Start der Version 12.3 von Wolfram Language & Mathematica
Schau, was wir in fünf Monaten geschaffen haben!

Wir haben Version 12.2 am 16. Dezember 2020 veröffentlicht. Und heute, nur fünf Monate später, bringen wir Version 12.3 heraus. There are some breakthroughs and major new directions in 12.3. Aber ein Großteil der Version 12.3 besteht darin, die Wolfram Language und Mathematica besser, reibungsloser und bequemer zu machen. Things are faster. Mehr „Aber was ist mit ___?“-Fälle werden behandelt. Große Frameworks sind vollständiger ausgefüllt. Und es gibt eine Menge neuer Annehmlichkeiten.
Es gibt auch die ersten Teile dessen, was in Zukunft zu großen Strukturen werden wird. Frühe Funktionen – die bereits für sich genommen sehr nützlich sind – werden in zukünftigen Versionen Teile von großen systemweiten Frameworks sein.
Eine Möglichkeit, eine neue Version zu beurteilen, ist die Anzahl der neuen Funktionen, die sie enthält. Für Version 12.3 beträgt diese Zahl 111 (oder etwa 5 neue Funktionen pro Entwicklungswoche). Das ist ein sehr beeindruckendes Niveau der F&E-Produktivität. Aber speziell für 12.3 ist das nur ein Teil der Geschichte; es gibt auch 1190 Fehlerkorrekturen (etwa ein Viertel für extern gemeldete Fehler) und 105 wesentlich aktualisierte und verbesserte Funktionen.
Inkrementelle Veröffentlichungen sind Teil unseres Engagements für eine offene Entwicklung. Wir haben auch mehr Funktionen in Open-Source-Form zur Verfügung gestellt (darunter mehr als 300 neue Funktionen im Wolfram Function Repository). Und wir haben unsere internen Entwicklungsprozesse per Livestreaming übertragen. Bei Version 12.3 ist es wieder möglich, zu sehen, wo und wie Designentscheidungen getroffen wurden und wie sie begründet wurden. Und wir haben auch großartige Beiträge aus unserer Community erhalten (oft in Echtzeit während der Livestreams), die die Version 12.3, die wir heute ausliefern, erheblich verbessert haben.
Übrigens, wenn wir von „Version 12.3“ von Wolfram Language und Mathematica sprechen, meinen wir Desktop, Cloud und Engine: alle drei Versionen werden heute veröffentlicht.
Viele kleine neue Annehmlichkeiten
Version 12.3 enthält unsere neueste Reihe von Erleichterungen, die über viele Teile der Sprache verstreut sind. Eine neue Dynamik, die in dieser Version aufgetaucht ist, sind Funktionen, die im Wesentlichen im Wolfram Function Repository„prototypisiert“ und dann „aufgerüstet“ wurden, um in das System eingebaut zu werden.
Hier ist ein erstes Beispiel für eine neue Komfortfunktion: SolveValues. Die Funktion Solve—ursprünglich in Version 1.0 eingeführt – hat eine sehr flexible Art, ihre Ergebnisse darzustellen, die eine unterschiedliche Anzahl von Variablen, eine unterschiedliche Anzahl von Lösungen usw. zulässt.
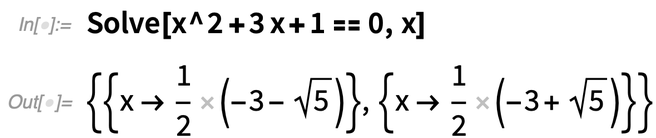
|

|
Übrigens gibt es auch ein NSolveValues, das ungefähre numerische Werte liefert:
 |
Ein weiteres Beispiel für eine neue Komfortfunktion ist NumberDigit. Angenommen, Sie wollen die 10. Stelle von π. Sie können immer RealDigits verwenden und dann die gewünschte Stelle auswählen:
 |
Aber jetzt können Sie auch einfach NumberDigit verwenden (wobei wir jetzt davon ausgehen, dass Sie mit „10. Stelle“ den Koeffizienten von 10-10 meinen):
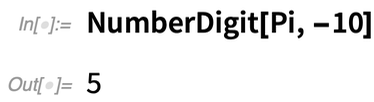 |
In Version 1.0 hatten wir nur Sort. In Version 10.3 (2015) fügten wir AlphabeticSort hinzu, und in Version 11.1 (2017) dann NumericalSort. Jetzt, in Version 12.3, fügen wir LexicographicSort hinzu, um die Familie der Standard-Sortierarten zu vervollständigen. Die Standardsortierung (wie sie von Sort erzeugt wird) ist:

|
Aber hier ist eine echte lexikografische Ordnung, wie man sie in einem Wörterbuch finden würde:

Eine weitere kleine neue Funktion in Version 12.3 ist StringTakeDrop:

|
Da es sich hierbei um eine einzige Funktion handelt, ist es einfacher, sie in funktionalen Programmierkonstrukten wie diesem zu verwenden:
 |
Es ist immer ein wichtiges Ziel, „Standard-Workflows“ so einfach wie möglich zu gestalten. Für den Umgang mit Graphen gibt es zum Beispiel seit Version 8.0 (2010) die Komponente VertexOutComponent. Sie gibt eine Liste der Punkte aus, die von einem bestimmten Punkt aus erreicht werden können. Und für manche Dinge ist das genau das, was man will. Aber manchmal ist es viel bequemer, den Untergraphen zu erhalten (und in der Tat ist dieser Untergraphen – den wir als „geodätische Kugel“ betrachten – im Formalismus unseres Physikprojekts ein ziemlich zentrales Konstrukt). Daher haben wir in Version 12.3 VertexOutComponentGraph hinzugefügt:
 |
Ein weiteres Beispiel für eine kleine „Workflow-Verbesserung“ ist HighlightImage. HighlightImage nimmt in der Regel eine Liste von Regionen, die im Bild hervorgehoben werden sollen. Aber Funktionen wie MorphologicalComponents erstellen nicht einfach nur Listen von Regionen in einem Bild; stattdessen erzeugen sie eine „Beschriftungsmatrix“, die verschiedene Regionen in einem Bild mit Zahlen beschriftet. Um den HighlightImage-Arbeitsablauf reibungsloser zu gestalten, lassen wir ihn in Version 12.3 direkt eine Beschriftungsmatrix verwenden und weisen den unterschiedlich beschrifteten Regionen unterschiedliche Farben zu:
 |
Eine Sache, an der wir in der Wolfram Language hart arbeiten, ist Kohärenz und Interoperabilität. (Tatsächlich haben wir eine ganze Initiative zu diesem Thema, die wir „Language Completeness & Consistency“ nennen und deren wöchentliche Treffen wir regelmäßig live übertragen.) Eine der verschiedenen Facetten der Interoperabilität besteht darin, dass wir wollen, dass Funktionen in der Lage sind, jede vernünftige Eingabe zu „fressen“ und sie in etwas zu verwandeln, das sie „natürlich“ verarbeiten können.
Ein kleines Beispiel dafür ist die automatische Konvertierung zwischen Farbräumen, die wir in Version 12.3 hinzugefügt haben. Rot bedeutet standardmäßig die RGB-Farbe Rot (RGBColor[1,0,0]). Aber jetzt
 |
bedeutet, dass das Rot im Farbtonraum zu Rot wird:

|
Angenommen, Sie führen eine lange Berechnung durch. Oft möchten Sie einen Hinweis auf den Fortschritt der Berechnung erhalten. In Version 6.0 (2007) haben wir Monitor hinzugefügt, und in späteren Versionen haben wir für einige Funktionen, z. B. NetTrain, automatische Fortschrittsberichte eingebaut. Aber jetzt haben wir eine Initiative gestartet, um systematisch Fortschrittsberichte für alle möglichen Funktionen hinzuzufügen, die lange Berechnungen durchführen können. ($ProgressReporting = False schaltet dies global ab.)
 |
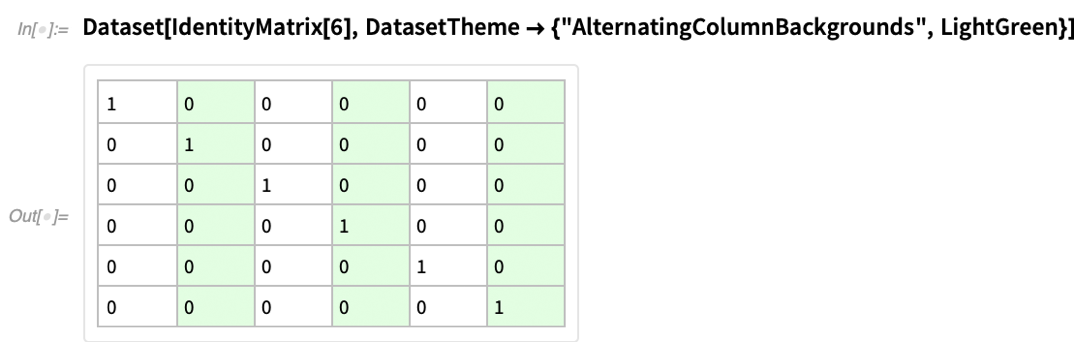
Wir arbeiten in der Wolfram Language hart daran, gute Standardeinstellungen zu wählen, zum Beispiel für die Darstellung von Dingen. Aber manchmal muss man dem System sagen, welche Art von „Look“ man haben möchte. Und in Version 12.3 haben wir die Option DatasetTheme hinzugefügt, mit der man „Themen“ für die Darstellung von Dataset-Objekten festlegen kann.
Im Grunde genommen stellt jedes Thema nur bestimmte Optionen ein, die Sie selbst festlegen können. Aber das Thema ist ein „Bankschalter“, der die Optionen auf bequeme Weise umschaltet. Here’s a basic dataset with default formatting:
 |
Hier sieht es für das Web „lebendiger“ aus:
 |
Sie können auch verschiedene „Themenrichtlinien“ angeben:
 |
Sowie zusätzliche Hinweise:
 |
Ich bin mir nicht sicher, warum wir nicht schon früher daran gedacht haben, aber in Version 11.3 (2018) haben wir eine sehr schöne „Neuerung der Benutzeroberfläche“ eingeführt: Iconize. Und in Version 12.3 haben wir der Ikonisierung einen weiteren Feinschliff verpasst. Wenn Sie einen Teil eines Ausdrucks auswählen und dann im Kontextmenü („Rechtsklick“) die Funktion „Ikonisieren“ verwenden, wird ein geeigneter Teil des Ausdrucks ikonisiert, auch wenn die Auswahl, die Sie getroffen haben, ein zusätzliches Komma enthalten hat oder etwas war, das kein strenger Teil des Ausdrucks sein kann:
 |
Nehmen wir an, Sie erzeugen ein Objekt, dessen Speicherung viel Speicherplatz benötigt:
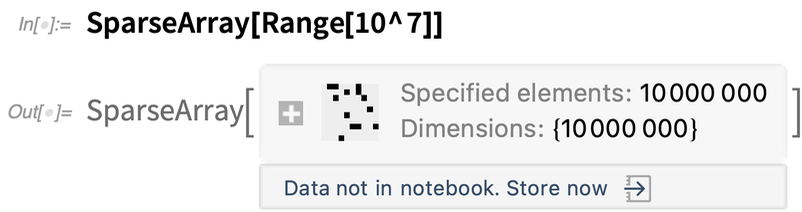 |
Standardmäßig wird das Objekt in Ihrer Kernel-Sitzung aufbewahrt, aber es wird nicht direkt in Ihrem Notebook gespeichert – es bleibt also nicht bestehen, nachdem Sie Ihre aktuelle Kernel-Sitzung beendet haben. In Version 12.3 haben wir einige Optionen hinzugefügt, wo Sie die Daten speichern können:
 |
Ein wichtiger Bereich, in dem wir uns sehr darum bemühen, dass die Dinge „einfach funktionieren“, ist der Import und Export von Daten. Die Wolfram Language unterstützt jetzt etwa 250 externe Datenformate, wobei in Version 12.3 zum Beispiel neue statistische Datenformate wie SAS7BDAT, DTA, POR und SAV hinzugekommen sind.
Viele Dinge wurden schneller
Hier ist eine Berechnung mit Around:
 |
In Version 12.2 dauert es auf meinem Computer etwa 1,3 Sekunden, dies 10.000 Mal zu tun:
 |
In Version 12.3 ist sie etwa 100 Mal schneller:
 |
Es gibt viele verschiedene Gründe, warum die Dinge in Version 12.3 schneller geworden sind. Im Fall von Permanent zum Beispiel konnten wir einen neuen und viel besseren Algorithmus verwenden. Hier ist er in Version 12.2:
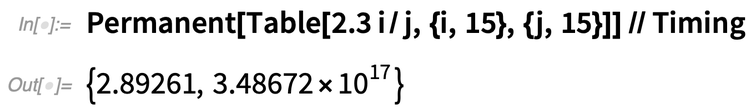 |
Und jetzt in der 12.3:
 |
Ein weiteres Beispiel ist Rasterize, das in Version 12.3 in der Regel 2 bis 4 Mal schneller ist als in Version 12.2. Der Grund für diese Beschleunigung ist etwas subtiler. Als Rasterize zum ersten Mal in Version 6.0 (2007) eingeführt wurde, waren die Datenübertragungsgeschwindigkeiten zwischen den Prozessen ein Problem, und daher war es eine gute Optimierung, alle übertragenen Daten zu komprimieren. Aber heute sind die Übertragungsgeschwindigkeiten viel höher, und wir haben besser optimierte Array-Datenstrukturen – daher macht die Komprimierung keinen Sinn mehr, und das Entfernen der Komprimierung (zusammen mit anderen Codepfad-Optimierungen) ermöglicht es Rasterize, deutlich schneller zu sein.
Ein wichtiger Fortschritt in Version 12.1 war die Einführung von DataStructure, die die direkte Verwendung von Optimierungsdatenstrukturen ermöglicht (implementiert durch unsere neue Compiler-Technologie). Version 12.3 führt mehrere neue Datenstrukturen ein. Es gibt „ByteTrie“ für schnelle präfixbasierte Suchvorgänge (z.B. Autocomplete und GenomeLookup), und es gibt „KDTree“ für schnelle geometrische Suchvorgänge (z.B. Nearest). Außerdem gibt es jetzt den „ImmutableVector„, der im Grunde wie eine gewöhnliche Wolfram Language-Liste ist, nur dass er für schnelles Anhängen optimiert ist.
Zusätzlich zu den Geschwindigkeitsverbesserungen im Rechenkern bietet Version 12.3 auch Geschwindigkeitsverbesserungen in der Benutzeroberfläche. Besonders bemerkenswert ist das deutlich schnellere Rendering auf Windows-Plattformen, das durch die Verwendung von DirectWrite und die Nutzung der GPU-Fähigkeiten erreicht wird.
Die Grenzen der Mathematik verschieben
Für Version 12.3 wollen wir zunächst über das Lösen von symbolischen Gleichungen sprechen. Bereits in Version 3 (1996) führten wir die Idee impliziter „Root-Objekt“-Darstellungen für Wurzeln von Polynomen ein, die es uns ermöglichten, exakte, symbolische Berechnungen auch ohne „explizite Formeln“ in Form von Radikalen durchzuführen. In Version 7 (2008) wurde Root dann so verallgemeinert, dass es auch für transzendente Gleichungen funktioniert.
Was ist mit Gleichungssystemen? Für Polynome bedeutet die Eliminierungstheorie, dass sich Systeme nicht wirklich von einzelnen Gleichungen unterscheiden; es können die gleichen Root-Objekte verwendet werden. Aber für transzendente Gleichungen gilt das nicht mehr. Für die Version 12.3 haben wir nun herausgefunden, wie man Root-Objekte verallgemeinern kann, so dass sie mit multivariaten transzendentalen Wurzeln arbeiten können:
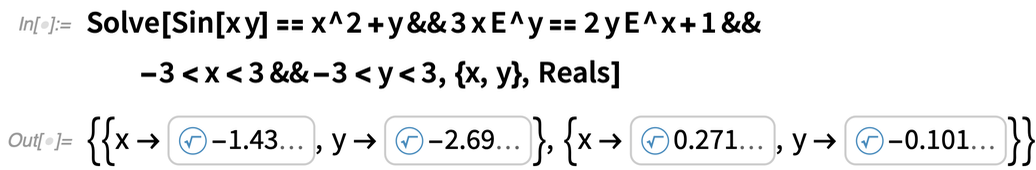 |
Und weil diese Root-Objekte exakt sind, können sie zum Beispiel mit beliebiger Genauigkeit ausgewertet werden:
 |
In Version 12.3 gibt es auch einige neue Gleichungen mit elliptischen Funktionen, bei denen exakte symbolische Ergebnisse auch ohne Root-Objekte gegeben werden können:
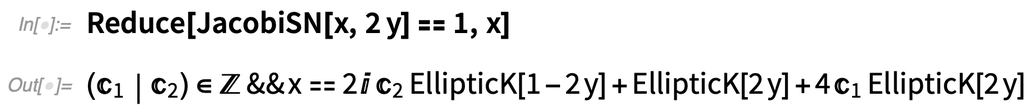 |
Ein großer Fortschritt in Version 12.3 ist die Möglichkeit, jedes lineare System von ODEs (gewöhnlichen Differentialgleichungen) mit rationalen Funktionskoeffizienten symbolisch zu lösen.
Manchmal beinhaltet das Ergebnis explizite mathematische Funktionen:
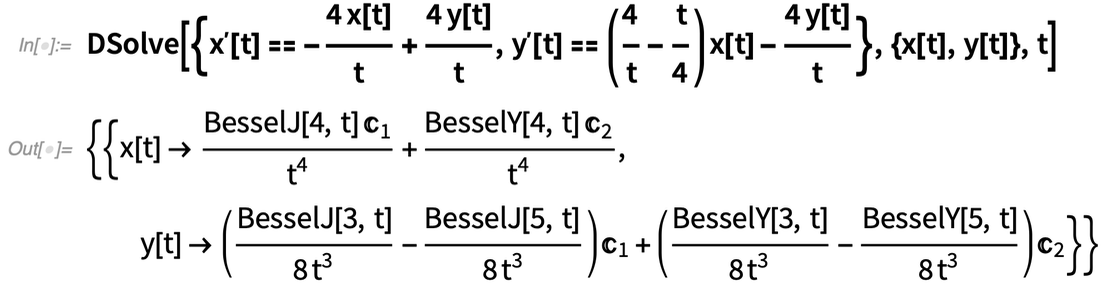 |
Manchmal sind in den Ergebnissen Integrale oder Differentialwurzeln enthalten:
 |
Ein weiterer Fortschritt in Version 12.3 ist die vollständige Abdeckung von linearen ODEs mit q-rationalen Funktionskoeffizienten, bei denen die Variablen explizit oder implizit in den Exponenten erscheinen können. Die Ergebnisse sind exakt, obwohl sie typischerweise Differentialwurzeln beinhalten:
 |
Was ist mit PDEs? In Version 12.2 haben wir ein neues Framework für die Modellierung mit numerischen PDEs eingeführt. Und jetzt haben wir in Version 12.3 eine ganze 105-seitige Monographie über symbolische Lösungen von PDEs erstellt:

|
|
Jetzt kann sie exakt und auch symbolisch gelöst werden:
 |
Zusätzlich zu den linearen PDEs werden in Version 12.3 auch spezielle Lösungen für nichtlineare PDEs behandelt. Hier ist eine (mit 4 Variablen), die die Jacobi-Methode verwendet:
 |
Etwas, das in 12.3 hinzugefügt wurde und sowohl PDEs unterstützt als auch neue Funktionen für die Signalverarbeitung bietet, ist die bilaterale Laplace-Transformation (d. h. die Integration von -∞ nach +∞, wie eine Fourier-Transformation):
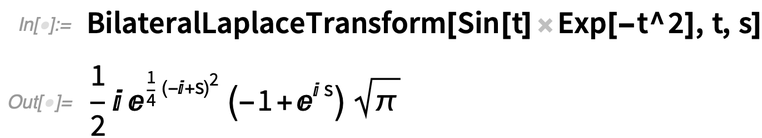 |
Bereits in Version 3 (1996) haben wir die MeijerG-Funktion eingeführt, die den Bereich der definiten Integrale, die wir in symbolischer Form darstellen können, drastisch erweitert hat. MeijerG ist durch ein Mellin-Barnes-Integral in der komplexen Ebene definiert. Es handelt sich um eine kleine Änderung des Integranden, aber es hat 25 Jahre gedauert, die notwendige Mathematik und die Algorithmen zu entschlüsseln, um uns jetzt in die Version 12.3 FoxH zu bringen.
FoxHst eine sehr allgemeine Funktion, die alle hypergeometric pFq und Meijer-G-Funktionen und noch viel mehr umfasst. Und jetzt, da FoxH in unserer Sprache vorliegt, können wir damit beginnen, unsere Integrations- und anderen symbolischen Fähigkeiten zu erweitern, um sie zu nutzen.
Durchbruch bei der symbolischen Optimierung
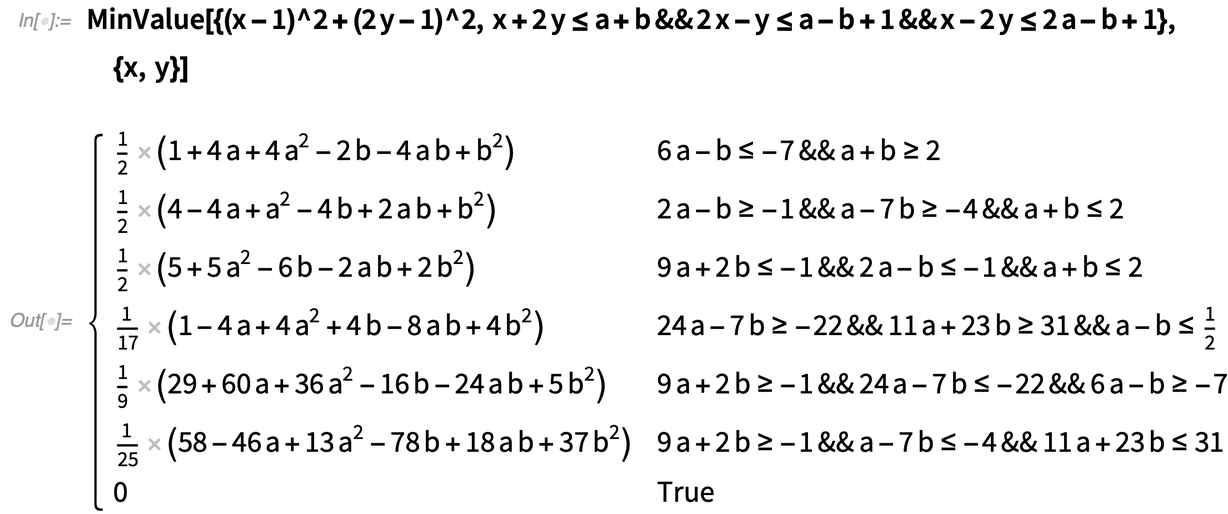 |
 |
Bei typischen konvexen Optimierungsberechnungen, die keine symbolischen Parameter beinhalten, strebt man nur ungefähre numerische Ergebnisse an, und es war nicht klar, ob es eine allgemeine Methode gibt, um exakte numerische Ergebnisse zu erhalten. Für die Version 12.3 haben wir jedoch eine gefunden, und wir sind nun in der Lage, exakte numerische Ergebnisse zu liefern, die Sie z.B. mit beliebiger Genauigkeit auswerten können.
Es handelt sich um ein geometrisches Optimierungsproblem, das nun genau mit Hilfe von transzendentalen Wurzelobjekten gelöst werden kann:
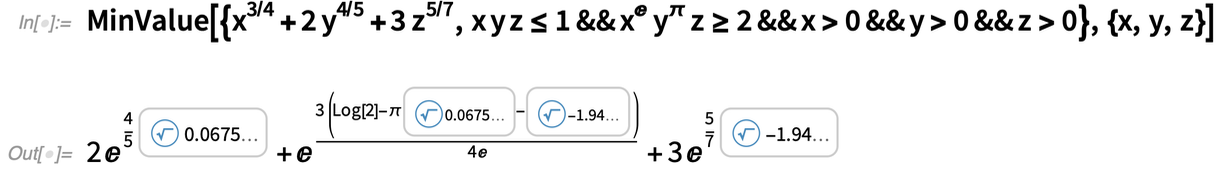 |
Mit einer solchen exakten Lösung ist es nun möglich, numerische Berechnungen mit beliebiger Genauigkeit durchzuführen:
 |
Mehr mit Diagrammen
In Version 12.3 haben wir diese Funktionalität weiter ausgebaut. Hier ist zum Beispiel eine neue 3D-Visualisierungsfunktion für Graphen:
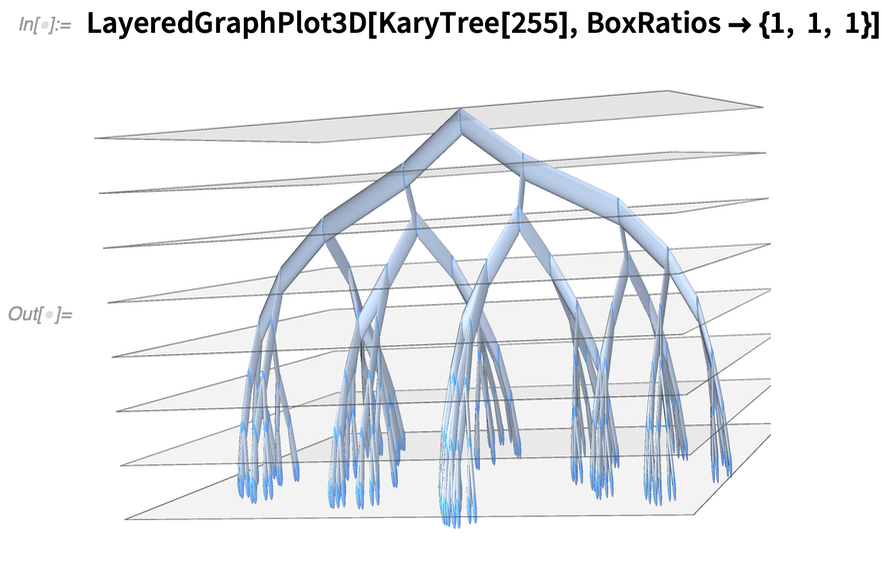 |
Und hier ist eine neue 3D-Grafikeinbettung:
 |
Seit Version 10 (2014) sind wir in der Lage, Spannbäume in Graphen zu finden. In Version 12.3 haben wir FindSpanningTree jedoch so verallgemeinert, dass es direkt mit Objekten – wie Geo-Standorten – umgehen kann, die eine Art von Koordinaten haben. Hier ist ein spannender Baum, der auf den Positionen der Hauptstädte in Europa basiert:
 |
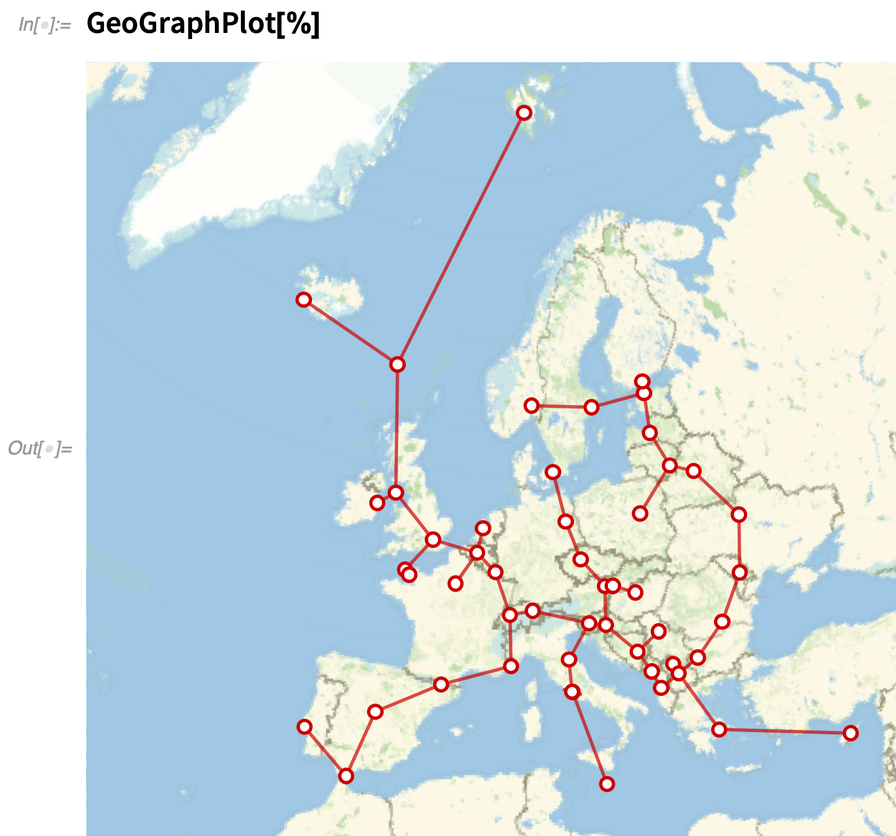 |
Übrigens gibt es in einem „Geo-Graphen“ „geo“-Möglichkeiten, die Kanten zu routen. Sie können zum Beispiel festlegen, dass sie (wenn möglich) Fahranweisungen folgen (wie von TravelDirections bereitgestellt):
 |
Euklid trifft auf Descartes und mehr
Bei drei symbolisch angegebenen Punkten kann GeometricTest die algebraische Bedingung angeben, dass sie kollinear sind:
 |
Für den besonderen Fall der Kollinearität gibt es eine spezielle Funktion zur Durchführung des Tests:
 |
GeometricTest ist jedoch viel allgemeiner und unterstützt mehr als 30 Arten von Prädikaten. Dies ist die Bedingung dafür, dass ein Polygon konvex ist:
 |
Dies ist die Voraussetzung dafür, dass ein Polygon regelmäßig ist:
 |
Und hier ist die Bedingung, dass drei Kreise sich gegenseitig tangieren (und ja, das ∃ ist ein wenig „post Descartes“):
 |
Die Version 12.3 enthält auch Verbesserungen in der Kernberechnungsgeometrie. Am bemerkenswertesten sind RegionDilation und RegionErosion, die im Wesentlichen Regionen miteinander konvolvieren. RegionDilation findet effektiv die gesamte („Minkowski-Summe“) „Vereinigungsregion“, die sich aus der Verschiebung einer Region in jeden Punkt einer anderen Region ergibt.
Warum ist dies nützlich? Hierfür gibt es viele Gründe. Ein Beispiel ist das „Piano-Mover-Problem“ (auch bekannt als das Problem der Bewegungsplanung von Robotern). Gibt es eine Möglichkeit, eine rechteckige Form (im einfachsten Fall ohne Drehung) durch ein Haus mit bestimmten Hindernissen (z. B. Wände) zu manövrieren?
Im Grunde genommen muss man die rechteckige Form nehmen und den Raum (und die Hindernisse) mit ihr „ausdehnen“:
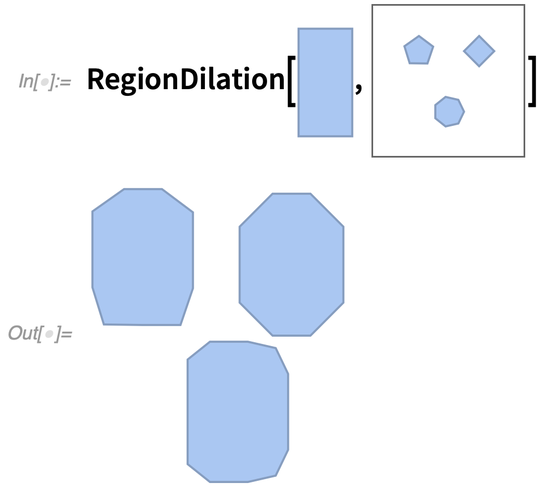 |
Wenn dann ein zusammenhängender Weg von einem Punkt zum anderen „übrig“ bleibt, kann das Klavier entlang dieses Weges bewegt werden. (Das Gleiche gilt natürlich auch für Roboter in einer Fabrik usw. usw.)
RegionDilation eignet sich auch zum „Glätten“ oder „Versetzen“ von Formen, zum Beispiel für CAD-Anwendungen:
 |
Zumindest in einfachen Fällen kann man damit „nach Descartes“ vorgehen und eindeutige Formeln erhalten:
 |
Das Ganze funktioniert übrigens in beliebig vielen Dimensionen und bietet eine nützliche Möglichkeit, alle möglichen „neuen Formen“ zu erzeugen (z. B. ist ein Zylinder die Ausdehnung einer Scheibe durch eine Linie in 3D).
Noch mehr Visualisierung
Hier ist ein 3D-Zufallsspaziergang, gerendert mit ListLinePlot3D:
 |
Wenn Sie mehrere Listen mit Daten eingeben, stellt ListLinePlot3D jede Liste einzeln dar:
 |
Wir haben das Plotten von Vektorfeldern erstmals in Version 7.0 (2008) eingeführt, mit Funktionen wie VectorPlot und StreamPlot, die in den Versionen 12.1 und 12.2 erheblich verbessert wurden. In Version 12.3 fügen wir nun StreamPlot3D (sowie ListStreamPlot3D) hinzu. Hier sehen Sie eine Darstellung von Stromlinien für ein 3D-Vektorfeld, eingefärbt nach Feldstärke:

Achsen funktionieren ein bisschen wie Pfeile: Zuerst geben Sie die „Kernstruktur“ an, dann sagen Sie, wie sie beschriftet werden soll. Hier ist eine Achse, die linear von 0 bis 100 auf einer Linie beschriftet ist:








Goldene Knoten und andere materielle Angelegenheiten



Die Modellierung von Licht, das mit Oberflächen interagiert – und das „physikalisch basierte Rendering“ – ist eine komplizierte Angelegenheit, zu der es in Version 12.3 eine ganze Monografie gibt:

Bäume!
Das grundlegende Objekt ist Tree:

Es gibt eine Vielzahl von „*Tree“-Funktionen zur Konstruktion von Bäumen und „Tree*“-Funktionen zur Umwandlung von Bäumen in andere Dinge. RulesTree z.B. konstruiert einen Baum aus einer verschachtelten Sammlung von Regeln:





Als wir Tree entwarfen, dachten wir zunächst, dass wir getrennte symbolische Darstellungen für ganze Bäume, Unterbäume und Blattknoten benötigen würden. Es stellte sich jedoch heraus, dass wir mit Tree allein ein elegantes Design erstellen konnten. Knoten in einem Baum haben typischerweise die Form Tree[payload, {child1, child2, …}], wobei die childi Teilbäume sind. Ein Knoten muss nicht unbedingt eine Nutzlast haben, in diesem Fall kann er einfach als Tree[{child1, child2, …}]angegeben werden. Ein Blattknoten ist dann Tree[expr, None] oder Tree[None].
Eine sehr schöne Eigenschaft dieses Designs ist, dass Bäume sofort aus Unterbäumen konstruiert werden können, indem man Ausdrücke verschachtelt:















Daten, Zeiten und wie schnell dreht sich die Erde?
Hier ist ein Datum mit den in Schweden verwendeten Standardkonventionen:


aIn Version 12.3 gibt es eine neue detaillierte Spezifikation dafür, wie Datumsformate aufgebaut sein sollten:


In Version 10.0 (2014) haben wir die siderische (sternbasierte) Zeit eingeführt:



Diese geben an, wie viel länger als 24 Stunden der Tag derzeit ist:


Die Spitze des maschinellen Lernens und der neuronalen Netze
Trainieren Sie einen Prädiktor zur Vorhersage der „Weinqualität“ anhand des chemischen Gehalts eines Weins:




Ein subtiles, aber wichtiges Thema beim maschinellen Lernen ist die Kalibrierung des „Vertrauens“ von Klassifikatoren. Wenn ein Klassifikator sagt, dass es sich bei bestimmten Bildern mit einer Wahrscheinlichkeit von 60 % um Katzen handelt, bedeutet dies dann, dass es sich bei 60 % der Bilder tatsächlich um Katzen handelt? Ein einfaches neuronales Netz wird dies in der Regel nicht richtig machen. Man kann sich aber annähern, indem man die Wahrscheinlichkeiten mithilfe einer Kalibrierungskurve neu kalibriert. Und in Version 12.3 unterstützen Funktionen wie Classify zusätzlich zur automatischen Rekalibrierung die neue Option RecalibrationFunction, mit der Sie angeben können, wie die Rekalibrierung erfolgen soll.
Ein wichtiger Bestandteil unseres Frameworks für maschinelles Lernen ist die umfassende symbolische Unterstützung für neuronale Netze. Wir haben weiterhin die neuesten neuronalen Netze aus der Forschungsliteratur in unser Neural Net Repository aufgenommen, so dass sie in unserem Framework mit NetModel sofort zugänglich sind.
In Version 12.3 haben wir unser Framework um einige zusätzliche Funktionen erweitert, zum Beispiel die Aktivierungsfunktionen „swish“ und „hardswish“ für ElementwiseLayer. Auch „unter der Haube“ hat sich einiges getan. Wir haben den ONNX import and export verbessert, wir haben das Software-Engineering unserer MXNet-Integration erheblich gestrafft, und wir haben fast eine native Version unseres Frameworks für Apple Silicon fertiggestellt (in 12.3.0 läuft das Framework über Rosetta).
Wir sind stets bemüht, unser Framework für maschinelles Lernen so weit wie möglich zu automatisieren. Und um dies zu erreichen, war es sehr wichtig, dass wir so viele kuratierte Netzkodierer und -dekodierer haben, die Sie sofort für verschiedene Arten von Daten verwenden können. In Version 12.3 wurde dies durch die Verwendung eines beliebigen Merkmalsextraktors Merkmalsextraktors als Netzkodierer erweitert, der als Teil des eigentlichen Trainingsprozesses trainiert werden kann. Warum ist das wichtig? Nun, es gibt Ihnen eine trainierbare Möglichkeit, beliebige Datensammlungen unterschiedlicher Art in ein neuronales Netz einzuspeisen, auch wenn es keine vordefinierte Möglichkeit gibt, zu wissen, wie die Daten in etwas wie ein Zahlenfeld umgewandelt werden können, das für die Eingabe in ein neuronales Netz geeignet ist.
Die Wolfram Language bietet nicht nur einen direkten Zugang zum maschinellen Lernen auf dem neuesten Stand der Technik, sondern verfügt auch über eine wachsende Anzahl von eingebauten Funktionen, die das maschinelle Lernen intern nutzen. Eine solche Funktion ist TextCases. Und in Version 12.3 ist TextCases deutlich stärker geworden, insbesondere bei der Unterstützung von weniger gebräuchlichen Textinhaltstypen wie „Protein“ und „BoardGame„:

Neu in Video
Eine große Gruppe neuer Funktionen in 12.3 dreht sich um die programmatische Videoerstellung. Es gibt drei grundlegende neue Funktionen: FrameListVideo, SlideShowVideo und AnimationVideo.
FrameListVideo nimmt eine Liste von Rohbildern und setzt sie zu einem Video zusammen, indem es sie als aufeinanderfolgende Rohbilder behandelt. SlideShowVideo nimmt ebenfalls eine Liste von Bildern, erstellt aber jetzt ein „Diashow-Video“, in dem jedes Bild für eine bestimmte Dauer angezeigt wird. In diesem Beispiel wird jedes Bild im Video 1 Sekunde lang angezeigt:

AnimationVideonimmt keine vorhandenen Bilder, sondern einen Ausdruck und wertet ihn dann „Manipulate-style“ für einen Bereich von Werten eines Parameters aus. (Es ist sozusagen ein Analogon zu Animate, das Videos erstellt).





Version 12.3 bietet auch einige neue Funktionen für die Videobearbeitung. Mit VideoTimeStretch können Sie die Zeit in einem Video mit einer beliebigen Funktion „verzerren“. Mit VideoInsert können Sie einen Videoclip in ein Video einfügen, und mit VideoReplace können Sie einen Teil eines Videos durch ein anderes ersetzen.
Eines der besten Dinge an Videos in der Wolfram Language ist, dass sie sofort mit allen Werkzeugen der Sprache analysiert werden können. Dazu gehört auch maschinelles Lernen, und in Version 12.3 haben wir damit begonnen, Videos für die Berechnung mit neuronalen Netzen zu kodieren. Version 12.3 enthält einen einfachen Frame-basierten Netzkodierer für Videos sowie eine Reihe integrierter Merkmalsextraktoren. Weitere werden bald folgen, einschließlich einer Vielzahl von Videoverarbeitungs- und -analyse-Netzen im Wolfram Neural Net Repository.
Mehr in Chemie
In Version 12.3 gibt es zum Beispiel neue Eigenschaften für Molecule, wie „TautomerList“ (mögliche Rekonfigurationen in Lösung):









Schließen des Regelkreises für Kontrollsysteme
Beginnen wir mit dem Importieren eines Modells, das in Wolfram System Modeler erstellt wurde. In diesem speziellen Fall handelt es sich um ein einfaches Modell für ein U-Boot:


Wie können wir also angesichts des zugrunde liegenden Systemmodells diesen Regler entwerfen? Nun, in Version 12.3 haben wir es geschafft, dies auf ein paar Funktionen zu reduzieren. Zunächst geben wir das Modell und die Parameter an, die geregelt werden sollen, und spezifizieren unser Entwurfsziel durch Angabe der gewünschten Eigenwerte:



So how did this work? Well, as is typical in this type of control systems design, we first found a linearization of the underlying model, appropriate for the domain in which we were going to be operating:







Es wird einfacher, Code in Notebooks zu tippen
Das bedeutet zum Beispiel, dass Ihr Code nicht mehr wie folgt aussieht


Aber wenn Sie mit [[ … ]] zu tun haben, können Sie nicht einfach diese Art von „lokaler Ersetzung“ vornehmen, ohne dass es zu Verwechslungen kommt, wenn einige ]] als 〛 angezeigt werden, während andere durch routinemäßige Bearbeitung in ]] zerfallen.
In Version 12.3 werden keine Ersetzungen mehr vorgenommen, sondern nur noch bestimmte Zeichenfolgen (wie ]]) auf besondere Weise dargestellt. Das Ergebnis ist, dass wir ein sehr allgemeines „ligaturähnliches“ Verhalten unterstützen können, und dass der Abstand zwischen den Zeichen immer genau umgekehrt ist als der, der eingegeben wurde.
AutoOperatorRenderings sorgt dafür, dass der von Ihnen eingegebene Code schöner aussieht und leichter zu lesen ist. Aber es gibt noch eine zweite, bedeutendere Änderung in der Art und Weise, wie Sie Code eingeben, die jetzt in Version 12.3 verfügbar ist. Sie ist noch recht experimentell und daher nicht standardmäßig aktiviert, aber Sie können sie explizit einschalten, wenn Sie wollen, indem Sie einfach

Das bedeutet also, wenn Sie Folgendes eingeben

Was passiert nun mit Ihren alten Tippgewohnheiten? Nun, Sie können sie weiterhin verwenden. Denn Sie können ] eingeben, um das schließende ] „durchzutippen“. Und das bedeutet, dass Sie genau die gleichen Zeichen tippen wie vorher. Aber der wichtige Punkt ist, dass Sie das nicht müssen. Das ] ist bereits für Sie da.
Warum ist das wichtig? Vor allem, weil Sie nicht mehr darüber nachdenken müssen, wie Sie Ihre Begrenzungszeichen anpassen. Das wird automatisch für Sie erledigt. Seit Version 3.0 (1996) haben wir eine Syntaxfärbung, die anzeigt, wenn Begrenzungszeichen nicht geschlossen wurden, und die vorschlägt, dass Sie sie schließen sollten. Aber jetzt geschieht das Schließen einfach automatisch. Das bedeutet vor allem, dass Ausdrücke, die Sie eingeben, immer „vollständig“ aussehen und nicht bei der Eingabe jedes einzelnen Zeichens alle möglichen strukturellen Änderungen vorgenommen werden.
Natürlich ist das alles viel komplizierter, als es auf den ersten Blick erscheinen mag. Nehmen wir an, Sie haben bereits einen komplizierten Ausdruck eingegeben und fügen nun ein öffnendes Begrenzungszeichen darin ein, oder, noch schlimmer, mehrere öffnende Begrenzungszeichen. Wohin kommen die schließenden Begrenzungszeichen? Wie viel von dem Code, der bereits vorhanden ist, sollten sie einschließen? Manchmal ist das ziemlich offensichtlich, manchmal aber auch nicht. Sie können ein unangemessenes schließendes Begrenzungszeichen immer löschen, aber wir arbeiten hart daran, die entsprechenden Heuristiken zu verwenden, um das schließende Begrenzungszeichen entweder an der richtigen Stelle einzufügen oder es überhaupt nicht einzufügen.
Was stimmt mit diesem Code nicht? Code-Analyse & Hilfe
Dinge wie Syntaxfärbung und ^ für fehlende Argumente haben wir schon seit Jahrzehnten. Und diese sind äußerst nützlich. Aber was wir wollen, ist etwas Globaleres. Etwas, das nicht so sehr mit der Rechtschreibprüfung vergleichbar ist, sondern eher in der Lage ist, zu sagen, ob ein Stück Text das Richtige bedeutet.
Man könnte meinen, dass es dabei eine Art philosophisches Problem gibt. In der Wolfram Language ist jedes Stück Code – solange es syntaktisch korrekt ist – ein symbolischer Ausdruck, der auf irgendeiner Ebene etwas bedeutet. Die Frage ist, ob dieses „etwas“ das ist, was Sie wollen. Wenn man die typische Struktur von „korrektem Code“ kennt, ist es oft möglich, eine sehr gute Vermutung anzustellen. Und das ist es, was unser neues Code-Analyse-System tut.
Nehmen wir an, Sie haben dieses einfache Stück Code:


Hier ist ein geringfügig komplizierteres Beispiel:

Findet die Codeanalyse echte Fehler? Ja, und wir haben Beweise dafür, denn wir haben es auf unseren internen Code sowie auf Beispiele in unserer Dokumentation angewendet. In Version 12.2 enthielt die Dokumentation für FitRegularization zum Beispiel dieses Beispiel:


Fortschritte im Compiler: Portabilität und Librarying
In Version 12.3 haben wir einen wichtigen Schritt unternommen, um den Arbeitsablauf in diesem Bereich zu vereinfachen. Nehmen wir an, Sie kompilieren eine sehr einfache Funktion:

Was ist diese Ausgabe? Nun, in Version 12.3 ist es ein symbolisches Objekt, das rohen Low-Level-Code enthält:

Aber ein wichtiger Punkt ist, dass alles in diesem symbolischen Objekt enthalten ist. Man kann es also einfach in die Hand nehmen und benutzen:
 |
Es gibt jedoch einen kleinen Haken. Standardmäßig generiert FunctionCompile rohen Low-Level-Code für den Computertyp, auf dem Sie gerade arbeiten. Wenn Sie jedoch die resultierende CompiledCodeFunction auf einen anderen Computertyp übertragen, kann sie den Low-Level-Code nicht mehr verwenden. (Er behält eine Kopie des ursprünglichen Ausdrucks vor der Kompilierung, so dass er weiterhin ausgeführt werden kann, aber nicht den Effizienzvorteil des kompilierten Codes hat).
In Version 12.3 gibt es eine neue Option für FunctionCompile: TargetSystem. Und mit TargetSystem → All können Sie FunctionCompile anweisen, cross-compilierten Low-Level-Code für alle aktuellen Systeme zu erstellen:
 |
Natürlich ist die Kompilierung langsamer. Aber das Ergebnis ist ein portables Objekt, das Low-Level-Code für alle aktuellen Plattformen enthält:
 |
Wenn Sie also ein Notizbuch – oder einen Eintrag im Wolfram Function Repository – haben, das diese Art von CompiledCodeFunction enthält, können Sie es an jemanden schicken, und es wird automatisch auf dessen System ausgeführt.
Es gibt noch ein paar andere Feinheiten in diesem Zusammenhang. Der Low-Level-Code, der standardmäßig in FunctionCompile erstellt wird, ist eigentlich LLVM-IR-Code (Intermediate Representation) und kein reiner Maschinencode. Die LLVM IR ist für jede einzelne Plattform optimiert, aber wenn der Code auf die Plattform geladen wird, gibt es den kleinen zusätzlichen Schritt der lokalen Konvertierung in tatsächlichen Maschinencode. Sie können UseEmbeddedLibrary → True verwenden, um diesen Schritt zu vermeiden, und eine vollständige Bibliothek erstellen, die Ihren Code enthält.
Dadurch wird das Laden von kompiliertem Code auf Ihrer Plattform etwas schneller, aber der Haken ist, dass die Erstellung einer vollständigen Bibliothek nur auf einer bestimmten Plattform möglich ist. Wir haben einen Prototyp für ein Cloud-basiertes Compilation-as-a-Service-System entwickelt, aber es ist noch nicht klar, ob die Geschwindigkeitsverbesserung die Mühe wert ist.
Ein weiteres neues Compiler-Feature in Version 12.3 ist, dass FunctionCompile nun eine Liste oder eine Assoziation von Funktionen annehmen kann, die zusammen kompiliert werden, wobei alle Abhängigkeiten zwischen ihnen optimiert werden.
Der Compiler wird immer stärker und breiter, da immer mehr Funktionen und Typen (wie „Integer128“) unterstützt werden. Zur Unterstützung größerer Kompilierungsprojekte wurde in Version 12.3 das CompilerEnvironmentObject eingeführt. Dabei handelt es sich um ein symbolisches Objekt, das eine ganze Sammlung von kompilierten Ressourcen repräsentiert (z. B. definiert durch FunctionDeclaration), die wie eine Bibliothek wirken und sofort verwendet werden können, um eine Umgebung für zusätzliche Kompilierungen zu schaffen.
Shell, Java, …: Neue eingebaute externe Verbindungen
Da ist zunächst die Shell. Bereits in Version 1.0 gab es den Begriff der „Shell-Escapes“: Geben Sie ! am Anfang einer Zeile ein, und alles, was danach kommt, wird an die Shell Ihres Betriebssystems gesendet. Ein Dritteljahrhundert später ist es etwas ausgefeilter und raffinierter, aber die Grundidee ist dieselbe.
Geben Sie > in ein Notizbuch ein, wählen Sie Shell und geben Sie dann Ihren Shell-Befehl ein:
 |
Das stdout der Shell wird bei der Generierung mit einem Echo versehen, und was zurückkommt, ist ein symbolisches Objekt, aus dem man Dinge wie den Exit-Code oder stdout extrahieren kann:
 |
In früheren Versionen haben wir Funktionen für Sprachen wie Python, Julia, R usw. sowie für SQL hinzugefügt. In dieser Version fügen wir auch Unterstützung für Octave hinzu (ja, die Funktionsnamen sind nicht toll):
 |
Wichtig ist hier jedoch, dass die Datenstrukturen so miteinander verbunden wurden, dass ein Octave-Array als geeigneter Ausdruck zurückkommt, in diesem Fall eine Liste von Listen (die ungefähre Zahlen enthalten, denn das ist alles, was Octave kann).
Übrigens, obwohl externe Sprachzellen in Notizbüchern nett sind, müssen Sie sie definitiv nicht verwenden, und Sie können ExternalEvaluate – oder ExternalFunction – verwenden, um Dinge rein programmatisch zu tun.
Wir haben seit mehr als 20 Jahren eine enge Integration mit Java in Wolfram Language durch J/Link. Aber in Version 12.3 haben wir die Dinge so eingerichtet, dass Sie statt der ausgeklügelten symbolischen Schnittstelle von J/Link zu Java einfach Java-Code direkt in ExternalEvaluate und externe Sprachzellen eingeben können:
 |
Einfache Java-Datenstrukturen werden als Standardausdrücke der Wolfram Language zurückgegeben:
 |
Java-Objekte werden symbolisch durch J/Link dargestellt:
 |
Alles interagiert nahtlos mit J/Link. So können Sie beispielsweise direkt mit J/Link Java-Objekte erstellen, die Sie anschließend mit Java verwenden können, das Sie in einer externen Sprachzelle eingeben:

Wenn Sie eine Java-Funktion definieren, wird sie symbolisch als ExternalFunction-Objekt dargestellt:
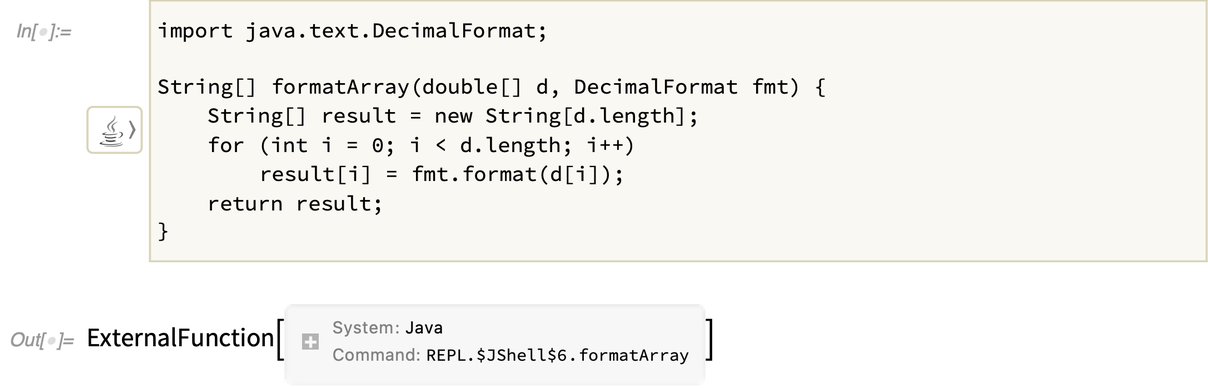
Diese spezielle Funktion benötigt eine Liste von Zahlen und ein Java-Objekt, wie wir es oben mit J/Link erstellt haben:
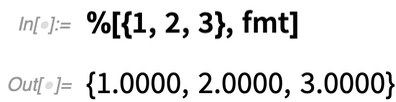
(Ja, diese spezielle Operation ist extrem einfach direkt in der Wolfram Language durchzuführen).
Blockchain, Speicherung, Authentifizierung und Kryptographie
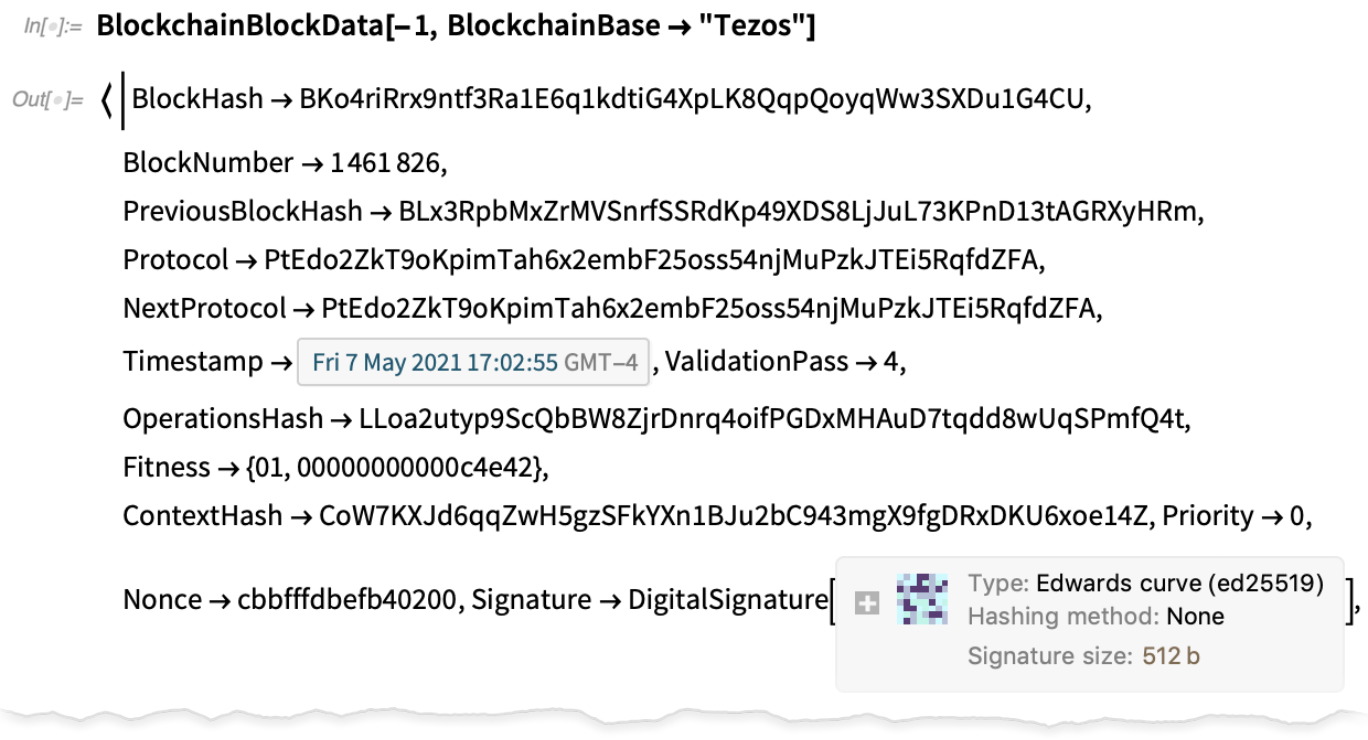
In Version 12.1 haben wir ExternalStorageObject eingeführt, das zunächst IPFS und Dropbox unterstützte. In Version 12.3 haben wir Unterstützung für Amazon S3 hinzugefügt (und, ja, Sie können einen ganzen Bucket von Dateien auf einmal speichern und abrufen):

Ein notwendiger Schritt bei allen Arten von externen Interaktionen ist die Authentifizierung. Und in Version 12.3 haben wir Unterstützung für OAuth 2.0-Workflows hinzugefügt. Sie erstellen einen SecuredAuthenticationKey:

Sie erhalten ein Browserfenster, in dem Sie aufgefordert werden, sich mit Ihrem Konto anzumelden – und schon sind Sie startklar.
Für viele gängige externe Dienste haben wir „vorgefertigte“ ServiceConnect-Verbindungen. Diese erfordern oft eine Authentifizierung. Und für OAuth-basierte APIs (wie Reddit oder Twitter) haben wir unsere WolframConnector-App, die den externen Teil der Authentifizierung vermittelt. Eine neue Funktion von Version 12.3 ist, dass Sie auch Ihre eigene externe App verwenden können, um diese Authentifizierung zu vermitteln, so dass Sie nicht durch die Vereinbarungen mit dem externen Dienst für die WolframConnector-App beschränkt sind.
Unter der Haube von allem, worüber wir hier sprechen, ist Kryptographie. Und in Version 12.3 haben wir einige neue kryptographische Fähigkeiten hinzugefügt; insbesondere haben wir jetzt Unterstützung für alle elliptischen Kurven im NIST Digital Signature FIPS 186-4 Standard, sowie für Edwards Kurven, die Teil von FIPS 186-5 sein werden.
All dies haben wir so gebündelt, dass es sehr einfach ist, Blockchain-Wallets zu erstellen, Transaktionen zu signieren und Daten für Blockchains zu kodieren:


Verteiltes Rechnen und seine Verwaltung
In Version 12.2 haben wir RemoteKernelObject als symbolische Darstellung von entfernten Wolfram Language-Funktionen eingeführt. Ab Version 12.2 war dies für einmalige Auswertungen mit RemoteEvaluate verfügbar. In Version 12.3 haben wir RemoteKernelObject in die Parallelberechnung integriert.
Lassen Sie uns dies für eine meiner Maschinen ausprobieren. Hier ist ein Remote-Kernel-Objekt, das einen einzelnen Kernel auf dem Rechner darstellt:

Jetzt können wir dort eine Berechnung durchführen, wobei wir hier nur die Anzahl der Prozessorkerne abfragen:
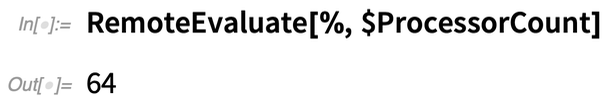
Erstellen wir nun ein entferntes Kernelobjekt, das alle 64 Kerne dieses Rechners nutzt:

Jetzt kann ich diese Kernel starten (und ja, es geht viel schneller und stabiler als vorher):
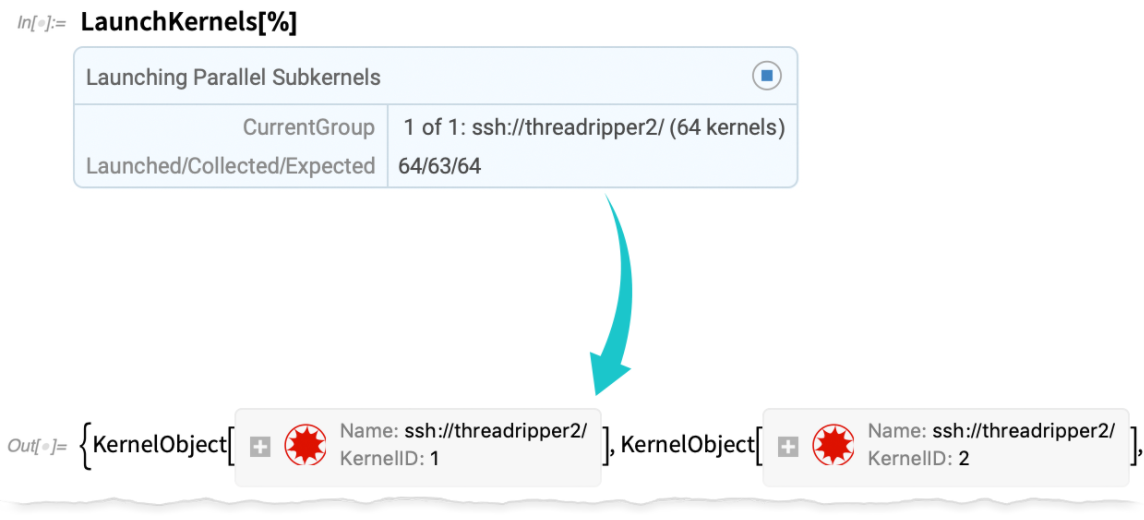
Jetzt kann ich damit parallele Berechnungen durchführen:

Für jemanden wie mich, der oft mit parallelen Berechnungen zu tun hat, wird die Vereinfachung dieser Funktionen in Version 12.3 einen großen Unterschied machen.
Ein Merkmal von Funktionen wie ParallelMap ist, dass sie im Grunde nur Teile einer Berechnung unabhängig an verschiedene Prozessoren senden. Die Dinge können ziemlich kompliziert werden, wenn eine Kommunikation zwischen den Prozessoren erforderlich ist und alles asynchron abläuft.
Die wissenschaftliche Grundlage hierfür ist eng mit der Geschichte der Mehrwegegraphen und den Ursprüngen der Quantenmechanik in unserem Physikprojekt verbunden. Aber auf der praktischen Ebene der Softwareentwicklung geht es um Race Conditions, Thread Safety, Locking usw. Und in Version 12.3 haben wir einige neue Funktionen hinzugefügt.
Insbesondere haben wir die Funktion WithLock hinzugefügt, mit der Dateien (oder lokale Objekte) während einer Berechnung gesperrt werden können, wodurch Störungen zwischen verschiedenen Prozessen, die versuchen, in die Datei zu schreiben, verhindert werden. WithLock bietet einen Low-Level-Mechanismus zur Gewährleistung der Atomarität und Thread-Sicherheit von Operationen.
Es gibt eine übergeordnete Version davon in LocalSymbol. Angenommen, man setzt ein lokales Symbol auf 0:
Starten Sie dann 40 lokale parallele Kernel (sie müssen lokal sein, damit sie Dateien gemeinsam nutzen):
Wegen der Sperrung wird der Zähler nun gezwungen, bei jedem Kernel nacheinander aktualisiert zu werden:

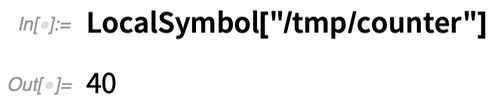
Noch mehr Informationen finden Sie unter: