnellement beaucoup de temps (avec d’autres « petits éléments » comme la physique, etc.). Mais ces deux dernières années, nous avons conçu notre langage de manière très ouverte, en diffusant en direct nos discussions internes sur la conception et en recevant toutes sortes de commentaires intéressants en temps réel. Jusqu’à présent, nous avons enregistré environ 550 heures – dont la version 12.2 a occupé au moins 150 heures.
À propos, en plus de toutes les nouvelles fonctionnalités entièrement intégrées dans la version 12.2, le Wolfram Function Repository a également connu une activité importante. En effet, depuis la sortie de la version 12.1, 534 nouvelles fonctions sélectionnées pour toutes sortes d’applications spécialisées y ont été ajoutées.
Séquences biomoléculaires : ADN symbolique, protéines, etc.
Il y a tant de choses différentes dans tant de domaines dans la version 12.2 qu’il est difficile de savoir par où commencer. Mais parlons d’un domaine complètement nouveau : calcul de la bioséquence.Oui, nous avons des données sur les gènes et les protéines dans le langage Wolfram depuis plus d’une décennie. Mais ce qui est nouveau dans la version 12.2, c’est le début de la possibilité d’effectuer des calculs flexibles et généraux avec des séquences biologiques. Et ce, d’une manière qui s’intègre à toutes les capacités de calcul chimique que nous avons ajoutées au langage Wolfram au cours des dernières années.
Voici comment nous représentons une séquence d’ADN (et, oui, cela fonctionne aussi avec de très longues séquences) :

|
Celui-ci traduit la séquence en un peptide (comme un « ribosome symbolique ») :
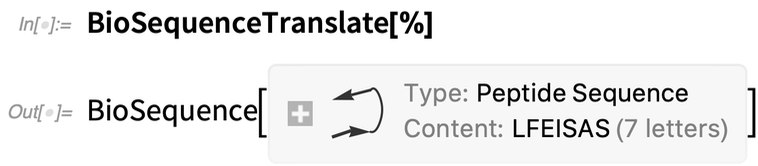
|
Maintenant, nous pouvons trouver quelle est la molécule correspondante :
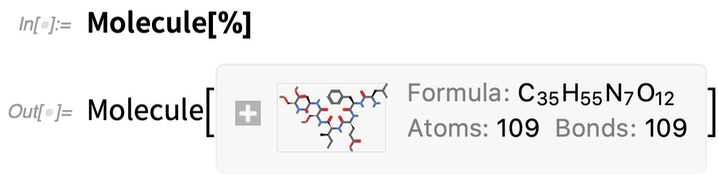
|
Et le visualiser en 3D (ou calculer de nombreuses propriétés) :
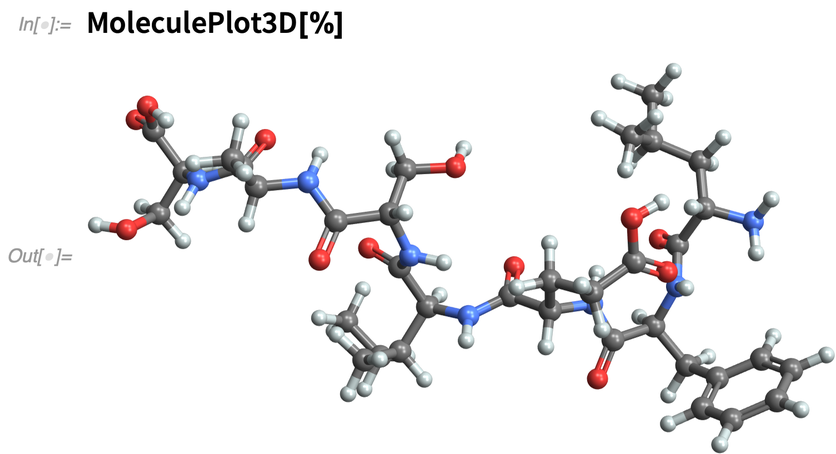
|

|
Vous pourriez penser que la manipulation des séquences génomiques n’est qu’une « simple manipulation de chaînes de caractères » – et en effet, nos fonctions de chaînes de caractères sont maintenant configurées pour travailler avec des séquences biologiques:
 |
Mais il y a aussi beaucoup de fonctionnalités supplémentaires spécifiques à la biologie. Comme ceci trouve une séquence de paires de bases complémentaires :

|
Les séquences réelles et expérimentales comportent souvent des paires de bases incertaines, et il existe des conventions standard pour les représenter (par exemple, « S » signifie C ou G ; « N » signifie toute base). Et maintenant, nos modèles de chaînes de caractères comprennent aussi des choses comme ça pour les bio-séquences :

|

|
BioSequence est également complètement intégrée à nos données intégrées sur le génome et les protéines. Voici un gène que nous pouvons demander en langage naturel « à la Wolfram|Alpha« :
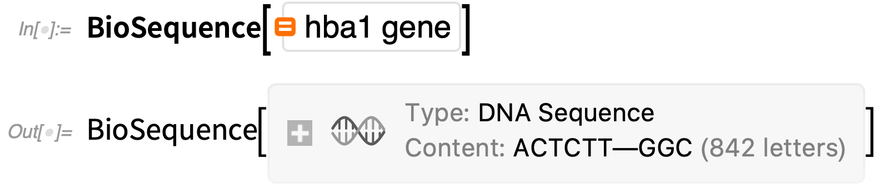 |
Nous demandons maintenant de faire un alignement de séquences entre ces deux gènes (dans ce cas, tous deux humains – ce qui est, inutile de le dire, la valeur par défaut) :
 |
Le contenu de la version 12.2 n’est que le début de ce que nous prévoyons pour le calcul des bioséquences. Mais vous pouvez déjà faire des choses très souples avec de grands ensembles de données. Par exemple, il est maintenant très simple pour moi de lire mon génome à partir de fichiers FASTA et de commencer à l’explorer…
 |
Statistiques et modélisation spatiales
Emplacements des nids d’oiseaux, des gisements d’or, des maisons à vendre, des défauts d’un matériau, des galaxies…. Ce sont tous des exemples d’ensembles de données ponctuelles spatiales. Dans la version 12.2, nous disposons désormais d’un large éventail de fonctions permettant de traiter ces ensembles de données.
Voici les « données spatiales ponctuelles » pour les emplacements des capitales des États américains :
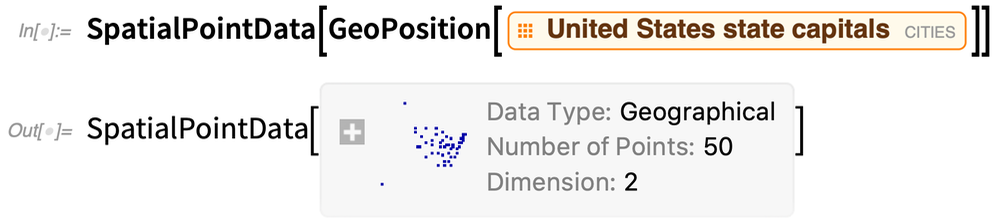 |
Comme il s’agit de données géographiques, elles sont reportées sur une carte :
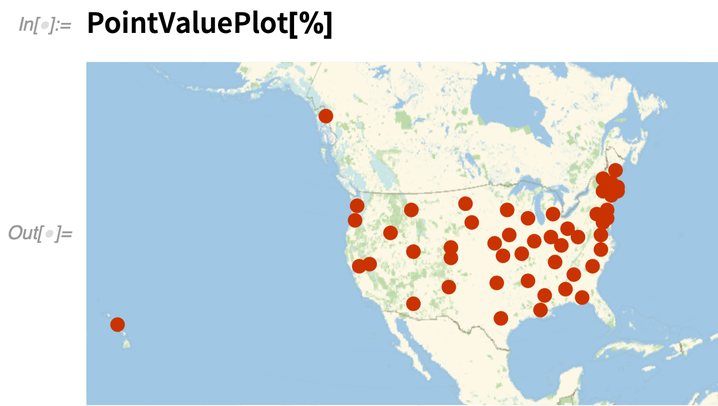 |
Limitons notre domaine aux États-Unis contigus :
 |
 |
Maintenant, nous pouvons commencer à calculer des statistiques spatiales. Comme ici la densité moyenne des capitales des états :
 |
Supposons que vous êtes dans la capitale d’un État. Voici la probabilité de trouver l’autre capitale d’État la plus proche à une certaine distance :
 |
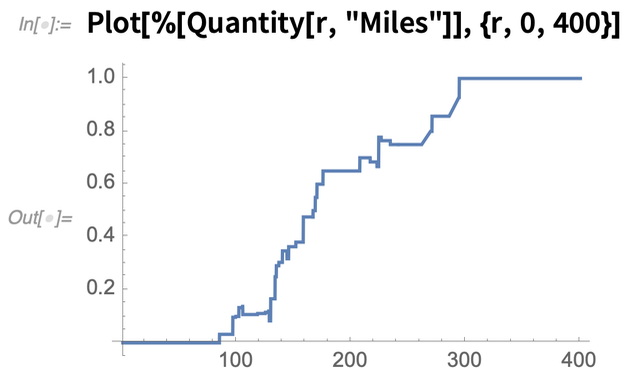 |
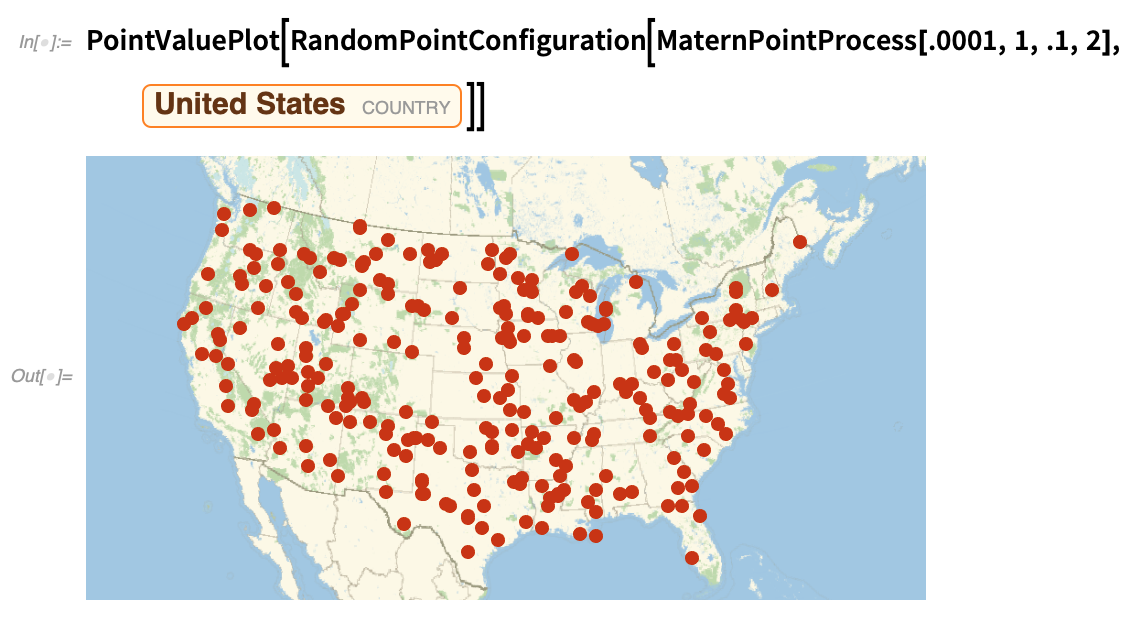
Cela permet de vérifier si les capitales des États sont distribuées de manière aléatoire ; inutile de dire qu’elles ne le sont pas :
 |
 |
Vous pouvez également faire l’inverse et dapter un modèle spatial aux données :
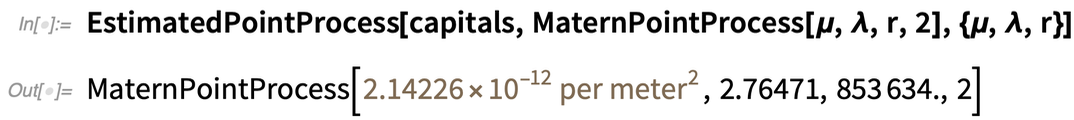 |
EDP pratiques dans le monde réel
D’une certaine manière, nous y travaillons depuis 30 ans. Nous avons présenté NDSolve pour la première fois dans la Version 2.0, et nous l’avons constamment amélioré depuis. Mais notre objectif à long terme a toujours été la manipulation pratique des EDP du monde réel, du type de celles qui apparaissent dans l’ingénierie haut de gamme. Et dans la version 12.2, nous avons finalement obtenu tous les éléments de la technologie algorithmique sous-jacente pour pouvoir créer une expérience de résolution d’EDP vraiment rationalisée.
OK, alors comment spécifier une EDP ? Dans le passé, cela était toujours fait explicitement en termes de dérivées particulières, de conditions aux limites, etc. Mais la plupart des EDP utilisées par exemple en ingénierie consistent en des composants de plus haut niveau qui « regroupent » les dérivées, les conditions aux limites, etc. pour représenter les caractéristiques de la physique, des matériaux, etc.
Le niveau le plus bas de notre nouveau cadre d’EDP est constitué de « termes » symboliques, correspondant aux constructions mathématiques courantes qui apparaissent dans les EDP du monde réel. Par exemple, voici un « terme Laplacien » 2D :
 |
Et voilà, c’est tout ce qu’il faut pour trouver les 5 premières valeurs propres du Laplacien dans un polygone régulier :
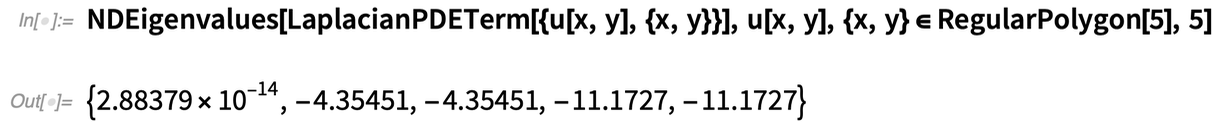 |
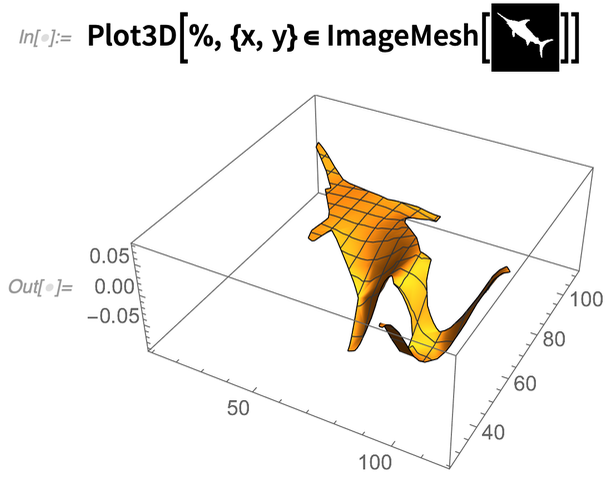
Et la chose importante est que vous pouvez mettre ce genre d’opération dans un pipeline entier. Comme ici, nous obtenons la région d’une image, nous résolvons le 10e mode propre, puis nous traçons le résultat en 3D :
 |
 |
 |
Au-delà des termes individuels, il existe également des « composants » qui combinent plusieurs termes, généralement avec divers paramètres. Voici une composante PDE de Helmholtz :
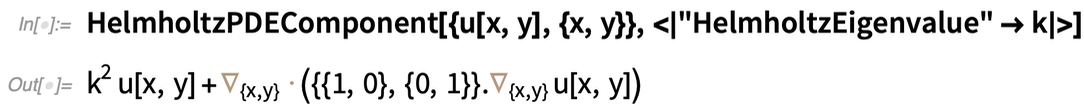 |
À propos, il est utile de souligner que nos « termes » et « composants » sont conçus pour représenter la structure symbolique des EDP sous une forme adaptée à la manipulation structurelle et à des choses comme l’analyse numérique. Et pour s’assurer qu’ils conservent leur structure, ils sont normalement conservés sous une forme inactivée. Mais vous pouvez toujours les « activer » si vous voulez faire des choses comme des opérations algébriques :
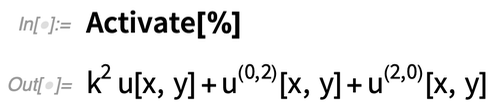 |
Dans les EDP du monde réel, on a souvent affaire à des processus physiques réels qui se déroulent dans des matériaux physiques réels. Et dans la version 12.2, nous avons des moyens immédiats de traiter non seulement des choses comme la diffusion, mais aussi l’acoustique, le transfert de chaleur et le transport de masse — et d’introduire les propriétés des matériaux réels. En général, la structure est la suivante : un » composant » d’EDP qui représente le comportement global du matériau, ainsi qu’une variété de » valeurs » ou de » conditions » d’EDP qui représentent les conditions limites.
Voici un composant PDE typique, utilisant les propriétés des matériaux de la Wolfram Knowledgebase :
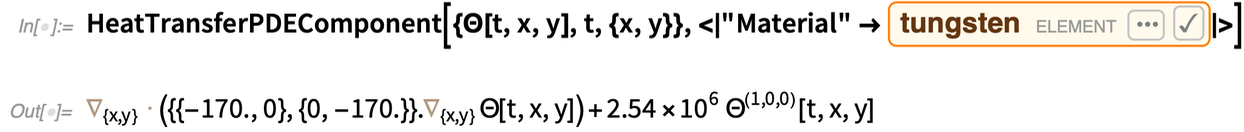 |
Les conditions aux limites possibles sont assez diverses et complexes. Par exemple, pour le transfert de chaleur, il existe HeatFluxValue, HeatInsulationValue et cinq autres constructions symboliques de spécification des conditions aux limites. Dans chaque cas, l’idée de base est de dire où (géométriquement) la condition s’applique, puis à quoi elle s’applique, et quels paramètres s’y rapportent.
Ainsi, par exemple, voici une condition qui spécifie qu’il existe une « température de surface » fixe θ0partout en dehors de la région (circulaire) définie par x2 + y2 = 1:
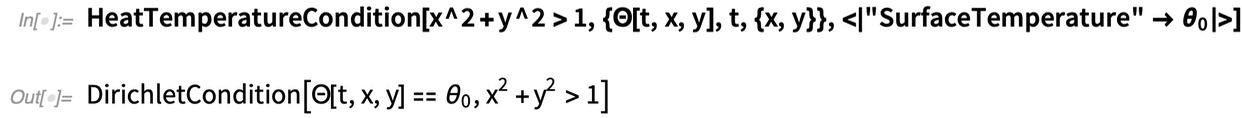 |
Ce qui se passe ici, c’est que notre description « physique » de haut niveau est « compilée » en structures d’EDP « mathématiques » explicites, comme les conditions limites de Dirichlet.
OK, alors comment tout cela s’articule-t-il dans une situation réelle ? Laissez-moi vous montrer un exemple. Mais d’abord, laissez-moi vous raconter une histoire. En 2009, je prenais le thé avec notre principal développeur PDE. J’ai pris une cuillère à café et j’ai demandé : « Quand pourrons-nous modéliser les contraintes dans ce modèle ? » Notre développeur principal m’a expliqué qu’il y avait pas mal de choses à construire pour en arriver là. Eh bien, je suis heureux de vous annoncer qu’après 11 ans de travail, nous y sommes arrivés avec la version 12.2. Et pour le prouver, notre développeur principal vient de me donner… une cuillère (de calcul) !

Le cœur du calcul est un terme PDE de diffusion 3D, avec un « coefficient de diffusion » donné par un tenseur de rang 4 paramétré par le module de Young (ici Y) et le coefficient de Poisson (ν):

Il y a des conditions aux limites pour spécifier comment la cuillère est tenue, et poussée. Ensuite, la résolution de l’EDP (qui ne prend que quelques secondes) donne le champ de déplacement de la cuillère


La modélisation des EDP est un domaine complexe, et je considère comme une réussite majeure le fait que nous ayons réussi à l' »emballer » aussi proprement que cela. Mais dans la version 12.2, en plus de la technologie réelle de la modélisation des EDP, une autre chose importante est une grande collection d’essais informatiques sur la modélisation des EDP — en tout, environ 400 pages d’explications détaillées et d’exemples d’application, actuellement en acoustique, transfert de chaleur et transport de masse, mais avec de nombreux autres domaines à venir.
Tapez simplement TEX
Le langage Wolfram consiste à s’exprimer dans un langage informatique précis. Mais dans les carnets, vous pouvez également vous exprimer avec du texte ordinaire en langage naturel. Mais que faire si vous souhaitez également y afficher des mathématiques ? Depuis 25 ans, nous disposons de l’infrastructure nécessaire à l’affichage des mathématiques, grâce à notre langage de boîte. Mais le seul moyen pratique de saisir les mathématiques est de passer par des constructions mathématiques en langage Wolfram, qui, dans un certain sens, doivent avoir une signification informatique.
Mais qu’en est-il des « mathématiques » qui ne sont « que pour les yeux humains » ? Elles ont une certaine présentation visuelle que vous voulez spécifier, mais elles n’ont pas nécessairement de signification computationnelle sous-jacente particulière qui a été définie. Eh bien, depuis plusieurs décennies, il existe un bon moyen de spécifier de telles mathématiques, grâce à mon ami Don Knuth: il suffit d’utiliser TEX. Et dans la version 12.2, nous prenons désormais en charge l’entrée directe des mathématiques TEX dans les Wolfram Notebooks, à la fois sur le bureau et dans le nuage. En dessous, le TEX est transformé en notre représentation en boîte, de sorte qu’il interagit structurellement avec tout le reste. Mais vous pouvez simplement le saisir – et l’éditer – en tant que TEX.
L’interface ressemble beaucoup à l’interface ctrl+= pour la saisie en langage naturel de type Wolfram|Alpha. Mais pour TEX (dans un clin d’œil aux délimiteurs TEX standard), c’est ctrl>+$.
Tapez ctrl+$ et vous obtenez une boîte de saisie TEX. Lorsque vous avez terminé le TEX, appuyez simplement sur ctrl et il sera rendu :

La saisie de TEX dans des cellules de texte est la chose la plus courante à vouloir. Mais la version 12.2 permet également de saisir des TEX dans des cellules de saisie :

Dessinez n’importe quoi
Tapez Canvas[] et vous obtiendrez une toile vierge pour dessiner ce que vous voulez :
![Canvas[]](https://sciexperts.com/wp-content/uploads/2022/04/just-draw-anything-canvas-02.png)
Nous avons travaillé dur pour rendre les outils de dessin aussi ergonomiques que possible.
L’application de Normal vous donne des graphiques que vous pouvez ensuite utiliser ou manipuler :

Lorsque vous créez un canevas, il peut avoir n’importe quel graphique comme contenu initial – et il peut avoir n’importe quel arrière-plan que vous voulez :


C’est une autre molécule maintenant :
![]()

L’histoire sans fin des mathématiques
Les mathématiques constituent un cas d’utilisation essentiel du langage Wolfram (et Mathematica) depuis le début. Au cours du dernier tiers de siècle, il a été très satisfaisant de voir la quantité de mathématiques que nous avons réussi à rendre informatique. Mais plus nous en faisons, plus nous réalisons que c’est possible, et plus nous pouvons aller loin. C’est devenu en quelque sorte une routine pour nous. Il y aura un domaine des mathématiques que les gens ont toujours fait à la main ou de manière fragmentaire. Et nous nous rendrons compte : oui, nous pouvons faire un algorithme pour cela ! Nous pouvons utiliser la tour géante de capacités que nous avons construite au cours de toutes ces années pour systématiser et automatiser encore plus de mathématiques, pour rendre encore plus de mathématiques accessibles à tous par le calcul. Et c’est ce qui s’est passé avec la version 12.2. Toute une collection de pièces du « progrès mathématique ».
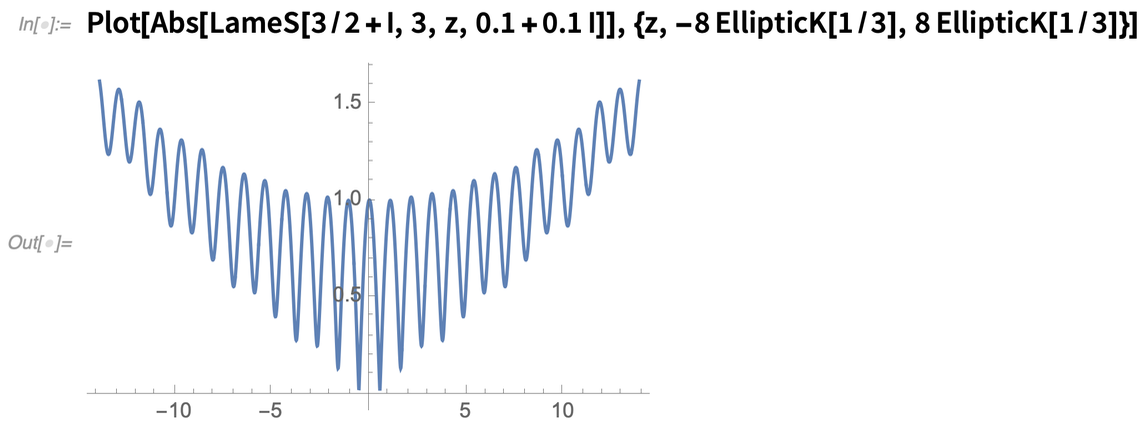
Commençons par quelque chose d’assez simple : les fonctions spéciales. Dans un sens, chaque fonction spéciale est une encapsulation d’une certaine pépite de mathématiques : une façon de définir des calculs et des propriétés pour un type particulier de problème ou de système mathématique. Depuis Mathematica 1.0, nous avons obtenu une excellente couverture des fonctions spéciales, qui s’étend régulièrement à des fonctions de plus en plus complexes. Et dans la version 12.2, nous disposons d’une nouvelle classe de fonctions : les fonctions de Lamé.
Les fonctions de Lamé font partie du monde complexe de la manipulation des coordonnées elliptiques ; elles apparaissent comme des solutions à l’équation de Laplace dans un ellipsoïde. Nous pouvons maintenant les évaluer, les développer, les transformer et faire toutes les autres choses nécessaires à l’intégration d’une fonction dans notre langage :

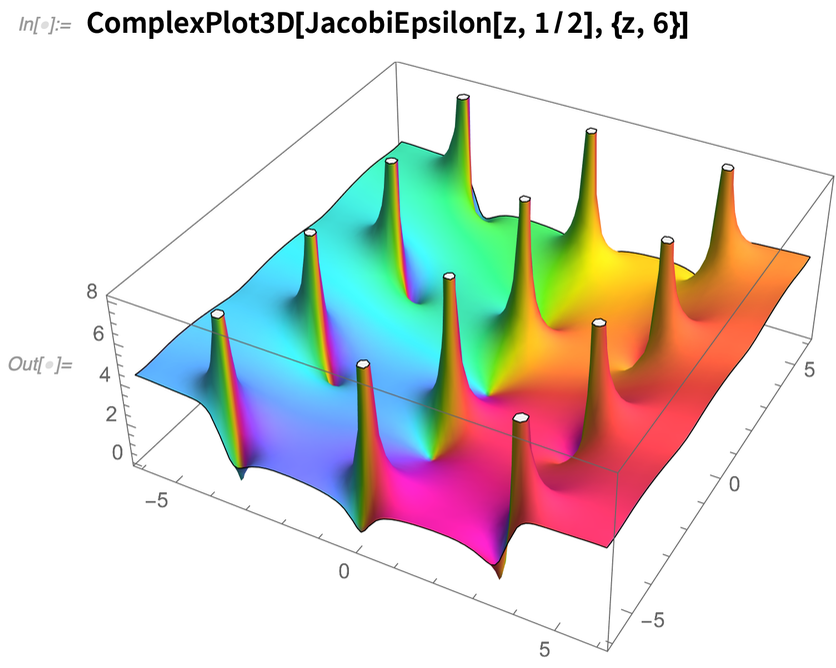
Dans la version 12.2, nous avons également beaucoup travaillé sur les fonctions elliptiques, en accélérant de façon spectaculaire leur évaluation numérique et en inventant des algorithmes efficaces pour une précision arbitraire. Nous avons également introduit quelques nouvelles fonctions elliptiques, comme JacobiEpsilon, qui fournit une généralisation d’EllipticE qui évite les coupures de branche et maintient la structure analytique des intégrales elliptiques :
Depuis une vingtaine d’années, nous sommes en mesure d’effectuer de nombreuses transformations symboliques de Laplace et de Laplace inverse. Mais dans la version 12.2, nous avons résolu le problème subtil de l’utilisation de l’intégration des contours pour effectuer des transformées de Laplace inverses. Il s’agit de connaître suffisamment la structure des fonctions dans le plan complexe pour éviter les coupures de branche et autres singularités désagréables. Un résultat typique est en fait une somme sur un nombre infini de pôles :

Et entre l’intégration des contours et les autres méthodes, nous avons également ajouté les transformées de Laplace inverses numériques. Tout cela semble facile au final, mais un travail algorithmique complexe est nécessaire pour y parvenir :
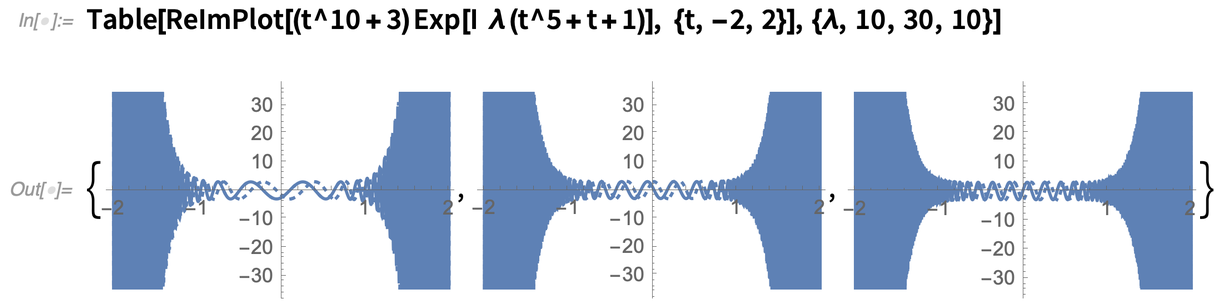
 Un autre nouvel algorithme rendu possible par une « compréhension des fonctions » plus fine a trait à l’expansion asymptotique des intégrales. Voici une fonction complexe qui devient de plus en plus ondulante lorsque λ augmente :
Un autre nouvel algorithme rendu possible par une « compréhension des fonctions » plus fine a trait à l’expansion asymptotique des intégrales. Voici une fonction complexe qui devient de plus en plus ondulante lorsque λ augmente :
Et voici l’expansion asymptotique pour λ→∞ :
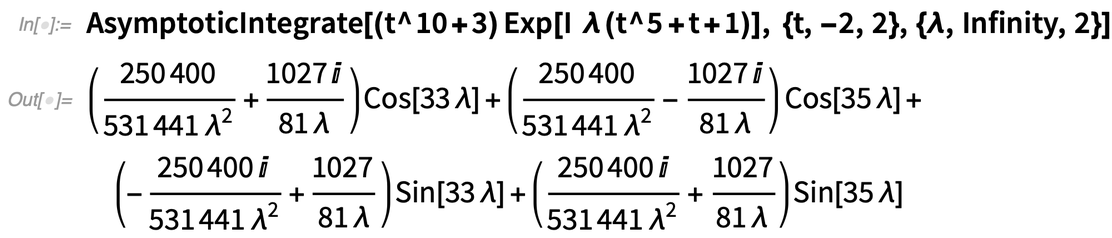
Parlez-moi de cette fonction
C’est un exercice de calcul très courant que de déterminer, par exemple, si une fonction particulière est injective. Et il est assez simple de le faire dans les cas faciles. Mais un grand pas en avant dans la version 12.2 est que nous pouvons maintenant déterminer systématiquement ce genre de propriétés globales des fonctions, non seulement dans les cas faciles, mais aussi dans les cas très difficiles. Il existe souvent des réseaux entiers de théorèmes qui dépendent de fonctions ayant telle ou telle propriété. Eh bien, nous pouvons maintenant déterminer automatiquement si une fonction particulière possède cette propriété, et donc si les théorèmes sont valables pour elle. Et cela signifie que nous pouvons créer des algorithmes systématiques qui utilisent automatiquement les théorèmes lorsqu’ils s’appliquent.
Voici un exemple. Tan[x] est-elle injective ? Pas globalement :

Mais sur un intervalle, oui :
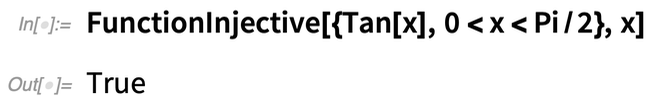
Et les singularités de Tan[x] ? Cela donne une description de l’ensemble :
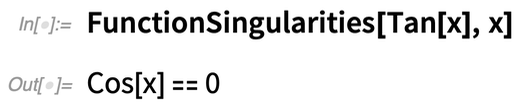 Vous pouvez obtenir des valeurs explicites avec Reduce:
Vous pouvez obtenir des valeurs explicites avec Reduce:
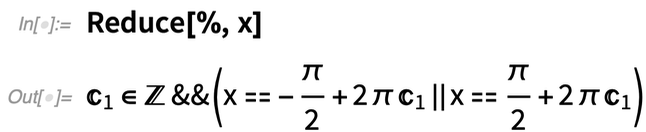
Jusqu’ici, c’est assez simple. Mais les choses se compliquent rapidement :
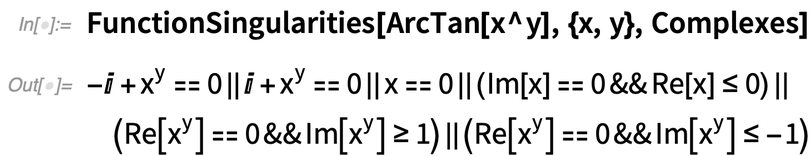
Et il existe également des propriétés plus sophistiquées que vous pouvez demander :

 Depuis longtemps, nous utilisons en interne différents types de propriétés de test de fonction. Mais avec la version 12.2, les propriétés de fonction sont beaucoup plus complètes et entièrement exposées pour que chacun puisse les utiliser. Vous voulez savoir si vous pouvez interchanger l’ordre de deux limites ? Vérifiez FunctionSingularities. Vous voulez savoir si vous pouvez effectuer un changement multivarié de variables dans une intégrale ? Vérifiez FunctionInjective.
Depuis longtemps, nous utilisons en interne différents types de propriétés de test de fonction. Mais avec la version 12.2, les propriétés de fonction sont beaucoup plus complètes et entièrement exposées pour que chacun puisse les utiliser. Vous voulez savoir si vous pouvez interchanger l’ordre de deux limites ? Vérifiez FunctionSingularities. Vous voulez savoir si vous pouvez effectuer un changement multivarié de variables dans une intégrale ? Vérifiez FunctionInjective.
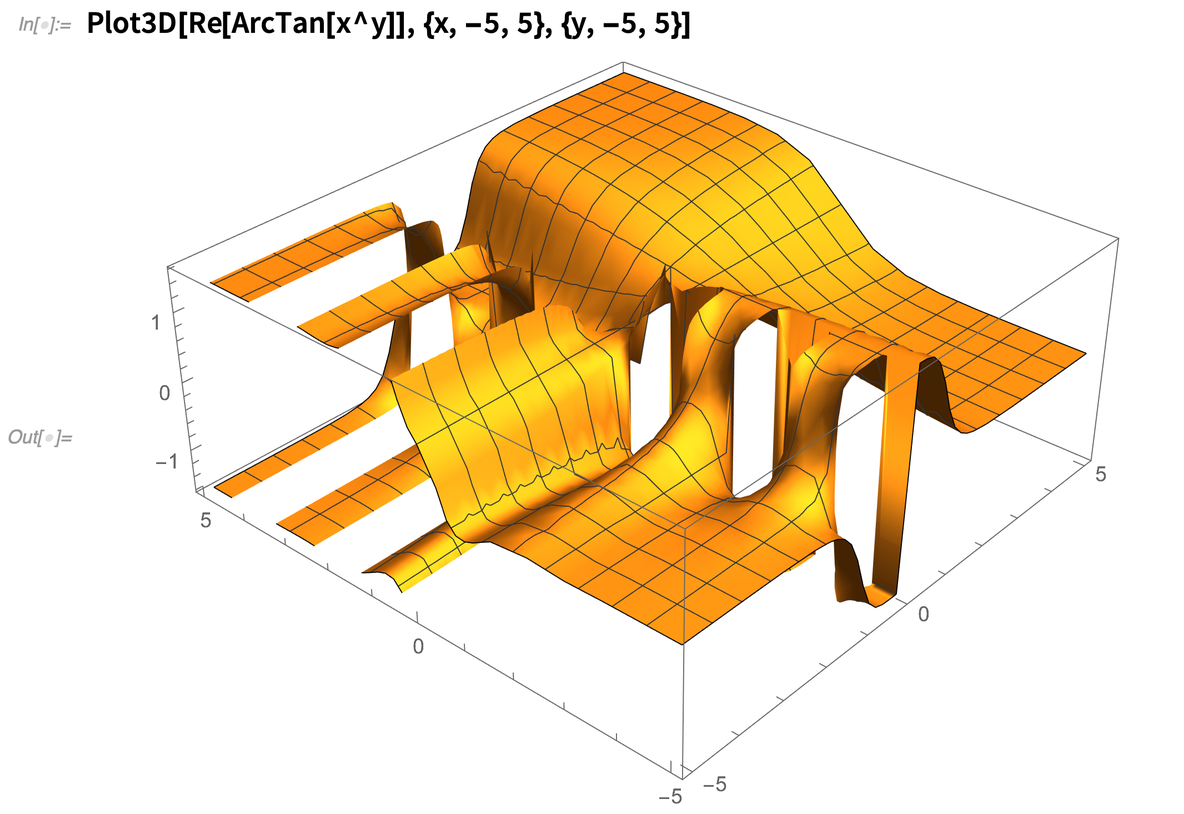
Et, oui, même dans Plot3D , nous utilisons régulièrement les FunctionSingularities pour comprendre ce qui se passe :
Intégration de la vidéo
Dans la version 12.1, nous avons commencé à introduire la vidéo comme une fonctionnalité intégrée au langage Wolfram. La version 12.2 poursuit ce processus. Dans la version 12.1, nous ne pouvions gérer la vidéo que dans les notebooks de bureau ; désormais, cette fonctionnalité est étendue aux cloud notebooks. Ainsi, lorsque vous générez une vidéo dans Wolfram Language, elle peut être immédiatement déployée dans le cloud.
L’une des principales nouveautés de la version 12.2 en matière de vidéo est VideoGenerator. Fournissez une fonction qui crée des images (et/ou de l’audio), et VideoGenerator générera une vidéo à partir de celles-ci (ici une vidéo de 4 secondes) :

Pour ajouter une piste sonore, nous pouvons simplement utiliser VideoCombine:
![]()
Alors comment monter cette vidéo ? Dans la version 12.2, nous disposons de versions programmatiques des fonctions standard de montage vidéo. VideoSplit, par exemple, divise la vidéo à des moments particuliers :

Mais la véritable puissance du langage Wolfram réside dans l’application systématique de fonctions arbitraires aux vidéos. VideoMap vous permet d’appliquer une fonction à une vidéo pour obtenir une autre vidéo. Par exemple, nous pourrions rendre progressivement floue la vidéo que nous venons de réaliser :
![]()
Il existe également deux nouvelles fonctions d’analyse des vidéos — VideoMapList et VideoMapTimeSeries — qui génèrent respectivement une liste et une série temporelleen appliquant une fonction aux images d’une vidéo et à sa piste audio.
Une autre nouvelle fonction, très utile pour le traitement et le montage vidéo, est VideoIntervals, qui détermine les intervalles de temps pendant lesquels un critère donné s’applique dans une vidéo :

Maintenant, par exemple, nous pouvons supprimer ces intervalles dans la vidéo :

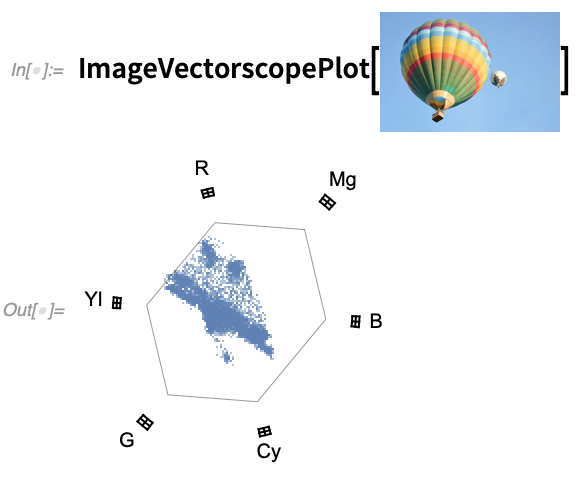
Une opération courante dans la manipulation pratique des vidéos est le transcodage. Dans la version 12.2, la fonction VideoTranscode vous permet de convertir une vidéo dans l’un des plus de 300 conteneurs et codecs que nous prenons en charge. À propos, la version 12.2 comporte également de nouvelles fonctions ImageWaveformPlot et ImageVectorscopePlot qui sont couramment utilisées dans la correction des couleurs des vidéos :
L’un des principaux problèmes techniques dans le traitement de la vidéo est la gestion de la grande quantité de données dans une vidéo typique. Dans la version 12.2, il y a maintenant un contrôle plus fin sur l’endroit où ces données sont stockées. L’option GeneratedAssetLocation (avec la valeur par défaut $GeneratedAssetLocation) vous permet de choisir entre différents fichiers, répertoires, magasins d’objets locaux, etc.
Mais il y a aussi une nouvelle fonction dans la version 12.2 pour gérer les « vidéos légères », sous la forme d’AnimatedImage. AnimatedImage prend simplement une liste d’images et produit une animation qui est immédiatement jouée dans votre bloc-notes – et tout est directement stocké dans votre bloc-notes.

De gros calculs ? Envoyez-les à un fournisseur de services en nuage !
Ce problème se pose assez fréquemment pour moi, surtout dans le cadre de notre projet de physique. J’ai un gros calcul à faire, mais je ne veux pas (ou ne peux pas) le faire sur mon ordinateur. À la place, j’aimerais l’exécuter en tant que travail par lots dans le nuage.
Cela est possible en principe depuis que les fournisseurs de calcul en nuage existent. Mais cela a été très compliqué et difficile. Aujourd’hui, dans la version 12.2, c’est enfin facile. Avec n’importe quel morceau de code Wolfram Language, il suffit d’utiliser RemoteBatchSubmit pour l’envoyer en tant que travail par lots dans le nuage.
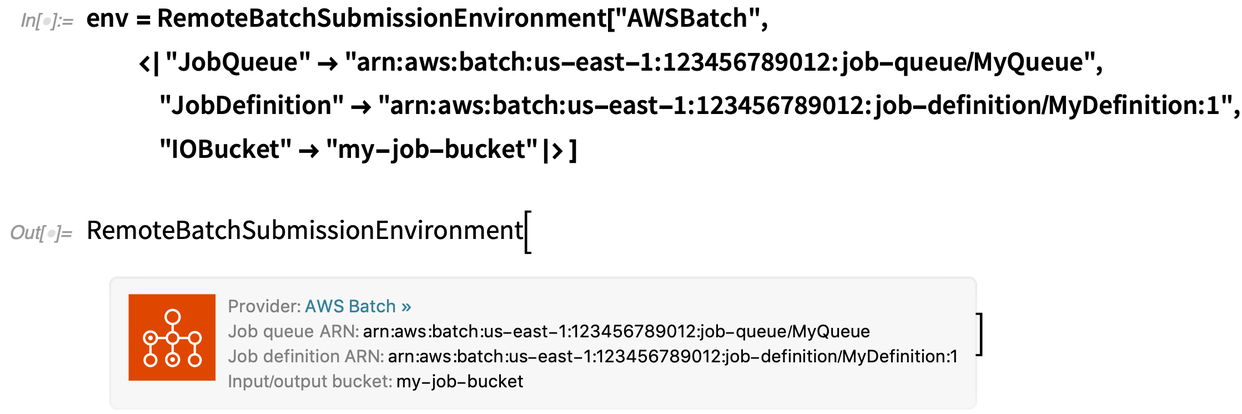
Il y a un peu de configuration requise du côté du fournisseur de calcul par lots. Tout d’abord, vous devez disposer d’un compte auprès d’un fournisseur approprié – initialement, nous prenons en charge AWS Batch et Charity Engine. Ensuite, vous devez configurer les choses avec ce fournisseur (et nous avons des flux de travail qui décrivent comment le faire). Mais dès que cela sera fait, vous obtiendrez un environnement de soumission par lots à distance qui est essentiellement tout ce dont vous avez besoin pour commencer à soumettre des travaux par lots :
OK, alors qu’est-ce qui serait impliqué, disons, dans la soumission d’une formation de réseau neuronal ? Voici comment je l’exécuterais localement sur ma machine (et, oui, il s’agit d’un exemple très simple) :

Et voici la façon minimale dont je l’enverrais pour l’exécuter sur AWS Batch :

Je reçois en retour un objet qui représente mon travail de traitement par lots à distance, que je peux interroger pour savoir ce qui s’est passé avec mon travail. Au début, il me dira simplement que mon travail est « exécutable » :

Plus tard, il dira qu’il « démarre », puis « fonctionne », puis (si tout va bien) « a réussi ». Et une fois que le travail est terminé, vous pouvez récupérer le résultat comme ceci :

Il y a beaucoup de détails que vous pouvez récupérer sur ce qui s’est réellement passé. Par exemple, voici le début du journal brut du travail :

Mais le véritable intérêt d’exécuter vos calculs à distance dans un nuage est qu’ils peuvent potentiellement être plus importants et plus complexes que ceux que vous pouvez exécuter sur vos propres machines. Voici comment nous pourrions exécuter le même calcul que ci-dessus, mais en demandant maintenant l’utilisation d’un GPU :
![]()
RemoteBatchSubmit peut également gérer des calculs parallèles. Si vous demandez une machine multicœur, vous pouvez immédiatement exécuter ParallelMap, etc. sur tous ses cœurs. Mais vous pouvez aller encore plus loin avec RemoteBatchMapSubmit, qui distribue automatiquement votre calcul sur toute une série de machines distinctes dans le cloud.
Voici un exemple :

Pendant qu’il est en cours d’exécution, nous pouvons obtenir un affichage dynamique de l’état de chaque partie du travail :
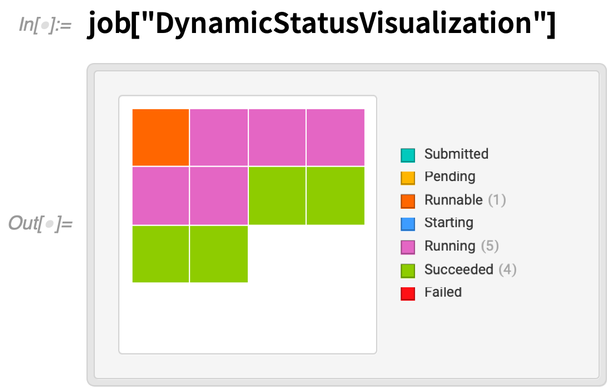
Environ 5 minutes plus tard, le travail est terminé :


RemoteBatchSubmit et RemoteBatchMapSubmit vous donnent un accès de haut niveau aux services de calcul en nuage pour le calcul général par lots. Mais dans la version 12.2, une interface directe de niveau inférieur est également disponible, par exemple pour AWS.
Connectez-vous à AWS :

Une fois que vous vous êtes authentifié, vous pouvez voir tous les services qui sont disponibles :

Ceci donne un handle au service Amazon Translate :
Vous pouvez maintenant l’utiliser pour appeler le service :

Bien entendu, vous pouvez toujours effectuer une traduction directement dans le langage Wolfram :

Pouvez-vous faire un tracé en 10 dimensions ?
Il est très simple de tracer des données à une, deux ou trois dimensions. Pour quelques dimensions supplémentaires, vous pouvez utiliser des couleurs ou d’autres styles. Mais dès que vous avez affaire à dix dimensions, tout s’écroule. Et si vous avez beaucoup de données en 10D, par exemple, vous allez probablement devoir utiliser quelque chose comme DimensionReduce pour essayer d’extraire les « caractéristiques intéressantes ».
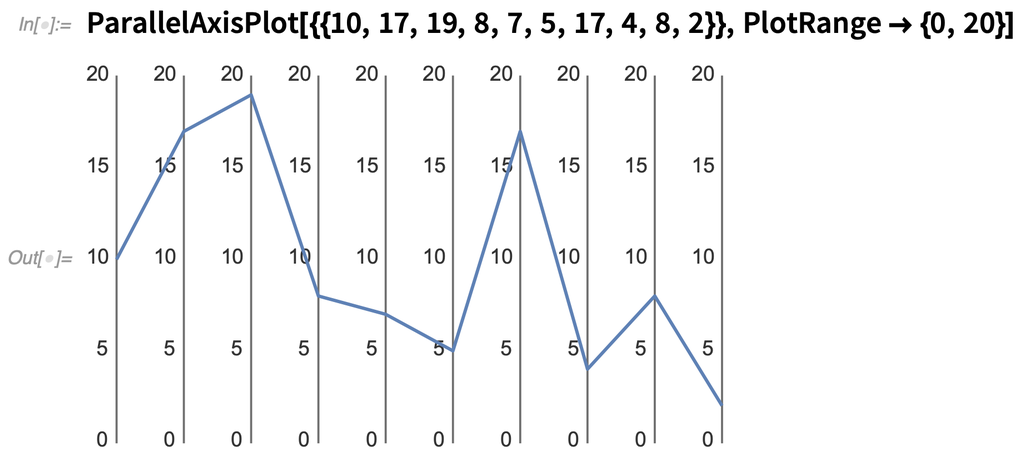
Mais si vous n’avez affaire qu’à quelques « points de données », il existe d’autres moyens de visualiser des choses comme des données en 10 dimensions. Dans la version 12.2, nous introduisons plusieurs fonctions à cet effet, dont le premier exemple est ParallelAxisPlot. L’idée est que chaque « dimension » est représentée sur un « axe séparé ». Pour un point unique, ce n’est pas très excitant :
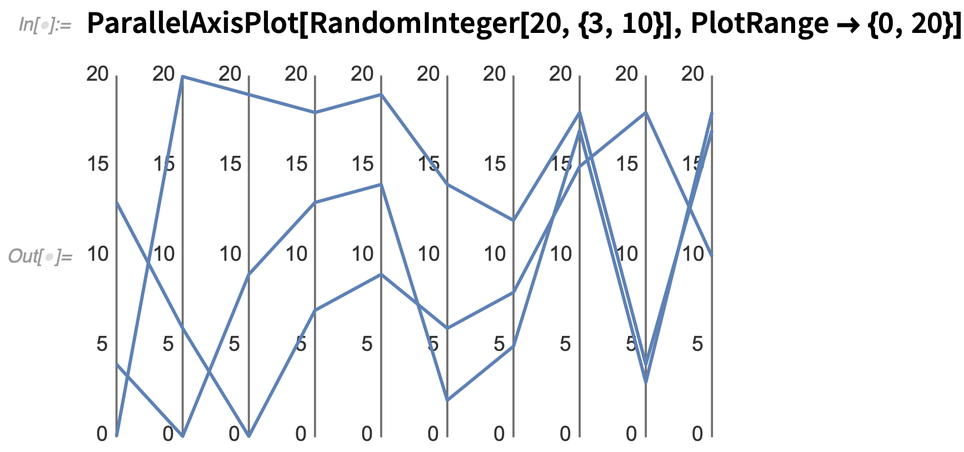
Voici ce qui se passe si nous traçons trois « points de données 10D » aléatoires :
Mais l’une des caractéristiques importantes de ParallelAxisPlot est que, par défaut, il détermine automatiquement l’échelle sur chaque axe, de sorte qu’il n’est pas nécessaire que les axes représentent des choses similaires. Ainsi, par exemple, voici 7 quantités complètement différentes tracées pour tous les éléments chimiques :
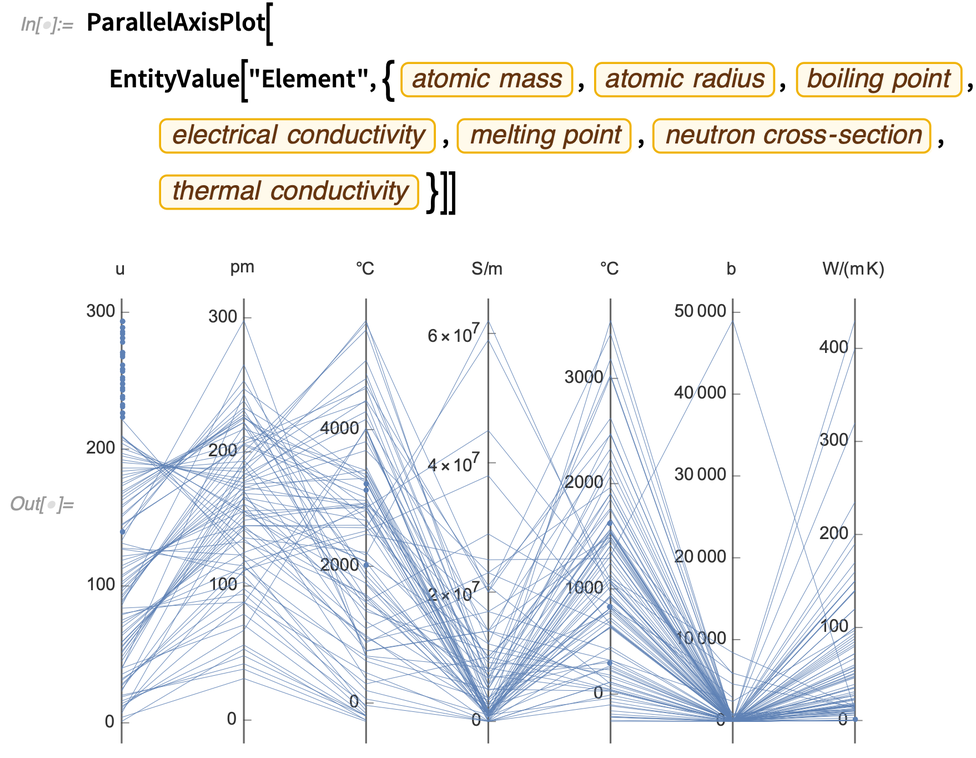
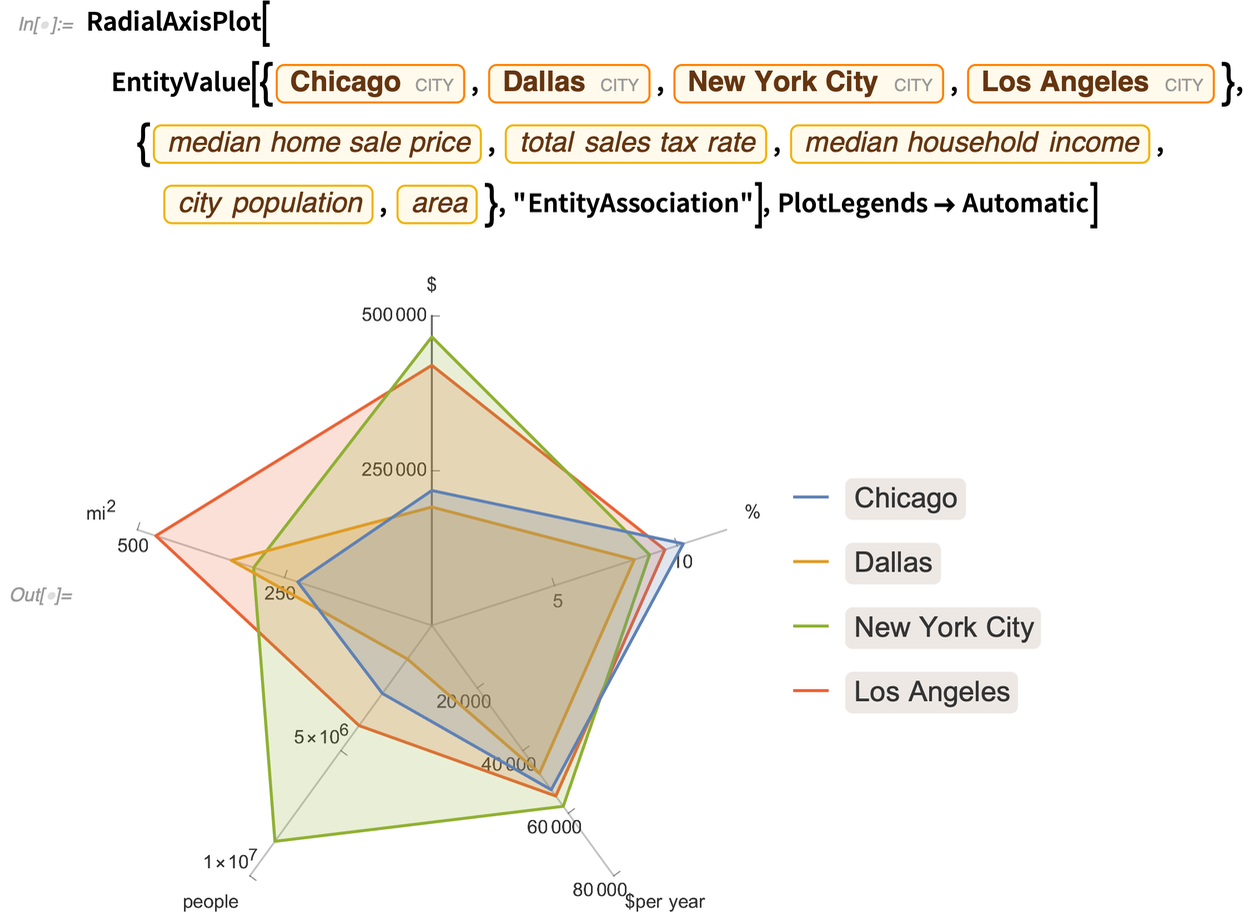
Différents types de données à haute dimension sont plus efficaces sur différents types de graphiques. Un autre nouveau type de graphique dans la version 12.2 est le RadialAxisPlot. (Ce type de tracé porte également des noms comme tracé radar, tracé araignée et tracé en étoile).
RadialAxisPlot trace chaque dimension dans une direction différente :

Elle est généralement plus instructive lorsqu’il n’y a pas trop de points de données :
Tracés de réseaux 3D
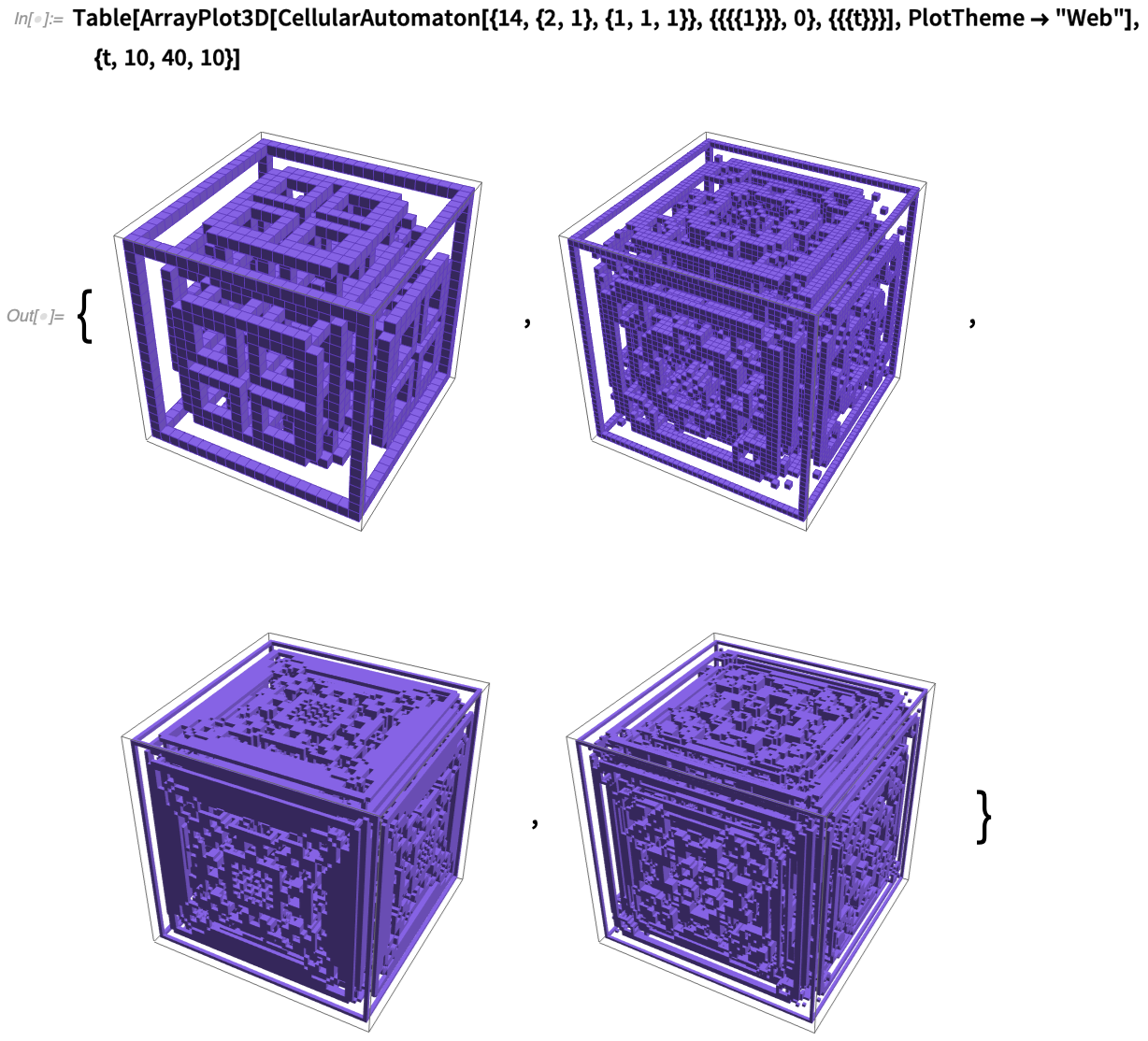
En 1984, j’ai utilisé un superordinateur Cray pour réaliser des images 3D d’automates cellulaires 2D évoluant dans le temps (oui, capturés sur des diapositives 35 mm) :

Cela fait 36 ans que j’attends de disposer d’un moyen vraiment rationnel de les reproduire. Et maintenant, dans la version 12.2, nous l’avons enfin : ArrayPlot3D. Déjà en 2012, nous avons introduit Image3D pour représenter et afficher des images 3D composées de voxels 3D avec des couleurs et des opacités spécifiées. Mais l’accent est mis sur le travail de « style radiologique », dans lequel il y a une certaine hypothèse de continuité entre les voxels. Et si vous avez vraiment un tableau discret de données discrètes (comme dans les automates cellulaires), cela ne donnera pas des résultats très nets.
Et voici, pour un cas légèrement plus élaboré d’automate cellulaire 3D :
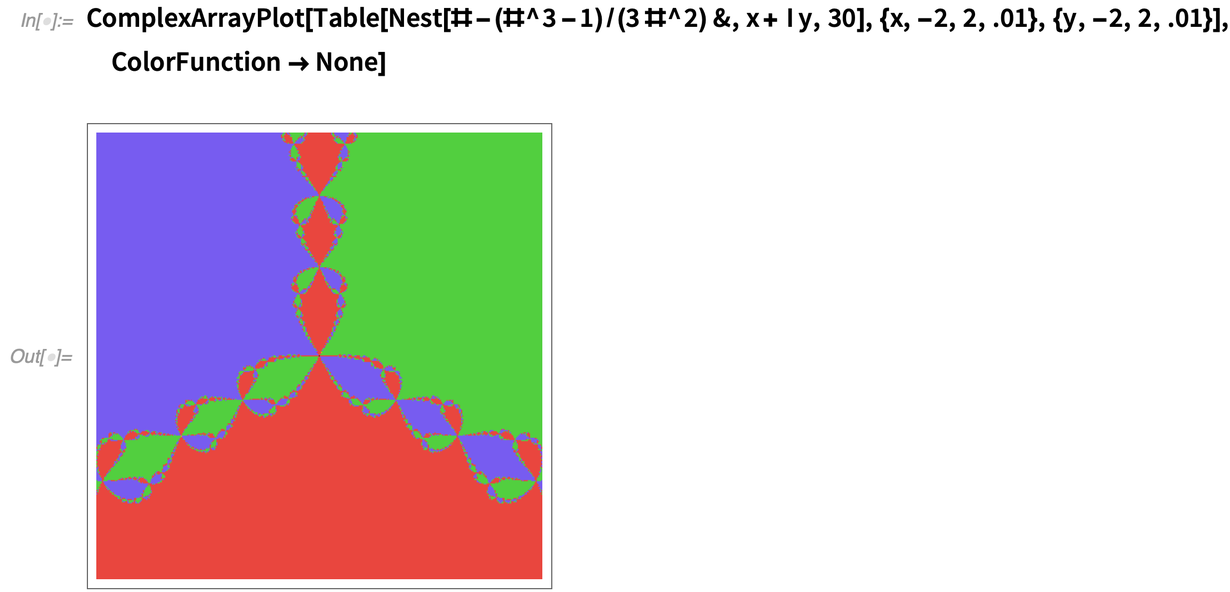
Une autre nouvelle fonction de la famille ArrayPlot dans 12.2 est ComplexArrayPlot, ici appliquée à un tableau de valeurs provenant de la méthode de Newton:
Faire progresser l’esthétique informatique de la visualisation
L’un de nos objectifs dans Wolfram Language est d’avoir des visualisations qui sont « automatiquement belles » – parce qu’elles ont des algorithmes et des heuristiques qui mettent en œuvre efficacement une bonne esthétique informatique. Dans la version 12.2, nous avons amélioré l’esthétique informatique pour une variété de types de visualisation. Par exemple, dans la version 12.1, voici à quoi ressemblait par défaut un SliceVectorPlot3D :
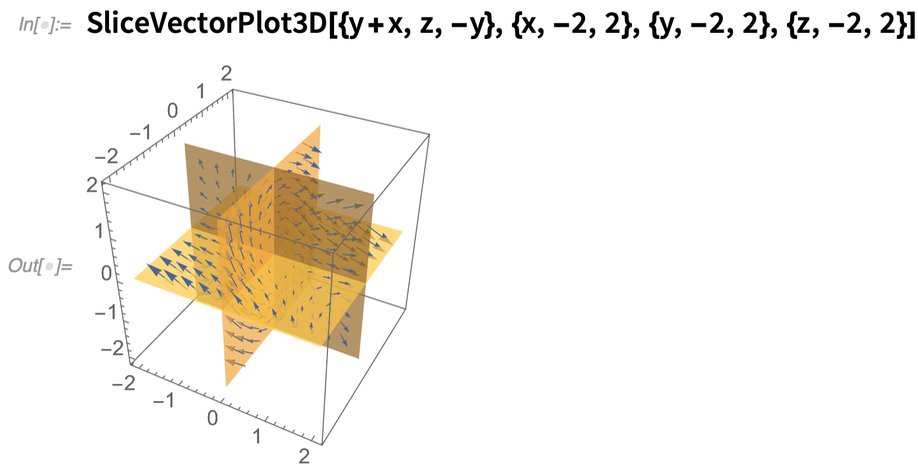
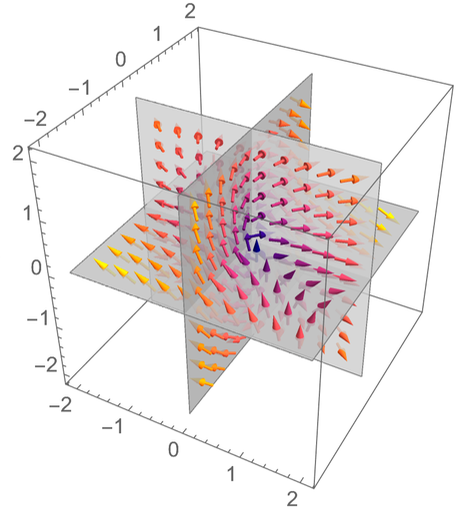
Maintenant, ça ressemble à ça :
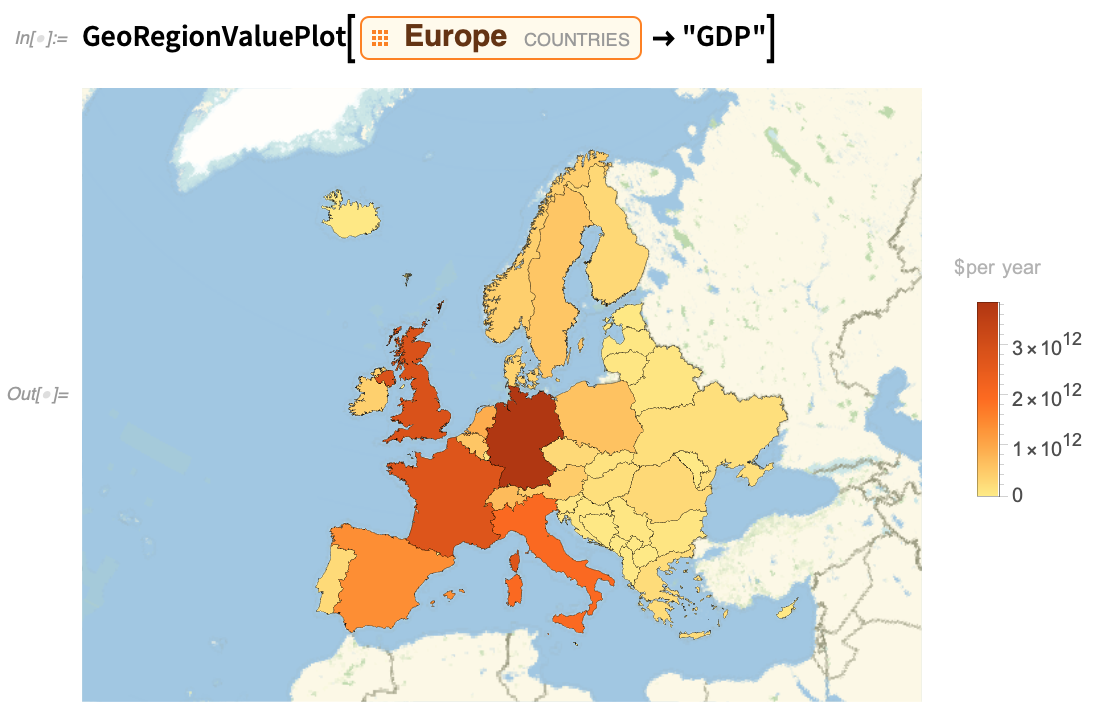
Depuis la version 10, nous utilisons aussi de plus en plus notre option PlotTheme, pour « changer de banque » d’options détaillées afin de faire des visualisations qui conviennent à différents objectifs, et répondent à différents buts esthétiques. Ainsi, par exemple, dans la version 12.2, nous avons ajouté des thèmes de tracé à GeoRegionValuePlot. Voici un exemple du thème par défaut (qui a été mis à jour, d’ailleurs) :
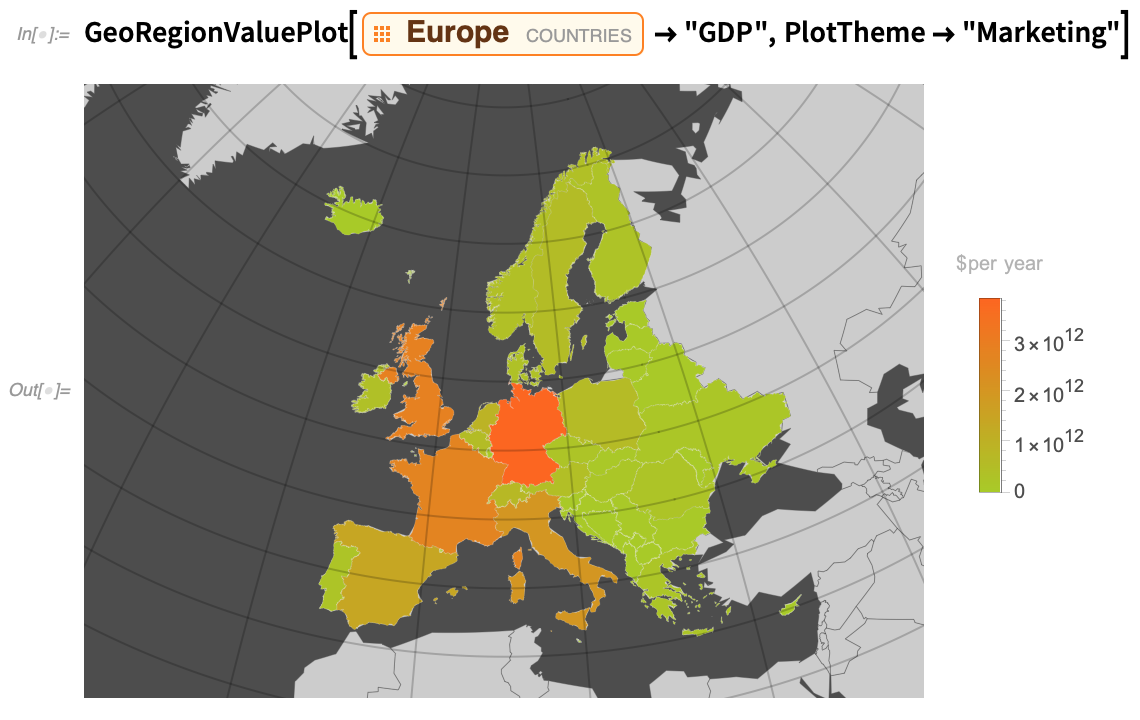
Et voici le thème de l’intrigue « Marketing » :
Une autre chose dans la version 12.2 est l’ajout de nouvelles primitives et de nouvelles « matières premières » pour créer des effets visuels esthétiques. Dans la version 12.1, nous avons introduit des éléments comme HatchFilling pour les hachures. Dans la version 12.2, nous avons maintenant aussi LinearGradientFilling :

Et nous pouvons maintenant ajouter ce type d’effet au remplissage d’une parcelle :

Pour être encore plus élégant, on peut tracer des points aléatoires en utilisant le nouveau ConicGradientFilling :

Rendre le code un peu plus beau
L’un des principaux objectifs du langage Wolfram est de définir un langage informatique cohérent qui puisse être compris à la fois par les ordinateurs et les humains. Nous (et moi en particulier !) avons consacré beaucoup d’efforts à la conception du langage, et à des choses comme le choix des bons noms pour les fonctions. Mais en rendant le langage aussi facile à lire que possible, il est également important de rationaliser ses aspects « non verbaux » ou syntaxiques. Pour les noms de fonctions, nous nous appuyons essentiellement sur la compréhension qu’ont les gens des mots du langage naturel. Pour la structure syntaxique, nous voulons tirer parti de la « compréhension ambiante » des gens, par exemple dans des domaines comme les mathématiques.
Il y a plus de dix ans, nous avons introduit comme moyen de spécifier les fonctions Function, de sorte qu’au lieu d’écrire
![]()
(ou #2&), vous pouviez écrire :
![]()
Mais pour entrer , vous deviez taper \[Function] ou au moins fn , ce qui avait tendance à être « un peu difficile ».
Eh bien, dans la version 12.2, nous nous » généralisons » en permettant de taper juste comme |-> ;
![]()
ainsi que des choses comme :
![]()
Dans la version 12.2, il y a aussi un autre nouvel élément de « syntaxe courte » : //=Imagine que vous avez un résultat, disons appelé res. Vous voulez maintenant appliquer une fonction à res, puis « mettre à jour res« . La nouvelle fonctionApplyTo (écrite //=) permet de le faire facilement :
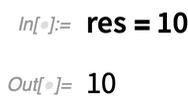
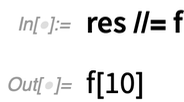

Nous sommes toujours à la recherche de « masses de calcul » répétées que nous pouvons « emballer » dans des fonctions aux « noms faciles à comprendre ». Et dans la version 12.2, nous avons quelques nouvelles fonctions de ce type : FoldWhile et FoldWhileList. FoldList prend normalement une liste et « plie » chaque élément successif dans le résultat qu’il construit, jusqu’à ce qu’il arrive à la fin de la liste :
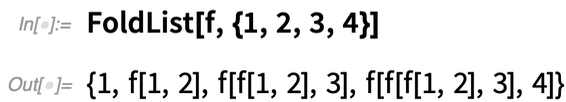
Mais que faire si vous voulez « arrêter tôt » ? FoldWhileList vous permet de le faire. Donc ici nous divisons successivement par 1, 2, 3, …, en nous arrêtant lorsque le résultat n’est plus un entier :
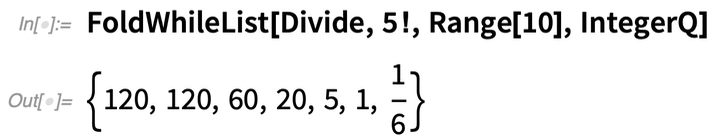
Plus de gymnastique de tableau : Opérations sur les colonnes et leurs généralisations
Disons que vous avez un tableau, par exemple :
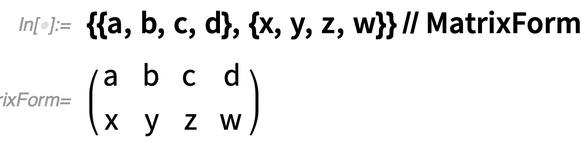
Map vous permet d’appliquer une fonction sur les « lignes » de ce tableau :
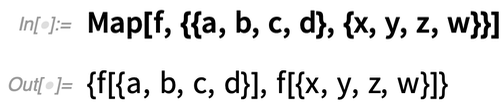
Mais que se passe-t-il si vous voulez opérer sur les « colonnes » du tableau, en « réduisant » effectivement la première dimension du tableau ? Dans la version 12.2, la fonction ArrayReduce vous permet de le faire :
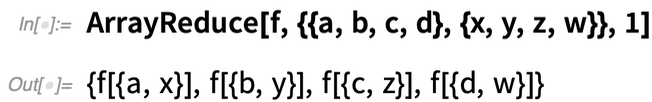
Voici ce qui se passe si, à la place, nous demandons à ArrayReduce de « réduire » la deuxième dimension du tableau :
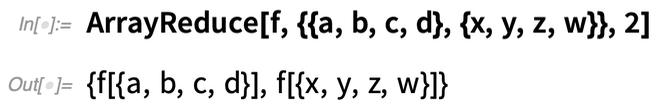
Qu’est-ce qui se passe réellement ici ? Le tableau a des dimensions 2×4 :
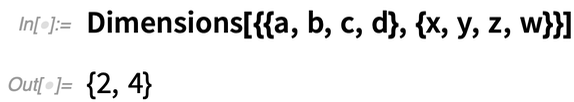
ArrayReduce[f, ..., 1]« réduit » la première dimension, laissant un tableau avec des dimensions {4}.
ArrayReduce[f, ..., 2]réduit la deuxième dimension, laissant un tableau avec des dimensions {2}.
Examinons un cas un peu plus grand : un réseau 2×3×4 :

Cela élimine maintenant la « première dimension », laissant un tableau 3×4 :


D’autre part, cela élimine la « deuxième dimension », laissant un tableau 2×4 :


Pourquoi cela est-il utile ? Par exemple, lorsque vous disposez de tableaux de données dont les différentes dimensions correspondent à différents attributs, vous souhaitez « ignorer » un attribut particulier et agréger les données en fonction de celui-ci. Disons que l’attribut que vous voulez ignorer se trouve au niveau n de votre tableau. Dans ce cas, tout ce que vous avez à faire pour l' » ignorer » est d’utiliser ArrayReduce[f, ..., n], où f est la fonction qui agrège les valeurs (souvent quelque chose comme Total ou Mean).
Vous pouvez obtenir les mêmes résultats qu’avec ArrayReduce par des séquences appropriées de Transpose, Apply, etc. Mais c’est assez désordonné, et ArrayReduce fournit un « emballage » élégant de ces types d’opérations sur les tableaux.
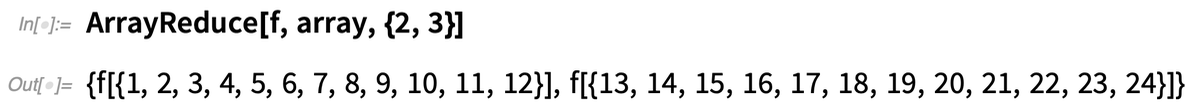
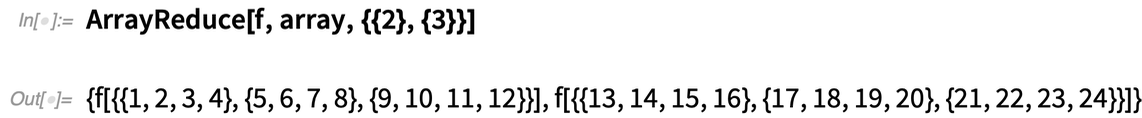
Au niveau le plus simple, ArrayReduce est un moyen pratique d’appliquer des fonctions « par colonne » sur des tableaux. Mais de manière générale, c’est un moyen d’appliquer des fonctions à des sous-réseaux avec des indices arbitraires. Et si vous pensez en termes de tenseurs, ArrayReduce est une généralisation de la contraction, dans laquelle plus de deux indices peuvent être impliqués, et les éléments peuvent être « aplatis » avant l’application de l’opération (qui ne doit pas nécessairement être une sommation).
Regardez votre code s’exécuter : D’autres produits de la famille Echo
C’est un vieil adage dans le débogage du code : « mettre une instruction d’impression ». Mais c’est plus élégant dans le Wolfram Language, notamment grâce à Echo. L’idée est simple : Echo[expr] « fait écho » (c’est-à-dire imprime) à la valeur de expr, mais renvoie ensuite cette valeur. Le résultat est donc que vous pouvez mettre Echo n’importe où dans votre code (souvent sous la forme Echo@…) sans que cela n’affecte ce que fait votre code.
Dans la version 12.2, il y a quelques nouvelles fonctions qui suivent le modèle « Echo« . Un premier exemple est EchoLabel, qui ajoute simplement une étiquette à ce qui est renvoyé :

Les aficionados pourraient se demander pourquoi EchoLabel est nécessaire. Après tout, Echo lui-même permet un second argument qui peut spécifier un label. La réponse – et oui, c’est un morceau légèrement subtil de la conception du langage – est que si l’on insère simplement Echo comme une fonction à appliquer (disons avec @), alors elle ne peut avoir qu’un seul argument, donc pas de label. EchoLabel est configuré pour avoir la forme d’opérateur EchoLabel[label] de sorte que EchoLabel[label][expr] est équivalent à Echo[expr,label].
Une autre nouvelle « fonction écho » dans la version 12.2 est EchoTiming, qui affiche le temps (en secondes) de ce qu’elle évalue :

Il est souvent utile d’utiliser à la fois Echo et EchoTiming:

Et, à propos, si vous voulez toujours imprimer le temps d’évaluation (comme Mathematica 1.0 le faisait par défaut il y a 32 ans), vous pouvez toujours définir globalement $Pre=EchoTiming.
Une autre nouvelle « fonction écho » dans la version 12.2 est EchoEvaluation qui renvoie les valeurs « avant » et « après » d’une évaluation :

Vous pouvez vous demander ce qui se passe avec des EchoEvaluation imbriquées. Voici un exemple :

Au fait, il est assez courant de vouloir utiliser à la fois EchoTiming et EchoEvaluation:

Enfin, si vous voulez laisser les fonctions d’écho dans votre code, mais que vous voulez que votre code soit « silencieux », vous pouvez utiliser la nouvelle QuietEcho pour « taire » tous les échos (comme Quiet « tait » les messages) :

Rendre le code un peu plus beau
Que peut-on faire à ce sujet ? Eh bien, dans la version 12.2, nous avons développé un mécanisme symbolique de haut niveau pour gérer les problèmes dans le code. L’idée de base est que vous insérez Confirm (ou des fonctions apparentées) – un peu comme vous pourriez insérer Echo – pour « confirmer » que quelque chose dans votre programme fait ce qu’il doit faire. Si la confirmation fonctionne, votre programme continue à fonctionner. Mais si elle échoue, le programme s’arrête et sort vers l’Enclose le plus proche. En un sens, Enclose « enferme » les régions de votre programme, ne laissant pas ce qui ne va pas à l’intérieur se propager immédiatement à l’extérieur.
Voyons comment cela fonctionne dans un cas simple. Dans ce cas, Confirm « confirme » avec succès y, en le renvoyant simplement, et Enclose ne fait pas grand-chose :
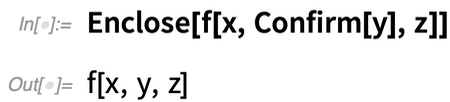
Mais maintenant, mettons $Failed à la place de y. $Failed est un élément que Confirm considère par défaut comme un problème. Ainsi, lorsqu’il voit $Failed, il s’arrête, sortant vers l’Enclose – qui à son tour produit un objet Failure :
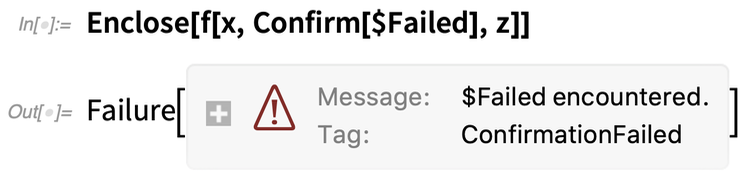
Si nous mettons quelques échos, nous verrons que x est atteint avec succès, mais pas z ; dès que la Confirm échoue, elle arrête tout :
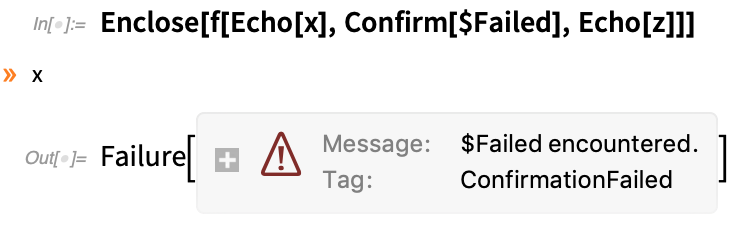
Il est très courant de vouloir utiliser Confirm/Enclose lorsque vous définissez une fonction :
![]()
Utilisez l’argument 5 et tout fonctionne :
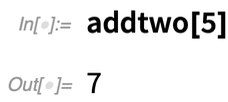
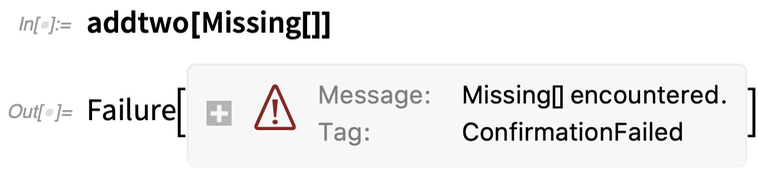
Mais si nous utilisons plutôt Missing[] – ce que Confirm considère par défaut comme un problème – nous obtenons en retour un objet Failure :
Nous pourrions obtenir la même chose avec If, Return, etc. Mais même dans ce cas très simple, ce ne serait pas aussi joli.
Confirm a un certain ensemble de choses par défaut qu’il considère comme « erronées » ($Failed, Failure[...], Missing[...] sont des exemples). Mais il existe des fonctions connexes qui vous permettent de spécifier des tests particuliers. Par exemple, ConfirmBy applique une fonction pour tester si une expression doit être confirmée.
Ici, ConfirmBy confirme que 2 est un nombre :

x n’est pas considéré comme tel par NumberQ:

OK, alors mettons ces pièces ensemble. Définissons une fonction qui est censée opérer sur des chaînes de caractères :
![]()
Si on lui donne une ficelle, tout va bien :

Mais si nous lui donnons un numéro à la place, la ConfirmBy échoue :
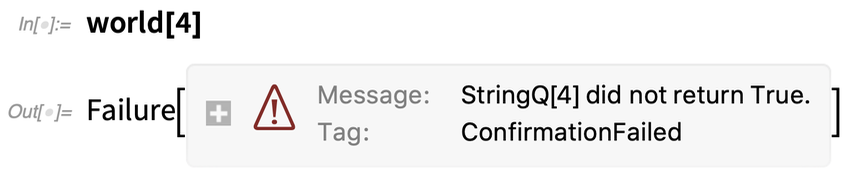
Mais c’est ici que des choses vraiment intéressantes commencent à se produire. Disons que nous voulons faire passer le monde par une liste, en confirmant toujours qu’il obtient un bon résultat. Ici, tout va bien :

Mais maintenant, quelque chose a mal tourné :
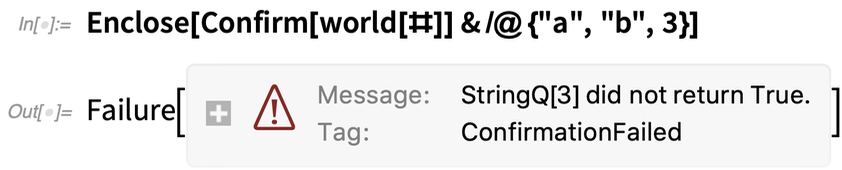
Le ConfirmBy à l’intérieur de la définition de world a échoué, ce qui a amené son Enclose à produire un objet Failure. Cet objet Failure a ensuite provoqué l’échec de Confirm dans la Map, et l’Enclose qui l’entoure a produit un objet Failure pour l’ensemble. Une fois encore, nous aurions pu obtenir la même chose avec If, Throw, Catch, etc. Mais Confirm/Enclose le fait de manière plus robuste et plus élégante.
Ce sont tous de très petits exemples. Mais où Confirm/Enclose montrent vraiment leur valeur, c’est dans les grands programmes, et en fournissant un cadre clair et de haut niveau pour gérer les erreurs et les exceptions, et définir leur portée.
Outre Confirm et ConfirmBy, il y a également ConfirmMatch, qui confirme qu’une expression correspond à un modèle spécifié. Puis il y a ConfirmQuiet, qui confirme que l’évaluation d’une expression ne génère aucun message (ou, du moins, aucun message que vous lui avez demandé de tester). Il y a aussi ConfirmAssert, qui prend simplement une « assertion » (comme like p>0) et confirme qu’elle est vraie.
Lorsqu’une confirmation échoue, le programme sort toujours vers l’Enclose le plus proche, en livrant à l’Enclose un objet Failure contenant des informations sur l’échec survenu. Lorsque vous configurez l’Enclose, vous pouvez lui indiquer comment traiter les objets d’échec qu’il reçoit, soit en les renvoyant simplement (peut-être vers les Confirm et Enclose les plus proches), soit en appliquant des fonctions à leur contenu.
Confirm et Enclose constituent un mécanisme élégant de gestion des erreurs, facile et propre à insérer dans les programmes. Mais il va sans dire qu’ils posent quelques problèmes délicats. Permettez-moi d’en mentionner une seule. La question est la suivante : quelles sont les Confirm qu’un Enclose donné englobe réellement ? Si vous avez écrit un morceau de code qui contient explicitement Enclose et Confirm, c’est assez évident. Mais que se passe-t-il si un Confirm est généré d’une manière ou d’une autre – peut-être dynamiquement – au plus profond d’une pile de fonctions ? La situation est similaire à celle des variables nommées. Module recherche simplement les variables directement (« lexicalement ») dans son corps. Le Block recherche les variables (« dynamiquement ») où qu’elles se trouvent. Eh bien, Enclose fonctionne par défaut comme Module, en recherchant « lexicalement » les Confirm‘s à enfermer. Mais si vous incluez des balises dans Confirm et Enclose, vous pouvez les configurer pour qu’elles se « trouvent » mutuellement, même si elles ne sont pas explicitement « visibles » dans le même morceau de code.
Robustification des fonctions
Confirm/Enclose constituent un bon moyen de haut niveau pour gérer le « flux » des choses qui tournent mal dans un programme ou une fonction. Mais que faire si quelque chose ne va pas dès le départ ? Dans nos fonctions intégrées au langage Wolfram, nous appliquons un ensemble standard de vérifications. Le nombre d’arguments est-il correct ? S’il y a des options, sont-elles autorisées et se trouvent-elles au bon endroit ? Dans la version 12.2, nous avons ajouté deux fonctions qui peuvent effectuer ces vérifications standard pour les fonctions que vous écrivez.
Ceci dit que f devrait avoir deux arguments, ce qui n’est pas le cas ici :
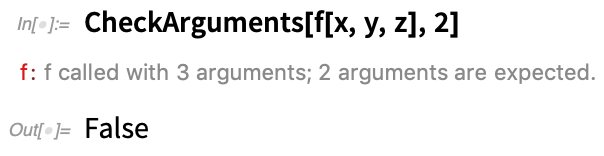
Voici un moyen d’intégrer CheckArguments à la définition de base d’une fonction :
![]()
Si vous lui donnez le mauvais nombre d’arguments, elle générera un message, puis reviendra non évaluée, comme le font de nombreuses fonctions intégrées au langage Wolfram :

ArgumentsOptions est une autre nouvelle fonction dans la version 12.2 – qui sépare les « arguments positionnels » des options dans une fonction. Configurer les options d’une fonction :
![]()
Cela attend un argument positionnel, qu’il trouve :

S’il ne trouve pas exactement un argument positionnel, il génère un message :

Nettoyer après votre code
Vous exécutez un morceau de code et il fait ce qu’il fait – et vous ne voulez généralement pas qu’il laisse quoi que ce soit derrière lui. Pour ce faire, vous pouvez souvent utiliser des constructions comme Module, Block, BlockRandom, etc. Mais il arrive parfois que vous mettiez en place quelque chose qui doit être explicitement « nettoyé » lorsque votre code se termine.
Par exemple, vous pouvez créer un fichier dans votre morceau de code, et vouloir que le fichier soit supprimé lorsque ce morceau de code particulier se termine. Dans la version 12.2, il y a une nouvelle fonction pratique pour gérer ce genre de choses : WithCleanup.
WithCleanup[expr, cleanup] évalue expr, puis cleanup – mais retourne le résultat de expr. Here’s a trivial example (which could really be achieved better with Block). Vous assignez une valeur à x, obtenez son carré, puis nettoyez x avant de retourner le carré :
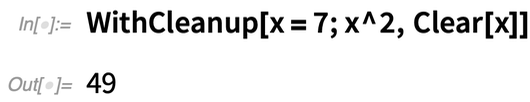
Il est déjà pratique d’avoir une construction qui fait le nettoyage tout en retournant l’expression principale que vous évaluiez. Mais un détail important de WithCleanup est qu’il gère également la situation où vous interrompez l’évaluation principale que vous étiez en train de faire. Normalement, l’émission d’un abandon devrait tout arrêter. Mais WithCleanup est configuré pour s’assurer que le nettoyage se fait même s’il y a un abandon. Ainsi, si le nettoyage implique, par exemple, la suppression d’un fichier, le fichier est supprimé, même si l’opération principale est interrompue.
WithCleanup permet également de donner une initialisation. Donc ici, l’initialisation est effectuée, ainsi que le nettoyage, mais l’évaluation principale est interrompue :
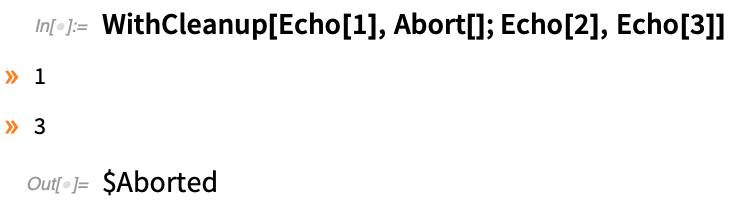
À propos, WithCleanup peut également être utilisé avec Confirm/Enclose pour garantir que même si une confirmation échoue, un certain nettoyage sera effectué.
Dates – avec 37 nouveaux calendriers
Nous sommes aujourd’hui le 16 décembre 2020, du moins selon le calendrier grégorien standard généralement utilisé aux États-Unis. Mais il existe de nombreux autres systèmes de calendrier utilisés à diverses fins dans le monde, et encore plus qui ont été utilisés à un moment ou à un autre de l’histoire.
Dans les versions précédentes du Wolfram Language, nous ne prenions en charge que quelques systèmes de calendrier courants. Mais dans la version 12.2, nous avons ajouté un support très large pour les systèmes de calendrier, 41 au total. On peut considérer que les systèmes de calendrier sont un peu comme les projections en géodésie ou les systèmes de coordonnées en géométrie. Vous disposez d’un certain temps : vous devez maintenant savoir comment il est représenté dans le système que vous utilisez. Et tout comme GeoProjectionData, il y a maintenant CalendarData qui peut vous donner une liste des systèmes de calendrier disponibles :

Voici donc la représentation de « maintenant » convertie en différents calendriers :
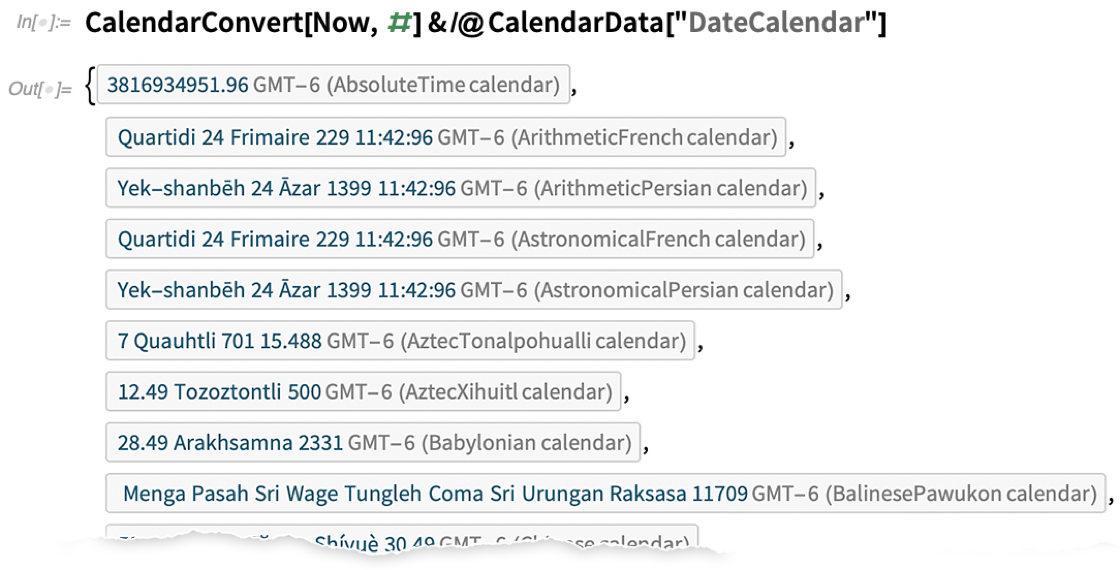
Il existe de nombreuses subtilités à ce sujet. Certains calendriers sont purement « arithmétiques », d’autres reposent sur des calculs astronomiques. Et puis il y a la question des « variantes bissextiles ». Avec le calendrier grégorien, nous avons l’habitude de simplement ajouter un 29 février. Mais le calendrier chinois, par exemple, peut ajouter des « mois bissextiles » entiers dans une année (de sorte que, par exemple, il peut y avoir deux « quatrièmes mois »). Dans le langage Wolfram, nous disposons désormais d’une représentation symbolique pour ces choses, en utilisant LeapVariant :

L’une des raisons pour lesquelles il faut tenir compte des différents systèmes de calendrier est qu’ils sont utilisés pour déterminer les fêtes et les festivals dans différentes cultures. (Une autre raison, particulièrement pertinente pour quelqu’un comme moi qui étudie beaucoup l’histoire, est la conversion des dates historiques : L’anniversaire de Newton a été enregistré à l’origine comme étant le 25 décembre 1642, mais en le convertissant en date grégorienne, on obtient le 4 janvier 1643.)
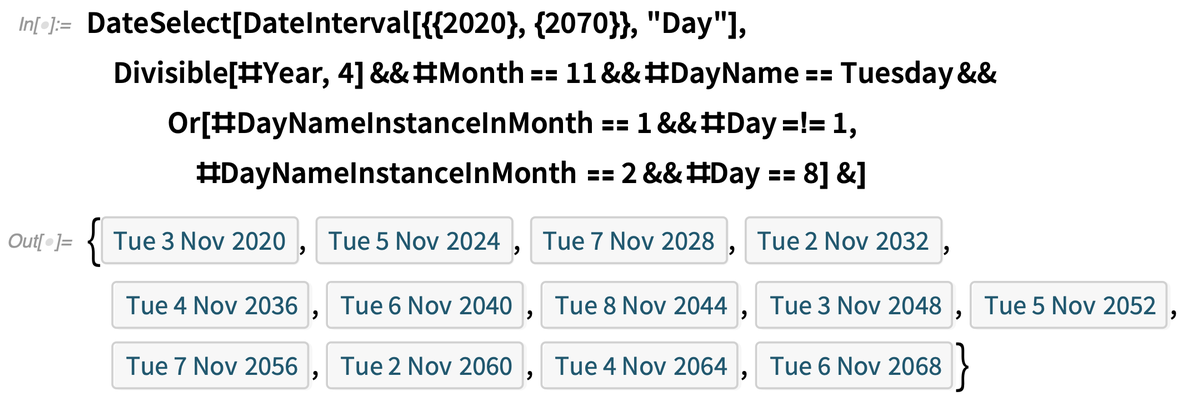
Dans un calendrier, on souhaite souvent sélectionner des dates qui répondent à un critère particulier. Dans la version 12.2, nous avons introduit la fonction DateSelect à cet effet. Ainsi, par exemple, nous pouvons sélectionner des dates dans un intervalle particulier qui satisfont le critère qu’elles sont des mercredis :

À titre d’exemple plus compliqué, nous pouvons convertir l’algorithme actuel de sélection des dates des élections présidentielles américaines en une forme calculable, puis l’utiliser pour déterminer les dates des 50 prochaines années :
Nouveau dans Geo
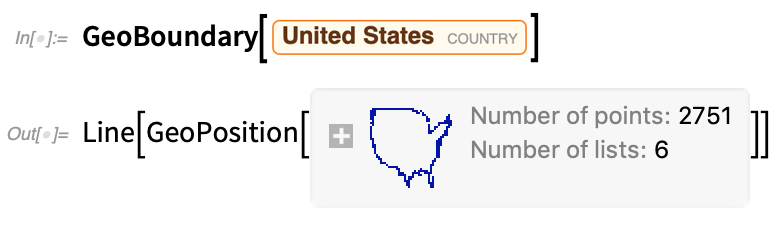
À l’heure actuelle, le langage Wolfram possède de solides capacités en matière de calcul et de visualisation géographiques. Mais nous continuons à développer nos fonctionnalité géographique. Dans la version 12.2, un ajout important est celui des statistiques spatiales (mentionnées ci-dessus) – qui sont entièrement intégrées à la géo. Mais il y a aussi quelques nouvelles primitives géographiques. La première est GeoBoundary, qui calcule les limites des objets :

Il y a aussi GeoPolygon, qui est une généralisation géographique complète des polygones ordinaires. L’un des problèmes délicats que GeoPolygon doit gérer est de savoir ce qui compte comme « intérieur » d’un polygone sur la Terre. Ici, il s’agit de choisir la plus grande zone (c’est-à-dire celle qui entoure le globe) :
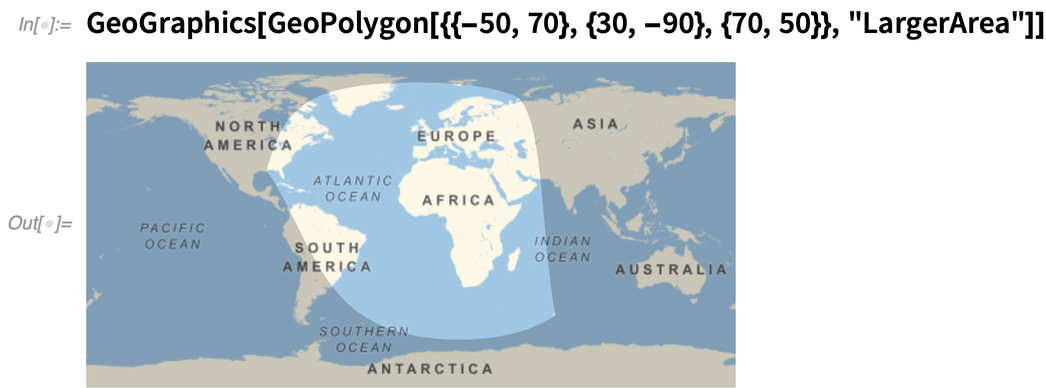
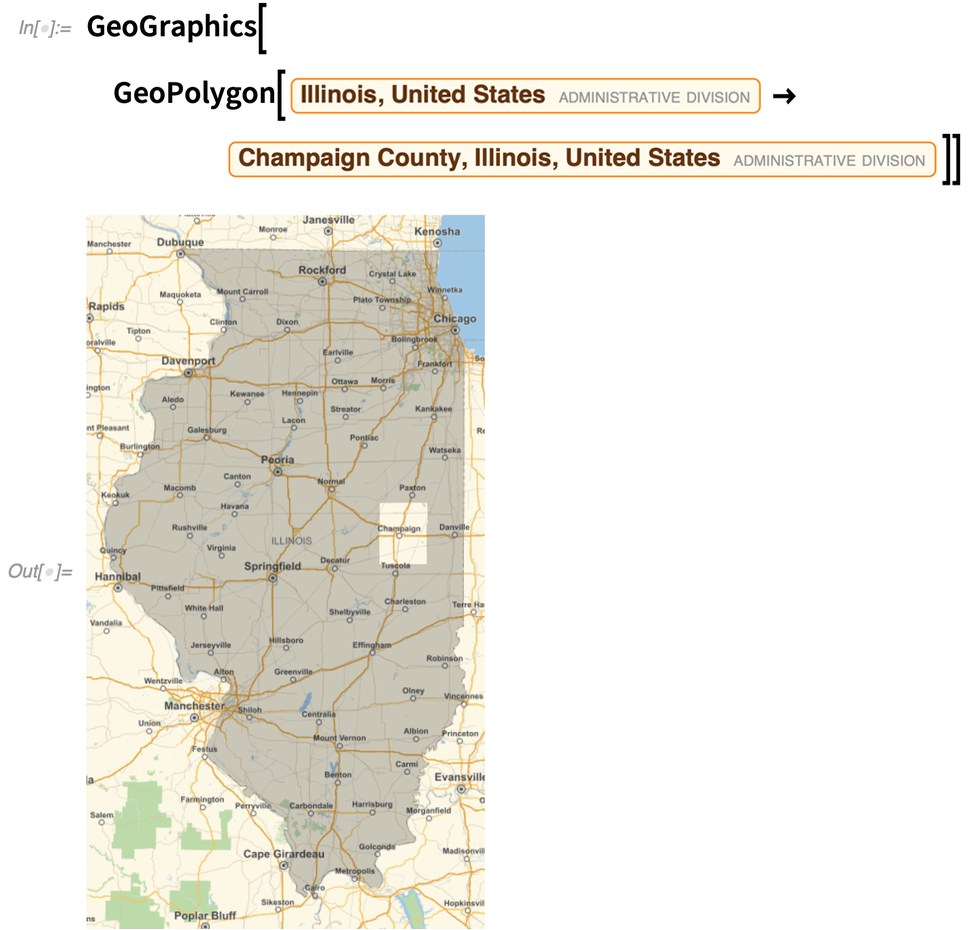
GeoPolygon peut également, comme Polygon, gérer des trous, ou en fait des niveaux arbitraires d’imbrication :
Mais la plus grande « attraction à venir » de la géo est le rendu complètement nouveau des graphiques et des cartes géo. La version 12.2 n’en est qu’à ses débuts (et n’est pas encore terminée), mais elle prend en charge, au moins à titre expérimental, le rendu vectoriel des cartes. Le gain le plus évident est que les cartes ont l’air beaucoup plus nettes et précises à toutes les échelles. Mais un autre avantage est notre capacité à introduire un nouveau style pour les cartes, et dans la version 12.2 nous incluons huit nouveaux styles de cartes.
Voici notre carte « à l’ancienne » :
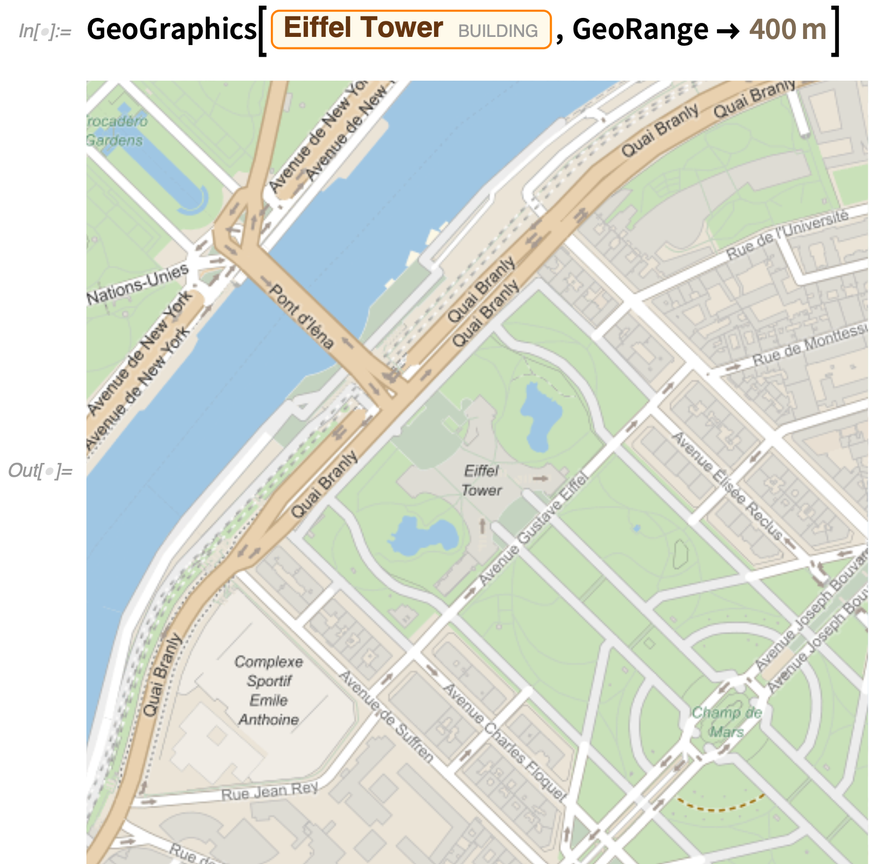
Voici la nouvelle version vectorielle de ce style « classique » :
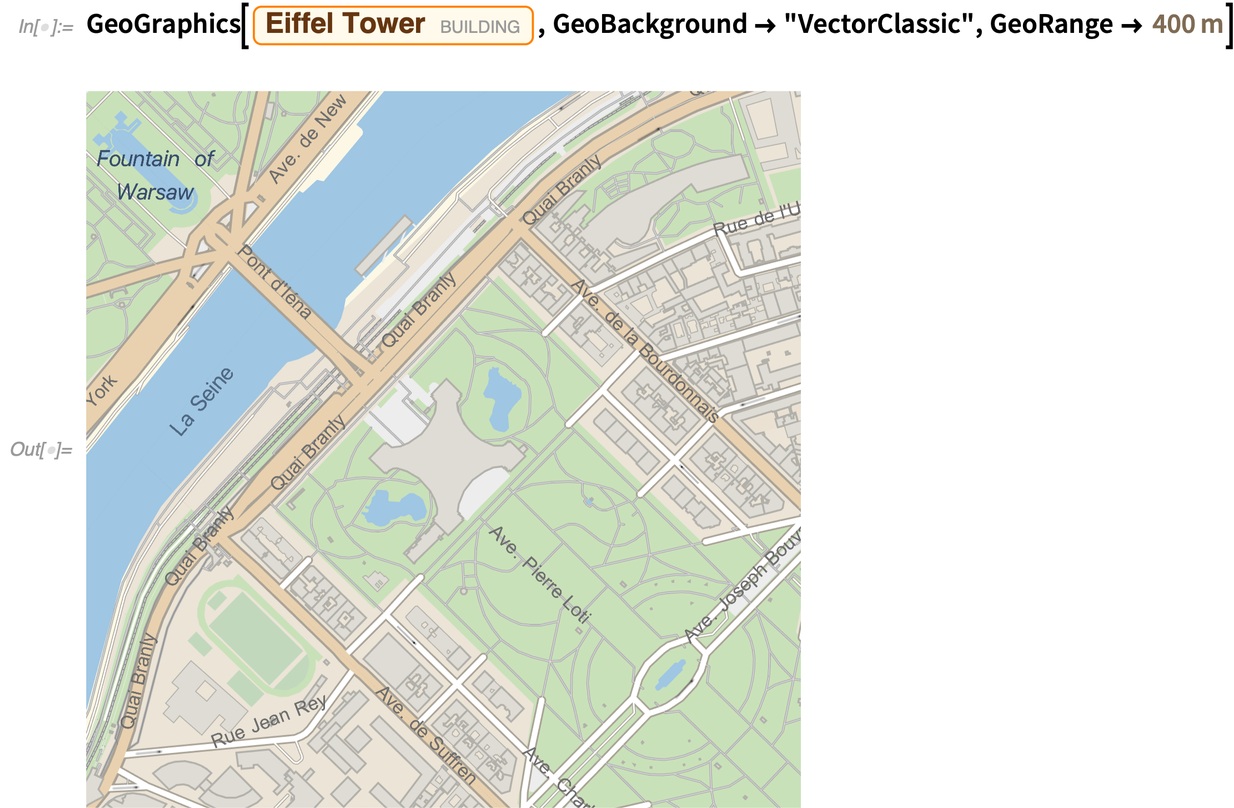
Voici un nouveau style (vectoriel), destiné au web :

Et voici un style « sombre », adapté à la superposition d’informations :
Importation de PDF
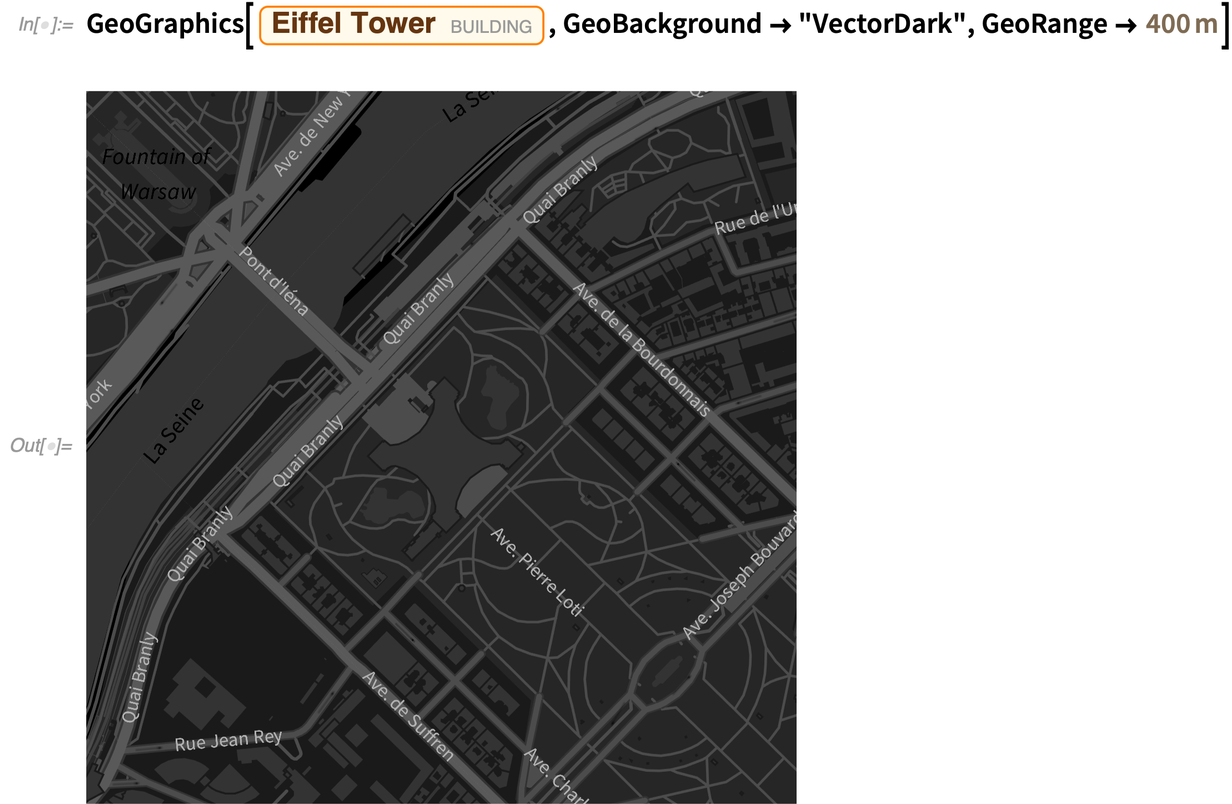
Vous voulez analyser un document au format PDF ? Depuis plus de dix ans, nous sommes en mesure d’extraire le contenu de base des fichiers PDF. Mais le format PDF est très complexe (et évolue), et de nombreux documents « dans la nature » ont une structure compliquée. Dans la version 12.2, cependant, nous avons considérablement étendu nos capacités d’importation de PDF, de sorte qu’il devient réaliste, par exemple, de prendre un article aléatoire d’arXiv et de l’importer :

Par défaut, vous obtiendrez une image haute résolution pour chaque page (dans ce cas particulier, les 100 pages).
Si vous voulez le texte, vous pouvez l’importer avec « Plaintext » :

Vous pouvez maintenant créer immédiatement un nuage de mots à partir des mots contenus dans le document :

Cela permet d’extraire toutes les images du papier et d’en faire un collage :

Vous pouvez obtenir les URLs de chaque page :
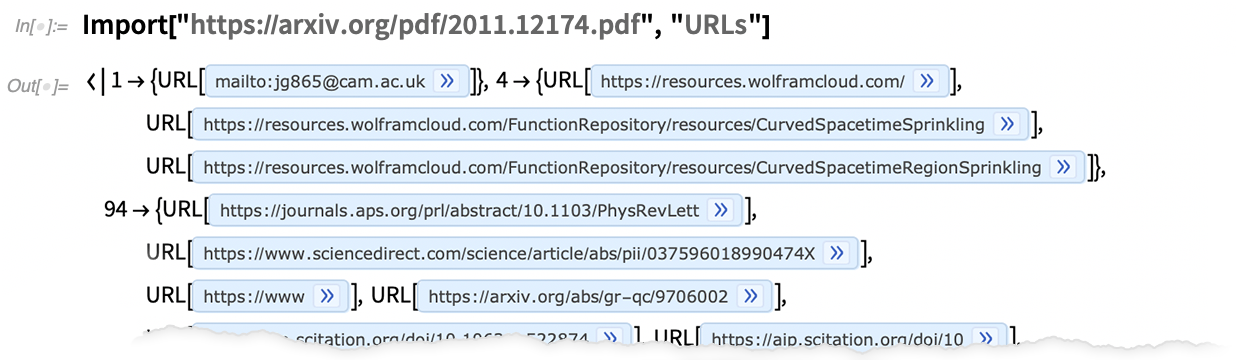
Maintenant, prenez les deux derniers, et obtenez des images de ces pages web :

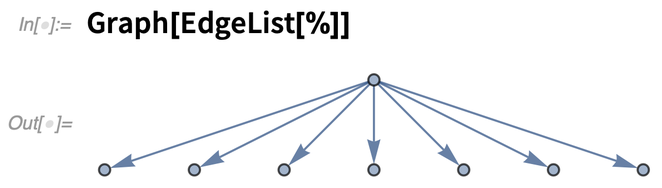
Selon la façon dont ils sont produits, les PDF peuvent avoir toutes sortes de structures. « ContentsGraph » donne un graphique représentant la structure globale détectée pour un document :

Et, oui, c’est vraiment un graphique :
Pour les PDF qui sont des formulaires à remplir, il y a plus de structure à importer. Ici, j’ai pris au hasard un formulaire gouvernemental non rempli sur le web. Import donne une association dont les clés sont les noms des champs – et si le formulaire avait été rempli, il aurait également donné leurs valeurs, de sorte que vous pourriez immédiatement faire une analyse sur eux :

Le dernier cri en matière d’optimisation convexe à l’échelle industrielle
Depuis la version 12.0, nous avons ajouté des fonctionnalités de pointe pour la résolution de problèmes d’optimisation à grande échelle. Une nouveauté est la superfonction ConvexOptimization, qui gère automatiquement le spectre complet de l’optimisation linéaire, linéaire-fractionnelle, quadratique, semi-définie et conique, en donnant à la fois des solutions optimales et leurs propriétés duales. Dans la version 12.1, nous avons ajouté la prise en charge des variables entières (c’est-à-dire l’optimisation combinatoire) ; dans la version 12.2, nous ajouterons également la prise en charge des variables complexes.
Mais les principales nouveautés de la version 12.2 en matière d’optimisation sont l’introduction de l’optimisation robuste et de l’optimisation paramétrique. L’optimisation robuste vous permet de trouver un optimum qui est valide sur toute une gamme de valeurs de certaines des variables. L’optimisation paramétrique vous permet d’obtenir une fonction paramétrique qui donne l’optimum pour toute valeur possible de paramètres particuliers. Ainsi, par exemple, cette fonction trouve l’optimum pour x, y pour toute valeur (positive) de α :

Évaluez maintenant la fonction paramétrique pour un α particulier :

Comme pour tout ce qui concerne le langage Wolfram, nous avons déployé beaucoup d’efforts pour que l’optimisation convexe s’intègre de manière transparente dans le reste du système : vous pouvez ainsi configurer des modèles de manière symbolique et transférer leurs résultats dans d’autres fonctions. Nous avons également inclus des solveurs d’optimisation convexe très puissants. Mais surtout si vous faites de l’optimisation mixte (c’est-à-dire réelle + entière), ou si vous traitez des problèmes vraiment énormes (par exemple, 10 millions de variables), nous vous donnons également accès à d’autres solveurs externes. Ainsi, par exemple, vous pouvez configurer votre problème en utilisant Wolfram Language comme « langage de modélisation algébrique », puis (en supposant que vous disposiez des licences externes appropriées) en définissant simplement Method sur, disons, « Gurobi » ou « Mosek« , vous pouvez immédiatement exécuter votre problème avec un solveur externe. (Et, soit dit en passant, nous avons maintenant un cadre ouvert pour ajouter plus de solveurs.)
Prise en charge des combinateurs et d’autres éléments de base formels
On peut dire que toute l’idée des expressions symboliques (et de leurs transformations) sur lesquelles nous nous appuyons tant dans le langage Wolfram provient des combinateurs, qui viennent fêter son centenaire le 7 décembre 2020. La version des expressions symboliques que nous avons dans le Wolfram Language est à bien des égards beaucoup plus avancée et utilisable que les combinateurs bruts. Mais dans la version 12.2, en partie pour célébrer les combinateurs, nous avons voulu ajouter un cadre pour les combinateurs bruts.
Ainsi, nous avons maintenant, par exemple, CombinatorS, CombinatorK, etc., rendus de manière appropriée :

Mais comment représenter l’application d’un combinateur à un autre ? Aujourd’hui, nous écrivons quelque chose comme :

Mais aux débuts de la logique mathématique, il existait une convention différente, qui impliquait une application associative gauche, dans laquelle on s’attendait à ce que le « style combinateur » génère des « fonctions » et non des « valeurs » en appliquant des fonctions aux choses. Dans la version 12.2, nous introduisons donc un nouvel « opérateur d’application », Application, affiché sous la forme (et saisi sous la forme \[Application] or ap ):


D’ailleurs, je m’attends à ce que Application – en tant que nouveau « constructeur » de base – ait une variété d’utilisations (sans parler d' »applications ») dans la mise en place de structures générales dans le langage Wolfram.
Les règles pour les combinateurs sont triviales à spécifier en utilisant des transformations de motifs dans le Wolfram Language :
![]()
Mais on peut aussi penser aux combinateurs de manière plus « algébrique » comme définissant des relations entre des expressions – et il y a maintenant une théorie dans AxiomaticTheory pour cela.
Et dans 12.2 quelques autres théories ont été ajoutées à AxiomaticTheory, ainsi que plusieurs nouvelles propriétés.
La géométrie euclidienne devient interactive
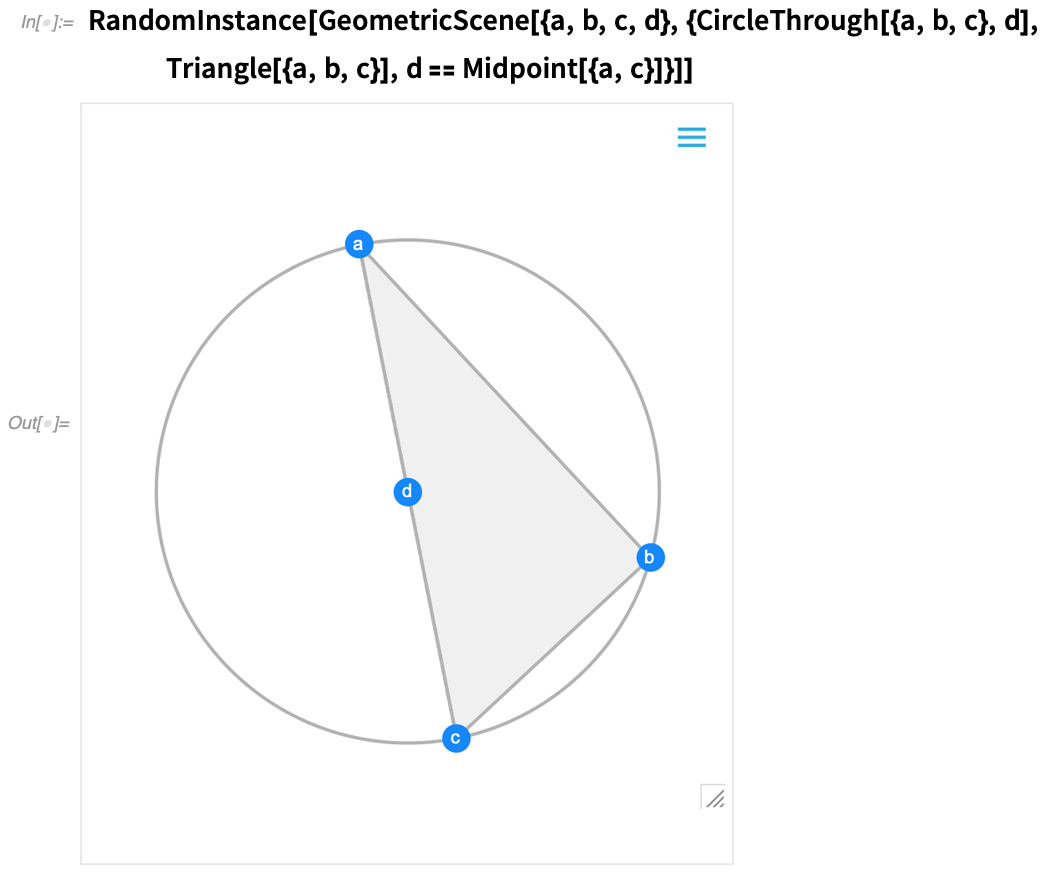
L’une des avancées majeures de la version 12.0 a été l’introduction d’une représentation symbolique pour la géométrie euclidienne : vous spécifiez une GeometricScene symbolique, en donnant une variété d’objets et de contraintes, et le Wolfram Language peut la « résoudre » et dessiner un diagramme d’une instance aléatoire qui satisfait aux contraintes. Dans la version 12.2, nous avons rendu ce processus interactif, de sorte que vous pouvez déplacer les points du diagramme, et tout sera (si possible) réorganisé de manière interactive afin de maintenir les contraintes.
Voici une instance aléatoire d’une scène géométrique simple :
Si vous déplacez l’un des points, les autres points seront réarrangés de manière interactive afin de maintenir les contraintes définies dans la représentation symbolique de la scène géométrique :
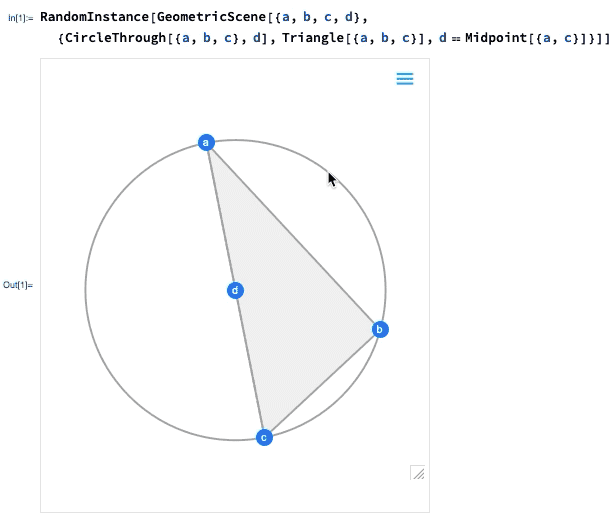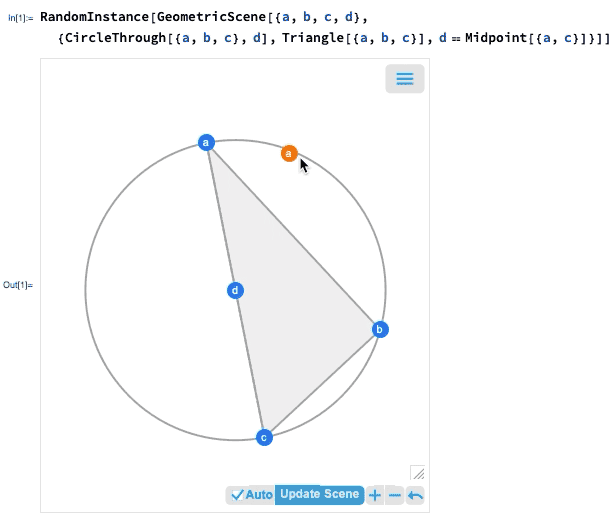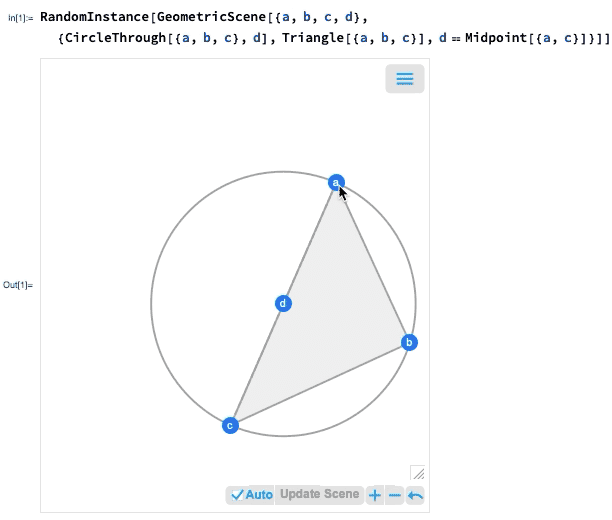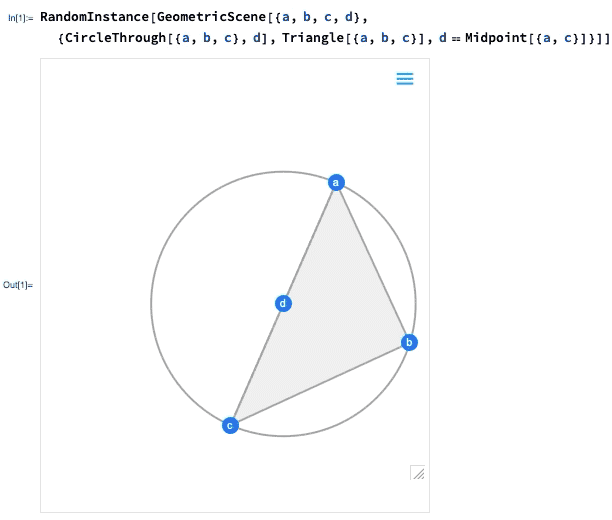
Qu’est-ce qui se passe vraiment ici ? En gros, la géométrie est convertie en algèbre. Et si vous voulez, vous pouvez obtenir la formulation algébrique :
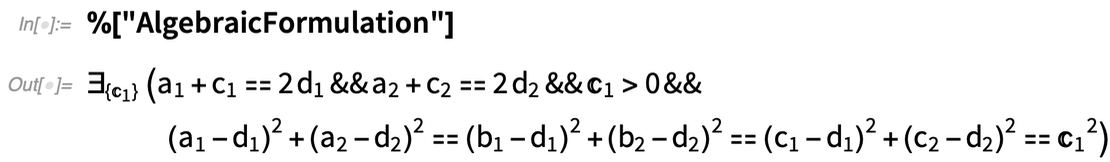
En plus de l’interactivité, une autre grande nouveauté de la version 12.2 est la possibilité de traiter non seulement des scènes géométriques complètes, mais aussi des constructions géométriques qui impliquent de construire une scène en plusieurs étapes. Voici un exemple, tiré directement d’Euclide :

La première image que vous obtenez est en fait le résultat de la construction. Et comme toutes les autres scènes géométriques, elle est maintenant interactive. Mais si vous passez la souris dessus, vous obtiendrez des commandes qui vous permettront de passer aux étapes précédentes :
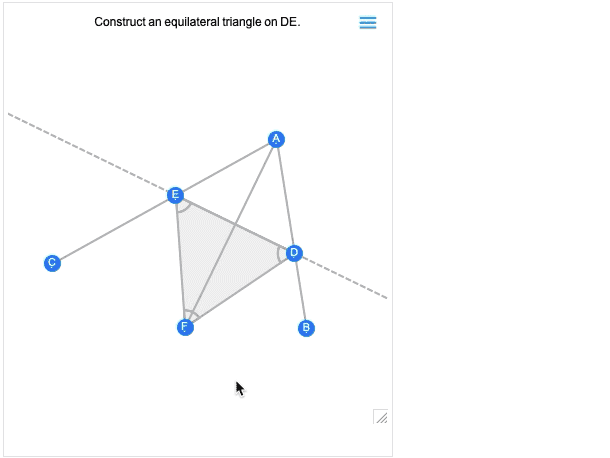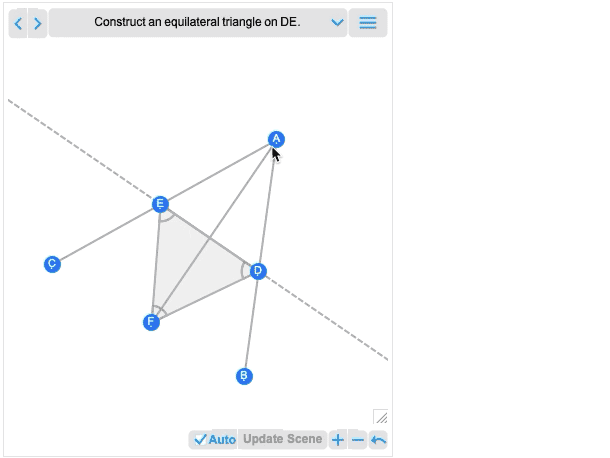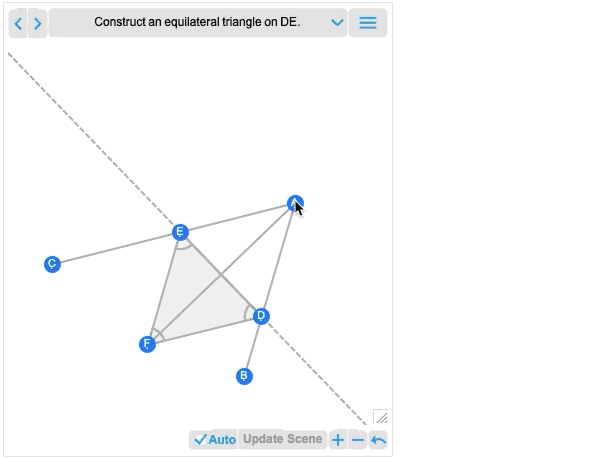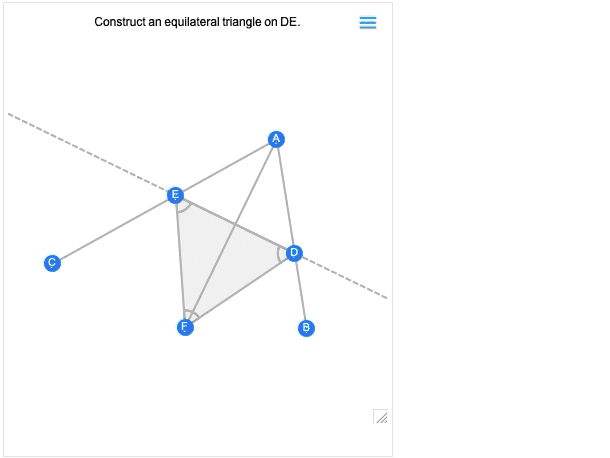
Déplacez un point à une étape antérieure, et vous verrez quelles conséquences cela a sur les étapes ultérieures de la construction.La géométrie d’Euclide est le tout premier système axiomatique des mathématiques que nous connaissons. La géométrie d’Euclide est le tout premier système axiomatique des mathématiques que nous connaissons. Plus de 2000 ans plus tard, il est donc passionnant de pouvoir enfin le rendre calculable. (Et, oui, il sera éventuellement connecté avec AxiomaticTheory, FindEquationalProof, etc.)
Mais en reconnaissance de l’importance de la formulation originale de la géométrie d’Euclide, nous avons ajouté des versions calculables de ses propositions (ainsi qu’un tas d’autres « théorèmes géométriques célèbres »). L’exemple ci-dessus s’avère être la proposition 9 du livre 1 d’Euclide. Et maintenant, par exemple, nous pouvons obtenir l’énoncé original de cette proposition en grec :

Et le voici en langage Wolfram moderne, dans une forme qui peut être comprise à la fois par les ordinateurs et les humains :

Encore plus de types de connaissances pour la base de connaissances
Une part importante de l’histoire du langage Wolfram en tant que langage informatique à part entière est son accès à notre vaste base de connaissances sur le monde. Cette base de connaissances est continuellement mise à jour et élargie, et en effet, depuis la version 12.1, pratiquement tous les domaines ont vu leurs données (et souvent une quantité importante) mises à jour, ou des entités ajoutées ou modifiées.
Mais à titre d’exemple de ce qui a été fait, permettez-moi de mentionner quelques ajouts. Un domaine qui a reçu beaucoup d’attention est celui de l’alimentation. Nous disposons aujourd’hui de données sur plus d’un demi-million d’aliments (à titre de comparaison, une grande épicerie typique stocke environ 30 000 types d’articles). Choisissez un aliment au hasard :

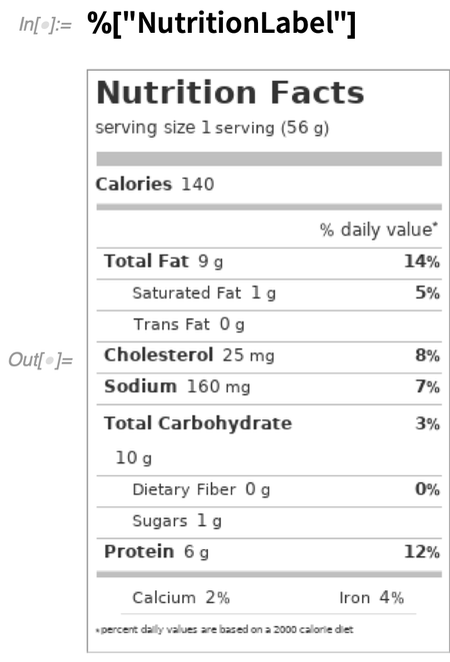
Maintenant, générez une étiquette nutritionnelle :
Autre exemple, un nouveau type d’entité a été ajouté : les effets physiques. En voici quelques uns au hasard :

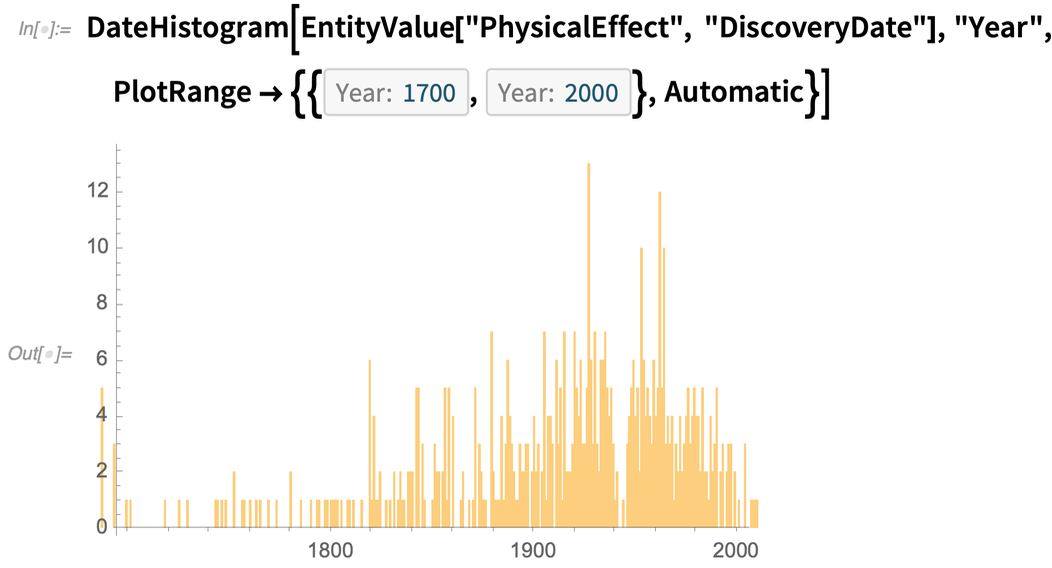
Et comme exemple de ce que l’on peut faire avec toutes les données de ce domaine, voici un histogramme des dates auxquelles ces effets ont été découverts :
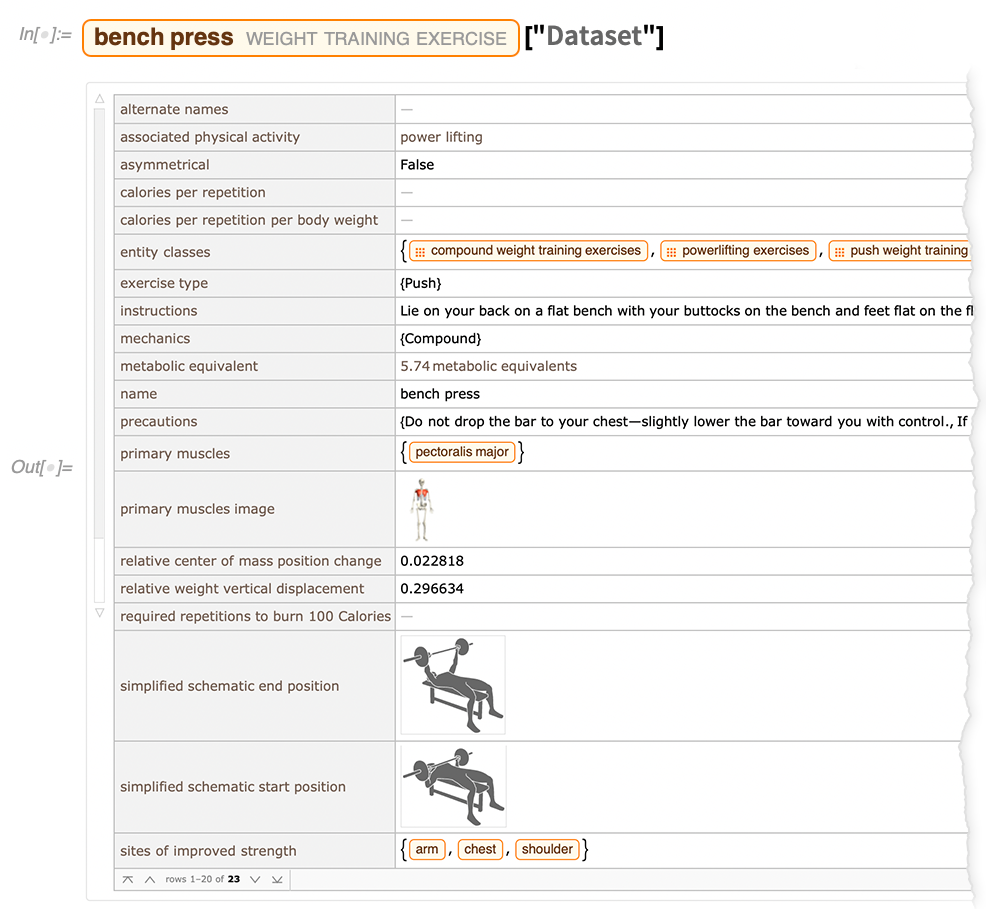
Comme autre exemple de ce que nous avons fait, il y a maintenant ce que l’on pourrait appeler (avec un certain humour) un domaine « d’haltérophilie » – les exercices de musculation :
Une caractéristique importante de la base de connaissances Wolfram est qu’elle contient des objets symboliques, qui peuvent représenter non seulement des « données ordinaires » – comme des nombres ou des chaînes de caractères – mais aussi un contenu informatique complet. À titre d’exemple, la version 12.2 permet d’accéder au projet Wolfram Demonstrations – avec tous ses codes et carnets de notes actifs en langage Wolfram – directement dans la base de connaissances. Voici quelques démonstrations choisies au hasard :

Les valeurs des propriétés peuvent être des objets interactifs dynamiques :
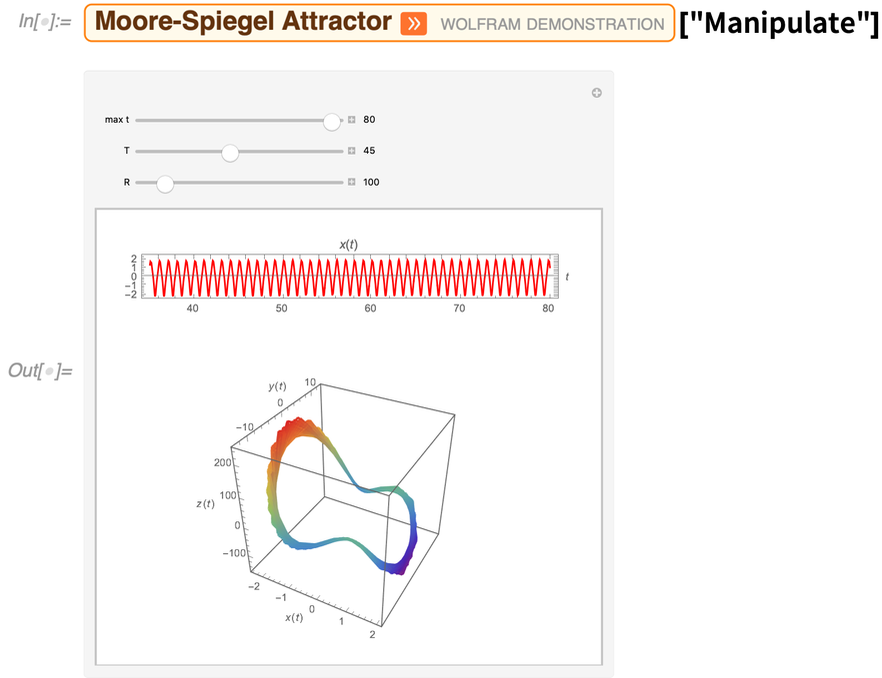
Et comme tout est calculable, on peut par exemple faire immédiatement un collage d’images de toutes les démonstrations sur un sujet particulier :

L’histoire continue de l’apprentissage automatique
Cela fait presque 7 ans que nous avons introduit Classify et Predict, , et que nous avons commencé à intégrer pleinement les réseaux neuronaux dans le langage Wolfram. Nous avons suivi deux grandes orientations : la première consiste à développer des » superfonctions « , comme Classify et Predict, qui exécutent – aussi automatiquement que possible – des opérations basées sur l’apprentissage automatique. La deuxième direction consiste à fournir un cadre symbolique puissant pour tirer parti des dernières avancées en matière de réseaux neuronaux (notamment grâce au Wolfram Neural Net Repository) et pour permettre un développement et une expérimentation continus et flexibles.
La version 12.2 a progressé dans ces deux domaines. Un exemple de nouvelle superfonction est FaceRecognize. Donnez-lui un petit nombre d’exemples de visages étiquetés, et elle essaiera de les identifier dans des images, des vidéos, etc. Obtenons des données d’entraînement à partir de recherches sur le Web (et, oui, elles sont quelque peu bruitées) :

Créez maintenant une reconnaissance de visage avec ces données d’entraînement :

Nous pouvons maintenant l’utiliser pour savoir qui est à l’écran dans chaque image d’une vidéo :

Maintenant, tracez les résultats :

Dans le référentiel Wolfram Neural Net, il y a un flux régulier de nouveaux réseaux ajoutés. Depuis la version 12.1, environ 20 nouveaux types de réseaux ont été ajoutés, y compris de nombreux nouveaux réseaux transformateurs, ainsi que EfficientNet et, par exemple, des extracteurs de caractéristiques tels que BioBERT et SciBERT spécifiquement formés sur du texte provenant d’articles scientifiques.
Dans chaque cas, les réseaux sont immédiatement accessibles – et utilisables – via NetModel. L’affichage visuel des réseaux a été mis à jour dans la version 12.2 :
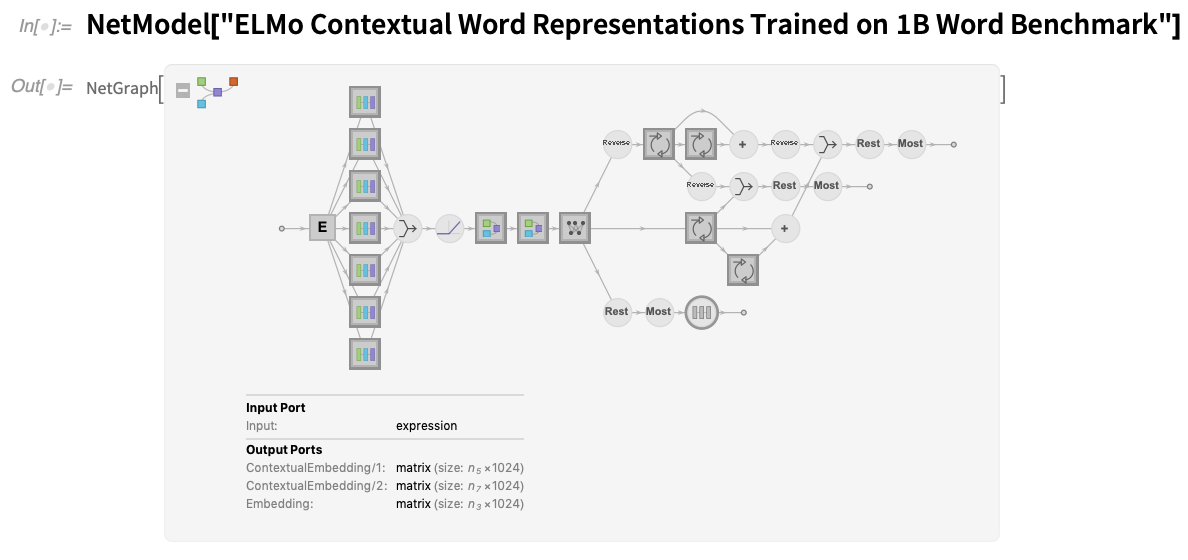
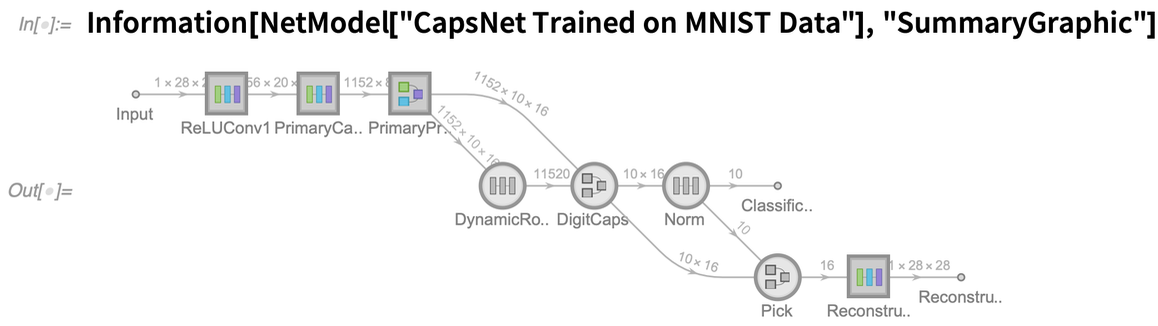
Il y a beaucoup de nouvelles icônes, mais il y a aussi maintenant une convention claire selon laquelle les cercles représentent les éléments fixes d’un réseau, tandis que les carrés représentent les éléments entraînables. Qu’il s’agisse d’un réseau provenant de NetModel ou d’un réseau que vous avez construit vous-même (ou une combinaison des deux), il est souvent pratique d’extraire le « graphique récapitulatif » du réseau, par exemple pour pouvoir le mettre dans une documentation ou une publication. Information fournit plusieurs niveaux de graphiques de synthèse :
Plusieurs ajouts importants à notre cadre de base de réseau neuronal élargissent la gamme des fonctionnalités de réseau neuronal auxquelles nous pouvons accéder. La première est que dans la version 12.2, nous disposons d’encodeurs natifs pour les graphiques et les séries chronologiques. Ainsi, ici, par exemple, nous réalisons un tracé de l’espace des caractéristiques de 20 graphiques aléatoires nommés :

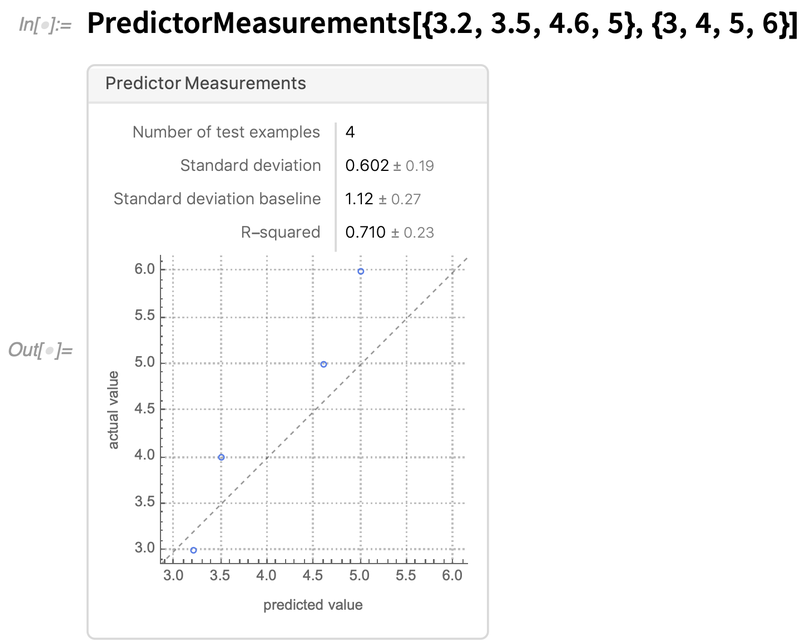
Une autre amélioration de la structure concerne les diagnostics pour les modèles. Nous avons introduit PredictorMeasurements et ClassifierMeasurements il y a plusieurs années pour fournir une représentation symbolique de la performance des modèles. Dans la version 12.2, en réponse à de nombreuses demandes, nous avons rendu possible l’utilisation de prédictions finales, plutôt que d’un modèle, pour créer un objet PredictorMeasurements, et nous avons rationalisé l’apparence et le fonctionnement des objets PredictorMeasurements :
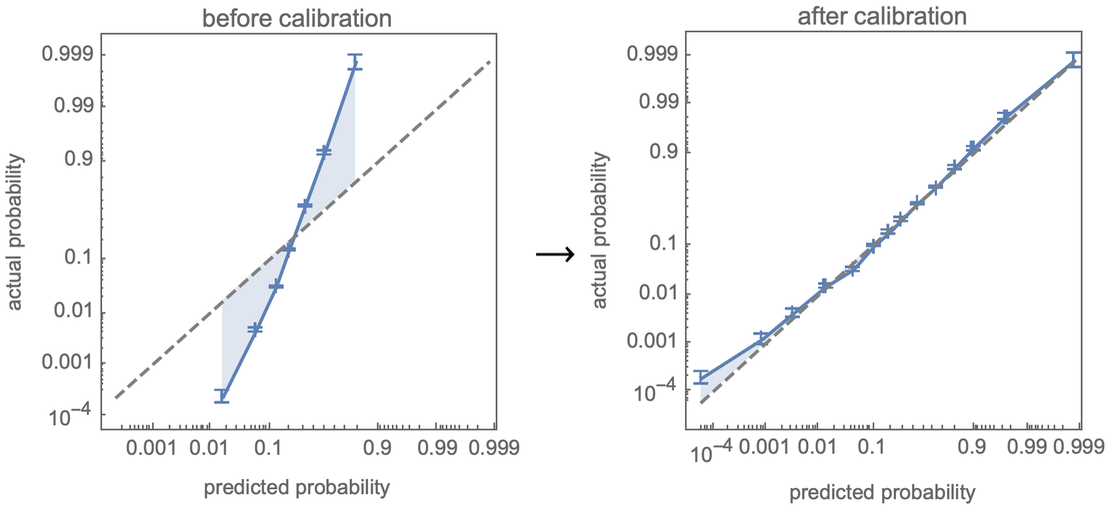
Une nouvelle fonctionnalité importante de ClassifierMeasurements est la possibilité de calculer une courbe d’étalonnage qui compare les probabilités réelles observées à partir de l’échantillonnage d’un ensemble de test avec les prédictions du classificateur. Mais ce qui est encore plus important, c’est que Classify calibre automatiquement ses probabilités, en essayant en fait de « sculpter » la courbe de calibration :
La version 12.2 marque également le début d’une mise à jour majeure de la manière dont les réseaux neuronaux peuvent être construits. La configuration fondamentale a toujours été d’assembler une certaine collection de couches qui exposent ce qui revient à des indices de tableaux connectés par des arêtes explicites dans un graphe. La version 12.2 introduit maintenant FunctionLayer, qui vous permet de donner quelque chose de beaucoup plus proche du code ordinaire du Wolfram Language. À titre d’exemple, voici une couche de fonction particulière :

Et voici la représentation de cette couche de fonction comme un NetGraph explicite :
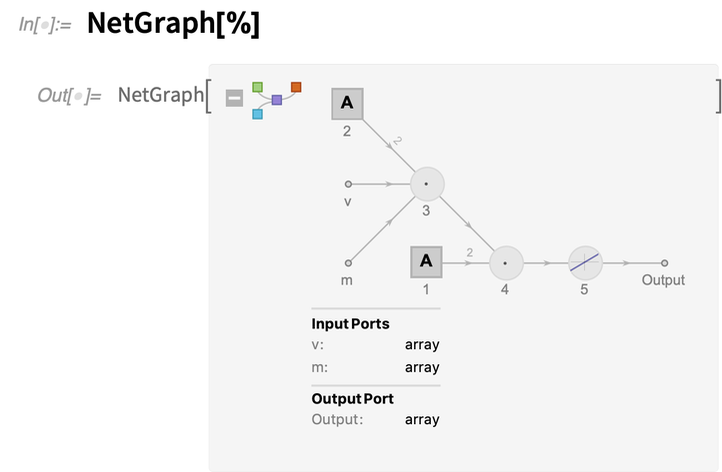
v et m sont nommés « ports d’entrée ». Le tableau NetArray – indiqué par les icônes carrées dans le graphe du réseau – est un tableau apprenable, contenant ici seulement deux éléments.
Dans certains cas, il est plus facile d’utiliser l’approche de programmation « par blocs » (ou « graphique ») en connectant simplement les couches entre elles (et nous avons travaillé dur pour nous assurer que les connexions puissent être faites aussi automatiquement que possible). Mais il y a aussi des cas où il est plus facile d’utiliser l’approche de programmation « fonctionnelle » de FunctionLayer. Pour l’instant, FunctionLayer ne prend en charge qu’un sous-ensemble des constructions disponibles dans le Wolfram Language, bien qu’il comprenne déjà de nombreuses opérations de programmation fonctionnelle et de tableaux standard, et que d’autres seront ajoutées à l’avenir.
Une caractéristique importante de FunctionLayer est que le réseau neuronal qu’il produit sera aussi efficace que n’importe quel autre réseau neuronal, et pourra fonctionner sur les GPU, etc. Mais que pouvez-vous faire avec les constructions du Wolfram Language qui ne sont pas encore supportées nativement par FunctionLayer ? Dans la version 12.2, nous ajoutons une nouvelle fonction expérimentale – CompiledLayer – qui étend la gamme de codes Wolfram Language pouvant être traités efficacement.
Il est peut-être utile d’expliquer un peu ce qui se passe à l’intérieur. Notre cadre principal de réseau neuronal est essentiellement une couche symbolique qui organise les choses pour une mise en œuvre optimisée de bas niveau, en utilisant actuellement MXNet. FunctionLayer traduit efficacement certaines constructions du langage Wolfram directement en MXNet. CompiledLayer traduit le Wolfram Language en LLVM, puis en code machine, et l’insère dans le processus d’exécution de MXNet. CompiledLayer utilise le nouveau compilateur Wolfram Language et ses mécanismes étendus d’inférence de type et de déclaration de type.
Bon, disons que l’on a construit un magnifique réseau neuronal dans notre cadre Wolfram Language. Tout est configuré pour que le réseau puisse être immédiatement utilisé dans toute une série de superfonctions Wolfram Language (Classify, FeatureSpacePlot, AnomalyDetection, FindClusters, …). Mais qu’en est-il si l’on veut utiliser le réseau de manière « autonome » dans un environnement externe ? Dans la version 12.2, nous introduisons la possibilité d’exporter essentiellement n’importe quel réseau dans la représentation standard ONNX récemment développée.
Et une fois que l’on a un réseau sous forme ONNX, on peut utiliser tout l’écosystème des outils externes pour le déployer dans une grande variété d’environnements. Un exemple notable – qui est maintenant un processus assez rationalisé – consiste à prendre un réseau neuronal entièrement créé en Wolfram Language et à l’exécuter en CoreML sur un iPhone, de sorte qu’il puisse par exemple être directement inclus dans une application mobile.
Carnets de formulaires
Quelle est la meilleure façon de collecter du matériel structuré ? Si vous voulez juste obtenir quelques éléments, un formulaire ordinaire créé avec FormFunction (et par exemple déployé dans le nuage) peut bien fonctionner. Mais qu’en est-il si vous essayez de collecter un matériel plus long et plus riche ?
Par exemple, disons que vous créez un quiz où vous voulez que les étudiants entrent toute une séquence de réponses complexes. Ou bien vous créez un modèle dans lequel les gens doivent remplir de la documentation sur quelque chose. Dans ces cas, vous avez besoin d’un nouveau concept que nous introduisons dans la version 12.2 : les carnets de formulaires.
Un cahier de formulaires est essentiellement un cahier qui est configuré pour être utilisé comme un « formulaire » complexe, où les entrées dans le formulaire peuvent être tous les types de choses que vous avez l’habitude d’avoir dans un cahier.Le flux de travail de base pour les cahiers de formulaires est le suivant. Tout d’abord, vous créez un cahier de formulaires, en définissant les différents « éléments de formulaire » (ou zones) que vous souhaitez que l’utilisateur du cahier de formulaires remplisse. Dans le cadre du processus de création, vous définissez ce que vous voulez qu’il advienne du matériel que l’utilisateur du carnet de formulaires saisit lorsqu’il utilise le carnet de formulaires (par exemple, placer le matériel dans une base de données Wolfram Data Drop, envoyer le matériel à une API en nuage, envoyer le matériel en tant qu’expression symbolique par courriel, etc.)
Une fois que vous avez créé le cahier de formulaires, vous générez une version active qui peut être envoyée à la personne qui utilisera le cahier de formulaires. Une fois que quelqu’un a rempli son matériel dans sa copie du cahier de formulaires déployé, il appuie sur un bouton, généralement “Submit”, et son matériel est alors envoyé sous forme d’expression symbolique structurée à la destination spécifiée par l’auteur du cahier de formulaires.
Il est peut-être utile de mentionner comment les carnets de formulaires sont liés à quelque chose qui semble similaire : les carnets de modèles. Dans un sens, un carnet de modèles fait l’inverse d’un carnet de formulaires. Dans un cahier de formulaires, l’utilisateur saisit des données qui seront ensuite traitées. Dans le cas d’un cahier modèle, l’ordinateur génère du matériel qui sera ensuite utilisé pour remplir un cahier dont la structure est définie par le cahier modèle.
OK, alors comment commencer avec les cahiers de formulaires ? Il suffit d’aller dans File > New > Programmatic Notebook > Form Notebook Authoring:
Il s’agit simplement d’un cahier, dans lequel vous pouvez saisir le contenu que vous souhaitez, par exemple une explication de ce que vous voulez que les gens fassent lorsqu’ils « remplissent » le cahier de formulaires. Mais il existe des cellules spéciales ou des séquences de cellules dans le cahier de formulaires que nous appelons « éléments de formulaire » et « zones de cahier éditables ». Ce sont ces éléments que l’utilisateur du cahier de formulaires « remplit » pour entrer ses « réponses », et le matériel qu’il fournit est envoyé lorsqu’il appuie sur le bouton « Soumettre » (ou toute autre action finale qui a été définie).
Dans le cahier d’écriture, la barre d’outils vous propose un menu d’éléments de formulaire que vous pouvez insérer :
Prenons l’exemple du « champ de saisie » :
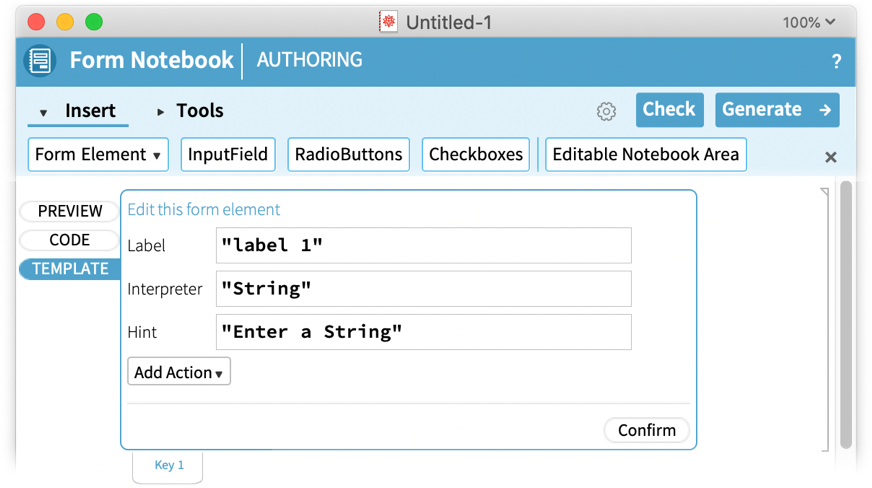
Que signifie tout cela ? Fondamentalement, un élément de formulaire est représenté par une expression symbolique très souple en Wolfram Language, ce qui vous permet de spécifier l’expression souhaitée. Vous pouvez donner une étiquette et une indication à mettre dans le champ de saisie. Mais c’est avec l’Interpreter que vous commencez à voir la puissance du Wolfram Language. En effet, c’est l’Interpreter qui prend tout ce que l’utilisateur des carnets de formulaires entre dans ce champ de saisie et l’interprète comme un objet calculable. Le défaut est de le traiter comme une chaîne de caractères. Mais cela peut être par exemple un « Country » ou une « MathExpression« . Et avec ces choix, le matériel sera automatiquement interprété comme un pays, une expression mathématique, etc., l’utilisateur étant généralement invité si sa saisie ne peut pas être interprétée comme spécifiée.
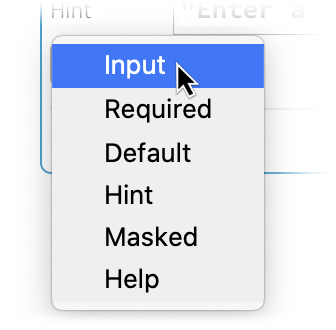
Il existe de nombreuses options concernant les détails du fonctionnement d’un champ de saisie. Certaines d’entre elles sont proposées dans le menu Ajouter une action :
Mais qu’est-ce que cet élément de formulaire ? Appuyez sur l’onglet CODE à gauche pour le voir :

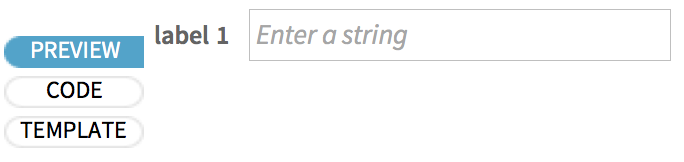
Qu’est-ce qu’un utilisateur du cahier de formulaires verrait ici ? Appuyez sur l’onglet PREVIEW pour le découvrir :
Outre les champs de saisie, il existe de nombreux autres éléments de formulaire possibles. Il y a des choses comme les cases à cocher, les boutons radio et les curseurs. Et en général, il est possible d’utiliser n’importe laquelle des riches constructions d’interface utilisateur symbolique qui existent dans le Wolfram Language.
Une fois que vous avez fini de rédiger, vous appuyez sur Générer pour générer un carnet de formulaires prêt à être fourni aux utilisateurs pour qu’ils le remplissent. Les paramètres définissent des éléments tels que la manière dont l’action « submit » doit être spécifiée, et ce qui doit être fait lorsque le carnet de formulaires est soumis :

Quel est donc le « résultat » d’un cahier de formulaires soumis ? Il s’agit essentiellement d’une association qui indique ce qui a été rempli dans chaque zone du cahier de formulaires. (Les zones sont identifiées par des clés dans l’association qui ont été spécifiées lorsque les zones ont été définies pour la première fois dans le cahier de rédaction).
Voyons comment cela fonctionne dans un cas simple. Voici le cahier de création d’un cahier de formulaires :
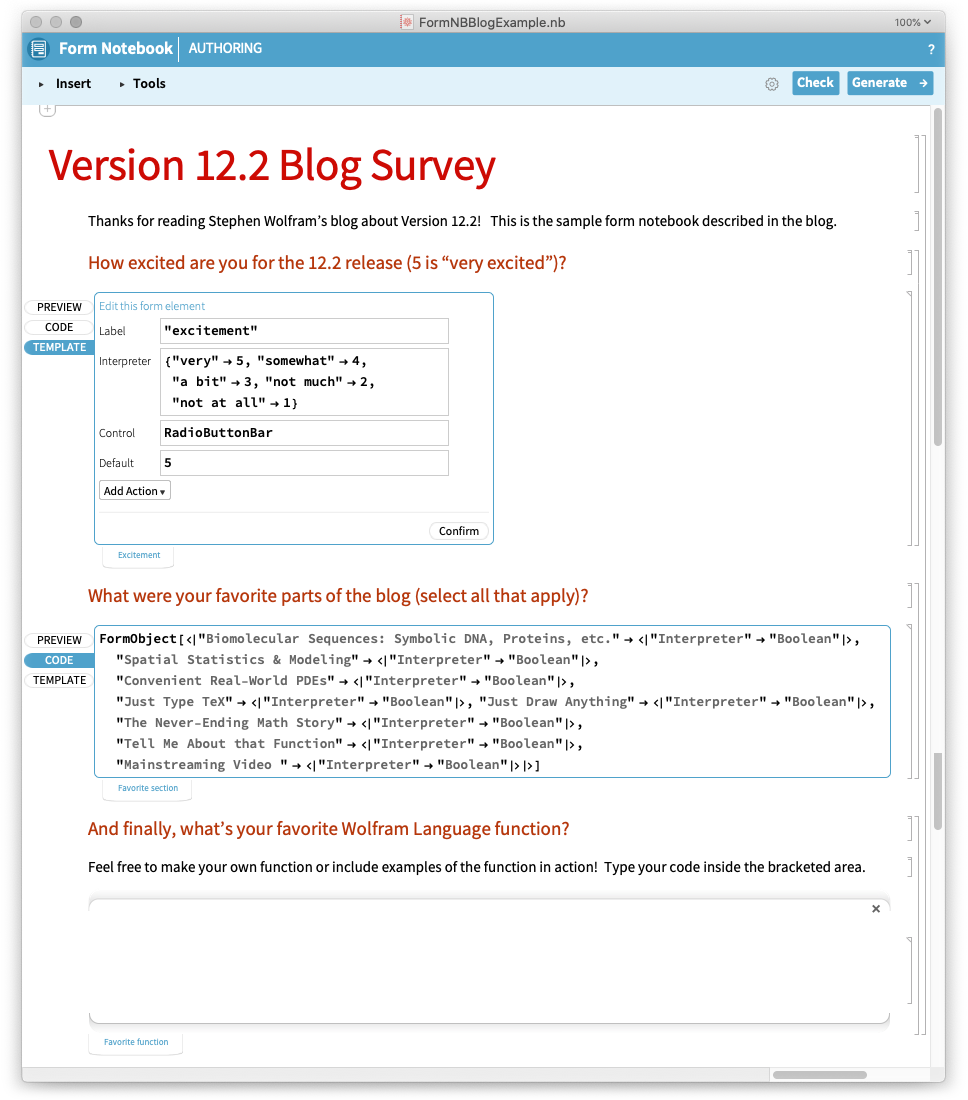
Voici le cahier de formulaires généré, prêt à être rempli :
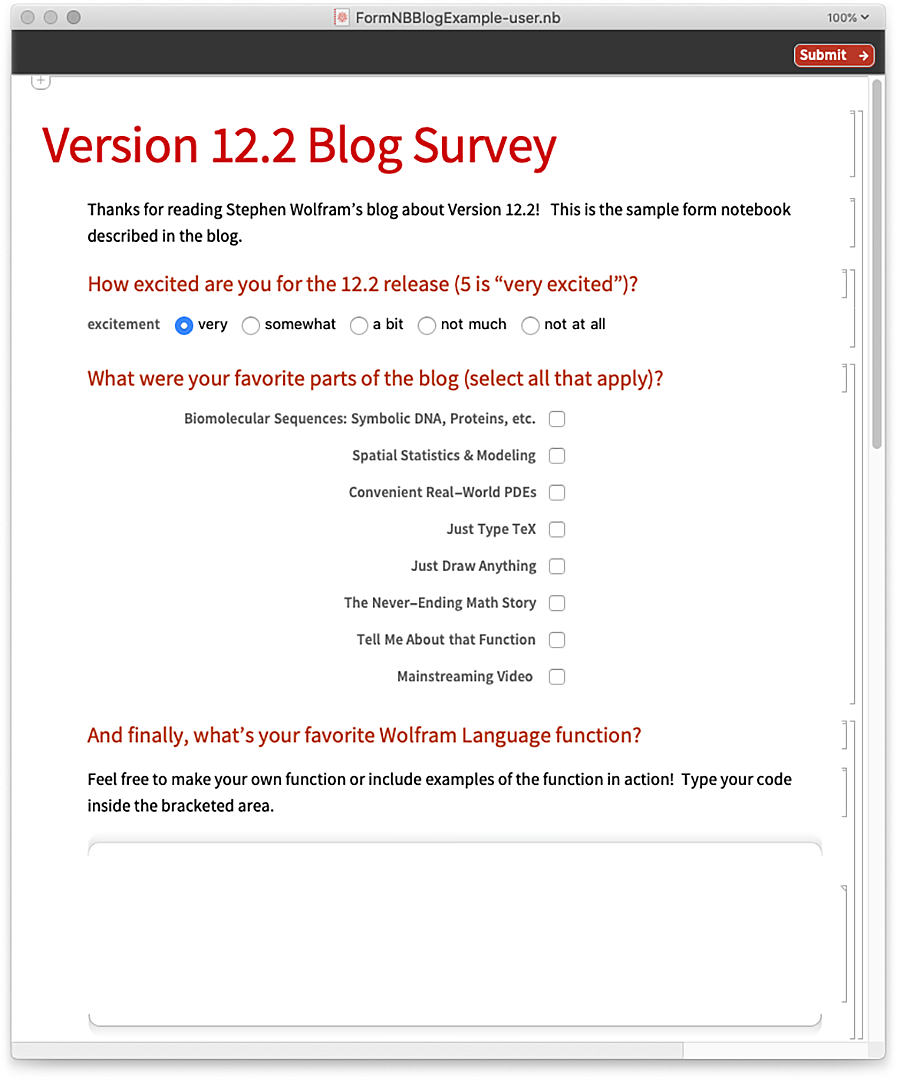
Voici un exemple de la façon dont le cahier de formulaires pourrait être rempli :
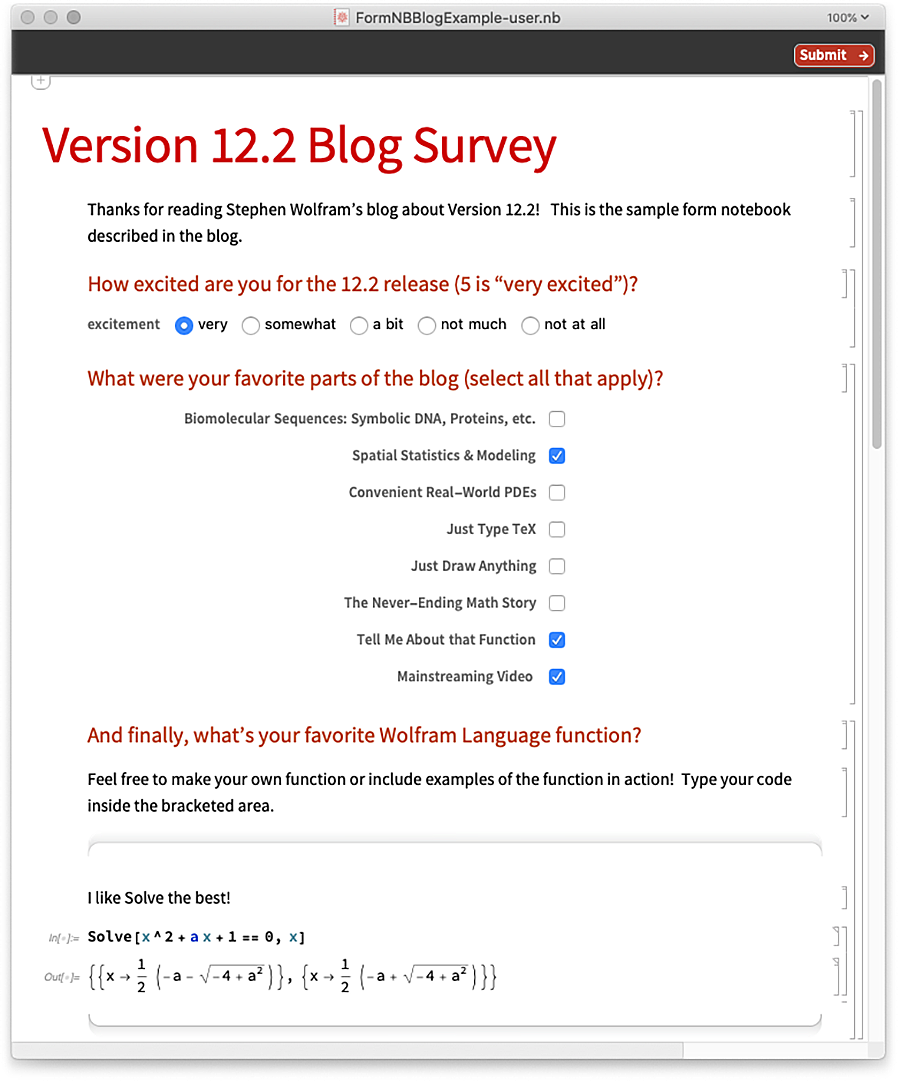
Et c’est ce qui « revient » quand on appuie sur Submit :

Pour les tests, vous pouvez simplement placer cette association de manière interactive dans un carnet de notes. Mais dans la pratique, il est plus courant d’envoyer l’association à une base de données, de la stocker dans un objet en nuage ou, plus généralement, de la placer dans un endroit plus « centralisé ».
Remarquez qu’à la fin de cet exemple, nous avons une zone de carnet éditable, où vous pouvez entrer le contenu du carnet en forme libre (avec des cellules, des titres, du code, des résultats, etc.) qui sera capturé lorsque le carnet de formulaires sera soumis. Comme premier exemple, les divers carnets de soumission pour le Wolfram Function Repository, le Wolfram Demonstrations Project, etc. deviennent des carnets de formulaires. Nous nous attendons également à ce que les carnets de formulaires soient beaucoup utilisés dans le cadre de l’enseignement. Et dans ce cadre, nous construisons un système qui utilise le langage Wolfram pour évaluer les réponses dans les carnets de formulaires (et ailleurs).
Vous pouvez en voir les prémices dans la version 12.2 avec la fonction expérimentale AssessmentFunction – qui peut être accrochée aux carnets de formulaires un peu comme Interpreter. Mais même sans les capacités complètes prévues pour AssessmentFunction, il y a toujours une quantité incroyable de choses qui peuvent être faites – dans des contextes éducatifs et autres – en utilisant des carnets de formulaires.
Il est bon de comprendre, en passant, que les carnets de formulaires sont en fin de compte très simples à utiliser dans n’importe quel cas particulier. Oui, ils ont beaucoup de profondeur qui leur permet de faire un très large éventail de choses. Et ils ne sont fondamentalement possibles qu’en raison de la structure symbolique du langage Wolfram et du fait que les carnets Wolfram sont finalement représentés sous forme d’expressions symboliques. Mais lorsqu’il s’agit de les utiliser dans un but particulier, ils sont très simples et directs, et il est tout à fait réaliste de créer un carnet de forme utile en quelques minutes.
Encore plus d’informations sur les ordinateurs portables
Nous avons inventé les ordinateurs portables, avec toutes leurs caractéristiques de base (cellules hiérarchiques, etc.), en 1987. Mais depuis un tiers de siècle, nous n’avons cessé de perfectionner et de rationaliser leur fonctionnement. La version 12.2 comporte toutes sortes de nouvelles fonctionnalités utiles et pratiques pour les blocs-notes.
ClickToCopy
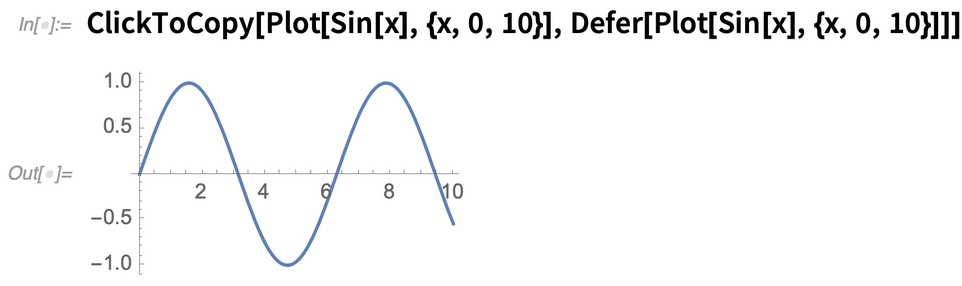
Il s’agit d’une fonctionnalité très simple, mais très utile. Vous voyez quelque chose dans un carnet de notes, et tout ce que vous voulez vraiment faire avec, c’est le copier (ou peut-être copier quelque chose qui y est lié). Dans ce cas, utilisez simplement

Si vous voulez cliquer pour copier quelque chose de non évalué, utilisez Defer :
Hyperliens simplifiés (et modification des hyperliens)
++h permet d’insérer un lien hypertexte dans un Wolfram Notebook depuis 1996. Mais dans la version 12.2, les hyperliens présentent deux nouveautés importantes. Tout d’abord, l’établissement automatique d’hyperliens qui gère un large éventail de situations différentes. Ensuite, un mécanisme modernisé et simplifié pour la création et l’édition des hyperliens.

Cellules attachées
Dans la version 12.2, nous exposons quelque chose que nous avions en interne depuis un certain temps : la possibilité d’attacher une cellule flottante entièrement fonctionnelle à n’importe quelle cellule donnée (ou boîte, ou cahier entier). L’accès à cette fonctionnalité nécessite une programmation symbolique du notebook, mais elle vous permet de faire des choses très puissantes, notamment en introduisant des interfaces contextuelles et « juste à temps ». Voici un exemple qui place un compteur dynamique qui compte les nombres premiers dans la partie inférieure droite du crochet de la cellule :

Infrastructure de la boîte à modèle
Il est parfois utile que ce que vous voyez ne soit pas ce que vous avez. Par exemple, vous pouvez vouloir afficher dans un carnet de notes J0(x) alors qu’il s’agit en réalité de BesselJ[0, x]. Depuis de nombreuses années, nous disposons de l’Interpretation comme moyen de configurer cela pour des expressions spécifiques. Mais nous disposons également d’un mécanisme plus général, TemplateBox, qui vous permet de prendre des expressions et de spécifier séparément comment elles doivent être affichées et interprétées.
Dans la version 12.2, nous avons encore généralisé et simplifié TemplateBox, en lui permettant d’incorporer des éléments d’interface utilisateur arbitraires, ainsi que de spécifier des choses comme le comportement de copie. Notre nouveau mécanisme de saisie TEX, par exemple, n’est en fait qu’une application du nouveau TemplateBox.
Dans ce cas, "TeXAssistantTemplate" fait référence à un élément de fonctionnalité défini dans la feuille de style du bloc-notes – dont les paramètres sont spécifiés par l’association donnée dans la TemplateBox :

L’interface bureautique du cloud
Une caractéristique importante des carnets de notes Wolfram est qu’ils sont conçus pour fonctionner à la fois sur le bureau et dans le nuage. Et même entre les versions de Wolfram Language, il y a beaucoup d’améliorations continues dans la façon dont les notebooks fonctionnent dans le nuage. Mais dans la version 12.2, il y a eu une rationalisation particulière de l’interface des notebooks entre le bureau et le cloud.
Un mécanisme particulièrement agréable, déjà disponible depuis quelques années dans n’importe quel bloc-notes de bureau, est l’élément de menu File > Publish to Cloud…, qui vous permet de prendre le bloc-notes et de le rendre immédiatement disponible en tant que bloc-notes publié dans le nuage, accessible à toute personne disposant d’un navigateur Web. Dans la version 12.2, nous avons simplifié le processus de publication des blocs-notes.
Lorsque je fais une présentation, je crée généralement un bloc-notes au fur et à mesure (ou j’en utilise un qui existe déjà). Et à la fin de la présentation, j’ai pris l’habitude de le publier sur le cloud, afin que tous les membres de l’auditoire puissent interagir avec lui. Mais comment puis-je donner à tout le monde l’URL du bloc-notes ? Dans un cadre virtuel, vous pouvez simplement utiliser le chat. Mais dans une présentation physique réelle, ce n’est pas une option. Dans la version 12.2, nous avons fourni une alternative pratique : le résultat de Publish to Cloud comprend un code QR que les gens peuvent capturer avec leur téléphone, puis se rendre immédiatement à l’URL et interagir avec le bloc-notes sur leur téléphone.
Il y a un autre nouvel élément notable visible dans le résultat de Publish to Cloud : « Direct JavaScript Embedding ». Il s’agit d’un lien vers le Wolfram Notebook Embedder, qui permet d’intégrer directement les carnets de notes du nuage dans des pages Web via JavaScript..
l est toujours facile d’utiliser une iframe pour intégrer une page Web sur une autre. Mais les iframes présentent de nombreuses limites, notamment le fait que leur taille doit être définie à l’avance. Wolfram Notebook Embedder permet l’intégration fluide de carnets de notes en nuage, ainsi que le contrôle par script des carnets de notes à partir d’autres éléments d’une page Web. Et comme Wolfram Notebook Embedder est configuré pour utiliser la norme d’intégration oEmbed, il peut être utilisé immédiatement dans pratiquement tous les systèmes de gestion de contenu Web standard.
Nous avons déjà parlé de l’envoi de blocs-notes du bureau vers le cloud. Mais une autre nouveauté de la version 12.2 est la navigation plus rapide et plus facile de votre système de fichiers dans le nuage à partir du bureau – comme on y accède par File > Open from Cloud… et File > Save to Cloud…
Cryptographie et sécurité
L’une des choses que nous voulons faire avec Wolfram Language est de rendre aussi facile que possible la connexion avec pratiquement n’importe quel système externe. Et à l’heure actuelle, une partie importante de ce processus consiste à pouvoir gérer de manière pratique les protocoles cryptographiques. Depuis que nous avons commencé à introduire la cryptographie directement dans le langage Wolfram il y a cinq ans, j’ai été surpris de voir à quel point le caractère symbolique du langage Wolfram nous a permis de clarifier et de simplifier les choses en matière de cryptographie.
La façon dont nous avons pu intégrer les blockchains dans le langage Wolfram en est un exemple particulièrement spectaculaire (la version 12.2 ajoute bloxberg et plusieurs autres sont en préparation). Et dans les versions successives, nous traitons différentes applications de la cryptographie. Dans la version 12.2, l’accent est mis sur les capacités symboliques de gestion des clés. La version 12.1 a déjà introduit SystemCredential pour la gestion des clés locales « keychain » (supportant, par exemple, « remember me » dans les dialogues d’authentification). Dans la version 12.2, nous traitons également les fichiers PEM.
Si nous importons un fichier PEM contenant une clé privée, nous obtenons une belle représentation symbolique de la clé privée:
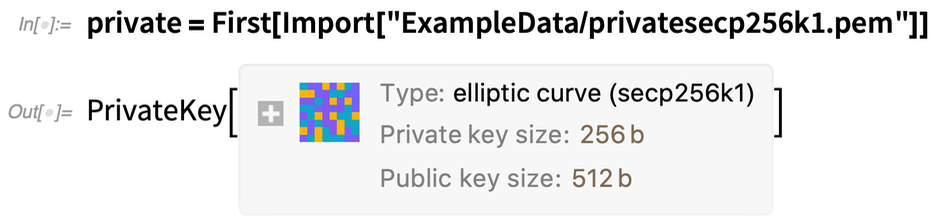
Maintenant nous pouvons dériver une clé publique:

Si nous générons une signature numérique pour un message en utilisant la clé privée

puis cela vérifie la signature en utilisant la clé publique que nous avons obtenue :

Une partie importante de l’infrastructure de sécurité moderne est le concept de certificat de sécurité – une construction numérique qui permet à une tierce partie d’attester de l’authenticité d’une clé publique particulière. Dans la version 12.2, nous disposons désormais d’une représentation symbolique des certificats de sécurité, qui fournit les éléments nécessaires aux programmes pour établir des canaux de communication sécurisés avec des entités extérieures, de la même manière que https :
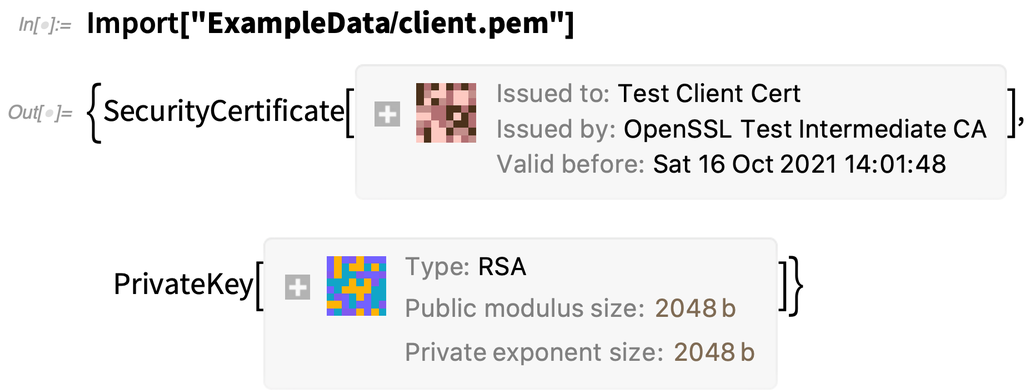
Il suffit de taper SQL
Dans la version 12.0, nous avons introduit une fonctionnalité puissante pour interroger les bases de données relationnelles de manière symbolique dans le langage Wolfram. Voici comment nous nous connectons à une base de données : :

Voici comment connecter la base de données afin que ses tables puissent être traitées comme des types d’entités de la base de connaissances Wolfram intégrée :

Maintenant, nous pouvons par exemple demander une liste d’entités d’un type donné :

La nouveauté de la version 12.2 est que nous pouvons facilement passer « sous » cette couche, pour exécuter directement des requêtes SQL contre la base de données sous-jacente, en obtenant la table de base de données complète sous forme d’expression Dataset :
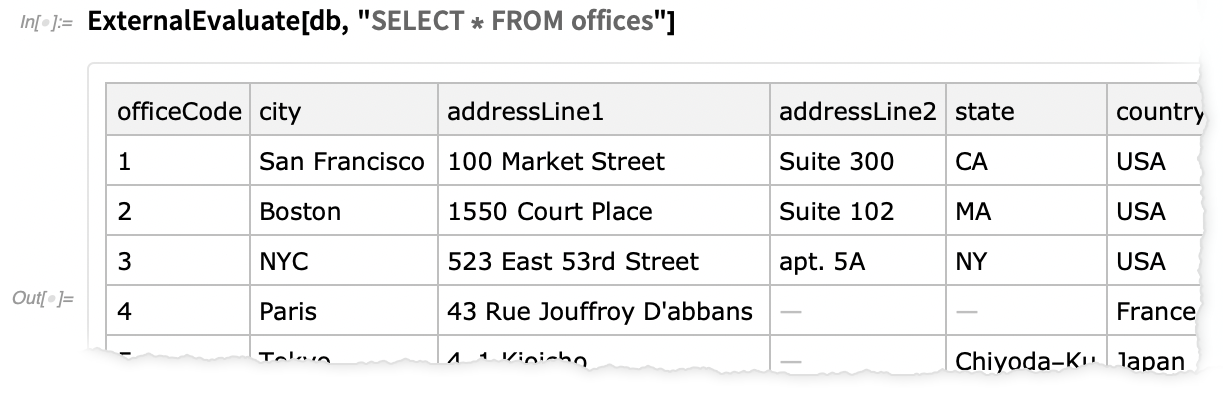
Ces requêtes peuvent non seulement lire la base de données, mais aussi y écrire. Et pour rendre les choses encore plus pratiques, nous pouvons effectivement traiter SQL comme n’importe quel autre « langage externe » dans un ordinateur portable.
Tout d’abord, nous devons enregistrer notre base de données, pour dire ce que nous voulons que notre SQL soit exécuté :

Et maintenant, nous pouvons simplement taper SQL en entrée – et obtenir la sortie en langage Wolfram, directement dans le carnet de notes :

Le support des microcontrôleurs passe à 32 bits
Vous avez développé un système de contrôle ou de traitement du signal dans le langage Wolfram. Maintenant, comment le déployer sur une pièce d’électronique autonome ? Dans la version 12.0, nous avons introduit le kit microcontrôleur pour compiler des structures symboliques en Wolfram Language directement en code microcontrôleur.
Nous avons reçu de nombreux commentaires à ce sujet, nous demandant d’étendre la gamme de microcontrôleurs que nous prenons en charge. Ainsi, dans la version 12.2, je suis heureux de vous annoncer que nous ajoutons la prise en charge de 36 nouveaux microcontrôleurs, en particulier ceux à 32 bits :

Voici un exemple dans lequel nous déployons un filtre numérique défini symboliquement sur un type particulier de microcontrôleur, montrant le code source C simplifié généré pour ce microcontrôleur particulier :
![]()


WSTPServer : Un nouveau déploiement de Wolfram Engine
Notre objectif à long terme est de rendre le langage Wolfram et l’intelligence informatique qu’il fournit aussi omniprésents que possible. Pour ce faire, nous devons notamment mettre en place le Wolfram Engine qui implémente le langage afin qu’il puisse être déployé dans un éventail aussi large que possible d’infrastructures informatiques.
Wolfram Desktop – ainsi que Mathematica classique – fournit principalement une interface de notebook au Wolfram Engine, qui s’exécute sur un système de bureau local. Il est également possible d’exécuter le Wolfram Engine directement – en tant que programme en ligne de commande (par exemple, via WolframScript) – sur un système informatique local. Et, bien sûr, il est possible d’exécuter le Wolfram Engine dans le nuage, soit par le biais du Wolfram Cloud complet (public ou privé), soit par le biais d’offres de nuages et de serveurs plus légers (existants et à venir).
Mais avec la version 12.2, il y a un nouveau déploiement du Wolfram Engine : WSTPServer. Si vous utilisez Wolfram Engine dans le nuage, vous communiquez généralement avec lui par le biais de http ou de protocoles connexes. Mais depuis plus de trente ans, le langage Wolfram dispose de son propre protocole dédié au transfert des expressions symboliques et de tout ce qui les entoure. À l’origine, nous l’avons appelé MathLink, mais ces dernières années, au fur et à mesure qu’il a été étendu, nous l’avons appelé WSTP : le Wolfram Symbolic Transfer Protocol. Comme son nom l’indique, le WSTPServer est un serveur léger qui fournit les moteurs Wolfram et vous permet de communiquer avec eux directement en WSTP natif.
Pourquoi est-ce important ? Essentiellement parce que cela vous permet de gérer des pools de sessions Wolfram Language persistantes qui peuvent fonctionner comme des services pour d’autres applications. Par exemple, normalement, chaque fois que vous appelez WolframScript, vous obtenez un nouveau moteur Wolfram. Mais en utilisant wolframscript -wstpserver avec un « nom de profil WSTP » particulier, vous pouvez continuer à obtenir le même moteur Wolfram à chaque fois que vous appelez WolframScript. Vous pouvez faire cela directement sur votre machine locale – ou sur des machines distantes.
Une utilisation importante de WSTPServer est d’exposer des pools de moteurs Wolfram auxquels on peut accéder par la nouvelle fonction RemoteEvaluate de la version 12.2. Il est également possible d’utiliser WSTPServer pour exposer des moteurs Wolfram qui seront utilisés parParallelMap, etc. Et enfin, puisque WSTP a été (pendant près de 30 ans !) la façon dont le front-end du notebook communique avec le noyau du Wolfram Engine, il est maintenant possible d’utiliser WSTPServer pour mettre en place un pool de noyau centralisé auquel vous pouvez connecter le front-end du notebook, vous permettant, par exemple, de continuer à exécuter une session particulière (ou même un calcul particulier) dans le noyau même si vous passez à un front-end différent du notebook, sur un ordinateur différent.
RemoteEvaluate : Calculer ailleurs…
Dans la lignée de « utiliser le Wolfram Language partout », une autre nouvelle fonction de la version 12.2 est RemoteEvaluate. Nous avons CloudEvaluate qui effectue un calcul dans le Wolfram Cloud, ou un Enterprise Private Cloud. Nous avons ParallelEvaluate qui effectue des calculs sur une collection prédéfinie de sous-noyaux parallèles. Et dans la version 12.2, nous avons RemoteBatchSubmit qui soumet des calculs par lots aux fournisseurs de calculs en nuage.
RemoteEvaluate est une fonction générale et légère « évaluer maintenant » qui vous permet d’effectuer un calcul sur n’importe quelle machine distante spécifiée qui possède un moteur Wolfram accessible. Vous pouvez vous connecter à la machine distante en utilisant ssh ou wstp (ou http avec un point de terminaison Wolfram Cloud).

Parfois, vous voudrez utiliser RemoteEvaluate pour faire des choses comme l’administration du système sur une série de machines. Parfois, vous voudrez collecter ou envoyer des données à des appareils distants. Par exemple, vous pouvez disposer d’un réseau d’ordinateurs Raspberry Pi qui sont tous équipés de Wolfram Engine et utiliser RemoteEvaluate pour récupérer des données sur ces machines. Au fait, vous pouvez également utiliser ParallelEvaluate à partir de RemoteEvaluate, afin qu’une machine distante soit le maître d’un ensemble de sous-noyaux parallèles.
Parfois, vous souhaiterez que RemoteEvaluate démarre une nouvelle instance de Wolfram Engine à chaque fois que vous effectuez une évaluation. Mais avec WSTPServer, vous pouvez également lui faire utiliser une session persistante de Wolfram Language. RemoteEvaluate et WSTPServer sont le début d’un cadre symbolique général pour représenter les processus de Wolfram Engine en cours d’exécution. La version 12.2 possède déjà RemoteKernelObject et $DefaultRemoteKernel qui fournissent des moyens symboliques de représenter des instances Wolfram Language distantes.
Et encore plus (alias « Aucun des éléments ci-dessus »)
J’ai au moins abordé la plupart des grandes nouveautés de la version 12.2. Mais il y en a beaucoup plus. Des fonctions supplémentaires, des améliorations, des corrections et des améliorations générales.
Comme en géométrie computationnelle, ConvexHullRegion traite désormais des régions, et non plus seulement des points. Et il y a des fonctions comme CollinearPoints et CoplanarPoints qui testent la colinéarité et la coplanarité, ou donnent des conditions pour les obtenir.
Les formats d’importation et d’exportation sont plus nombreux. Par exemple, les formats d’archives sont désormais pris en charge : « 7z« , « ISO« , « RAR« , « ZSTD« . Il y a aussi FileFormatQ et ByteArrayFormatQ pour tester si les choses correspondent à des formats particuliers.
En termes de langage de base, il y a des choses comme des mises à jour de ValueQ, un langage compliqué à définir. Il y a aussi RandomGeneratorState qui donne une représentation symbolique des états des générateurs aléatoires.
Dans l’éditeur du paquet de bureau (c’est-à-dire le fichier .wl), il y a un nouveau bouton (quelque peu expérimental) Format Cell, qui reformate le code – avec un contrôle sur la façon dont il doit être « aéré » (c’est-à-dire la densité des nouvelles lignes).
Dans les notebooks en mode Wolfram|Alpha (tel qu’utilisé par défaut dans Wolfram|Alpha Notebook Edition), il y a d’autres nouvelles fonctionnalités, comme la documentation des fonctions ciblée sur l’utilisation d’une fonction particulière.
Il y a aussi plus dans TableView, ainsi qu’une grande suite de nouveaux outils de création de paclets qui sont inclus sur une base expérimentale.
Pour moi, il est assez étonnant de voir tout ce que nous avons pu rassembler dans la version 12.2 et, comme toujours, je suis heureux qu’elle soit maintenant disponible et que tout le monde puisse l’utiliser.