Mathematica V14
Die Geschichte geht weiter: Ankündigung der Version 14 der Wolfram-Sprache und Mathematica – Die Spitze der Technologie von 2023
Die Version 14.0 der Wolfram-Sprache und Mathematica ist ab sofort sowohl auf dem Desktop als auch in der Cloud verfügbar. Siehe auch weitere ausführliche Informationen zu Version 13.1, Version 13.2 und Version 13.3.
Etwas Größeres und Größeres aufbauen… seit 35 Jahren und zählend
Heute feiern wir einen neuen Meilenstein auf unserer fast vier Jahrzehnte langen Reise mit der Veröffentlichung von Version 14.0 der Wolfram-Sprache und Mathematica. In den letzten zwei Jahren seit der Veröffentlichung von Version 13.0 haben wir kontinuierlich die Früchte unserer Forschung und Entwicklung in .1-Versionen alle sechs Monate geliefert. Heute fassen wir diese und mehr in Version 14.0 zusammen.
Es sind jetzt mehr als 35 Jahre vergangen, seit wir Version 1.0 veröffentlicht haben. Und all die Jahre haben wir weiterhin einen immer höheren Turm an Fähigkeiten aufgebaut, indem wir kontinuierlich den Umfang unserer Vision und die Bandbreite unserer computergestützten Abdeckung der Welt erweitern:

Version 1.0 hatte 554 integrierte Funktionen; in Version 14.0 sind es 6602. Und hinter jeder dieser Funktionen steckt eine Geschichte. Manchmal ist es die Geschichte der Schaffung eines Superalgorithmus, der Jahrzehnte der algorithmischen Entwicklung umfasst. Manchmal ist es die Geschichte der mühsamen Zusammenstellung von Daten, die zuvor noch nie zusammengetragen wurden. Manchmal ist es die Geschichte des Abtauchens in das Wesentliche einer Sache, um neue Ansätze und neue Funktionen zu erfinden, die es erfassen können.
Aus all diesen Teilen haben wir kontinuierlich das zusammenhängende Ganze aufgebaut, das die heutige Wolfram-Sprache ist. Im Bogen der intellektuellen Geschichte definiert sie ein breites, neues, rechnerisches Paradigma zur Formalisierung der Welt. Und auf praktischer Ebene bietet sie eine Superkraft zur Umsetzung rechnerischen Denkens und zur Ermöglichung von „rechnerischem X“ für alle Felder X.
Für uns ist es zutiefst befriedigend zu sehen, was in den letzten drei Jahrzehnten mit allem erreicht wurde, was wir bisher aufgebaut haben. So viele Entdeckungen, so viele Erfindungen, so viel erreicht, so viel gelernt. Und dieser Anblick hilft uns dabei, unsere Bemühungen voranzutreiben, noch mehr anzugehen und weiterhin jede Grenze mit unserer Forschung und Entwicklung zu durchbrechen und die Ergebnisse in neuen Versionen unseres Systems zu liefern.
Unser Forschungs- und Entwicklungsspektrum ist breit gefächert. Von Projekten, die innerhalb von Monaten nach ihrer Konzeption abgeschlossen werden, bis hin zu Projekten, die auf jahrelanger (und manchmal sogar jahrzehntelanger) systematischer Entwicklung beruhen. Und entscheidend für alles, was wir tun, ist die Nutzung dessen, was wir bereits erreicht haben – oft nehmen wir das, was in früheren Jahren der Höhepunkt technischer Leistung war, und verwenden es jetzt als Routine-Baustein, um ein Niveau zu erreichen, das kaum vorstellbar war. Und über die praktische Technologie hinaus gehen wir auch kontinuierlich weiter und weiter und nutzen das mittlerweile umfangreiche konzeptionelle Rahmenwerk, das wir all die Jahre aufgebaut haben, und integrieren es progressiv in das Design der Wolfram-Sprache.
Wir haben all die Jahre hart daran gearbeitet, nicht nur Ideen und Technologien zu schaffen, sondern auch ein praktisches und nachhaltiges Ökosystem zu schaffen, in dem wir dies jetzt und in Zukunft systematisch tun können. Und wir setzen unsere Innovationen in diesen Bereichen fort, erweitern die Bereitstellung dessen, was wir geschaffen haben, auf neue und unterschiedliche Weise und durch neue und unterschiedliche Kanäle. Und in den letzten fünf Jahren konnten wir auch unseren Kern-Designprozess der Welt öffnen – regelmäßig live übertragen, was wir auf einzigartig offene Weise tun.
Und tatsächlich wurden in den letzten Jahren im Wesentlichen alle heute in Version 14.0 gelieferten Inhalte offen mit der Welt geteilt und stellen eine Leistung nicht nur für unsere internen Teams dar, sondern auch für die vielen Menschen, die an unseren Liveübertragungen teilgenommen und kommentiert haben.
Ein Teil dessen, worum es in Version 14.0 geht, ist die kontinuierliche Erweiterung des Bereichs unserer rechnerischen Sprache und unserer rechnerischen Formalisierung der Welt. Aber Version 14.0 geht auch darum, die Funktionalität zu optimieren und zu polieren, die wir bereits definiert haben. Im gesamten System haben wir Dinge effizienter, robuster und bequemer gemacht. Und ja, in komplexer Software sind Fehler aller Art eine theoretische und praktische Unvermeidlichkeit. Und in Version 14.0 haben wir fast 10.000 Fehler behoben, wobei die Mehrheit von unseren zunehmend ausgefeilten internen Softwaretestmethoden gefunden wurde.
Jetzt müssen wir die Welt informieren
Auch nach all der Arbeit, die wir in die Wolfram-Sprache in den letzten Jahrzehnten gesteckt haben, steht uns noch eine weitere Herausforderung bevor: Wie können wir den Menschen klar machen, was die Wolfram-Sprache alles kann? Als wir Version 1.0 veröffentlichten, konnte ich ein Buch von überschaubarer Größe schreiben, das im Wesentlichen das gesamte System erklären konnte. Aber für Version 14.0 – mit all der enthaltenen Funktionalität – würde man wahrscheinlich ein Buch mit etwa 200.000 Seiten benötigen.
Und zu diesem Zeitpunkt kennt niemand (nicht einmal ich selbst!) sofort alles, was die Wolfram-Sprache kann. Natürlich ist eine unserer großen Leistungen, dass wir über all diese Funktionalität hinweg ein eng zusammenhängendes und konsistentes Design beibehalten haben, das letztendlich nur auf einem kleinen Satz grundlegender Prinzipien beruht, die man lernen muss. Aber bei der enormen Skala der Wolfram-Sprache, wie sie heute existiert, ist es zwangsläufig sehr herausfordernd zu wissen, was möglich ist – und was jetzt in rechnerischen Begriffen formuliert werden kann. Und allzu oft, wenn ich den Leuten zeige, was möglich ist, bekomme ich die Antwort: „Ich hatte keine Ahnung, dass die Wolfram-Sprache das kann!“
In den letzten Jahren haben wir daher immer mehr Wert darauf gelegt, groß angelegte Mechanismen aufzubauen, um die Wolfram-Sprache den Menschen zu erklären. Es beginnt auf einer sehr feingranulierten Ebene mit „Just-in-Time-Informationen“, die beispielsweise durch Vorschläge bereitgestellt werden, wenn Sie tippen. Dann gibt es für jede Funktion (oder andere Konstruktion in der Sprache) Seiten, die die Funktion erklären, mit umfangreichen Beispielen. Und jetzt fügen wir zunehmend „Just-in-Time-Lernmaterial“ hinzu, das die Konkretheit der Funktionen nutzt, um in sich geschlossene Erklärungen des umfassenderen Kontexts dessen zu liefern, was sie tun.
Übrigens müssen wir die Wolfram-Sprache in modernen Zeiten nicht nur den Menschen erklären, sondern auch KIs – und unsere sehr umfangreiche Dokumentation und Beispiele haben sich als äußerst wertvoll erwiesen, um LLMs darin zu trainieren, die Wolfram-Sprache zu verwenden. Und für KIs bieten wir eine Vielzahl von Tools an – wie sofortigen rechnerischen Zugriff auf die Dokumentation und rechnerische Fehlerbehandlung. Und mit unserer Chat-Notebook-Technologie gibt es auch eine neue „Einstiegsrampe“, um Wolfram-Sprache-Code aus sprachlicher (oder visueller usw.) Eingabe zu erstellen.
Aber wie sieht das Gesamtbild der Wolfram-Sprache aus? Sowohl für Menschen als auch für KIs ist es wichtig, Dinge auf einer höheren Ebene erklären zu können, und in diese Richtung gehen wir immer mehr. Seit mehr als 30 Jahren haben wir „Leitfaden-Seiten“, die spezifische Funktionalitäten in bestimmten Bereichen zusammenfassen. Jetzt fügen wir „Kernbereichsseiten“ hinzu, die ein breiteres Bild großer Funktionsbereiche geben – jeder davon deckt im Grunde genommen das ab, was ansonsten ein eigenständiges Produkt sein könnte, wenn es nicht nur ein integrierter Bestandteil der Wolfram-Sprache wäre:

Aber wir gehen noch viel weiter und erstellen ganze Kurse und Bücher, die moderne, praxisnahe Einführungen in eine breite Palette von Bereichen ermöglichen, die durch die Wolfram-Sprache unterstützt werden. Wir haben mittlerweile den Stoff vieler Standard-College-Kurse (und noch viel mehr) auf eine neue und sehr effektive „rechnerische“ Weise behandelt, die sofortiges praktisches Engagement mit Konzepten ermöglicht:

All diese Kurse beinhalten nicht nur Vorlesungen und Notebooks, sondern auch automatisch bewertete Übungen sowie offizielle Zertifizierungen. Außerdem haben wir einen regelmäßigen Kalender für von Instruktoren geleitete Peer-Studiengruppen, bei denen alle zur gleichen Zeit zusammenkommen, um über diese Kurse zu diskutieren. Und ja, unser Betrieb von Wolfram U entwickelt sich mittlerweile zu einer bedeutenden Bildungseinrichtung mit vielen tausend Studierenden zu jedem beliebigen Zeitpunkt.
Neben ganzen Kursen bieten wir auch „Miniserien“ von Vorlesungen zu spezifischen Themen an:

Und wir bieten auch Kurse und Bücher zur Wolfram-Sprache selbst an, wie meine „Elementare Einführung in die Wolfram-Sprache“, die in diesem Jahr in der dritten Auflage erschienen ist (und einen zugehörigen Kurs, eine Online-Version usw. hat):

In eine etwas andere Richtung haben wir unsere Wolfram Summer School um eine Wolfram Winter School erweitert und unser Wolfram High School Summer Research Program erheblich ausgebaut, indem wir ganzjährige Programme, Programme für Mittelschüler usw. hinzugefügt haben – einschließlich des neuen wöchentlichen Aktivitätsprogramms „Computational Adventures“.
Dann gibt es noch das Livestreaming. Wir führen wöchentliche „R&D Livestreams“ mit unserem Entwicklungsteam durch (und manchmal auch mit externen Gästen). Und auch ich selbst habe viel Livestreaming gemacht (allein im Jahr 2023 232 Stunden) – einige davon sind Design-Reviews der Funktionalität der Wolfram-Sprache, und einige davon sind Fragenbeantwortungen, technischer und anderer Natur.
Die Liste der Möglichkeiten, wie wir die Welt über die Wolfram-Sprache informieren, ist lang. Da ist die Wolfram Community, die voller interessanter Beiträge ist und immer mehr Leser hat. Es gibt Websites wie die Wolfram Challenges. Es gibt unsere Wolfram Technology Conferences. Und noch vieles mehr.
Wir haben immense Anstrengungen unternommen, um den gesamten Wolfram-Technologiestapel in den letzten vier Jahrzehnten aufzubauen. Und selbst während wir weiterhin aggressiv daran arbeiten, bauen wir auch immer mehr darauf auf, der Welt zu erklären, was darin steckt, und den Menschen (und KIs) zu helfen, es bestmöglich zu nutzen. Aber in gewisser Weise ist alles, was wir tun, nur ein Samen für das, was die breitere Gemeinschaft der Wolfram-Sprache-Benutzer tut und tun kann. Wir verbreiten die Leistungsfähigkeit der Wolfram-Sprache an immer mehr Menschen und Bereiche.
Die LLMs sind gelandet
Die Machine-Learning-Superfunktionen Classify und Predict erschienen erstmals in der Wolfram-Sprache im Jahr 2014 (Version 10). Im nächsten Jahr begannen Funktionen wie ImageIdentify und LanguageIdentify aufzutauchen, und innerhalb weniger Jahre hatten wir unser gesamtes neuronales Netz-Framework und das Neural Net Repository eingeführt. Darin enthalten waren verschiedene neuronale Netze für die Sprachmodellierung, die es uns ermöglichten, Funktionen wie SpeechRecognize und eine experimentelle Version von FindTextualAnswer zu entwickeln. Aber – wie alle anderen auch – wurden wir Ende 2022 von ChatGPT und seinen bemerkenswerten Fähigkeiten überrascht.
Sehr schnell erkannten wir, dass ein bedeutender neuer Anwendungsfall – und Markt – für Wolfram|Alpha und die Wolfram-Sprache entstanden war. Jetzt waren es nicht nur Menschen, die die von uns entwickelten Werkzeuge benötigten; es waren auch KIs. Bis März 2023 hatten wir mit OpenAI zusammengearbeitet, um unsere Wolfram Cloud-Technologie zu nutzen und ein Plugin für ChatGPT bereitzustellen, das es ihm ermöglicht, Wolfram|Alpha und die Wolfram-Sprache aufzurufen. LLMs wie ChatGPT bieten bemerkenswerte neue Fähigkeiten bei der Reproduktion menschlicher Sprache, grundlegenden menschlichen Denkens und allgemeinem Allgemeinwissen. Aber – wie ununterstützte Menschen – sind sie nicht darauf eingestellt, sich mit detaillierten Berechnungen oder präzisem Wissen zu befassen. Dafür müssen sie wie Menschen Formalismen und Werkzeuge verwenden. Und das bemerkenswerte ist, dass die Formalismen und Werkzeuge, die wir in der Wolfram-Sprache (und Wolfram|Alpha) entwickelt haben, im Wesentlichen perfekt zu dem passen, was sie benötigen.
Wir haben die Wolfram-Sprache geschaffen, um eine Brücke zwischen dem darzustellen, worüber Menschen nachdenken, und dem, was Berechnung ausdrücken und umsetzen kann. Und jetzt können auch die KIs das nutzen. Die Wolfram-Sprache bietet nicht nur Menschen einen Mittelweg, um „rechnerisch zu denken“, sondern auch KIs. Und wir haben kontinuierlich daran gearbeitet, die Technik zu entwickeln, damit KIs die Wolfram-Sprache so einfach wie möglich nutzen können.
Aber neben LLMs, die die Wolfram-Sprache nutzen, besteht auch die Möglichkeit, dass die Wolfram-Sprache LLMs verwendet. Und bereits im Juni 2023 (Version 13.3) haben wir eine umfangreiche Sammlung von LLM-basierten Fähigkeiten in der Wolfram-Sprache veröffentlicht. Eine Kategorie sind LLM-Funktionen, die LLMs effektiv als „interne Algorithmen“ für Operationen in der Wolfram-Sprache verwenden:

Wie typisch für die Wolfram-Sprache haben wir eine symbolische Darstellung für LLMs: LLMConfiguration[…] repräsentiert ein LLM mit seinen verschiedenen Parametern, Anweisungen usw. In den letzten Monaten haben wir kontinuierlich Verbindungen zur gesamten Bandbreite beliebter LLMs hinzugefügt, wodurch die Wolfram-Sprache nicht nur zu einem einzigartigen Drehkreuz für die Verwendung von LLMs, sondern auch für die Untersuchung der Leistung – und der Wissenschaft – von LLMs wird.
Sie können Ihre eigenen LLM-Funktionen in der Wolfram-Sprache definieren. Aber es gibt auch das Wolfram Prompt Repository, das eine ähnliche Rolle für LLM-Funktionen spielt wie das Wolfram Function Repository für gewöhnliche Wolfram-Sprache-Funktionen. Es gibt ein öffentliches Prompt-Repository, das bisher mehrere hundert kuratierte Prompts enthält. Aber es ist auch möglich, dass jeder seine Prompts in der Wolfram Cloud veröffentlicht und öffentlich (oder privat) zugänglich macht. Die Prompts können Personas definieren („sprich wie ein [stereotypischer] Pirat“). Sie können KI-orientierte Funktionen definieren („schreibe es mit Emoji“). Und sie können Modifikatoren definieren, die die Form der Ausgabe beeinflussen („Haiku-Stil“):

Neben dem programmatischen Aufruf von LLMs innerhalb der Wolfram-Sprache gibt es das neue Konzept (erstmals eingeführt in Version 13.3) der „Chat-Notebooks“. Chat-Notebooks stellen eine neue Art von Benutzeroberfläche dar, die die grafischen, rechnerischen und dokumentenbasierten Funktionen traditioneller Wolfram-Notebooks mit den neuen sprachlichen Schnittstellenfähigkeiten kombiniert, die uns von LLMs gebracht werden.
Die grundlegende Idee eines Chat-Notebooks – wie sie in Version 13.3 eingeführt und jetzt in Version 14.0 erweitert wurde – ist, dass Sie „Chat-Zellen“ (durch Eingabe von ‚) haben können, deren Inhalt nicht an den Wolfram-Kernel gesendet wird, sondern stattdessen an ein LLM:

Sie können „Funktions-Prompts“ – beispielsweise aus dem Wolfram Prompt Repository – direkt in einem Chat-Notebook verwenden:

Ab Version 14.0 können Sie auch Wolfram Language-Berechnungen direkt in Ihr „Gespräch“ mit dem LLM einbinden:

(Sie geben \ ein, um Wolfram Language einzufügen, ganz ähnlich wie Sie <* … *> verwenden können, um Wolfram Language in externe Bewertungszellen einzufügen.)
Eine Sache bei Chat-Notizbüchern ist, dass sie sich – wie der Name schon sagt – wirklich auf das „Chatten“ und die sequentielle Interaktion mit einem LLM konzentrieren. In einem gewöhnlichen Notizbuch spielt es keine Rolle, wo im Notizbuch jede Wolfram Language-Bewertung angefordert wird; Relevant ist lediglich die Reihenfolge, in der der Wolfram-Kernel die Auswertungen durchführt. Aber in einem Chat-Notizbuch sind die „LLM-Bewertungen“ immer Teil eines „Chats“, der explizit im Notizbuch angelegt ist.
Ein wichtiger Bestandteil von Chat-Notizbüchern ist das Konzept eines Chat-Blocks: Geben Sie ~ ein und Sie erhalten ein Trennzeichen im Notizbuch, das „einen neuen Chat startet“:

Chat-Notebooks – mit all ihren typischen Wolfram-Notebook-Bearbeitungs-, Strukturierungs-, Automatisierungs- usw. Fähigkeiten – sind als „LLM-Schnittstellen“ sehr leistungsfähig. Aber es gibt auch eine weitere Dimension, die durch die Fähigkeit von LLMs, die Wolfram-Sprache als Werkzeug aufzurufen, ermöglicht wird.
Auf einer Ebene bieten Chat-Notebooks eine „Einstiegsrampe“ für die Verwendung der Wolfram-Sprache. Wolfram|Alpha – und noch mehr die Wolfram|Alpha Notebook Edition – ermöglichen es Ihnen, Fragen in natürlicher Sprache zu stellen, die dann in die Wolfram-Sprache übersetzt und beantwortet werden. Aber in Chat-Notebooks können Sie über das Stellen spezifischer Fragen hinausgehen. Stattdessen können Sie durch den LLM einfach „anfangen zu chatten“, worüber Sie etwas tun möchten, dann den generierten Wolfram-Sprache-Code erstellen und ausführen lassen:

Der typische Ablauf sieht folgendermaßen aus: Zunächst müssen Sie in rechnerischen Begriffen konzeptualisieren, was Sie wollen. (Und ja, dieser Schritt erfordert rechnerisches Denken – eine sehr wichtige Fähigkeit, die bisher von viel zu wenigen Menschen gelernt wurde.) Dann teilen Sie dem LLM mit, was Sie wollen, und er wird versuchen, Wolfram-Sprachcode zu schreiben, um dies zu erreichen. Er wird den Code typischerweise für Sie ausführen (aber Sie können es auch selbst tun) – und Sie können sehen, ob Sie bekommen haben, was Sie wollten. Aber entscheidend ist, dass die Wolfram-Sprache nicht nur von Computern, sondern auch von Menschen gelesen werden soll. Und besonders da LLMs tatsächlich meistens ziemlich guten Wolfram-Sprache-Code zu schreiben scheinen, können Sie erwarten, dass Sie lesen, was sie geschrieben haben, und sehen, ob es das ist, was Sie wollten. Wenn ja, können Sie diesen Code nehmen und als „solides Bauelement“ für das verwenden, was immer größeres System Sie aufzubauen versuchen. Andernfalls können Sie es entweder selbst korrigieren oder versuchen, mit dem LLM zu chatten, um es zu erreichen.
Eine der Dinge, die wir im obigen Beispiel sehen, ist der LLM, der innerhalb des Chat-Notebooks einen „Tool-Aufruf“ macht, hier an einen Wolfram-Sprache-Auswerter. In der Wolfram-Sprache gibt es nun einen ganzen Mechanismus zur Definition von Werkzeugen für LLMs – wobei jedes Werkzeug durch ein LLMTool-symbolisches Objekt repräsentiert wird. In Version 14.0 gibt es eine experimentelle Version des neuen Wolfram LLM Tool Repository mit einigen vordefinierten Werkzeugen:

In einem Standard-Chat-Notebook hat der LLM Zugriff auf einige Standardwerkzeuge, zu denen nicht nur der Wolfram-Sprache-Auswerter gehört, sondern auch Dinge wie die Suche in der Wolfram-Dokumentation und die Abfrage von Wolfram|Alpha. Es ist üblich, den LLM hin und her gehen zu sehen, während er versucht, „funktionierenden Code“ zu schreiben, und zum Beispiel manchmal „zurückgreifen“ muss (genauso wie Menschen es tun) und die Dokumentation liest.
Neu in Version 14.0 ist der experimentelle Zugang zu multimodalen LLMs, die Bilder sowie Text als Eingabe verwenden können. Wenn diese Fähigkeit aktiviert ist, kann der LLM „Bilder aus dem generierten Code betrachten“, prüfen, ob sie dem entsprechen, was gefragt wurde, und sich gegebenenfalls selbst korrigieren:

The deep integration of images into Wolfram Language—and Wolfram Notebooks—yields all sorts of possibilities for multimodal LLMs. Here we’re giving a plot as an image and asking the LLM how to reproduce it:

Eine weitere Richtung für multimodale LLMs besteht darin, Daten (in den hunderten von Formaten, die von der Wolfram-Sprache akzeptiert werden) zu verwenden und das LLM zu nutzen, um deren Visualisierung und Analyse in der Wolfram-Sprache zu führen. Hier ist ein Beispiel, das von einer Datei data.csv im aktuellen Verzeichnis auf Ihrem Computer ausgeht:

Eine Sache, die sehr schön ist, wenn man die Wolfram-Sprache direkt verwendet, ist, dass alles, was man tut (nun ja, es sei denn, man verwendet RandomInteger, etc.), vollständig reproduzierbar ist; führen Sie dieselbe Berechnung zweimal durch, und Sie erhalten dasselbe Ergebnis. Das trifft auf LLMs (zumindest im Moment) nicht zu. Wenn man LLMs verwendet, fühlt es sich eher wie etwas Vergängliches und Flüchtiges an als die Verwendung der Wolfram-Sprache. Man muss alle guten Ergebnisse festhalten, die man erhält – denn man könnte sie vielleicht nie wieder reproduzieren können. Ja, es ist sehr hilfreich, dass man alles in einem Chat-Notebook speichern kann, auch wenn man es nicht erneut ausführen und dieselben Ergebnisse erhalten kann. Aber die „dauerhaftere“ Verwendung von LLM-Ergebnissen tendiert dazu, „offline“ zu sein. Man verwendet einen LLM „im Voraus“, um etwas herauszufinden, und nutzt dann einfach das erhaltene Ergebnis.
Eine unerwartete Anwendung von LLMs für uns war die Vorschläge von Funktionsnamen. Mit der „Erfahrung“ des LLMs darüber, worüber die Leute sprechen, ist es in der Lage, Funktionen vorzuschlagen, die für die Menschen nützlich sein könnten. Und ja, wenn es Code schreibt, hat es die Angewohnheit, solche Funktionen zu halluzinieren. Aber in Version 14.0 haben wir tatsächlich eine Funktion – DigitSum – hinzugefügt, die uns von LLMs vorgeschlagen wurde. Und in ähnlicher Weise können wir erwarten, dass LLMs nützlich sind, um Verbindungen zu externen Datenbanken, Funktionen usw. herzustellen. Der LLM „liest die Dokumentation“ und versucht, Wolfram-Sprache-„Klebe“-Code zu schreiben, der dann überprüft, überprüft usw. werden kann und bei Bedarf verwendet werden kann.
Dann gibt es noch die Datenkuratierung, ein Bereich, in dem wir durch Wolfram|Alpha und viele unserer anderen Bemühungen in den letzten Jahrzehnten äußerst kompetent geworden sind. Inwieweit können LLMs dabei helfen? Sie „lösen das gesamte Problem“ sicherlich nicht, aber ihre Integration mit den Werkzeugen, die wir bereits haben, hat es uns im letzten Jahr ermöglicht, einige unserer Datenkurierungs-Pipelines um den Faktor zwei oder mehr zu beschleunigen.
Wenn wir den gesamten Technologie- und Inhaltsstapel betrachten, der in der modernen Wolfram-Sprache vorhanden ist, wird die überwältigende Mehrheit davon nicht von LLMs unterstützt und wird es wahrscheinlich auch nicht. Aber es gibt viele – manchmal unerwartete – Bereiche, in denen LLMs Heuristiken dramatisch verbessern oder anderweitig Probleme lösen können. Und in Version 14.0 gibt es nun eine Vielzahl von „LLM inside“-Funktionen.
Ein Beispiel ist TextSummarize, eine Funktion, die wir seit vielen Versionen in Erwägung gezogen haben – aber jetzt, dank LLMs, endlich auf einem nützlichen Niveau implementieren können:

Die Haupt-LLMs, die wir derzeit verwenden, basieren auf externen Diensten. Aber wir entwickeln Funktionen, die es uns ermöglichen, LLMs in lokalen Wolfram-Sprache-Installationen auszuführen, sobald dies technisch machbar ist. Eine Fähigkeit, die tatsächlich Teil unserer Haupt-Maschinenlernbemühungen ist, ist NetExternalObject – eine Möglichkeit, symbolisch ein extern definiertes neuronales Netz zu repräsentieren, das innerhalb der Wolfram-Sprache ausgeführt werden kann. NetExternalObject ermöglicht es Ihnen beispielsweise, ein beliebiges Netzwerk in ONNX-Form zu nehmen und es effektiv als Komponente in einem Wolfram-Sprache-Neuronennetz zu behandeln. Hier ist ein Netzwerk zur Tiefenschätzung von Bildern, das wir hier aus einem externen Repository importieren (obwohl in diesem Fall bereits ein ähnliches Netzwerk im Wolfram Neural Net Repository vorhanden ist):

Nun können wir dieses importierte Netzwerk auf ein Bild anwenden, das mit unserem integrierten Bild-Encoder codiert wurde. Anschließend nehmen wir das Ergebnis und visualisieren es:

Es ist oft sehr praktisch, Netzwerke lokal ausführen zu können, aber manchmal ist dafür recht leistungsfähige Hardware erforderlich. Zum Beispiel gibt es jetzt eine Funktion im Wolfram Function Repository, die die Bildsynthese vollständig lokal durchführt – aber um sie auszuführen, benötigen Sie eine GPU mit mindestens 8 GB VRAM:

Übrigens haben sich auf der Grundlage von LLM-Prinzipien (und Ideen wie Transformatoren) auch andere Fortschritte im maschinellen Lernen ergeben, die eine breite Palette von Bereichen der Wolfram-Sprache gestärkt haben – ein Beispiel dafür ist die Bildsegmentierung, bei der ImageSegmentationComponents jetzt eine robuste „inhaltssensitive“ Segmentierung ermöglicht:

Immer noch stark in der Analysis
Als Mathematica 1.0 im Jahr 1988 veröffentlicht wurde, war es ein „Wow“, dass man jetzt routinemäßig Integrale symbolisch am Computer berechnen konnte. Es dauerte nicht lange, bis wir an den Punkt kamen – zuerst mit unbestimmten Integralen und später mit bestimmten Integralen – an dem das, was jetzt die Wolfram-Sprache ist, Integrale besser als jeder Mensch berechnen konnte. Bedeutete das, dass wir mit der Analysis „fertig“ waren? Nun, nein. Zunächst kamen Differentialgleichungen und partielle Differentialgleichungen. Es dauerte ein Jahrzehnt, um symbolische DGLs auf ein übermenschliches Niveau zu bringen. Und bei symbolischen PDGLs dauerte es bis vor wenigen Jahren. Irgendwo auf dem Weg haben wir diskrete Analysis, asymptotische Entwicklungen und Integraltransformationen aufgebaut. Außerdem haben wir viele spezifische Funktionen implementiert, die für Anwendungen wie Statistik, Wahrscheinlichkeitsrechnung, Signalverarbeitung und Regelungstechnik benötigt werden. Aber selbst jetzt gibt es noch Frontiers.
Und in Version 14 gibt es bedeutende Fortschritte in der Analysis. Eine Kategorie betrifft die Struktur der Antworten. Ja, man kann eine Formel haben, die die Lösung einer Differentialgleichung korrekt darstellt. Aber ist sie in der besten, einfachsten oder nützlichsten Form? Nun, in Version 14 haben wir hart daran gearbeitet, sicherzustellen, dass dies der Fall ist – oft wird die Größe der generierten Ausdrücke dramatisch reduziert.
Ein weiterer Fortschritt betrifft die Erweiterung des Bereichs der „vorgefertigten“ Analysisoperationen. Wir konnten Ableitungen bereits seit Version 1.0 durchführen. Aber in Version 14 haben wir implizite Differentiation hinzugefügt. Und ja, man kann leicht eine grundlegende Definition dafür geben, indem man gewöhnliche Differentiation und Gleichungslösung verwendet. Aber durch Hinzufügen einer expliziten ImplicitD verpacken wir das alles – und behandeln die kniffligen Randfälle –, sodass es zur Routine wird, die implizite Differentiation überall dort zu verwenden, wo man möchte:

Eine weitere Kategorie von vorgefertigten Analysisoperationen, die neu in Version 14 sind, sind solche für vektorbasierte Integration. Es war immer möglich, dies im „Do-it-yourself“-Modus zu tun. Aber in Version 14 sind sie jetzt optimierte integrierte Funktionen – die übrigens auch Randfälle abdecken usw. Und was sie möglich gemacht hat, ist tatsächlich eine Entwicklung in einem anderen Bereich: unser jahrzehntelanges Projekt, geometrische Berechnungen in die Wolfram-Sprache aufzunehmen – was uns eine natürliche Möglichkeit gab, geometrische Konstruktionen wie Kurven und Flächen zu beschreiben:


Eine verwandte neue Funktionalität in Version 14 ist ContourIntegrate:

Funktionen wie ContourIntegrate liefern einfach „die Antwort“. Aber wenn man Analysis lernt oder erkundet, ist es oft auch nützlich, Dinge auf eine schrittweise Weise zu tun. In Version 14 können Sie mit einem inaktiven Integral beginnen

und explizit Operationen wie Variablentransformationen durchführen:

Manchmal werden tatsächliche Antworten in inaktiver Form ausgedrückt, insbesondere als unendliche Summen

Version 14 ermöglicht die Funktion TruncateSum, eine solche Summe zu nehmen und eine abgeschnittene „Approximation“ zu generieren:

Funktionen wie D und Integrate sowie LineIntegrate und SurfaceIntegrate sind in gewisser Weise „klassische Analysis“, die seit mehr als drei Jahrhunderten gelehrt und verwendet wird. Aber in Version 14 unterstützen wir auch, was wir als „aufkommende“ Analysisoperationen betrachten können, wie die fraktionale Differentiation:

Kernsprache
Welche Grundbausteine können wir am besten verwenden, um unser Konzept der Berechnung aufzubauen? Das ist in gewisser Weise die Frage, die ich seit mehr als vier Jahrzehnten stelle und die die Funktionen und Strukturen im Kern der Wolfram-Sprache bestimmt hat.
Im Laufe der Jahre erkennen wir mehr und mehr von dem, was möglich ist, und erfinden neue Grundbausteine, die nützlich sein werden. Und ja, die Welt – und die Wege, wie Menschen mit Computern interagieren – verändern sich ebenfalls, eröffnen neue Möglichkeiten und bringen neues Verständnis für Dinge. Oh, und dieses Jahr gibt es LLMs, die „den intellektuellen Sinn der Welt erfassen“ können und neue Funktionen vorschlagen können, die in das von uns mit der Wolfram-Sprache geschaffene Framework passen. (Übrigens gab es auch viele großartige Vorschläge von den Zuschauern unserer Designüberprüfungs-Livestreams.)
Eine neue Konstruktion, die in Version 13.1 hinzugefügt wurde – und die ich persönlich sehr nützlich finde – ist Threaded. Wenn eine Funktion listbar ist – wie Plus – werden die obersten Ebenen von Listen kombiniert:

Aber manchmal möchten Sie, dass eine Liste auf der untersten Ebene in die andere eingefügt wird, nicht auf der höchsten. Und jetzt gibt es eine Möglichkeit, das zu spezifizieren, indem Sie Threaded verwenden:


Ein weiteres Beispiel, eingeführt im Jahr 2020, ist Splice:

Ein klassisches Problem im Design der Wolfram-Sprache betrifft die Behandlung von unendlichen Auswertungsschleifen. In Version 13.2 haben wir die symbolische Konstruktion TerminatedEvaluation eingeführt, um eine bessere Definition dafür zu liefern, wie außer Kontrolle geratene Auswertungen beendet wurden:

In einer interessanten Verbindung besteht in der berechnenden Darstellung der Physik in unserem kürzlichen Physikprojekt die direkte Analogie zu nichtterminierenden Auswertungen darin, dass sie das scheinbar unendliche Universum ermöglichen, in dem wir leben.
Aber was passiert eigentlich „innerhalb einer Auswertung“, ob sie nun terminiert oder nicht? Ich habe immer eine gute Darstellung davon haben wollen. Tatsächlich haben wir bereits in Version 2.0 Trace zu diesem Zweck eingeführt:

Aber wie viele Details dessen, was der Auswerter tut, sollte man zeigen? Bereits in Version 2.0 haben wir die Option TraceOriginal eingeführt, die jeden vom Auswerter verfolgten Pfad verfolgt

Aber oft ist das viel zu viel. In Version 14.0 haben wir die neue Einstellung TraceOriginal→Automatic eingeführt, die in ihrer Ausgabe Auswertungen ausschließt, die nichts tun:

Das mag pedantisch erscheinen, aber bei einem Ausdruck von erheblicher Größe ist dies ein entscheidendes Prüfelement. Hier ist zum Beispiel eine grafische Darstellung einer einfachen arithmetischen Auswertung mit TraceOriginal→True:

Und hier ist die entsprechende „beschnittene“ Version mit TraceOriginal→Automatic:

(Übrigens sind die Strukturen dieser Diagramme eng mit Dingen wie den kausalen Graphen verwandt, die wir in unserem Physikprojekt konstruieren.)
Im Bestreben, Rechenprimitiven zur Wolfram-Sprache hinzuzufügen, sind in Version 14.0 zwei neue Funktionen hinzugekommen: Comap und ComapApply. Die Funktion Map nimmt eine Funktion f und „macht ein Mapping“ über eine Liste:

Comap führt die „mathematisch gegenüberliegende“ Version davon aus, indem es eine Liste von Funktionen nimmt und diese auf ein einzelnes Argument „comappt“:

Warum ist das nützlich? Zum Beispiel möchte man möglicherweise drei verschiedene statistische Funktionen auf eine einzige Liste anwenden. Und jetzt ist es einfach, das mit Comap zu tun:

Übrigens gibt es, genauso wie bei Map, auch eine Operatorform für Comap:

Comap funktioniert gut, wenn die Funktionen, mit denen es umgeht, nur ein Argument annehmen. Wenn man Funktionen hat, die mehrere Argumente annehmen, ist ComapApply typischerweise das, was man verwenden möchte:

Wenn wir über „co-ähnliche“ Funktionen sprechen, wurde in Version 13.2 eine neue Funktion namens PositionSmallest hinzugefügt. Min gibt das kleinste Element in einer Liste zurück; PositionSmallest gibt stattdessen die Positionen der kleinsten Elemente an:

Eine der wichtigen Zielsetzungen in der Wolfram Language ist es, dass möglichst alles „einfach funktioniert“. Als wir Version 1.0 veröffentlichten, konnten Zeichenfolgen davon ausgehen, dass sie nur gewöhnliche ASCII-Zeichen enthalten oder möglicherweise eine externe Zeichenkodierung definiert haben. Und ja, es konnte unordentlich sein, nicht „innerhalb der Zeichenfolge selbst“ zu wissen, welche Zeichen dort sein sollten. Bis zur Version 3.0 im Jahr 1996 waren wir Mitwirkende und frühe Anwender von Unicode, das eine Standardkodierung für „16 Bit Wert“ von Zeichen bereitstellte. Und viele Jahre lang hat uns das gut gedient. Aber im Laufe der Zeit – insbesondere mit dem Aufkommen von Emoji – reichten 16 Bit nicht mehr aus, um alle Zeichen zu codieren, die die Menschen verwenden wollten. Vor einigen Jahren begannen wir daher, die Unterstützung für 32-Bit-Unicode einzuführen, und in Version 13.1 haben wir sie in Notebooks integriert – wodurch Zeichenfolgen etwas viel Reichhaltigeres als zuvor wurden:

Und ja, jetzt können Sie Unicode überall verwenden:

Video als fundamentales Objekt
Als Version 1.0 herauskam, war ein Megabyte viel Speicherplatz. Aber 35 Jahre später haben wir es routinemäßig mit Gigabytes zu tun. Eines der Dinge, die dies praktikabel machen, ist die Berechnung mit Video. Wir haben Video erstmals experimentell in Version 12.1 im Jahr 2020 eingeführt. In den letzten drei Jahren haben wir systematisch unsere Fähigkeit erweitert und gestärkt, mit Video in der Wolfram Language umzugehen. Wahrscheinlich der wichtigste Fortschritt ist, dass Dinge rund um Video jetzt – soweit möglich – einfach funktionieren, ohne unter der Belastung durch die Verarbeitung so großer Datenmengen zu „knarren“.
Wir können Videos direkt in Notebooks erfassen und Videos überall im Notebook robust wiedergeben. Außerdem haben wir Optionen hinzugefügt, wo das Video gespeichert werden soll, damit es für Sie und jeden anderen, dem Sie den Zugriff geben möchten, bequem zugänglich ist.
Die Codierung von Videos ist sehr komplex – und wir unterstützen jetzt robust und transparent mehr als 500 Codecs. Wir führen auch viele praktische Dinge automatisch aus, wie das Drehen von Videos im Hochformat – und die Anwendung von Bildverarbeitungsoperationen wie ImageCrop auf ganze Videos. In jeder Version optimieren wir weiterhin die Geschwindigkeit verschiedener Videooperationen.
Besonderes Augenmerk lag jedoch auf Video-Generatoren: programmatische Möglichkeiten, Videos und Animationen zu erzeugen. Ein grundlegendes Beispiel ist AnimationVideo, das dieselbe Art von Ausgabe wie Animate produziert, aber als Video-Objekt, das entweder direkt in einem Notebook angezeigt oder in MP4 oder einem anderen Format exportiert werden kann.

AnimationVideo basiert darauf, jedes Frame in einem Video durch Auswertung eines Ausdrucks zu berechnen. Eine andere Klasse von Video-Generatoren nimmt eine vorhandene visuelle Struktur und „führt“ sie einfach durch. TourVideo „führt“ Bilder, Grafiken und Geografiken durch; Tour3DVideo (neu in Version 14.0) führt 3D-Geometrie durch:

Eine sehr leistungsstarke Funktion in der Wolfram Language ist die Möglichkeit, beliebige Funktionen auf Videos anzuwenden. Ein Beispiel dafür ist VideoFrameMap, das eine Funktion über die Frames eines Videos abbildet und das in Version 13.2 effizient gemacht wurde:
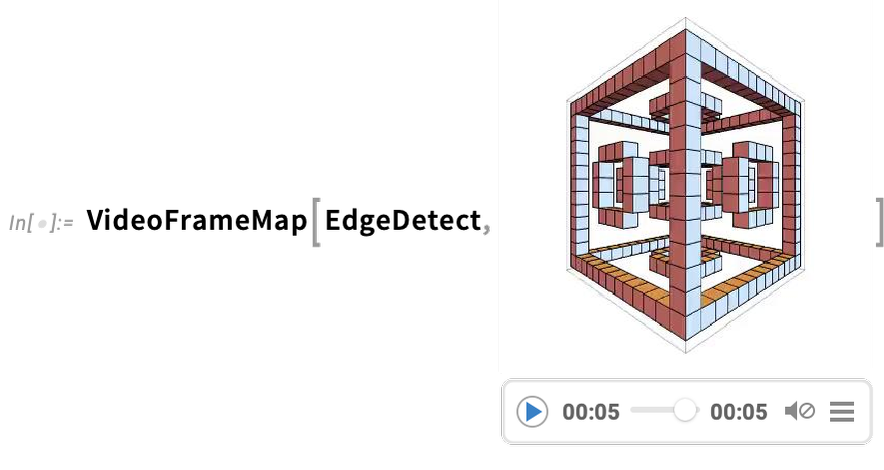
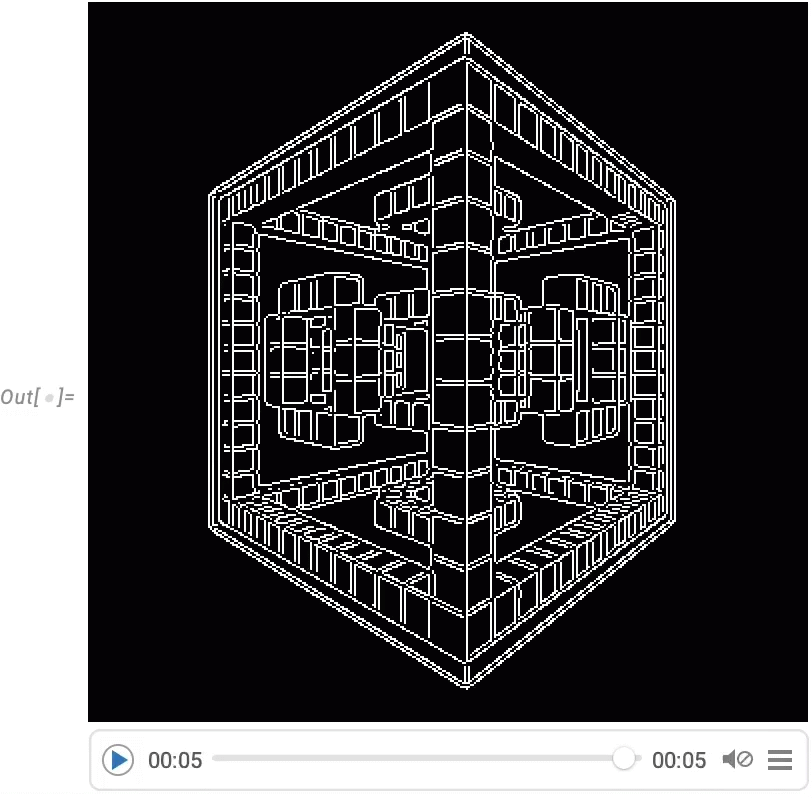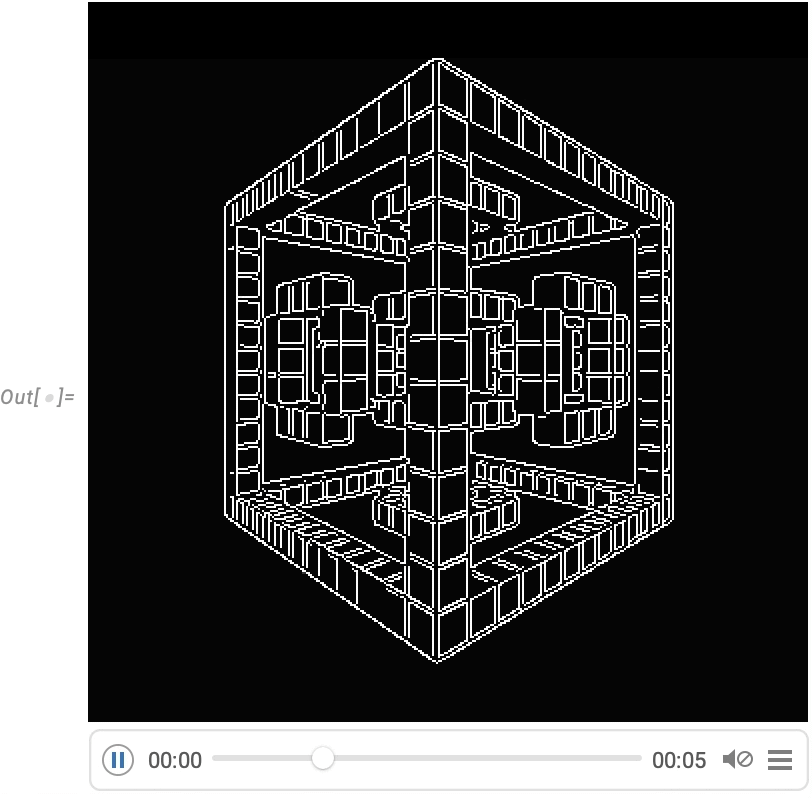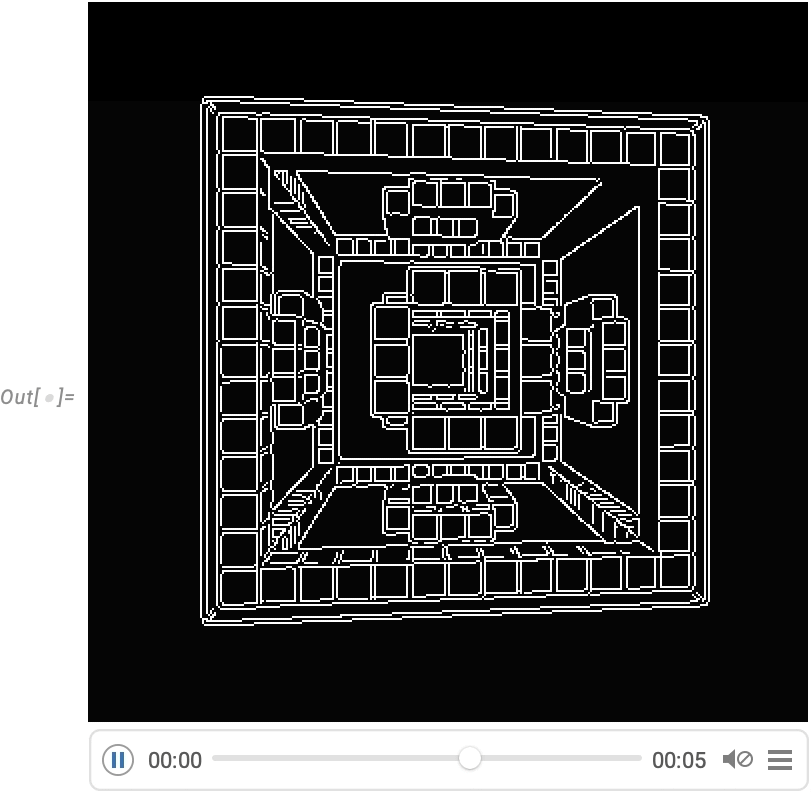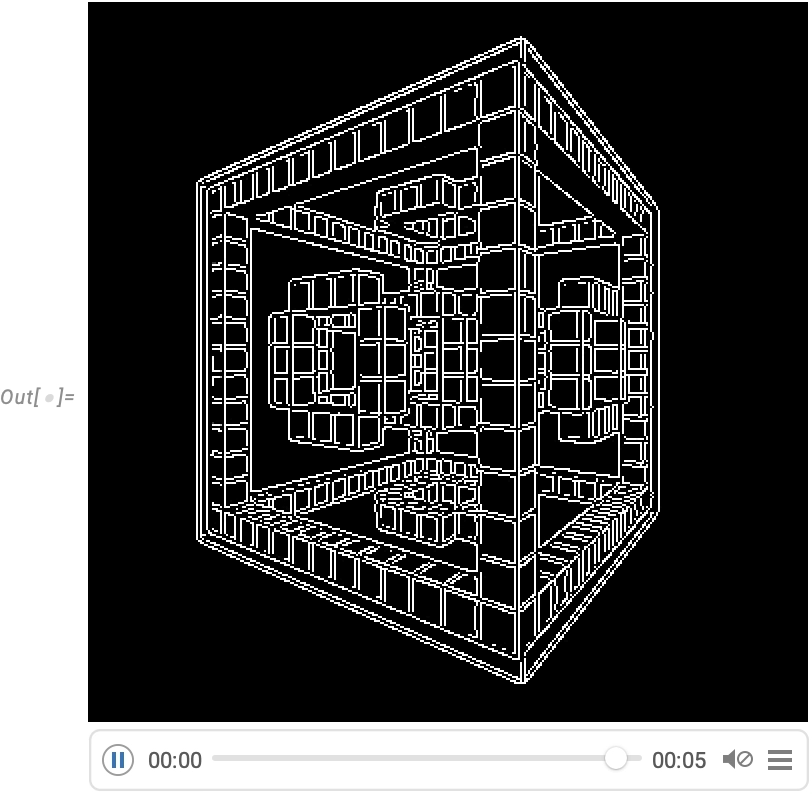
Obwohl die Wolfram Language nicht als interaktives Videobearbeitungssystem gedacht ist, haben wir sichergestellt, dass es möglich ist, eine effiziente programmatische Videobearbeitung in der Sprache durchzuführen. Zum Beispiel haben wir in Version 14.0 Dinge wie Übergangseffekte in VideoJoin und zeitgesteuerte Overlays in OverlayVideo hinzugefügt.
So viel wurde schneller, stärker, eleganter
Mit jeder neuen Version der Wolfram-Sprache fügen wir neue Fähigkeiten hinzu, um den Anwendungsbereich der Sprache weiter auszudehnen. Aber wir setzen auch viel Mühe in etwas, das nicht sofort sichtbar ist: Wir machen bestehende Fähigkeiten schneller, stärker und eleganter.
In Version 14 sind zwei Bereiche, in denen wir einige Beispiele für all dies sehen können, Daten und Mengen. Wir haben vor fast einem Jahrzehnt die Idee der symbolischen Daten (DateObject usw.) eingeführt. Seitdem haben wir viele Dinge auf dieser Struktur aufgebaut. Dabei wurde deutlich, dass es bestimmte Abläufe und Wege gibt, die besonders häufig und praktisch sind. Am Anfang war es am wichtigsten, sicherzustellen, dass die relevanten Funktionen vorhanden sind. Aber im Laufe der Zeit konnten wir sehen, was optimiert und verbessert werden sollte, und das haben wir kontinuierlich umgesetzt.
Zusätzlich, während wir an neuen und verschiedenen Anwendungen gearbeitet haben, haben wir „Lücken“ festgestellt, die gefüllt werden müssen. Zum Beispiel haben wir in Version 14 die Astronomie signifikant weiterentwickelt, und die Unterstützung der Astronomie erforderte die Einführung mehrerer neuer „hochpräziser“ Zeitfähigkeiten, wie die Option TimeSystem, sowie neue astronomieorientierte Kalendersysteme. Ein weiteres Beispiel betrifft die Datumsarithmetik. Was passiert, wenn Sie einen Monat zum 30. Januar hinzufügen möchten? Wo landen Sie dann? Unterschiedliche Arten von Geschäftsanwendungen und Verträgen gehen von verschiedenen Annahmen aus—deshalb haben wir eine Method-Option zu Funktionen wie DatePlus hinzugefügt, um dies zu handhaben. Gleichzeitig haben wir erkannt, dass die Datumsarithmetik in der „Inneren Schleife“ bestimmter Berechnungen involviert ist, und wir haben sie optimiert—mit einer mehr als 100-fachen Beschleunigung in Version 14.0.
Wolfram|Alpha kann seit seiner Einführung im Jahr 2009 mit Einheiten umgehen—mittlerweile mehr als 10.000 davon. Im Jahr 2012 haben wir Quantity eingeführt, um Mengen mit Einheiten in der Wolfram-Sprache zu repräsentieren. In den letzten zehn Jahren haben wir kontinuierlich eine Vielzahl von komplizierten Problemen und Fragen im Zusammenhang mit Einheiten geglättet. Zum Beispiel, was bedeutet 100°C + 20°C? Nun, die 20°C sind nicht wirklich dasselbe wie die 100°C. In der Wolfram-Sprache haben wir jetzt eine systematische Möglichkeit, dies zu handhaben, indem wir zwischen Temperatur und Temperaturdifferenz-Einheiten unterscheiden—so schreiben wir jetzt 100°C + .
Anfangs war unsere Priorität bei Quantity, es so breit wie möglich einzusetzen und es weitreichend in Berechnungen, Visualisierungen usw. im gesamten System zu integrieren. Aber mit der Ausweitung seiner Fähigkeiten haben sich auch seine Anwendungen vervielfacht, was immer wieder die Notwendigkeit vorangetrieben hat, den Betrieb für bestimmte häufige Fälle zu optimieren. Tatsächlich haben wir zwischen Version 13 und Version 14 viele Dinge im Zusammenhang mit Quantity dramatisch beschleunigt, oft um den Faktor 1000 oder mehr.
Ein weiteres Beispiel für Beschleunigungen—ermöglicht durch neue Algorithmen auf multithreaded CPUs—betrifft Polynome. Wir arbeiten seit Version 1 mit Polynomen in der Wolfram-Sprache, aber in Version 13.2 gab es eine dramatische Beschleunigung von bis zu 1000-fach bei Operationen wie Polynomfaktorisierung.
Zusätzlich beschleunigt ein neuer Algorithmus in Version 14.0 numerische Lösungen für Polynom- und transzendente Gleichungen dramatisch—und ermöglicht zusammen mit den neuen MaxRoots-Optionen beispielsweise die Auswahl einiger Wurzeln aus einem Polynom ersten Grades von einer Million
oder um Wurzeln einer transzendentalen Gleichung zu finden, die wir zuvor nicht einmal ohne vorherige Festlegung von Grenzen für ihre Werte versuchen konnten:

Ein weiteres „altbekanntes“ Funktionsmerkmal mit kürzlich erfolgten Verbesserungen betrifft mathematische Funktionen. Seit Version 1.0 haben wir mathematische Funktionen so eingerichtet, dass sie mit beliebiger Genauigkeit berechnet werden können:
Aber in den neueren Versionen wollten wir „genauer in Bezug auf Genauigkeit“ sein und in der Lage sein, rigoros zu berechnen, welcher Bereich von Ausgaben möglich ist, basierend auf dem Bereich der Eingabewerte, die bereitgestellt wurden:
Aber für jede Funktion, bei der wir dies effektiv tun, ist ein neues Theorem erforderlich, und wir haben die Anzahl der abgedeckten Funktionen stetig erhöht – jetzt sind es mehr als 130 – so dass dies „einfach funktioniert“, wenn Sie es in einer Berechnung verwenden müssen.
Die Baumgeschichte geht weiter
Bäume sind nützlich. Wir haben sie erstmals als grundlegende Objekte in der Wolfram-Sprache erst in Version 12.3 eingeführt. Aber jetzt, wo sie da sind, entdecken wir immer mehr Einsatzmöglichkeiten für sie. Um das zu unterstützen, haben wir immer mehr Funktionen hinzugefügt.
Ein Bereich, der sich seit Version 13 deutlich weiterentwickelt hat, ist die Darstellung von Bäumen. Wir haben das allgemeine Grafikdesign verbessert, aber vor allem haben wir viele neue Optionen für die Darstellung eingeführt.
Zum Beispiel hier ist ein zufälliger Baum, bei dem wir spezifiziert haben, dass nur 3 Kinderknoten explizit angezeigt werden sollen: die anderen werden ausgeblendet:

Hier fügen wir mehrere Optionen hinzu, um die Darstellung des Baums zu definieren:

Standardmäßig sind die Zweige in Bäumen mit Ganzzahlen beschriftet, ähnlich wie Teile in einem Ausdruck. Aber in Version 13.1 haben wir die Unterstützung für benannte Zweige eingeführt, die durch Assoziationen definiert werden:

Unsere ursprüngliche Vorstellung von Bäumen war stark darauf ausgerichtet, Elemente zu haben, auf die man explizit zugreifen konnte und die „Payloads“ enthalten konnten. Doch es stellte sich heraus, dass es Anwendungen gab, bei denen nur die Struktur des Baumes wichtig war, nicht jedoch die Elemente selbst. Deshalb haben wir UnlabeledTree hinzugefügt, um „reine Bäume“ zu erstellen:

Bäume sind nützlich, weil viele Arten von Strukturen im Grunde genommen Bäume sind. Seit Version 13 haben wir Funktionen hinzugefügt, um Bäume in verschiedene Arten von Strukturen zu konvertieren und umgekehrt. Zum Beispiel hier ist ein einfaches Dataset-Objekt:

Sie können ExpressionTree verwenden, um dies in einen Baum umzuwandeln:

Und TreeExpression, um es wieder zurück in seine ursprüngliche Form zu konvertieren:

Wir haben auch Funktionen hinzugefügt, um zwischen JSON und XML zu konvertieren sowie Dateiverzeichnis strukturen als Bäume darzustellen:

Endliche Körper
In Version 1.0 hatten wir ganze Zahlen, rationale Zahlen und reelle Zahlen. In Version 3.0 haben wir algebraische Zahlen hinzugefügt (implizit dargestellt durch Root)—und ein Dutzend Jahre später haben wir algebraische Zahlkörper und transzendente Wurzeln hinzugefügt. Für Version 14 haben wir jetzt eine weitere (sehr erwartete) „zahlbezogene“ Struktur hinzugefügt: endliche Körper.
Hier ist unsere symbolische Darstellung des Körpers der ganzen Zahlen modulo 7:

Und hier ist jetzt ein spezifisches Element dieses Körpers:

das wir sofort berechnen können mit:

Aber was wirklich wichtig ist an dem, was wir mit endlichen Körpern gemacht haben, ist, dass wir sie vollständig in andere Funktionen im System integriert haben. Zum Beispiel können wir ein Polynom faktorisieren, dessen Koeffizienten in einem endlichen Körper liegen:

Wir können auch Dinge wie das Finden von Lösungen für Gleichungen über endlichen Körpern durchführen.
Hier ist zum Beispiel ein Punkt auf einer Fermat-Kurve über dem endlichen Körper GF(173):

Und hier ist eine Potenz einer Matrix mit Elementen über dem gleichen endlichen Körper:

Aufbruch ins All: Die Astro-Geschichte
Eine bedeutende neue Fähigkeit, die seit Version 13 hinzugefügt wurde, ist die astrologische Berechnung. Sie beginnt damit, die Positionen von Dingen wie Planeten mit hoher Genauigkeit berechnen zu können. Selbst zu verstehen, was mit „Position“ gemeint ist, ist jedoch kompliziert, da es viele verschiedene Koordinatensysteme zu berücksichtigen gibt. Standardmäßig gibt AstroPosition die Position am Himmel zur aktuellen Zeit von Ihrem Standort Here aus an:

Man kann jedoch auch nach einem anderen Koordinatensystem fragen, wie zum Beispiel globalen galaktischen Koordinaten:

Und hier ist ein Diagramm der Entfernung zwischen Saturn und Jupiter über einen Zeitraum von 50 Jahren:

In direkter Analogie zu GeoGraphics haben wir AstroGraphics hinzugefügt, das hier einen Himmelsausschnitt um die aktuelle Position von Saturn zeigt:

Und hier werden nun die aufeinanderfolgenden Positionen von Saturn im Verlauf von einigen Jahren dargestellt—ja, einschließlich der rückläufigen Bewegung:

Für AstroGraphics gibt es viele Gestaltungsoptionen. Hier fügen wir einen Hintergrund des „galaktischen Himmels“ hinzu:

Und hier fügen wir Darstellungen für Sternbilder hinzu (und ja, wir hatten einen Künstler, der sie gezeichnet hat):

Etwas Spezifisches Neues in Version 14.0 betrifft die erweiterte Behandlung von Sonnenfinsternissen. Wir versuchen immer, neue Funktionen so schnell wie möglich bereitzustellen. Aber in diesem Fall gab es eine sehr spezifische Frist: die totale Sonnenfinsternis, die am 8. April 2024, von den USA aus sichtbar sein wird. Wir hatten die Möglichkeit, globale Berechnungen zu Sonnenfinsternissen schon seit einiger Zeit durchzuführen (eigentlich seit kurz vor der Sonnenfinsternis von 2017). Aber jetzt können wir auch detaillierte lokale Berechnungen direkt in der Wolfram-Sprache durchführen.
Hier ist zum Beispiel eine recht detaillierte Übersichtskarte der Sonnenfinsternis vom 8. April 2024:

Hier ist nun ein Diagramm der Größe der Sonnenfinsternis über einige Stunden, komplett mit einem kleinen „Rampart“ während der Totalitätsphase:

Und hier ist eine Karte der Totalitätsregion für jede Minute kurz nach dem Moment der maximalen Finsternis:

Millionen von Arten werden berechenbar
Wir haben erstmals berechenbare Daten über biologische Organismen eingeführt, als Wolfram|Alpha im Jahr 2009 veröffentlicht wurde. Aber in Version 14—nach mehreren Jahren der Arbeit—haben wir die berechenbaren Daten, die wir über biologische Organismen haben, dramatisch erweitert und vertieft.
Hier ist zum Beispiel, wie wir herausfinden können, welche Arten Geparden als Beutetiere haben:

Und hier sind Bilder davon:

Hier ist eine Karte der Länder, in denen Geparden (in freier Wildbahn) gesichtet wurden:

Wir haben jetzt Daten von mehr als einer Million Arten von Tieren—zusammengestellt aus vielen Quellen—sowie die meisten der beschriebenen Pflanzen, Pilze, Bakterien, Viren und Archaeen. Für Tiere haben wir zum Beispiel fast 200 Eigenschaften, die umfassend ausgefüllt sind. Einige davon sind taxonomische Eigenschaften:

Einige sind physikalische Eigenschaften:


Einige sind genetische Eigenschaften:

Einige sind ökologische Eigenschaften (ja, der Gepard ist nicht der Spitzenprädator):

Es ist nützlich, Eigenschaften einzelner Arten zu erhalten, aber die wahre Stärke unserer kuratierten berechenbaren Daten zeigt sich bei umfangreicheren Analysen. Hier ist zum Beispiel ein Diagramm der Längen von Genomen für Organismen mit den längsten Genomen in unserer Sammlung von Organismen:

Oder hier ist ein Histogramm der Genomlängen für Organismen im menschlichen Darmmikrobiom:

Und hier ist ein Streudiagramm der Lebensdauer von Vögeln gegen ihr Gewicht:

Basierend auf der Idee, dass Geparden keine Spitzenprädatoren sind, ist dies ein Diagramm dessen, was in der Nahrungskette über ihnen steht:

Chemische Berechnung
Wir begannen den Prozess der Einführung chemischer Berechnungen in die Wolfram-Sprache in Version 12.0, und bis Version 13 hatten wir eine gute Abdeckung von Atomen, Molekülen, Bindungen und funktionellen Gruppen. Nun haben wir in Version 14 die Abdeckung von chemischen Formeln, Mengen von Chemikalien—und chemischen Reaktionen hinzugefügt.
Hier ist eine chemische Formel, die im Wesentlichen nur eine „Anzahl von Atomen“ angibt:

Hier sind nun spezifische Moleküle mit dieser Formel:

Lassen Sie uns eines dieser Moleküle auswählen:

Jetzt in Version 14 haben wir eine Möglichkeit, eine bestimmte Menge an Molekülen eines bestimmten Typs darzustellen—hier 1 Gramm Methylcyclopentan:

ChemicalConvert kann in eine andere Spezifikation der Menge umgewandelt werden, hier Mol:

Und hier eine Zählung von Molekülen:

Aber die größere Neuerung in Version 14 ist, dass wir jetzt nicht nur einzelne Arten von Molekülen und Mengen von Molekülen, sondern auch chemische Reaktionen darstellen können. Hier geben wir eine „unpräzise“ unausgeglichene Darstellung einer Reaktion an, und ReactionBalance gibt uns die ausgeglichene Version:

Und jetzt können wir die Formeln für die Edukte extrahieren

Wir können auch eine chemische Reaktion in Form von Molekülen angeben:

Aber mit unserer symbolischen Darstellung von Molekülen und Reaktionen können wir jetzt eine große Sache tun: Klassen von Reaktionen als „Musterreaktionen“ darstellen und mit ihnen mit denselben Konzepten arbeiten, die wir beim Arbeiten mit Mustern für allgemeine Ausdrücke verwenden. Zum Beispiel hier ist eine symbolische Darstellung der Hydrohalogenierung:

Jetzt können wir diese Musterreaktion auf bestimmte Moleküle anwenden:

Hier ist ein ausführlicheres Beispiel, in diesem Fall eingegeben mit einem SMARTS-String:

Hier wenden wir die Reaktion nur einmal an:

Und jetzt wenden wir es wiederholt an
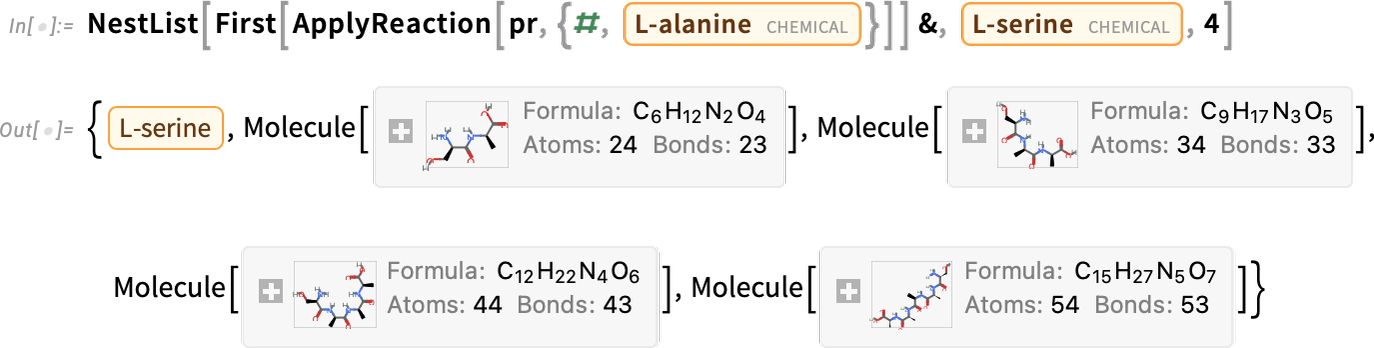
in diesem Fall werden längere und längere Moleküle generiert (die in diesem Fall zufällig Polypeptide sind):

Die Wissensbasis wächst ständig
Jede Minute des Tages werden neue Daten in die Wolfram-Wissensbasis eingefügt. Ein Großteil davon stammt automatisch aus Echtzeitdatenquellen. Aber wir führen auch eine sehr umfangreiche kontinuierliche Kuratierungsarbeit mit menschlicher Beteiligung durch. Im Laufe der Jahre haben wir eine ausgefeilte (Wolfram-Sprache) Automatisierung für unsere Datenkuratierungspipeline entwickelt—und in diesem Jahr konnten wir die Effizienz in einigen Bereichen durch den Einsatz von LLM-Technologie steigern. Aber es ist schwierig, Kuratierung richtig zu machen, und unsere langjährige Erfahrung zeigt, dass dies letztendlich die Einbindung menschlicher Experten erfordert, die wir haben.
Was ist neu seit Version 13.0? 291.842 neue bemerkenswerte aktuelle und historische Persönlichkeiten; 264.467 Musikwerke; 118.538 Musikalben; 104.024 benannte Sterne; und so weiter. Manchmal wird die Hinzufügung einer Entität durch die neue Verfügbarkeit zuverlässiger Daten vorangetrieben; oft wird sie durch die Notwendigkeit vorangetrieben, diese Entität in einer anderen Funktionalität zu verwenden (zum Beispiel Sterne zum Rendern in AstroGraphics). Aber mehr als nur das Hinzufügen von Entitäten gibt es die Frage, wie Werte von Eigenschaften bestehender Entitäten ausgefüllt werden. Und auch hier machen wir immer Fortschritte, manchmal durch die Integration neu verfügbarer groß angelegter sekundärer Datenquellen und manchmal durch direkte Kuratierung aus primären Quellen.
Ein aktuelles Beispiel, bei dem wir direkte Kuratierung durchführen mussten, war bei Daten zu alkoholischen Getränken. Wir haben sehr umfangreiche Daten zu Hunderttausenden von Arten von Lebensmitteln und Getränken. Aber keiner unserer groß angelegten Quellen enthielt Daten zu alkoholischen Getränken. Das ist also ein Bereich, in dem wir zu Primärquellen gehen müssen (in diesem Fall typischerweise die Originalhersteller von Produkten) und alles selbst kuratieren.
Zum Beispiel können wir jetzt nach etwas wie der Verteilung der Geschmacksrichtungen verschiedener Sorten von Wodka fragen (persönlich hatte ich als Nichtverbraucher solcher Dinge keine Ahnung, dass Wodka überhaupt Geschmacksrichtungen hat…):

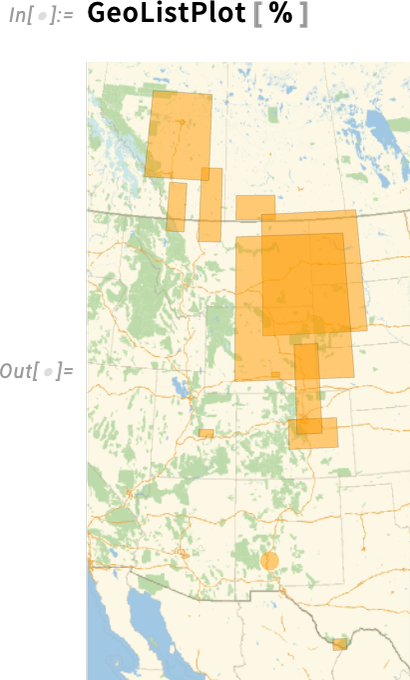
Aber neben dem Ausfüllen von Entitäten und Eigenschaften bestehender Typen haben wir auch kontinuierlich neue Entitätstypen hinzugefügt. Ein kürzliches Beispiel sind geologische Formationen, 13.706 an der Zahl:

Nun können wir beispielsweise angeben, wo T. rex-Fossilien gefunden wurden

und wir können diese Regionen auf einer Karte anzeigen:
Industrietaugliche partielle Differentialgleichungen (PDEs) über mehrere Bereiche
Partielle Differentialgleichungen (PDEs) sind komplex. Es ist schwer, sie zu lösen. Und es ist oft schon schwierig zu spezifizieren, was genau gelöst werden soll. Wir haben jedoch seit Jahrzehnten daran gearbeitet, PDEs für den allgemeinen Gebrauch zugänglicher zu machen. Viele Faktoren spielen dabei eine Rolle. Sie müssen in der Lage sein, komplexe Geometrien einfach zu spezifizieren. Sie müssen mathematisch anspruchsvolle Randbedingungen leicht definieren können. Sie benötigen einen effizienten Weg, um die komplizierten Gleichungen zu formulieren, die aus der zugrunde liegenden Physik resultieren. Dann müssen Sie die anspruchsvolle numerische Analyse so automatisch wie möglich durchführen, um die Gleichungen effizient zu lösen. Aber das ist nicht alles. Oft müssen Sie auch Ihre Lösung visualisieren, andere Berechnungen damit durchführen oder Optimierungen der Parameter durchführen.
Es ist eine tiefe Nutzung dessen, was wir mit der Wolfram-Sprache aufgebaut haben—mit vielen Teilen des Systems verbunden. Und das Ergebnis ist etwas Einzigartiges: eine wirklich vereinfachte und integrierte Methode zur Behandlung von PDEs. Man arbeitet nicht mit einem (meist sehr teuren) „nur für PDEs“-Paket; was wir jetzt haben, ist eine „verbraucherfreundliche“ Methode zur Behandlung von PDEs, wann immer sie benötigt werden—für Ingenieurwesen, Wissenschaft oder andere Anwendungen. Und ja, die Möglichkeit, maschinelles Lernen, Bildverarbeitung, kuratierte Daten, Datenwissenschaft, Echtzeit-Sensorfeeds oder paralleles Computing oder auch einfach Wolfram Notebooks mit PDEs zu verbinden, macht sie umso wertvoller.
Wir haben „grundlegendes, rohes NDSolve“ seit 1991. Aber was Jahrzehnte gedauert hat, ist der Aufbau der gesamten Struktur um dieses Grundgerüst herum, um PDEs aus der realen Welt bequem zu formulieren und effizient zu lösen und sie mit allem anderen zu verknüpfen. Dafür mussten wir einen ganzen Turm von zugrunde liegenden algorithmischen Fähigkeiten entwickeln, wie unsere flexibleren und integrierteren als je zuvor industrietauglichen Berechnungsgeometrie- und Finite-Elemente-Methoden. Doch darüber hinaus war es erforderlich, eine Sprache zur Spezifizierung realer PDEs zu schaffen. Und hier hat die symbolische Natur der Wolfram-Sprache—und unser gesamtes Designframework—etwas sehr Einzigartiges ermöglicht, das es uns ermöglicht hat, die Verwendung von PDEs dramatisch zu vereinfachen und zu verbraucherfreundlich zu gestalten.
Es geht darum, symbolische „Konstruktionskits“ für PDEs und ihre Randbedingungen bereitzustellen. Wir haben vor etwa fünf Jahren damit begonnen und dabei stetig mehr und mehr Anwendungsbereiche abgedeckt. In Version 14 haben wir uns besonders auf Festkörpermechanik, Fluidmechanik, Elektromagnetik (electromagnetics) und (Ein-Teilchen-) Quantenmechanik konzentriert.
Hier ist ein Beispiel aus der Festkörpermechanik. Zuerst definieren wir die Variablen, mit denen wir arbeiten (Verschiebung und zugrunde liegende Koordinaten):
Als Nächstes geben wir die Parameter an, die wir verwenden möchten, um das feste Material zu beschreiben, mit dem wir arbeiten werden:
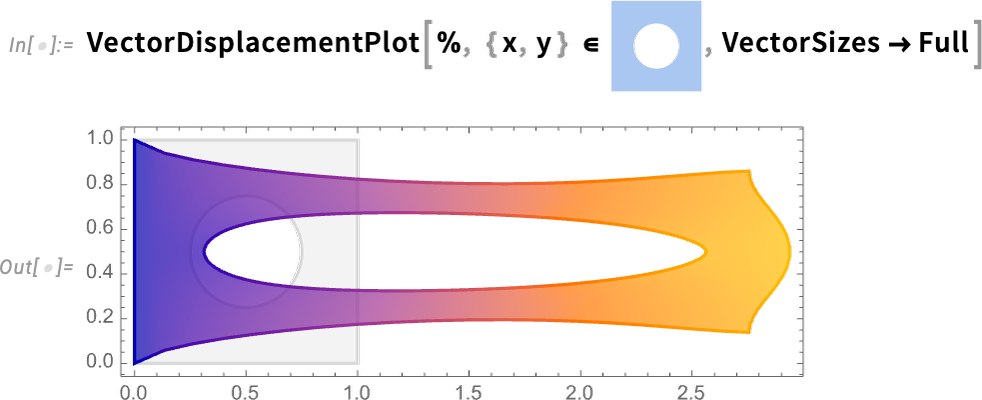
Nun können wir tatsächlich unsere PDE einrichten—unter Verwendung symbolischer PDE-Spezifikationen wie SolidMechanicsPDEComponent—hier für die Deformation eines festen Objekts, das an einer Seite gezogen wird:

Und ja, „unter der Oberfläche“ werden diese einfachen symbolischen Spezifikationen zu einer komplizierten „rohen“ PDE umgewandelt:
Nun sind wir bereit, unsere PDE tatsächlich in einem bestimmten Bereich zu lösen, d.h. für ein Objekt mit einer bestimmten form:

Und jetzt können wir das Ergebnis visualisieren, das zeigt, wie sich unser Objekt dehnt, wenn daran gezogen wird:
Die Art und Weise, wie wir die Dinge eingerichtet haben, stellt das Material für unser Objekt als eine Idealisierung von etwas Ähnlichem wie Gummi dar. Aber in der Wolfram-Sprache haben wir jetzt Möglichkeiten, alle Arten von detaillierten Materialeigenschaften anzugeben. Zum Beispiel können wir unserem Material Verstärkung als Einheitsvektor in eine bestimmte Richtung hinzufügen (sagen wir in der Praxis mit Fasern):
Dann können wir das, was wir zuvor gemacht haben, erneut ausführen
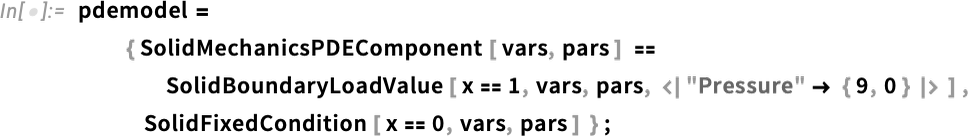
aber jetzt erhalten wir ein leicht unterschiedliches Ergebnis:
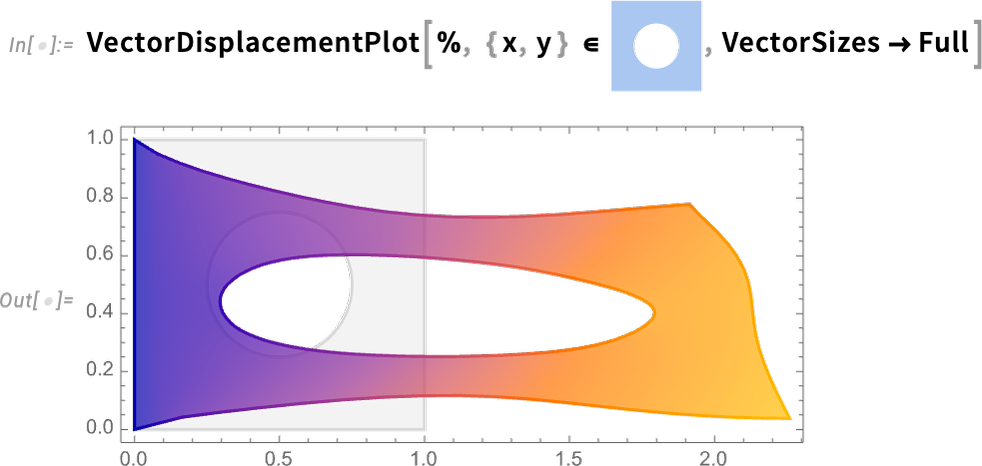
Ein weiterer wichtiger PDE-Bereich, der neu in Version 14.0 ist, ist der Strömungsfluss. Lassen Sie uns ein 2D-Beispiel machen. Unsere Variablen sind 2D-Geschwindigkeit und Druck
![]()
Nun können wir unser Fluidsystem in einem bestimmten Bereich einrichten, mit „No-Slip“-Bedingungen an allen Wänden außer oben, wo wir annehmen, dass das Fluid von links nach rechts fließt. Der einzige benötigte Parameter ist die Reynolds-Zahl. Statt unsere PDEs nur für eine einzige Reynolds-Zahl zu lösen, erstellen wir einen parametrischen Solver, der jede angegebene Reynolds-Zahl verwenden kann:

Hier ist das Ergebnis für eine Reynolds-Zahl von 100:
Aber mit der Art und Weise, wie wir die Dinge eingerichtet haben, können wir auch ein komplettes Video in Abhängigkeit von der Reynolds-Zahl erstellen (und ja, die Verwendung von Parallelize beschleunigt den Prozess, indem verschiedene Frames parallel generiert werden):

Ein großer Teil unserer Arbeit mit PDEs besteht darin, auf die Komplexitäten realer ingenieurtechnischer Situationen einzugehen. In Version 14.0 fügen wir jedoch auch Funktionen hinzu, um „reine Physik“ zu unterstützen, insbesondere die Unterstützung der Quantenmechanik mit der Schrödinger-Gleichung. Hier ist zum Beispiel die 2D-Ein-Teilchen-Schrödinger-Gleichung (mit ![]() ):
):

Hier ist die Region, über die wir lösen werden—mit einer expliziten Diskretisierung dargestellt:
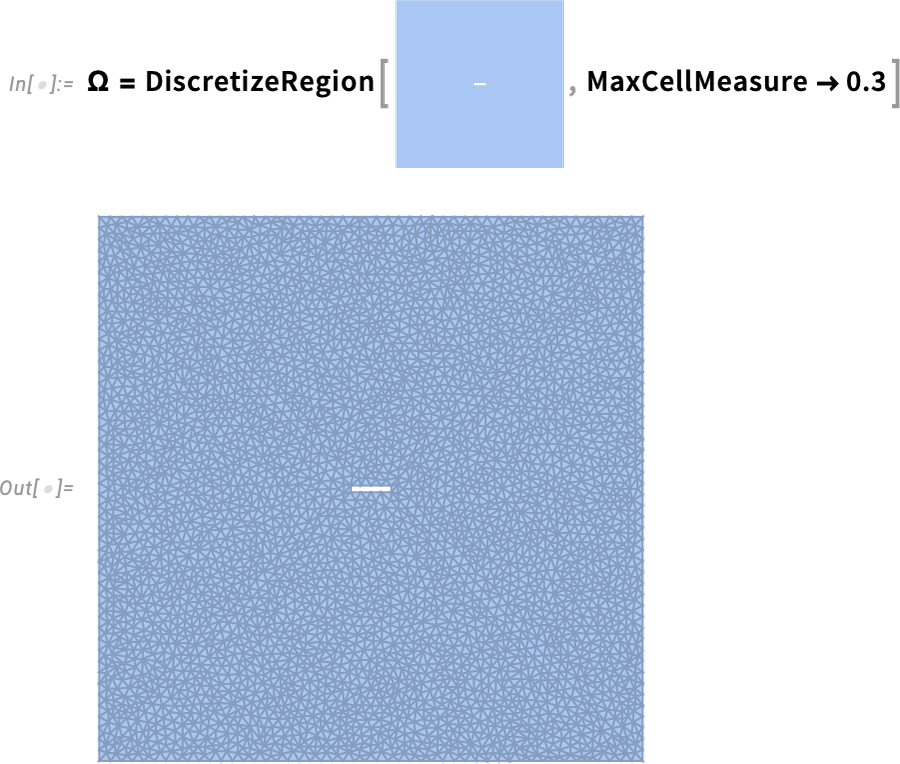
Nun können wir die Gleichung lösen und einige Randbedingungen hinzufügen:
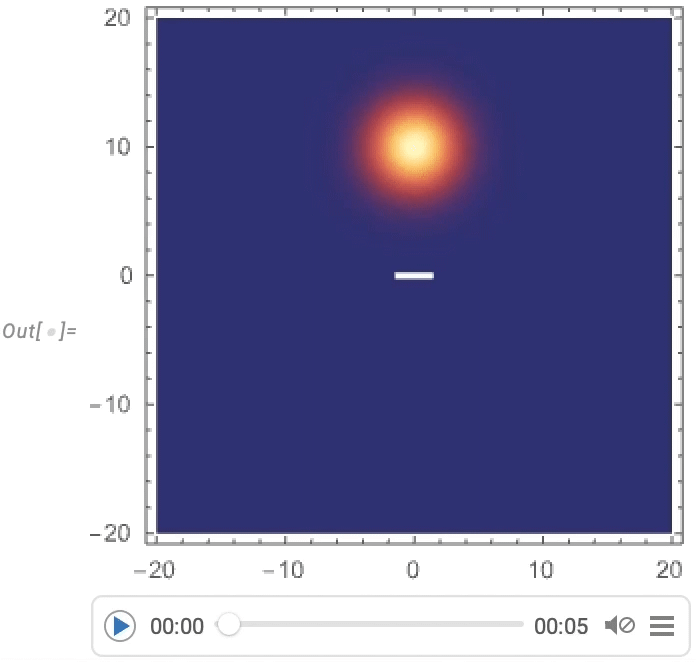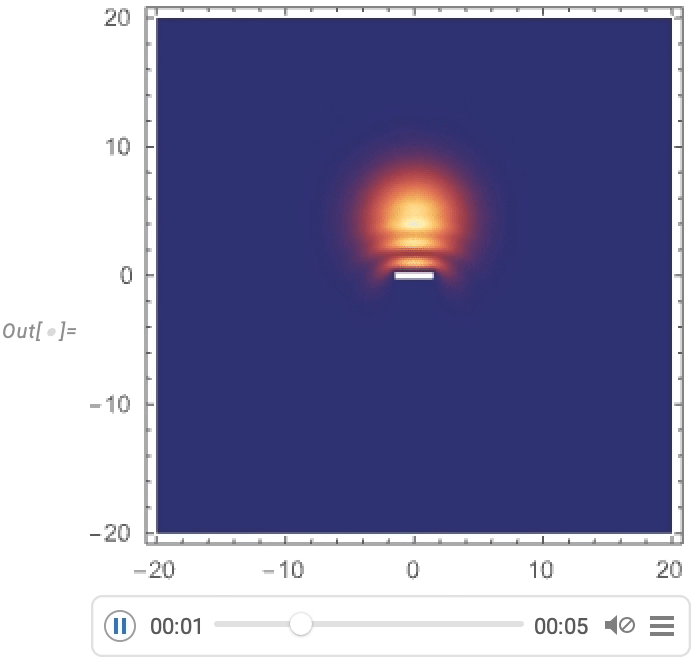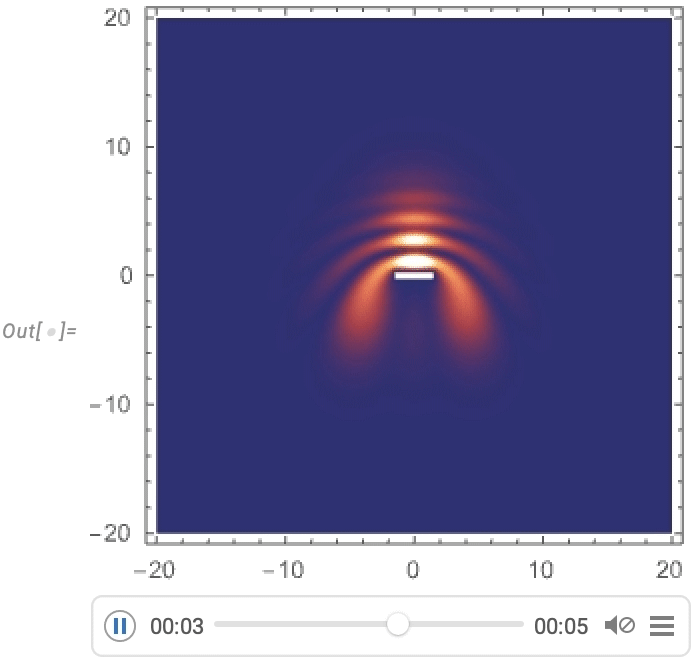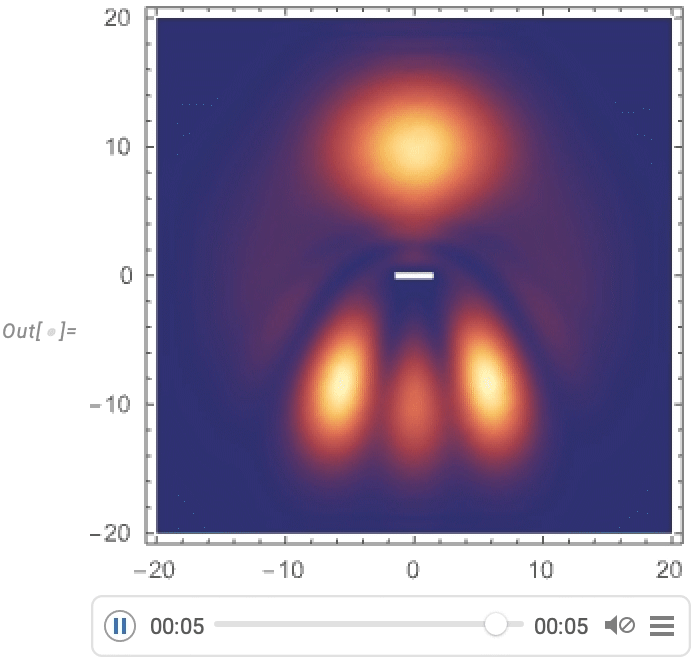
Und jetzt können wir die Streuung eines gaußförmigen Wellenpakets um eine Barriere visualisieren:
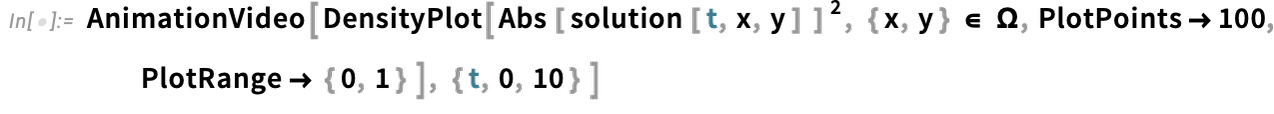
Systemtechnik-Berechnungen optimieren
Die Systemtechnik ist ein breites Feld, aber hier bieten die Struktur und die Fähigkeiten der Wolfram-Sprache einzigartige Vorteile, die es uns im Laufe des letzten Jahrzehnts ermöglicht haben, eine ziemlich umfassende Unterstützung für Modellierung, Analyse und Regelungsentwurf für eine Vielzahl von Systemtypen aufzubauen. Es ist alles ein integrierter Bestandteil der Wolfram-Sprache, zugänglich über die Berechnungs- und Schnittstellenstruktur der Sprache. Aber es ist auch mit unserem separaten Produkt Wolfram System Modeler integriert, das einen GUI-basierten Workflow für Systemmodellierung und Exploration bietet.
Gemeinsam mit dem System Modeler werden große Sammlungen von domänenspezifischen Modellierungsbibliotheken verwendet. So haben wir zum Beispiel seit Version 13 Bibliotheken in Bereichen wie Batterietechnik, Hydrauliktechnik und Flugzeugtechnik hinzugefügt, sowie Bildungsbibliotheken für Maschinenbau, Thermodynamik, Digitalelektronik und Biologie. (Wir haben auch Bibliotheken für Bereiche wie Geschäfts- und Politiksimulation hinzugefügt.)

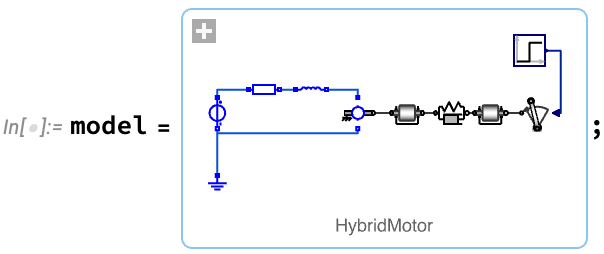
Ein typischer Workflow für Systemtechnik beginnt mit der Erstellung eines Modells. Das Modell kann von Grund auf aufgebaut oder aus Komponenten in Modellbibliotheken zusammengebaut werden—entweder visuell in Wolfram System Modeler oder programmatisch in der Wolfram-Sprache. Hier ist zum Beispiel ein Modell eines Elektromotors, der über eine flexible Welle eine Last antreibt:
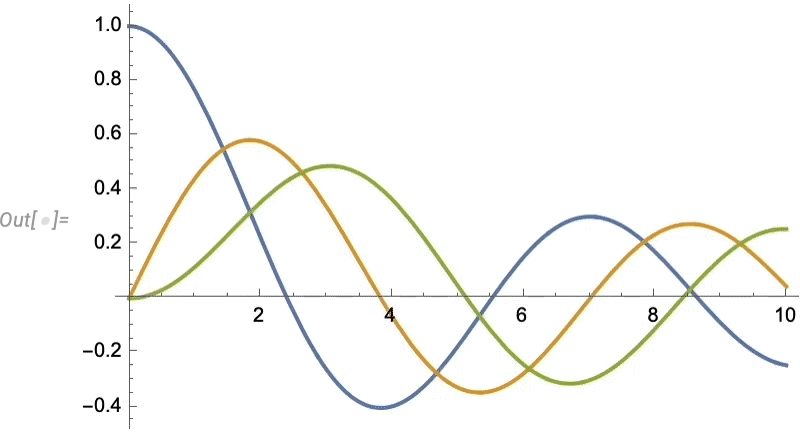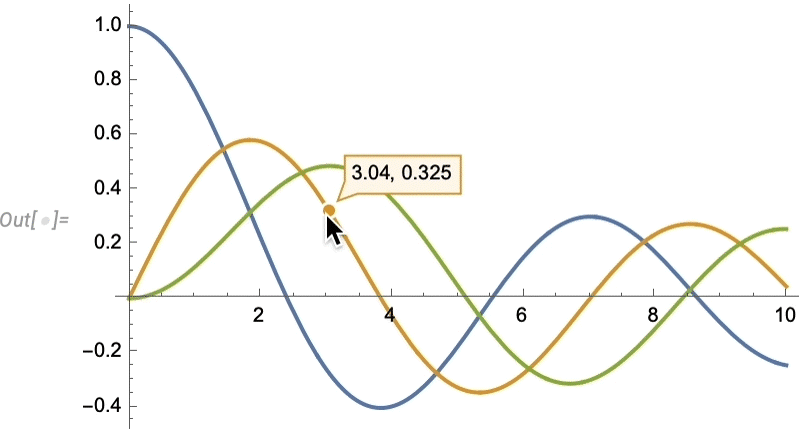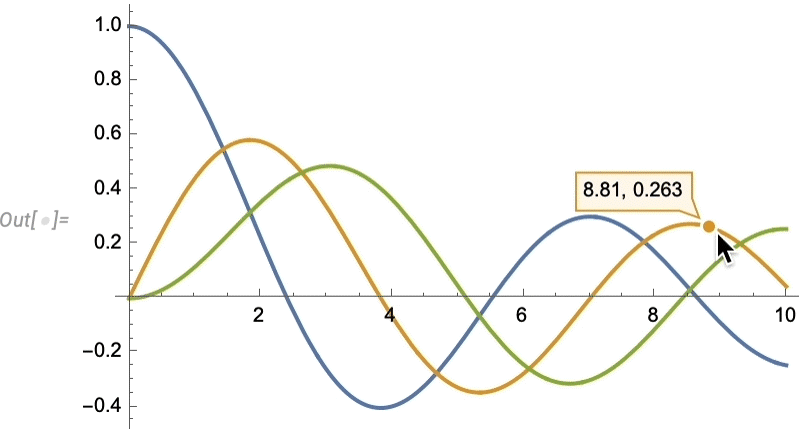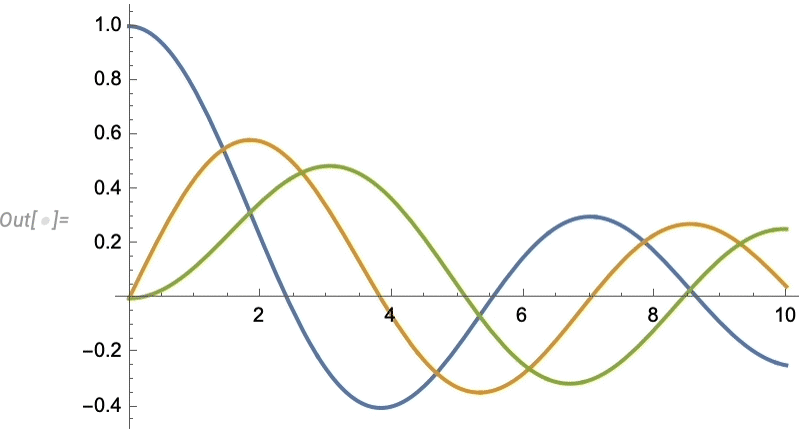
Sobald man ein Modell hat, kann man es simulieren. Hier ist ein Beispiel, bei dem wir einen Parameter unseres Modells (das Trägheitsmoment der Last) festgelegt haben und die Werte von zwei anderen als Funktion der Zeit berechnen:
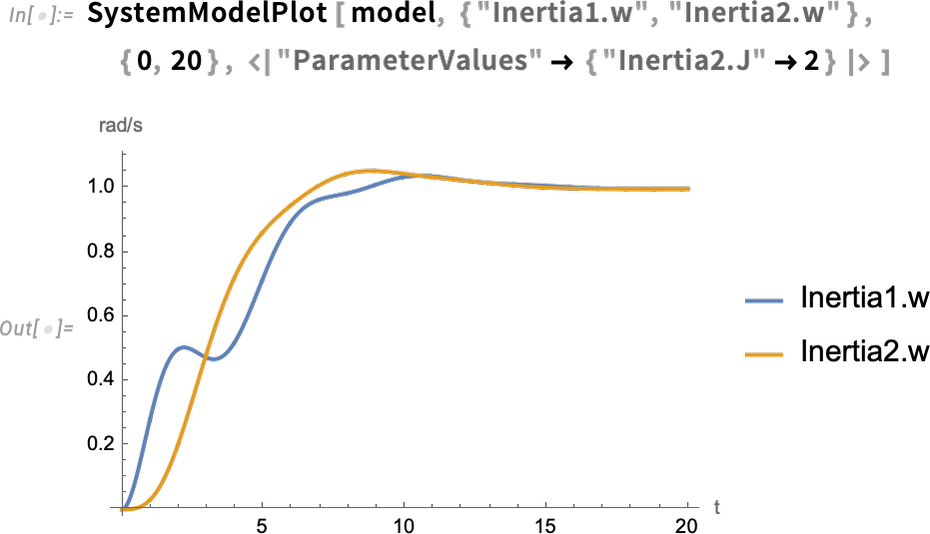
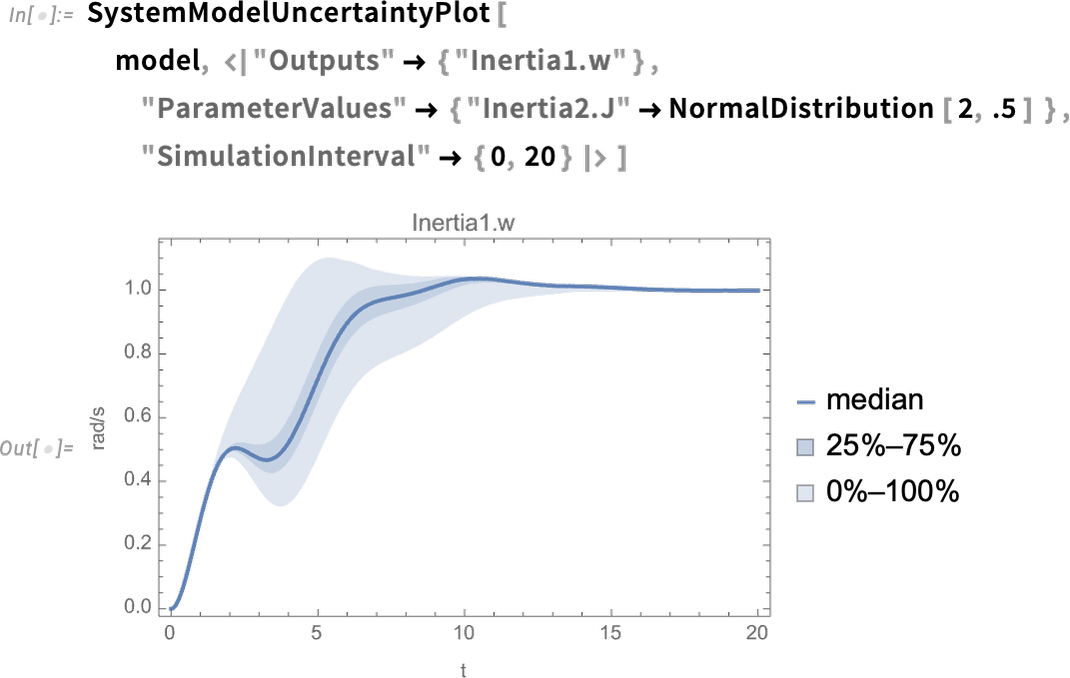
Eine neue Funktion in Version 14.0 besteht darin, die Auswirkungen von Unsicherheiten in Parametern (oder Anfangswerten usw.) auf das Verhalten eines Systems sehen zu können. Hier nehmen wir zum Beispiel an, dass der Wert des Parameters nicht fest definiert ist, sondern gemäß einer Normalverteilung verteilt ist. Dann betrachten wir die Verteilung der Ausgabewerte:
Der Motor mit flexiblem Wellenschaft, den wir betrachten, kann als „multidomänen System“ betrachtet werden, das elektrische und mechanische Komponenten kombiniert. Aber die Wolfram-Sprache (und Wolfram System Modeler) kann auch „gemischte Systeme“ verarbeiten, die analoge und digitale (d. h. kontinuierliche und diskrete) Komponenten kombinieren. Hier ist ein recht anspruchsvolles Beispiel aus der Welt der Regelungstechnik: Ein Hubschraubermodell, das in einem geschlossenen Regelkreis mit einem digitalen Steuersystem verbunden ist:

Dieses gesamte Modellsystem kann symbolisch wie folgt dargestellt werden:
![]()
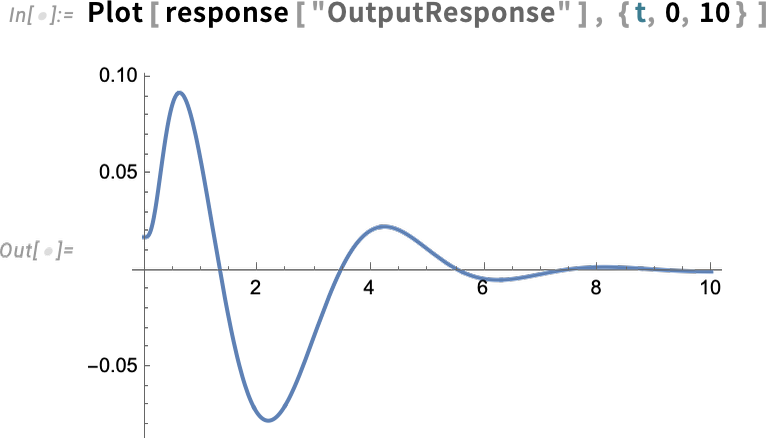
Und jetzt berechnen wir die Ein-/Ausgangsantwort des Modells:

Hier ist speziell die Ausgangsantwort:
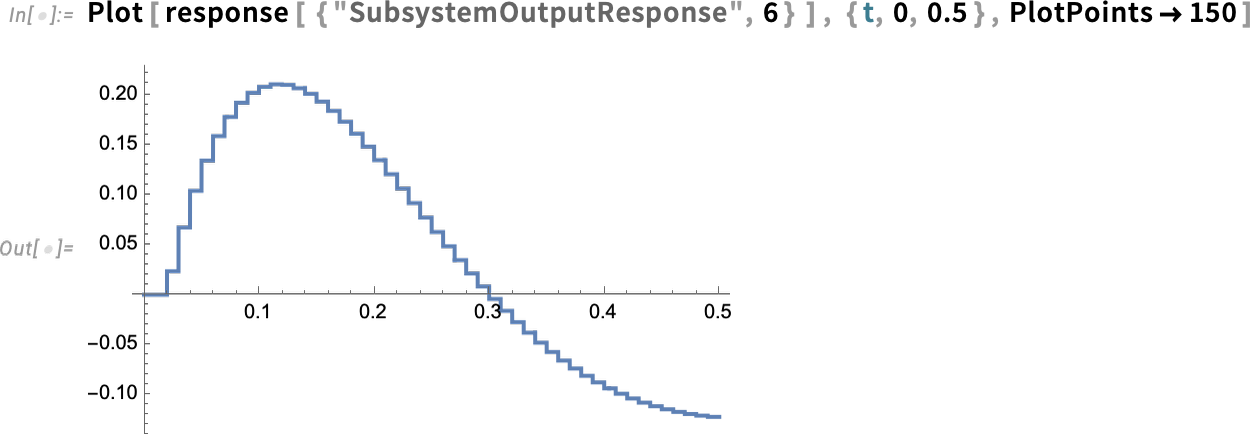
Aber jetzt können wir „hineinzoomen“ und spezifische Teilsystemantworten betrachten, hier die des Zero-Order-Hold-Geräts (bezeichnet als ZOH oben) – vollständig mit seinen kleinen digitalen Schritten:
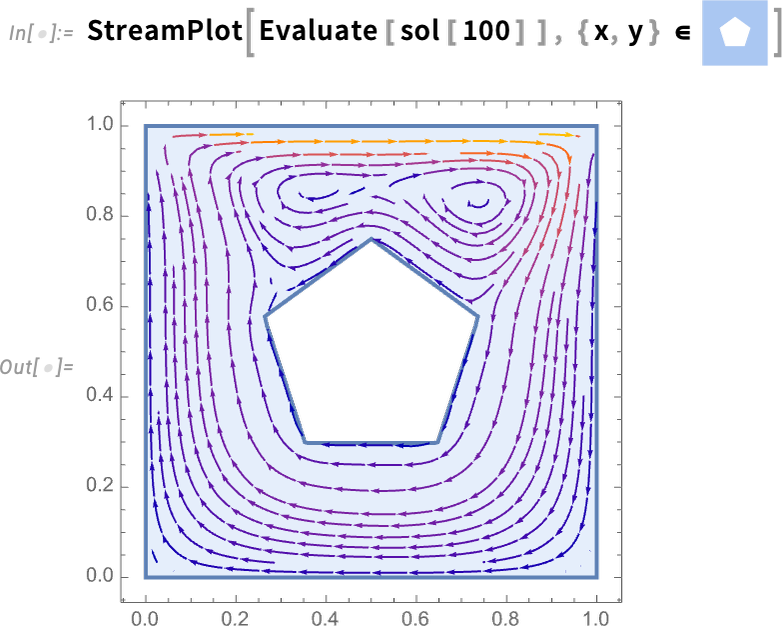
Aber was ist, wenn wir die Regelungssysteme selbst entwerfen möchten? Nun, in Version 14 können wir jetzt alle Funktionalitäten des Wolfram Language Control Systems Designs auf beliebige Systemmodelle anwenden. Hier ist ein Beispiel für ein einfaches Modell, in diesem Fall aus dem Bereich der Chemietechnik (ein kontinuierlich gerührter Tank):

Nun können wir dieses Modell nehmen und einen LQG-Regler dafür entwerfen – anschließend ein vollständiges geschlossenes Regelkreissystem dafür zusammenstellen:
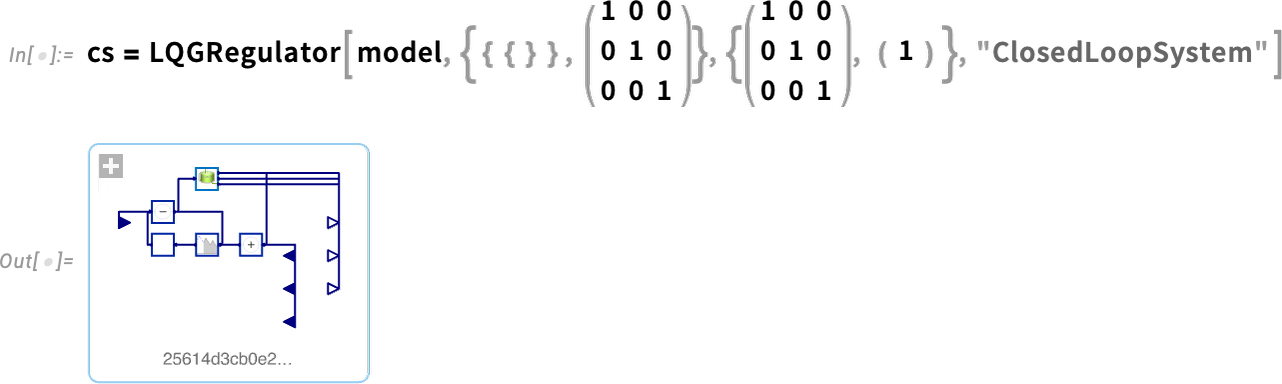
Nun können wir das geschlossene Regelkreissystem simulieren – und sehen, dass der Regler erfolgreich den Endwert auf 0 bringt:
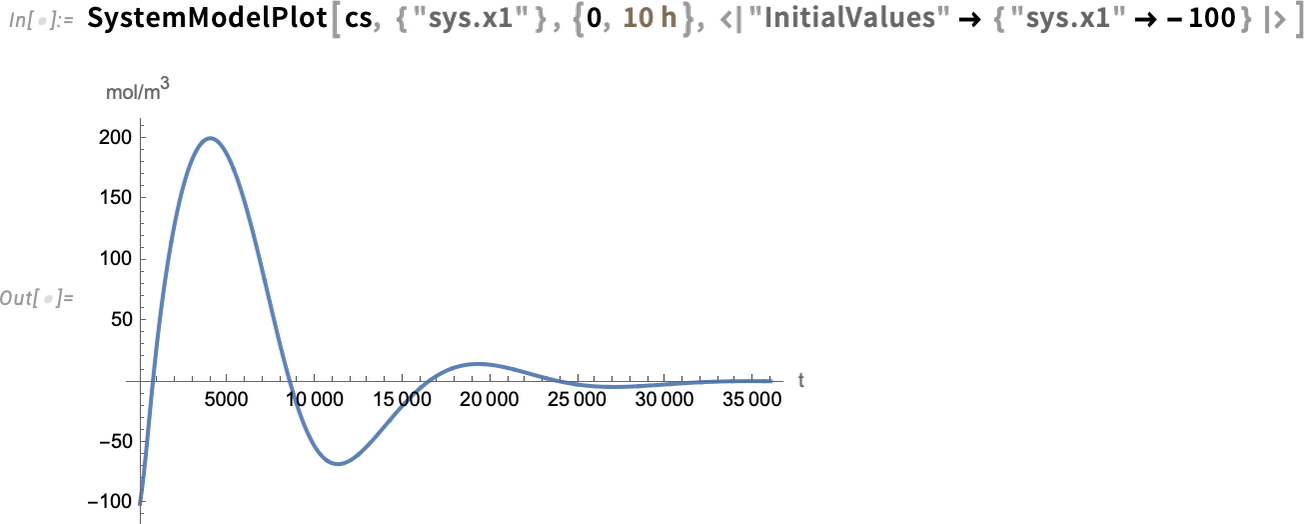
Grafiken: Schöner und Lebendiger
Grafiken waren schon immer ein wichtiger Bestandteil der Geschichte der Wolfram Language, und seit mehr als drei Jahrzehnten verbessern und aktualisieren wir kontinuierlich ihr Erscheinungsbild und ihre Funktionalität – manchmal mit Hilfe von Fortschritten in den Hardwarefähigkeiten (z. B. GPU).
Seit Version 13 haben wir eine Vielzahl von „dekorativen“ (oder „annotativen“) Effekten in 2D-Grafiken hinzugefügt. Ein Beispiel (nützlich zum Hinzufügen von Untertiteln zu Objekten) ist das „Haloing“:

Ein weiteres Beispiel ist das DropShadowing:

All diese Effekte werden symbolisch spezifiziert und können im gesamten System verwendet werden (zum Beispiel in Hover-Effekten usw.). Und ja, es gibt viele detaillierte Parameter, die Sie einstellen können:
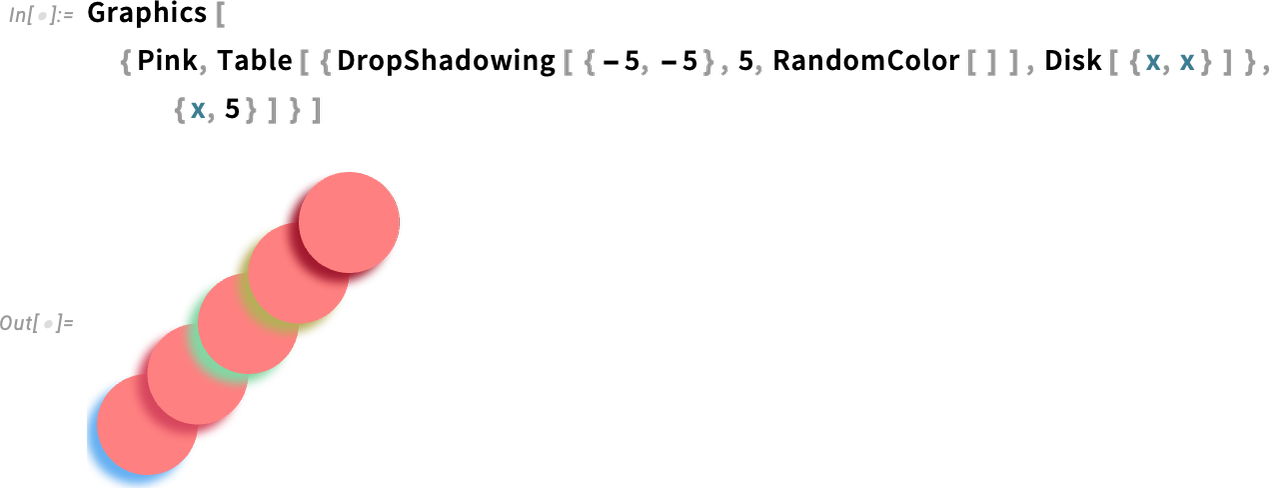
Eine bedeutende neue Funktion in Version 14.0 ist die komfortable Texturzuordnung. Wir hatten seit anderthalb Jahrzehnten Texturzuordnungen auf Polygon-Ebene. Aber jetzt in Version 14.0 haben wir es einfach gemacht, Texturen auf ganze Oberflächen zu übertragen. Hier ist ein Beispiel, wie eine Textur auf eine Kugel gewickelt wird:

Und hier wird dieselbe Textur auf eine komplexere Oberfläche gewickelt:

Eine bedeutende Feinheit besteht darin, dass es viele Möglichkeiten gibt, „Texturkoordinaten-Patches“ auf Oberflächen abzubilden. Die Dokumentation zeigt neue, benannte Fälle:

Und hier ist, was bei stereographischer Projektion auf eine Kugel passiert:

Hier ist ein Beispiel für die „Oberflächentextur“ des Planeten Venus:

und hier wurde sie auf eine Kugel abgebildet, die gedreht werden kann:


Hier ist ein „blumenverziertes“ Häschen:

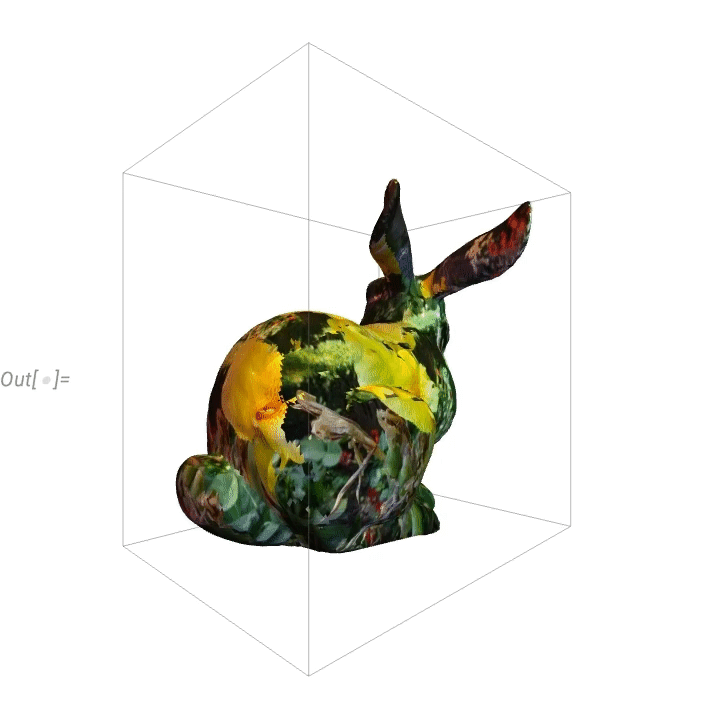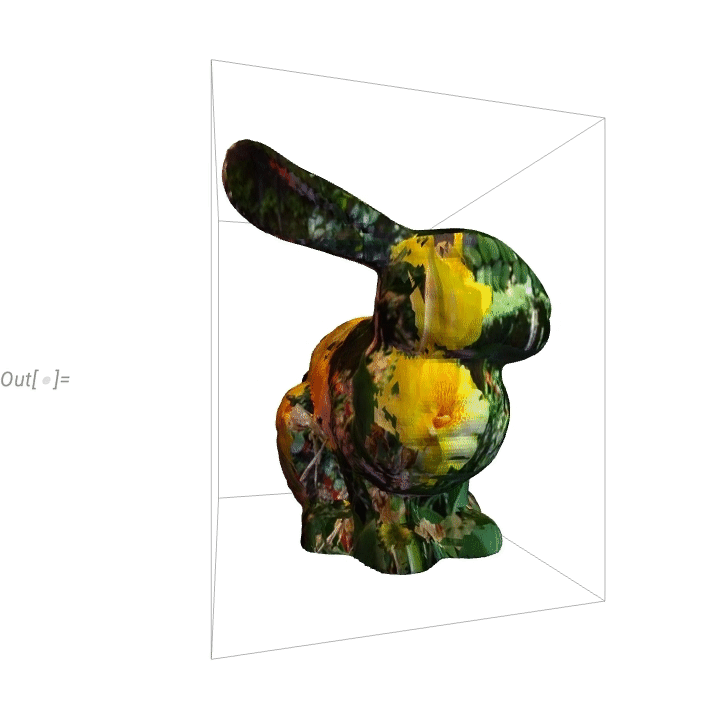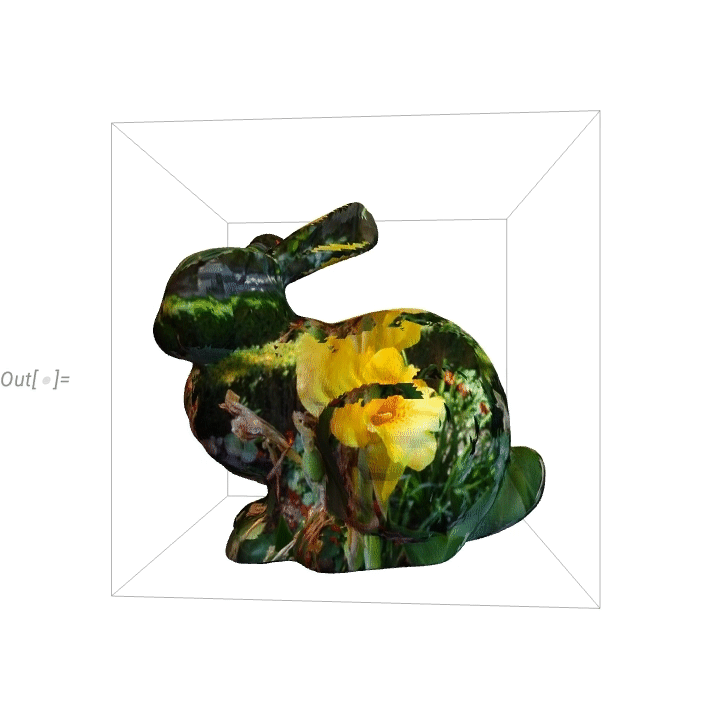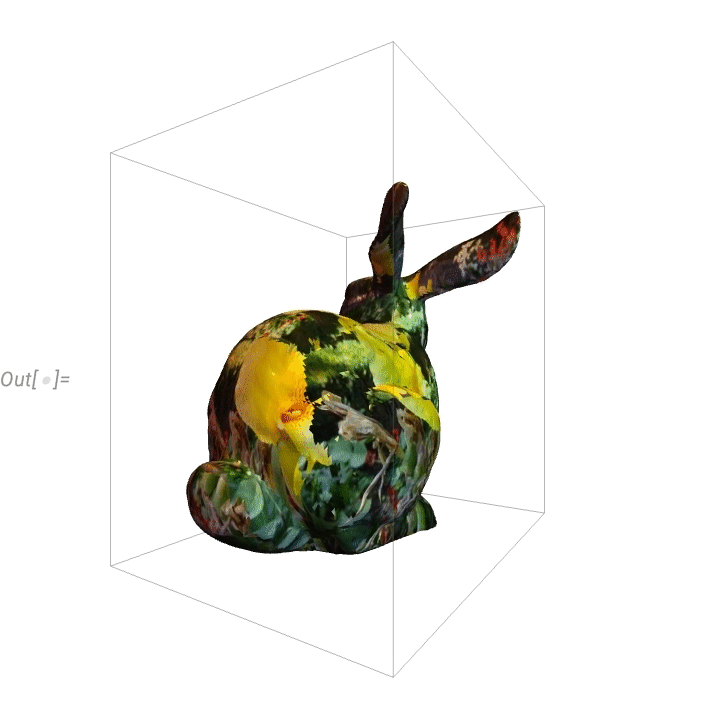
Funktionen wie Texturzuordnung tragen dazu bei, Grafiken visuell ansprechend zu gestalten. Seit Version 13 haben wir auch verschiedene Funktionen für „Live-Visualisierungen“ hinzugefügt, die automatisch „Visualisierungen lebendig machen“. Zum Beispiel hat jeder Plot standardmäßig jetzt eine „Koordinaten-Mouseover“-Funktion:
![]()
Wie üblich gibt es viele Möglichkeiten, solche „Hervorhebungseffekte“ zu steuern:


Euclid Redux: Der Fortschritt der synthetischen Geometrie
Man könnte sagen, dass es zwei Jahrtausende gedauert hat. Aber vor vier Jahren (Version 12) begannen wir, eine berechenbare Version der synthetischen Geometrie im Stil von Euklid einzuführen.
Die Idee besteht darin, geometrische Szenen symbolisch anzugeben, indem eine Sammlung von (potenziell impliziten) Einschränkungen angegeben wird:

Wir können dann eine zufällige Instanz der Geometrie generieren, die mit den Einschränkungen übereinstimmt – und in Version 14 haben wir unsere Fähigkeit erheblich verbessert, sicherzustellen, dass die Geometrie „typisch“ und nicht degeneriert ist:

Aber eine neue Funktion von Version 14 ist, dass wir Werte geometrischer Größen finden können, die durch die Einschränkungen bestimmt sind:

Hier ist ein etwas komplizierterer fall:

Und hier lösen wir jetzt die Flächen von zwei Dreiecken in der Abbildung:

Wir konnten schon immer explizite Stile für bestimmte Elemente einer Szene angeben:
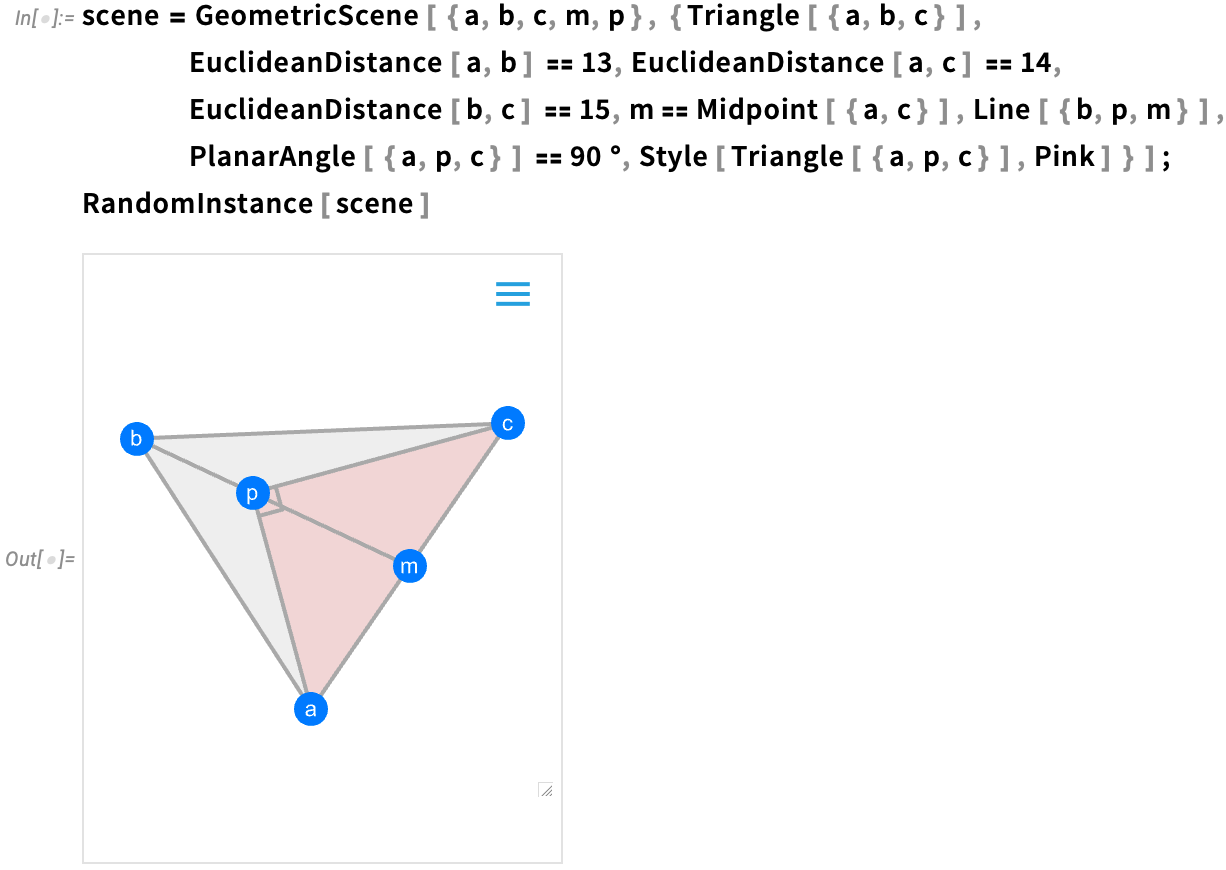
Eine der neuen Funktionen in Version 14 ist die Möglichkeit, allgemeine „geometrische Stilregeln“ anzugeben, hier einfach durch Zuweisen zufälliger Farben zu jedem Element:

Die stets verbesserte Benutzeroberfläche
Unser Ziel mit der Wolfram Language ist es, es so einfach wie möglich zu machen, sich rechnerisch auszudrücken. Ein großer Teil davon ist das zusammenhängende Design der Sprache selbst. Aber es gibt auch einen anderen Teil, nämlich die Möglichkeit, Wolfram Language-Eingaben, die man möchte – zum Beispiel in einem Notebook – so einfach wie möglich einzugeben. Mit jeder neuen Version verbessern wir das.
Ein Bereich, der kontinuierlich weiterentwickelt wird, ist die interaktive Syntaxhervorhebung. Wir haben vor fast zwei Jahrzehnten erstmals Syntaxhervorhebung hinzugefügt – im Laufe der Zeit haben wir sie immer ausgefeilter gemacht, indem wir sowohl während der Eingabe als auch während der Ausführung des Codes reagieren. Einige Hervorhebungen hatten immer offensichtliche Bedeutung. Aber insbesondere Hervorhebungen, die dynamisch und abhängig von der Cursorposition sind, waren manchmal schwerer zu interpretieren. In Version 14 – unter Verwendung der helleren Farbpaletten, die in den letzten Jahren zum Standard geworden sind – haben wir unsere dynamische Hervorhebung optimiert, damit es einfacher ist, schnell „zu erkennen, wo man sich innerhalb der Struktur eines Ausdrucks befindet“:

Zum Thema „Wissen, was man hat“, wurde in Version 13.2 eine weitere Verbesserung eingeführt: differenzierte Rahmenfarben für verschiedene Arten von visuellen Objekten in Notebooks. Ist das Ding eine Grafik? Oder ein Bild? Oder ein Diagramm? Jetzt kann man anhand der Rahmenfarbe erkennen, wenn man es auswählt:

Ein wichtiger Aspekt der Wolfram Language ist, dass die Namen der integrierten Funktionen ausreichend erklärend sind, sodass leicht zu erkennen ist, was sie tun. Oft sind die Namen daher notwendigerweise recht lang, daher ist es wichtig, sie beim Tippen automatisch vervollständigen zu können. In Version 13.3 haben wir die Idee der „unscharfen Autocompletion“ hinzugefügt, die nicht nur den Namen vervollständigt, den man eingibt, sondern auch Zwischenbuchstaben ergänzen, die Groß- und Kleinschreibung ändern usw. So ruft zum Beispiel das einfache Tippen von „lll“ ein Autocompletion-Menü auf, das mit „ListLogLogPlot“ beginnt:

Ein wichtiges Benutzeroberflächen-Update, das erstmals in Version 13.1 erschien und in nachfolgenden Versionen weiterentwickelt wurde, ist eine Standard-Symbolleiste für jedes Notebook:
![]()
Die Symbolleiste bietet sofortigen Zugriff auf Evaluierungssteuerungen, Zellenformatierung und verschiedene Arten von Eingaben (wie Inline-Zellen, ![]() , Hyperlinks, Zeichenfläche usw.) – sowie auf Funktionen wie
, Hyperlinks, Zeichenfläche usw.) – sowie auf Funktionen wie ![]() Cloud-Veröffentlichung,
Cloud-Veröffentlichung,![]() Dokumentationssuche und
Dokumentationssuche und ![]() „Chat“ (d. h. LLM) Einstellungen.
„Chat“ (d. h. LLM) Einstellungen.
Oft ist es nützlich, die Symbolleiste in jedem Notebook angezeigt zu haben, mit dem Sie arbeiten. Aber auf der linken Seite gibt es ein kleines ![]() , mit dem Sie die Symbolleiste minimieren können:
, mit dem Sie die Symbolleiste minimieren können:

In Version 14.0 gibt es eine Einstellung in den „Einstellungen“, die die Symbolleiste standardmäßig minimiert, wenn Sie ein neues Notebook erstellen. Auf diese Weise haben Sie sofortigen Zugriff auf die Symbolleiste, aber Ihre Notebooks enthalten nichts „Zusätzliches“, das vom Inhalt ablenken könnte.
Eine weitere Weiterentwicklung seit Version 13 betrifft die Handhabung von „Zusammenfassungsformen“ von Ausgaben in Notebooks. Ein grundlegendes Beispiel ist das Verhalten, wenn Sie ein sehr großes Ergebnis generieren. Standardmäßig wird nur eine Zusammenfassung des Ergebnisses angezeigt. Es gibt jedoch eine Leiste am unteren Rand, die verschiedene Optionen bietet, wie die tatsächliche Ausgabe behandelt werden soll:

Standardmäßig wird die Ausgabe nur in Ihrer aktuellen Kernel-Sitzung gespeichert. Durch Drücken der Schaltfläche „Iconize“ erhalten Sie eine ikonisierte Form, die direkt in Ihrem Notebook angezeigt wird (oder die überallhin kopiert werden kann) und „die gesamte Ausgabe enthält“. Es gibt auch eine Schaltfläche „Vollständigen Ausdruck im Notebook speichern“, die den Ausdruck „unsichtbar“ hinter der Zusammenfassungsanzeige im Notebook speichert.
Wenn der Ausdruck im Notebook gespeichert ist, bleibt er über Kernel-Sitzungen hinweg erhalten. Andernfalls können Sie nicht auf ihn in einer anderen Kernel-Sitzung zugreifen; das Einzige, was Sie haben, ist die Zusammenfassungsanzeige.

Ähnlich ist es bei großen „Berechnungsobjekten“. Zum Beispiel hier ist eine Nearest-Funktion mit einer Million Datenpunkten:
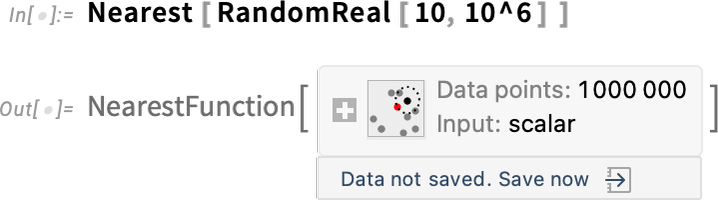
Standardmäßig existieren die Daten nur in Ihrer aktuellen Kernel-Sitzung. Aber jetzt gibt es ein Menü, das es Ihnen ermöglicht, die Daten an verschiedenen dauerhaften Speicherorten zu speichern:

Und es gibt auch die Cloud
Es gibt viele Möglichkeiten, die Wolfram Language auszuführen. Schon in Version 1.0 hatten wir die Idee von Remote-Kernels: Die Notebook-Oberfläche läuft auf einer Maschine (damals meistens ein Mac oder ein NeXT), und der Kernel läuft auf einer anderen Maschine (manchmal sogar über Telefonleitungen verbunden). Vor einem Jahrzehnt gab es jedoch einen großen Fortschritt: die Wolfram Cloud.
Die Wolfram Cloud wird wirklich auf zwei verschiedene Arten verwendet. Erstens bietet sie eine Notebook-Erfahrung ähnlich unserer langjährigen Desktop-Erfahrung, läuft jedoch vollständig im Browser. Zweitens dient sie der Bereitstellung von APIs und anderen programmatisch zugänglichen Funktionen – insbesondere, schon vor einem Jahrzehnt, durch Dinge wie APIFunction.
Die Wolfram Cloud wurde in den letzten fast 15 Jahren intensiv weiterentwickelt. Daneben kamen auch der Wolfram Application Server und der Wolfram Web Engine, die speziell für APIs optimierte Unterstützung bieten (ohne Dinge wie Benutzerverwaltung usw., aber mit Funktionen wie Clustering).
Alle diese Technologien – insbesondere die Wolfram Cloud – sind zu Kernfähigkeiten für uns geworden, die viele unserer anderen Aktivitäten unterstützen. Zum Beispiel basieren das Wolfram Function Repository und das Wolfram Paclet Repository beide auf der Wolfram Cloud (und tatsächlich gilt dies für unser gesamtes Ressourcensystem). Und als wir früher in diesem Jahr das Wolfram-Plugin für ChatGPT entwickelten, konnten wir das Plugin innerhalb weniger Tage bereitstellen, indem wir die Wolfram Cloud verwendet haben.
Seit Version 13 gab es viele verschiedene Anwendungen der Wolfram Cloud. Eine davon ist die Funktion ARPublish, die 3D-Geometrie in die Wolfram Cloud mit den entsprechenden Metadaten bringt, um es mobilen Geräten zu ermöglichen, AR-Versionen über einen QR-Code einer Cloud-URL zu erhalten:


Auf der Cloud-Notebook-Seite gab es eine stetige Zunahme der Nutzung, insbesondere von eingebetteten Cloud-Notebooks, die zum Beispiel auf der Wolfram Community häufig vorkommen und im gesamten Wolfram Demonstrations Project verwendet werden. Unser Ziel war es von Anfang an, Cloud-Notebooks so benutzerfreundlich zu gestalten wie einfache Webseiten, aber mit der Tiefe der Funktionen, die wir in Notebooks in den letzten 35 Jahren entwickelt haben. Vor einigen Jahren haben wir dies für recht kleine Notebooks erreicht, aber in den letzten Jahren haben wir fortschreitend noch größere Notebooks bis hin zu mehreren Hundert Megabyte verarbeitet. Es ist eine komplizierte Geschichte aus Caching, Aktualisierung – und dem Ausweichen der Launen von Webbrowsern. Aber zu diesem Zeitpunkt können die allermeisten Notebooks nahtlos in die Cloud bereitgestellt werden und werden sofort wie einfache Webseiten angezeigt.
Die großartige Integration von externem code
Es war schon seit Version 1.0 möglich, externen Code aus der Wolfram Language aufzurufen. Aber in Version 14 gibt es wichtige Fortschritte hinsichtlich des Umfangs und der Benutzerfreundlichkeit der Integration externen Codes. Das übergeordnete Ziel ist es, die gesamte Leistungsfähigkeit und Kohärenz der Wolfram Language zu nutzen, selbst wenn ein Teil einer Berechnung in externem Code durchgeführt wird. In Version 14 haben wir viel unternommen, um den Prozess der Integration externen Codes in die Sprache zu vereinfachen und zu automatisieren.
Sobald etwas in die Wolfram Language integriert ist, wird es beispielsweise zu einer Funktion, die genauso verwendet werden kann wie jede andere Wolfram Language-Funktion. Aber was darunter liegt, ist zwangsläufig für verschiedene Arten von externem Code sehr unterschiedlich. Es gibt eine Konfiguration für interpretierte Sprachen wie Python. Es gibt eine andere für C-ähnliche kompilierte Sprachen und dynamische Bibliotheken. (Und dann gibt es andere für externe Prozesse, APIs und was im Wesentlichen „importierbare Codespezifikationen“ sind, z. B. für neuronale Netzwerke.)
Beginnen wir mit Python. Wir haben seit 2018 ExternalEvaluate, um Python-Code auszuführen. Aber wenn Sie tatsächlich Python verwenden möchten, gibt es all diese Abhängigkeiten und Bibliotheken zu berücksichtigen. Und ja, das ist einer der Bereiche, in denen die unglaublichen Vorteile der Wolfram Language und ihr kohärentes Design schmerzhaft deutlich werden. Aber in Version 14.0 haben wir nun eine Möglichkeit, die gesamte Komplexität von Python zu kapseln, sodass wir Python-Funktionalität innerhalb der Wolfram Language bereitstellen können, wobei wir alle Unordnung von Python-Abhängigkeiten und sogar die Versionierung von Python selbst verbergen.
Als Beispiel nehmen wir an, wir möchten eine Wolfram Language-Funktion Emojize erstellen, die die Python-Funktion Emojize aus der Bibliothek emoji verwendet. Hier ist, wie wir das machen können:

Und jetzt können Sie einfach Emojize in der Wolfram Language aufrufen, und unter der Oberfläche wird Python-Code ausgeführt:

Die Funktionsweise besteht darin, dass beim ersten Aufruf von Emojize eine Python-Umgebung mit allen erforderlichen Funktionen erstellt und dann für spätere Verwendungen zwischengespeichert wird. Und was wichtig ist, ist dass die Wolfram Language-Spezifikation von Emojize vollständig systemunabhängig ist (oder so systemunabhängig wie möglich, angesichts der Schwankungen der Python-Implementierungen). Das bedeutet, dass Sie beispielsweise Emojize im Wolfram Function Repository genau wie etwas, das rein in der Wolfram Language geschrieben ist, bereitstellen können.
Die Anforderungen und das Engineering sind sehr unterschiedlich beim Aufrufen von C-kompatiblen Funktionen in dynamischen Bibliotheken. Aber in Version 13.3 haben wir auch dies sehr vereinfacht, indem wir die Funktion ForeignFunctionLoad verwendet haben. Es gibt viele Komplexitäten im Zusammenhang mit der Konvertierung von und nach nativen C-Datentypen, der Verwaltung des Speichers für Datenstrukturen usw. Aber wir haben jetzt sehr saubere Möglichkeiten, dies in der Wolfram Language zu tun.
Als Beispiel hier ist, wie man einen „externen Funktionsaufruf“ für eine Funktion RAND_bytes in der OpenSSL-Bibliothek einrichtet:
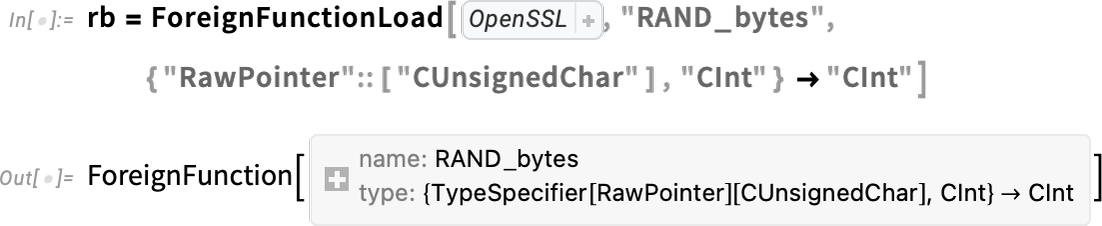
Hier verwenden wir die Compiler-Technologie der Wolfram Language, um die nativen C-Typen zu spezifizieren, die in der externen Funktion verwendet werden. Aber jetzt können wir das alles in eine Wolfram Language-Funktion verpacken:

Und wir können diese Funktion genauso aufrufen wie jede andere Wolfram Language-Funktion:
Intern werden viele komplexe Vorgänge durchgeführt. Zum Beispiel reservieren wir einen Rohspeicher-Puffer, der dann unserer C-Funktion übergeben wird. Bei dieser Speicherzuweisung erstellen wir jedoch eine symbolische Struktur, die ihn als „verwaltetes Objekt“ definiert:
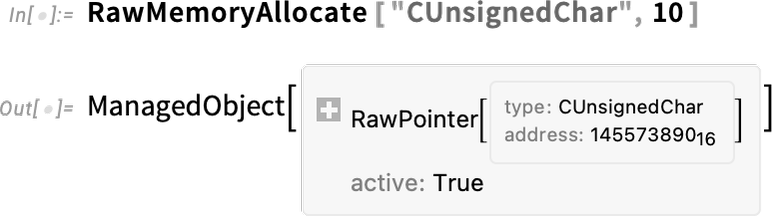
Und jetzt, wenn dieses Objekt nicht mehr verwendet wird, wird der damit verbundene Speicher automatisch freigegeben.
Ja, mit sowohl Python als auch C gibt es eine ziemliche Komplexität im Hintergrund. Aber die gute Nachricht ist, dass wir in Version 14 im Wesentlichen in der Lage waren, die Handhabung zu automatisieren. Das Ergebnis ist, dass das, was freigelegt wird, reine, einfache Wolfram Language ist.
Aber es gibt noch ein weiteres wichtiges Element. In bestimmten Python- oder C-Bibliotheken gibt es oft aufwendige Definitionen von Datenstrukturen, die spezifisch für diese Bibliothek sind. Um diese Bibliotheken zu verwenden, muss man in all die potenziell eigenartigen Komplexitäten dieser Definitionen eintauchen. Aber in der Wolfram Language haben wir konsistente symbolische Darstellungen für Dinge, egal ob es sich um Bilder, Datum oder Arten von Chemikalien handelt. Wenn Sie eine externe Bibliothek zum ersten Mal einbinden, müssen Sie ihre Datenstrukturen auf diese abbilden. Aber sobald das erledigt ist, kann jeder verwenden, was erstellt wurde, und nahtlos mit anderen Dingen integrieren, die er vielleicht tut, und möglicherweise sogar anderen externen Code aufrufen. Effektiv wird das gesamte Entwurfsframework der Wolfram Language genutzt und angewendet, selbst wenn unterliegende Implementierungen verwendet werden, die nicht auf der Wolfram Language basieren.
Für ernsthafte Entwickler
Eine einzelne Zeile (oder weniger) Wolfram Language-Code kann viel bewirken. Aber eine bemerkenswerte Eigenschaft der Sprache ist, dass sie grundsätzlich skalierbar ist: gut sowohl für sehr kurze Programme als auch für sehr lange Programme. Seit Version 13 gab es mehrere Fortschritte im Umgang mit sehr langen Programmen. Einer davon betrifft das „Code-Editing“.
Standard Wolfram Notebooks eignen sich sehr gut für explorative, erklärende und viele andere Arten von Arbeiten. Es ist sicherlich möglich, große Mengen von Code in Standard-Notebooks zu schreiben (und ich persönlich mache das zum Beispiel). Aber wenn man „Software-Engineering-artige Arbeit“ macht, ist es sowohl bequemer als auch vertrauter, was im Wesentlichen einem reinen Code-Editor zu verwenden, der weitgehend von der Code-Ausführung und -Darstellung getrennt ist. Und deshalb haben wir den „Package-Editor“, erreichbar über Datei > Neu > Paket/Script. Sie arbeiten immer noch in der Notebook-Umgebung mit all ihren ausgeklügelten Möglichkeiten. Aber die Oberfläche wurde angepasst, um eine viel textlichere „Code-Erfahrung“ zu bieten – sowohl beim Bearbeiten als auch beim Speichern von .wl-Dateien.
Hier ist ein typisches Beispiel für den Package-Editor in Aktion (in diesem Fall angewendet auf unser GitLink-Paket):

Mehrere Dinge sind sofort ersichtlich. Erstens ist es sehr zeilenorientiert. Die Zeilen (des Codes) sind nummeriert und werden nur an expliziten Zeilenumbrüchen unterbrochen. Es gibt Überschriften wie in normalen Notebooks, aber beim Speichern der Datei werden sie als Kommentare mit einer bestimmten stilisierten Struktur gespeichert:

Es ist immer noch möglich, Code im Package-Editor auszuführen, aber die Ausgabe wird nicht in der .wl-Datei gespeichert:

Eine Sache, die sich seit Version 13 geändert hat, ist, dass die Symbolleiste erheblich verbessert wurde. Zum Beispiel gibt es jetzt eine „intelligente Suche“, die sich der Code-Struktur bewusst ist:

Sie können auch zu einer Zeilennummer springen und sofort die umliegenden Codezeilen sehen:

Neben dem Code-Editing gibt es seit Version 13 weitere wichtige Funktionen für ernsthafte Entwickler, die sich mit automatisierten Tests befassen. Der wichtigste Fortschritt ist die Einführung eines vollständig symbolischen Test-Frameworks, bei dem einzelne Tests als symbolische Objekte dargestellt werden
und in symbolischer Form manipuliert werden können, dann mit Funktionen wie TestEvaluate und TestReport ausgeführt werden können:

In Version 14.0 gibt es eine weitere neue Testfunktion namens IntermediateTest, mit der Sie sozusagen Zwischenprüfpunkte in größere Tests einfügen können:

Wenn wir diesen Test auswerten, sehen wir, dass auch die Zwischentests ausgeführt wurden:
Wolfram Function Repository: 2900 Funktionen und mehr
Das Wolfram Function Repository war ein großer Erfolg. Wir haben es 2019 eingeführt, um spezifische, individuelle Funktionen, die von Benutzern beigesteuert wurden, in der Wolfram Language verfügbar zu machen. Und jetzt gibt es mehr als 2900 solcher Funktionen im Repository.
Die fast 7000 Funktionen, die die heutige Wolfram Language ausmachen, wurden im Laufe der letzten dreieinhalb Jahrzehnte sorgfältig entwickelt, immer im Bewusstsein, ein kohärentes Ganzes mit konsistenten Designprinzipien zu schaffen. Und jetzt ist der Erfolg des Function Repository gewissermaßen eine der Dividenden all dieser Anstrengungen. Denn es ist die Kohärenz und Konsistenz der zugrunde liegenden Sprache und ihrer Designprinzipien, die es ermöglichen, einfach eine Funktion nach der anderen hinzuzufügen und sie wirklich funktionieren zu lassen. Sie möchten eine Funktion hinzufügen, um eine sehr spezifische Operation durchzuführen, die Bilder und Graphen kombiniert. Nun, es gibt eine konsistente Darstellung sowohl von Bildern als auch von Graphen in der Wolfram Language, die Sie nutzen können. Und indem Sie den Prinzipien der Wolfram Language folgen – wie der Benennung von Funktionen – können Sie eine Funktion erstellen, die für Wolfram Language-Benutzer leicht zu verstehen und zu verwenden ist.
Die Verwendung des Wolfram Function Repository ist ein bemerkenswert nahtloser Prozess. Wenn Sie den Namen der Funktion kennen, können Sie sie einfach mit ResourceFunction aufrufen; die Funktion wird geladen, wenn sie benötigt wird, und dann wird sie einfach ausgeführt:

Wenn für die Funktion ein Update verfügbar ist, erhalten Sie eine Nachricht, aber die alte Version wird dennoch ausgeführt. Die Nachricht enthält eine Schaltfläche, mit der Sie das Update laden können. Anschließend können Sie Ihre Eingabe erneut ausführen und die neue Version verwenden. (Wenn Sie Code schreiben, bei dem Sie eine bestimmte Version einer Funktion verwenden möchten, können Sie einfach die Option ResourceVersion von ResourceFunction verwenden.)
Wenn Sie möchten, dass Ihr Code eleganter aussieht, werten Sie einfach das ResourceFunction-Objekt aus:

und verwenden Sie die formatierte Version:

Übrigens erhalten Sie durch Drücken von + weitere Informationen über die Funktion:

Ein wichtiges Merkmal von Funktionen im Function Repository ist, dass sie alle Dokumentationsseiten haben, die im Wesentlichen wie die Seiten für integrierte Funktionen organisiert sind:

Aber wie erstellt man einen Eintrag im Function Repository? Gehen Sie einfach zu Datei > Neu > Repository-Element > Function Repository-Element, und Sie erhalten ein Definition-Notebook:

Wir haben dies optimiert, um das Ausfüllen so einfach wie möglich zu gestalten, indem wir Boilerplate minimieren und automatisch auf Richtigkeit und Konsistenz prüfen, wann immer möglich. Das Ergebnis ist, dass es durchaus realistisch ist, ein einfaches Element des Function Repository in weniger als einer Stunde zu erstellen, wobei die meiste Zeit für das Schreiben guter erklärender Beispiele aufgewendet wird.
Wenn Sie auf „Im Repository veröffentlichen“ klicken, wird Ihre Funktion an das Überprüfungsteam des Wolfram Function Repository gesendet, dessen Aufgabe es ist sicherzustellen, dass die Funktionen im Repository das tun, was sie sagen, in einer Weise funktionieren, die mit den allgemeinen Designprinzipien der Wolfram Language konsistent ist, gute Namen haben und angemessen dokumentiert sind. Mit Ausnahme sehr spezialisierter Funktionen ist das Ziel, die Überprüfungen innerhalb einer Woche abzuschließen (und manchmal deutlich schneller) – und Funktionen so bald wie möglich zu veröffentlichen, sobald sie bereit sind.
Es gibt einen Überblick über neue (und aktualisierte) Funktionen im Function Repository, der jeden Freitag verschickt wird – und interessante Lektüre bietet (hier können Sie sich abonnieren):

Das Wolfram Function Repository ist eine kuratierte öffentliche Ressource, die von jedem Wolfram Language-System aus zugänglich ist (übrigens ist der Quellcode für jede Funktion verfügbar – drücken Sie einfach die Schaltfläche „Quellnotebook“). Es gibt jedoch noch einen weiteren wichtigen Anwendungsfall für die Infrastruktur des Function Repository: privat bereitgestellte „Ressourcen funktionen“.
Das Ganze funktioniert über die Wolfram Cloud. Sie verwenden genau dasselbe Definition-Notebook, aber anstatt es an das öffentliche Wolfram Function Repository zu senden, bereitstellen Sie Ihre Funktion einfach in der Wolfram Cloud. Sie können sie privat machen, sodass nur Sie oder eine spezifische Gruppe darauf zugreifen können. Oder Sie können sie öffentlich machen, sodass jeder, der die URL kennt, sofort darauf zugreifen und sie in seinem Wolfram Language-System verwenden kann.
Dies erweist sich als enorm nützlicher Mechanismus, sowohl für Gruppenprojekte als auch für die Erstellung von veröffentlichtem Material. In gewisser Weise ist es eine sehr leichte, aber robuste Möglichkeit, Code zu verteilen – verpackt in Funktionen, die sofort verwendet werden können. (Übrigens: Um die von Ihnen veröffentlichten Funktionen in Ihrem Wolfram Cloud-Konto zu finden, gehen Sie einfach zum Ordner „DeployedResources“ im Cloud-Dateibrowser.)
(Für Organisationen, die ihren eigenen Funktions-Repository verwalten möchten, sei erwähnt, dass der gesamte Mechanismus des Wolfram Function Repository – einschließlich der Infrastruktur für Überprüfungen usw. – auch in einer privaten Form über die Wolfram Enterprise Private Cloud verfügbar ist.)
Also, was gibt es im öffentlichen Wolfram Function Repository? Es gibt viele „Spezialfunktionen“, die für spezifische „Nischen“-Zwecke gedacht sind – aber sehr nützlich, wenn sie das sind, was Sie brauchen:





Es gibt Funktionen, die verschiedene Arten von Visualisierungen hinzufügen.







Einige Funktionen richten Benutzeroberflächen ein:

Einige Funktionen verknüpfen mit externen Diensten:




Einige Funktionen bieten einfache Dienstprogramme an:
![]()

Es gibt auch Funktionen, die für eine mögliche Integration in das Kernsystem erkundet werden:


Es gibt auch viele „Spitzenfunktionen“, die im Rahmen von Forschung oder explorativer Entwicklung hinzugefügt werden. Zum Beispiel in den Texten, die ich schreibe (einschließlich dieses), sorge ich dafür, dass alle Bilder und andere Ausgaben durch „Klick-zum-Kopieren“-Code unterstützt werden, der sie reproduziert. Dieser Code enthält sehr oft Funktionen aus dem öffentlichen Wolfram Function Repository oder aus (öffentlich zugänglichen) privaten Bereitstellungen.
The Paclet Repository Arrives
Paclets sind eine Technologie, die wir seit mehr als anderthalb Jahrzehnten verwenden, um aktualisierte Funktionalitäten an Wolfram Language-Systeme im Feld zu verteilen. In Version 13 haben wir begonnen, Werkzeuge bereitzustellen, mit denen jeder Paclets erstellen kann. Seit Version 13 haben wir auch das Wolfram Language Paclet Repository eingeführt, eine zentrale Sammlung für Paclets.

Was ist ein Paclet? Es handelt sich um eine Sammlung von Wolfram Language-Funktionalitäten, einschließlich Funktionsdefinitionen, Dokumentation, externe Bibliotheken, Stylesheets, Paletten und mehr, die als Einheit verteilt und sofort in jedem Wolfram Language-System eingesetzt werden können.
Das Paclet-Repository ist ein zentraler Ort, an dem jeder Paclets zur öffentlichen Verteilung veröffentlichen kann. Wie verhält sich dies zum Wolfram Function Repository? Sie ergänzen sich interessanterweise mit unterschiedlichen Optimierungen und Einrichtungen. Das Function Repository ist leichtgewichtiger, während das Paclet-Repository flexibler ist. Das Function Repository stellt einzelne neue Funktionen zur Verfügung, die unabhängig in die gesamte bestehende Struktur der Wolfram Language passen. Das Paclet-Repository stellt größere Funktionsmodule zur Verfügung, die ein ganzes Framework und Umgebung definieren können.
Das Function Repository wird vollständig kuratiert, wobei jede Funktion von unserem Team überprüft wird, bevor sie veröffentlicht wird. Das Paclet-Repository ist ein sofortiges Bereitstellungssystem ohne vorherige Überprüfung. Im Function Repository wird jede Funktion lediglich durch ihren Namen angegeben – und unser Überprüfungsteam ist dafür verantwortlich, sicherzustellen, dass die Namen gut gewählt sind und keine Konflikte aufweisen. Im Paclet-Repository erhält jeder Beitragende seinen eigenen Namensraum, und alle Funktionen und sonstigen Materialien befinden sich innerhalb dieses Namensraums. Zum Beispiel habe ich die Funktion RandomHypergraph dem Function Repository hinzugefügt, die einfach über ResourceFunction["RandomHypergraph"] aufgerufen werden kann. Wenn ich diese Funktion jedoch in einem Paclet im Paclet-Repository platziert hätte, müsste sie über etwas wie PacletSymbol[„StephenWolfram/Hypergraphs“, „RandomHypergraph“] aufgerufen werden.
PacletSymbol ist übrigens eine bequeme Möglichkeit, einzelne Funktionen innerhalb eines Paclets „tief“ zu erreichen. PacletSymbol installiert (und lädt) vorübergehend ein Paclet, damit Sie auf ein bestimmtes Symbol darin zugreifen können. Oftmals möchte man jedoch ein Paclet dauerhaft installieren (mit PacletInstall) und dann explizit seine Inhalte laden (mit Needs), wann immer man die Symbole verwenden möchte. (Alle verschiedenen Nebenelemente wie Dokumentation, Stylesheets usw. in einem Paclet werden bei der Installation eingerichtet.)
Wie sieht ein Paclet im Paclet-Repository aus? Jedes Paclet hat eine Startseite, die typischerweise eine Gesamtübersicht, eine Anleitung zu den enthaltenen Funktionen und einige allgemeine Beispiele des Paclets enthält.

Einzelne Funktionen haben normalerweise ihre eigenen Dokumentationsseiten:

Genau wie in der Hauptdokumentation der Wolfram Language können einzelne Funktionen eine ganze Hierarchie von Leitfaden-Seiten und Tutorials haben.
In den Beispielen in der Paclet-Dokumentation sieht man oft Konstruktionen wie ![]() . Diese repräsentieren Symbole im Paclet, präsentiert in Formen wie PacletSymbol["WolframChemistry/ProteinVisualization", "AmidePlanePlot"], die es ermöglichen, diese Symbole auf eigenständige Weise zu verwenden. Wenn Sie übrigens eine solche Form direkt auswerten, erzwingt sie (temporäre) Installation des Paclets und gibt dann das tatsächliche, rohe Symbol zurück, das im Paclet enthalten ist.
. Diese repräsentieren Symbole im Paclet, präsentiert in Formen wie PacletSymbol["WolframChemistry/ProteinVisualization", "AmidePlanePlot"], die es ermöglichen, diese Symbole auf eigenständige Weise zu verwenden. Wenn Sie übrigens eine solche Form direkt auswerten, erzwingt sie (temporäre) Installation des Paclets und gibt dann das tatsächliche, rohe Symbol zurück, das im Paclet enthalten ist.
Wie erstellt man ein Paclet, das sich für die Einreichung im Paclet Repository eignet? Dies kann rein programmatisch erfolgen oder Sie können über Datei > Neu > Repository-Element > Paclet-Repository-Element starten, was praktisch eine vollständige IDE für die Erstellung von Paclets darstellt. Der erste Schritt besteht darin, anzugeben, wo Sie Ihr Paclet zusammenstellen möchten. Sie geben einige grundlegende Informationen

Dann wird ein Paclet-Ressourcendefinitions-Notebook erstellt, über das Sie Funktionsdefinitionen angeben, Dokumentationsseiten einrichten und festlegen können, wie die Startseite Ihres Paclets aussehen soll usw.

Es gibt viele ausgefeilte Tools, mit denen Sie voll ausgestattete Paclets mit der gleichen Bandbreite und Tiefe an Funktionen erstellen können, wie Sie sie in der Wolfram Language selbst finden. Zum Beispiel ermöglichen Ihnen die Dokumentationstools, voll ausgestattete Dokumentationsseiten zu erstellen (Funktionsseiten, Leitfaden-Seiten, Tutorials usw.).

Sobald Sie ein Paclet zusammengestellt haben, können Sie es überprüfen, erstellen, privat bereitstellen oder im Paclet Repository einreichen. Nachdem Sie es eingereicht haben, wird es automatisch auf den Servern des Paclet Repository eingerichtet, und innerhalb weniger Minuten werden die von Ihnen erstellten Seiten zur Beschreibung Ihres Paclets auf der Paclet Repository-Website angezeigt.
Was gibt es bisher im Paclet Repository? Es gibt viele gute und sehr ernsthafte Dinge, die sowohl von Teams in unserem Unternehmen als auch von Mitgliedern der breiteren Wolfram Language-Community beigetragen wurden. Tatsächlich enthalten viele der derzeit 134 Paclets im Paclet Repository genug Material, dass man darüber einen ganzen Artikel schreiben könnte.
Eine Kategorie von Dingen, die Sie im Paclet Repository finden, sind Snapshots unserer laufenden internen Entwicklungsprojekte – viele davon werden letztendlich integrierte Bestandteile der Wolfram Language. Ein gutes Beispiel dafür ist unsere LLM- und Chat-Notebook-Funktionalität, deren schnelle Entwicklung und Bereitstellung im letzten Jahr durch die Nutzung des Paclet Repository ermöglicht wurde. Ein weiteres Beispiel, das laufende Arbeiten unseres Chemieteams (auch bekannt als WolframChemistry im Paclet Repository) repräsentiert, ist das ChemistryFunctions-Paclet, das Funktionen wie enthalten:

Und ja, das ist interaktiv:

Und auch aus WolframChemistry:

Ein weiteres „Entwicklungssnapshot“ ist DiffTools – ein Paclet zum Erstellen und Anzeigen von Unterschieden zwischen Zeichenfolgen, Zellen, Notebooks usw.:

Ein wichtiges Paclet ist QuantumFramework, das die Funktionalität für unser Wolfram Quantum Framework bereitstellt.

und bietet umfangreiche Unterstützung für Quantencomputing (mit zumindest einigen Verbindungen zu Mehrwegesystemen und unserem Physikprojekt).


Wenn wir über unser Physikprojekt sprechen, gibt es über 200 Funktionen im Wolfram Function Repository, die es unterstützen. Es gibt jedoch auch Paclets wie WolframInstitute/Hypergraph:

Ein Beispiel für ein extern beigetragenes Paket ist Automata, das über 250 Funktionen für Berechnungen im Zusammenhang mit endlichen Automaten bietet.


Ein weiteres beigetragenes Paclet ist FunctionalParsers, das von einer symbolischen Parser-Spezifikation zu einem tatsächlichen Parser übergeht und hier im Rückwärtsmodus verwendet wird, um zufällige „Sätze“ zu generieren:

Phi4Tools ist ein spezialisierteres Paclet für die Arbeit mit Feynman-Diagrammen in ![]() der Feldtheorie.
der Feldtheorie.



Und als weiteres Beispiel gibt es MaXrd für Kristallographie und Röntgenstreuung.


Als nur ein weiteres Beispiel gibt es das Organizer-Paclet – ein Dienstprogramm-Paclet zum Erstellen und Bearbeiten von Organizer-Notizbüchern. Im Gegensatz zu den anderen hier gezeigten Paclets stellt es jedoch keine Wolfram Language-Funktionen bereit. Stattdessen fügt es nach der Installation eine Palette Ihrer Palettenliste hinzu.


Kommende Attraktionen
Heute ist Version 14 abgeschlossen und weltweit verfügbar. Was steht als Nächstes an? Wir haben viele laufende Projekte – einige mit bereits jahrelanger Entwicklung. Einige erweitern und stärken die bestehende Wolfram Language, andere gehen in neue Richtungen.
Ein Hauptaugenmerk liegt darauf, die Bereitstellung der Sprache zu erweitern und zu vereinheitlichen: Wir wollen die Art und Weise, wie sie auf Computern bereitgestellt und installiert wird, vereinheitlichen und verpacken, damit sie effizient in eigenständige Anwendungen integriert werden kann, usw.
Ein weiterer Schwerpunkt liegt auf der Verbesserung der Handhabung sehr großer Datenmengen durch die Wolfram Language – einschließlich der nahtlosen Integration von Out-of-Core- und Lazy-Processing.
Dann gibt es natürlich die algorithmische Entwicklung. Einige basieren auf klassischen Ansätzen und erweitern direkt die Funktionsvielfalt, die wir über Jahrzehnte aufgebaut haben. Andere basieren stärker auf KI. Wir entwickeln heuristische Algorithmen und Meta-Algorithmen seit Version 1.0 – und verwenden zunehmend Methoden des maschinellen Lernens. Wie weit können neuronale Netzmethoden gehen? Das wissen wir noch nicht. Wir verwenden sie routinemäßig bei der Algorithmusauswahl. Aber inwieweit können sie im Kern der Algorithmen helfen?
Ich erinnere mich an etwas, das wir 1987 bei der Entwicklung von Version 1.0 gemacht haben. In der numerischen Analyse gab es eine lange Tradition, mühsam Serienapproximationen für bestimmte mathematische Funktionen abzuleiten. Aber wir wollten in der Lage sein, Hunderte von verschiedenen Funktionen für beliebige komplexe Argumente mit beliebiger Genauigkeit zu berechnen. Wie haben wir das gemacht? Wir gingen von Serien zu rationalen Approximationen über – und dann haben wir auf eine sehr „maschinenlernähnliche“ Weise monatelang CPU-Zeit systematisch optimiert. Nun versuchen wir, etwas Ähnliches zu tun – jedoch in noch ambitionierteren Bereichen und jetzt mit großen neuronalen Netzen als Grundlage.
Wir erforschen auch den Einsatz von neuronalen Netzen zur „Steuerung“ präziser Algorithmen, indem wir heuristische Entscheidungen treffen, die entweder die präzisen Algorithmen lenken oder von ihnen validiert werden können. Bisher hat nichts von dem, was wir produziert haben, unsere bestehenden Methoden übertroffen, aber es scheint plausibel, dass es bald der Fall sein wird
Wir arbeiten intensiv an verschiedenen Aspekten der Metaprogrammierung. Ein Projekt besteht darin, LLMs (Large Language Models) bei der Konstruktion von Wolfram Language-Code zu unterstützen – sowie Kommentare dazu zu geben und zu analysieren, was schief gelaufen ist, wenn der Code nicht das tat, was man erwartet hatte. Dann gibt es die Code-Annotation – bei der LLMs helfen können, Dinge wie die wahrscheinlichste Art für etwas vorherzusagen. Und schließlich die Code-Kompilierung. Wir arbeiten seit vielen Jahren an einem vollständigen Compiler für die Wolfram Language, und in jeder Version wird das, was wir haben, immer leistungsfähiger. Seit mehr als 30 Jahren betreiben wir auf bestimmten Gebieten (insbesondere im Bereich numerischer Berechnungen) eine automatische Kompilierung. Und schließlich wird eine vollständige automatische Kompilierung für alles möglich sein. Aber bislang haben einige der größten Vorteile unserer Compiler-Technologie in unserer internen Entwicklung gelegen, wo wir jetzt einfach durch sorgfältig geschriebenen, kompilierten Wolfram Language-Code eine optimale Performance erzielen können.
Eine der großen Lehren aus dem überraschenden Erfolg von LLMs ist, dass es in der bedeutungsvollen menschlichen Sprache potenziell mehr Struktur gibt, als wir dachten. Ich habe schon lange daran interessiert, was ich eine „symbolische Diskurs-Sprache“ genannt habe, die eine Repräsentation des täglichen Diskurses ermöglicht. Die LLMs haben das nicht explizit getan. Aber sie ermutigen die Idee, dass es möglich sein sollte, und sie bieten auch praktische Hilfe dabei. Und egal, ob es darum geht, narrative Texte, Verträge oder textliche Spezifikationen darzustellen, es geht darum, die aufgebauten Begriffe und Strukturen der Berechnungssprache zu erweitern.
Typischerweise gibt es mehrere Treiber für unsere fortlaufenden Entwicklungsbemühungen. Manchmal geht es darum, einen Turm von Fähigkeiten in eine bekannte Richtung weiterzuentwickeln (wie zum Beispiel das Lösen von partiellen Differentialgleichungen). Manchmal lässt uns der Turm, den wir gebaut haben, plötzlich neue Möglichkeiten erkennen. Manchmal erkennen wir, wenn wir das, was wir gebaut haben, tatsächlich verwenden, dass es offensichtliche Möglichkeiten gibt, es zu verbessern oder zu erweitern – oder sich auf etwas zu konzentrieren, von dem wir jetzt sehen können, dass es wertvoll ist. Und dann gibt es Fälle, in denen Dinge, die in der Technologiewelt geschehen, plötzlich neue Möglichkeiten eröffnen – wie es LLMs kürzlich getan haben und XR (Extended Reality) vielleicht irgendwann tun wird. Und schließlich gibt es Fälle, in denen neue wissenschaftliche Erkenntnisse neue Richtungen nahelegen.
Ich hatte angenommen, dass unser Physics Project bestenfalls erst in Jahrhunderten praktische Anwendungen haben würde. Aber tatsächlich hat sich gezeigt, dass die Korrespondenz, die es zwischen Physik und Berechnung definiert hat, uns recht unmittelbare neue Möglichkeiten gibt, über Aspekte der praktischen Berechnung nachzudenken. Und tatsächlich erkunden wir jetzt aktiv, wie wir dies nutzen können, um eine neue Ebene der parallelen und verteilten Berechnung in der Wolfram Language zu definieren, sowie symbolisch – nicht nur die Ergebnisse von Berechnungen, sondern auch den laufenden Prozess der Berechnung – darzustellen.
Man könnte denken, dass nach fast vier Jahrzehnten intensiver Entwicklung in der Entwicklung der Wolfram Language nichts mehr zu tun wäre. Aber tatsächlich gibt es auf jeder Ebene, die wir erreichen, immer mehr, was möglich wird, und immer mehr, was wir für möglich halten. Und tatsächlich ist dieser Moment besonders fruchtbar, mit einem beispiellos breiten Spektrum an Möglichkeiten. Version 14 ist ein wichtiger und befriedigender Meilenstein. Aber es stehen wunderbare Dinge bevor – während wir unsere langfristige Mission fortsetzen, das Rechenparadigma zu seinem Potenzial zu führen und unsere Berechnungssprache zu entwickeln, um dies zu ermöglichen.